 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Collaborative Reasoning
Dec 28, 2021
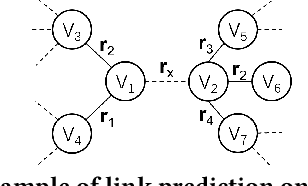


Graphs can represent relational information among entities and graph structures are widely used in many intelligent tasks such as search, recommendation, and question answering. However, most of the graph-structured data in practice suffers from incompleteness, and thus link prediction becomes an important research problem. Though many models are proposed for link prediction, the following two problems are still less explored: (1) Most methods model each link independently without making use of the rich information from relevant links, and (2) existing models are mostly designed based on associative learning and do not take reasoning into consideration. With these concerns, in this paper, we propose Graph Collaborative Reasoning (GCR), which can use the neighbor link information for relational reasoning on graphs from logical reasoning perspectives. We provide a simple approach to translate a graph structure into logical expressions, so that the link prediction task can be converted into a neural logic reasoning problem. We apply logical constrained neural modules to build the network architecture according to the logical expression and use back propagation to efficiently learn the model parameters, which bridges differentiable learning and symbolic reasoning in a unified architecture. To show the effectiveness of our work, we conduct experiments on graph-related tasks such as link prediction and recommendation based on commonly used benchmark datasets, and our graph collaborative reasoning approach achieves state-of-the-art performance.
Neural Residual Flow Fields for Efficient Video Representations
Jan 12, 2022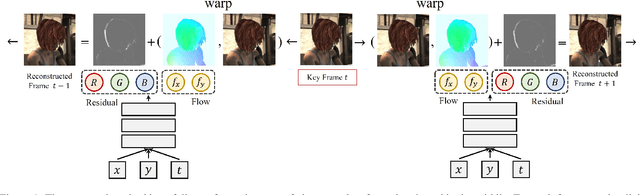
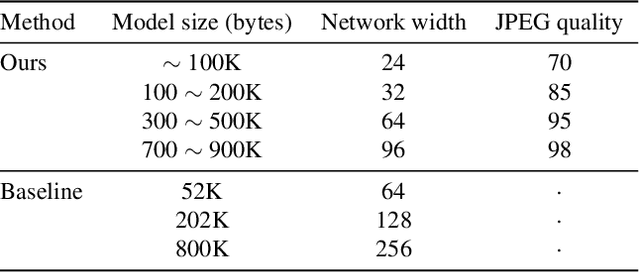
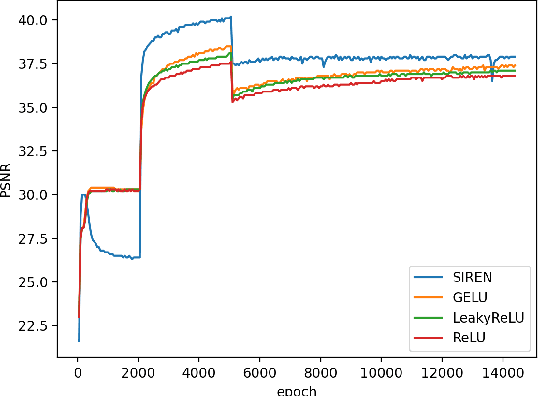
Implicit neural representation (INR) has emerged as a powerful paradigm for representing signals, such as images, videos, 3D shapes, etc. Although it has shown the ability to represent fine details, its efficiency as a data representation has not been extensively studied. In INR, the data is stored in the form of parameters of a neural network and general purpose optimization algorithms do not generally exploit the spatial and temporal redundancy in signals. In this paper, we suggest a novel INR approach to representing and compressing videos by explicitly removing data redundancy. Instead of storing raw RGB colors, we propose Neural Residual Flow Fields (NRFF), using motion information across video frames and residuals that are necessary to reconstruct a video. Maintaining the motion information, which is usually smoother and less complex than the raw signals, requires far fewer parameters. Furthermore, reusing redundant pixel values further improves the network parameter efficiency. Experimental results have shown that the proposed method outperforms the baseline methods by a significant margin. The code is available in https://github.com/daniel03c1/eff_video_representation.
