 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-automatic Data Extraction System for Heterogeneous Data Sources: A Case Study from Cotton Industry
Paper and Code
Nov 05, 2021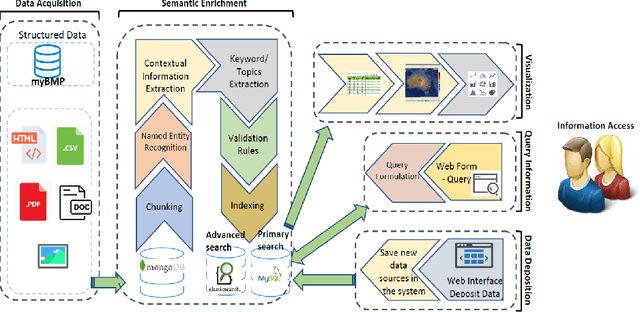
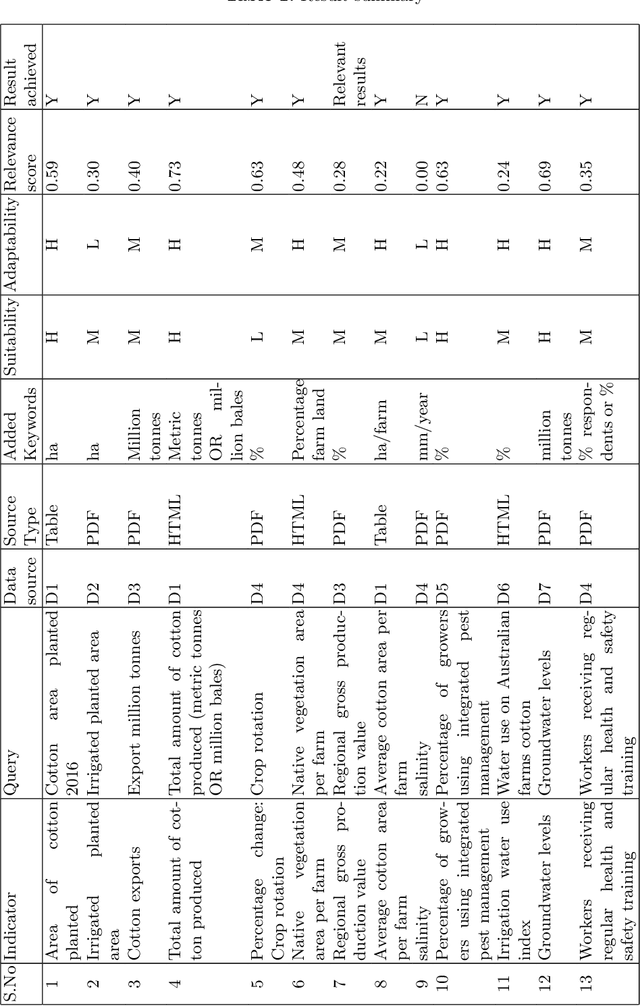

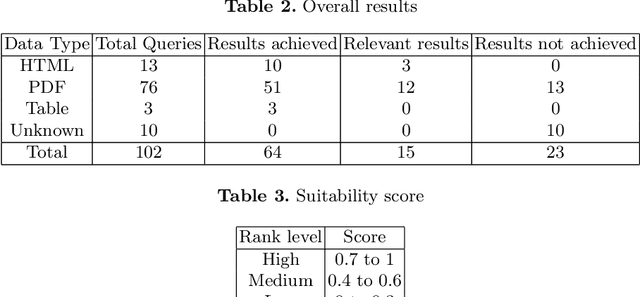
With the recent developments in digitisation, there are increasing number of documents available online. There are several information extraction tools that are available to extract information from digitised documents. However, identifying precise answers to a given query is often a challenging task especially if the data source where the relevant information resides is unknown. This situation becomes more complex when the data source is available in multiple formats such as PDF, table and html. In this paper, we propose a novel data extraction system to discover relevant and focused information from diverse unstructured data sources based on text mining approaches. We perform a qualitative analysis to evaluate the proposed system and its suitability and adaptability using cotton industry.