Explainability for identification of vulnerable groups in machine learning models
Mar 01, 2022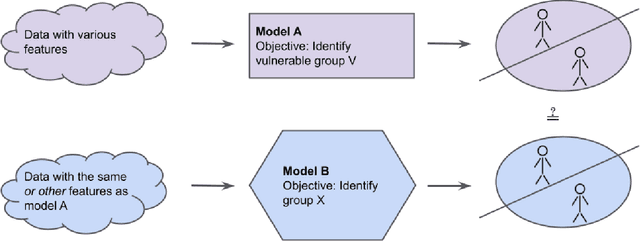
If a prediction model identifies vulnerable individuals or groups, the use of that model may become an ethical issue. But can we know that this is what a model does? Machine learning fairness as a field is focused on the just treatment of individuals and groups under information processing with machine learning methods. While considerable attention has been given to mitigating discrimination of protected groups, vulnerable groups have not received the same attention. Unlike protected groups, which can be regarded as always vulnerable, a vulnerable group may be vulnerable in one context but not in another. This raises new challenges on how and when to protect vulnerable individuals and groups under machine learning. Methods from explainable artificial intelligence (XAI), in contrast, do consider more contextual issues and are concerned with answering the question "why was this decision made?". Neither existing fairness nor existing explainability methods allow us to ascertain if a prediction model identifies vulnerability. We discuss this problem and propose approaches for analysing prediction models in this respect.
Deep Information Theoretic Registration
Dec 31, 2018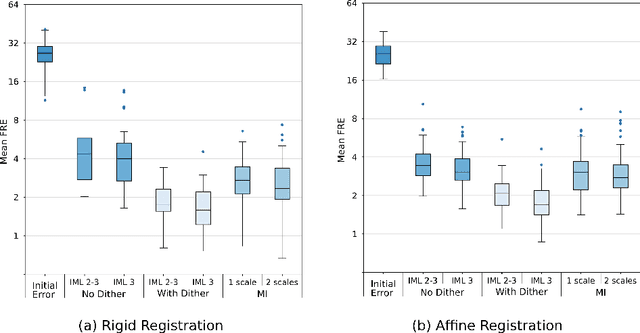
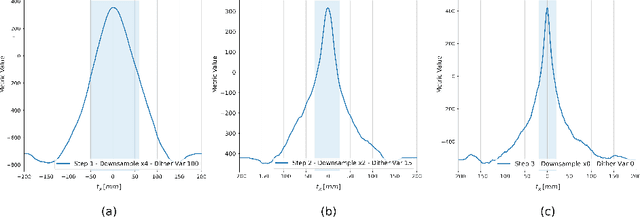
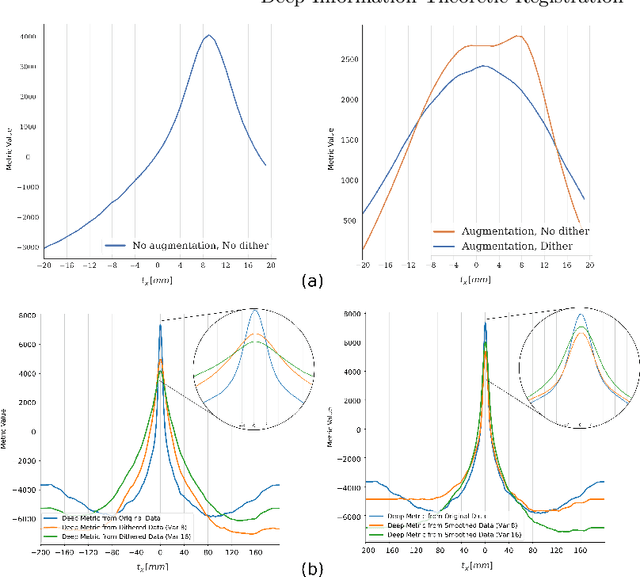
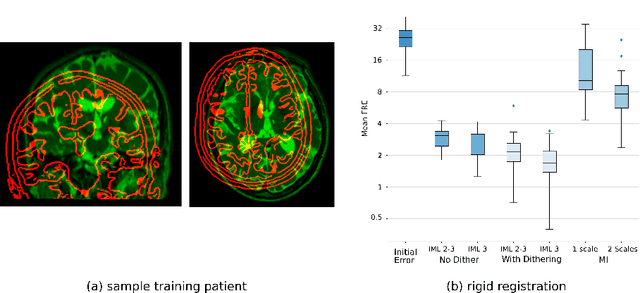
This paper establishes an information theoretic framework for deep metric based image registration techniques. We show an exact equivalence between maximum profile likelihood and minimization of joint entropy, an important early information theoretic registration method. We further derive deep classifier-based metrics that can be used with iterated maximum likelihood to achieve Deep Information Theoretic Registration on patches rather than pixels. This alleviates a major shortcoming of previous information theoretic registration approaches, namely the implicit pixel-wise independence assumptions. Our proposed approach does not require well-registered training data; this brings previous fully supervised deep metric registration approaches to the realm of weak supervision. We evaluate our approach on several image registration tasks and show significantly better performance compared to mutual information, specifically when images have substantially different contrasts. This work enables general-purpose registration in applications where current methods are not successful.
Online handwriting, signature and touch dynamics: tasks and potential applications in the field of security and health
Feb 24, 2022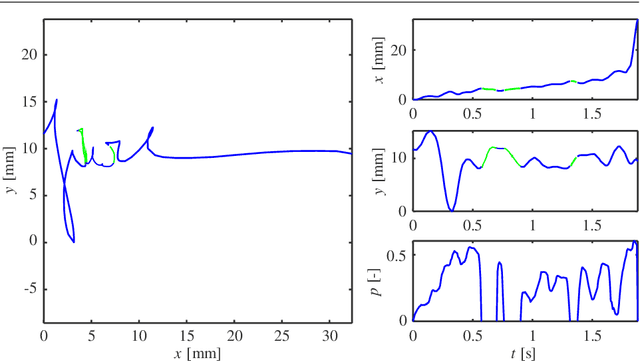

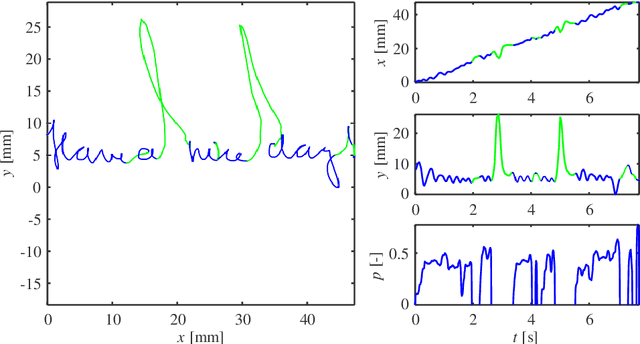
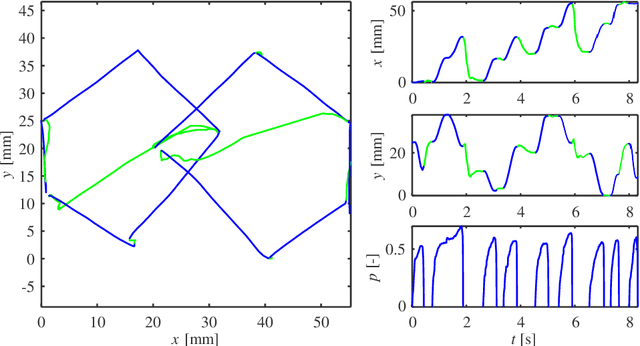
Background: An advantageous property of behavioural signals ,e.g. handwriting, in contrast to morphological ones, such as iris, fingerprint, hand geometry, etc., is the possibility to ask a user for a very rich amount of different tasks. Methods: This article summarises recent findings and applications of different handwriting and drawing tasks in the field of security and health. More specifically, it is focused on on-line handwriting and hand-based interaction, i.e. signals that utilise a digitizing device (specific devoted or general-purpose tablet/smartphone) during the realization of the tasks. Such devices permit the acquisition of on-surface dynamics as well as in-air movements in time, thus providing complex and richer information when compared to the conventional pen and paper method. Conclusions: Although the scientific literature reports a wide range of tasks and applications, in this paper, we summarize only those providing competitive results (e.g. in terms of discrimination power) and having a significant impact in the field.
* 27 pages
MIME: Mutual Information Minimisation Exploration
Jan 16, 2020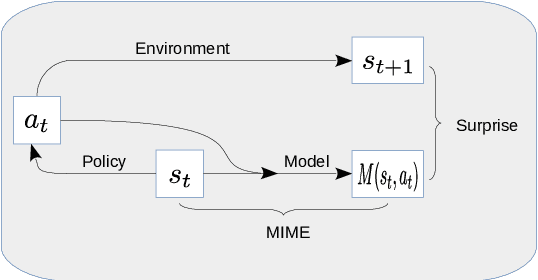

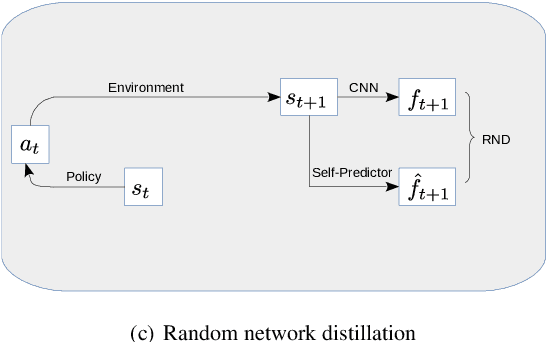
We show that reinforcement learning agents that learn by surprise (surprisal) get stuck at abrupt environmental transition boundaries because these transitions are difficult to learn. We propose a counter-intuitive solution that we call Mutual Information Minimising Exploration (MIME) where an agent learns a latent representation of the environment without trying to predict the future states. We show that our agent performs significantly better over sharp transition boundaries while matching the performance of surprisal driven agents elsewhere. In particular, we show state-of-the-art performance on difficult learning games such as Gravitar, Montezuma's Revenge and Doom.
Learning to Evolve on Dynamic Graphs
Nov 13, 2021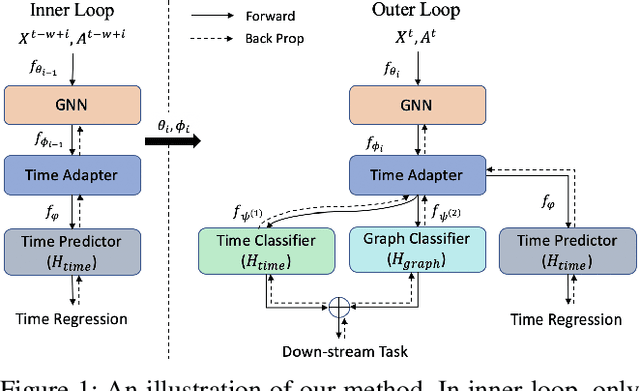

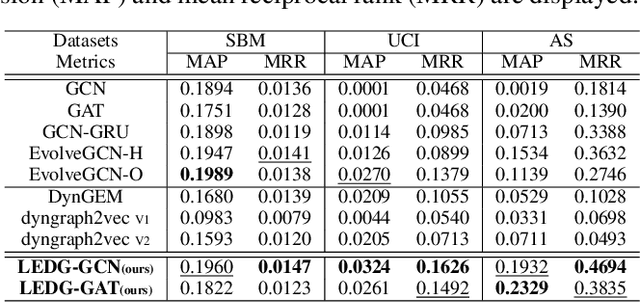
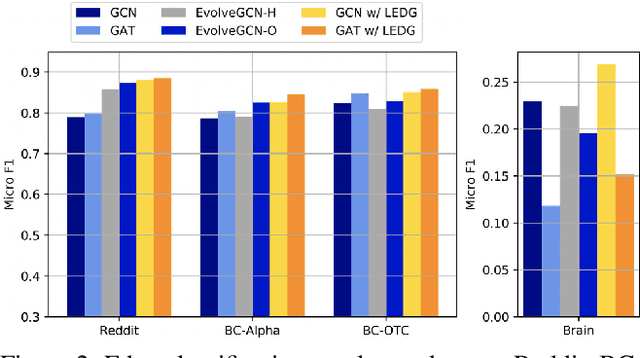
Representation learning in dynamic graphs is a challenging problem because the topology of graph and node features vary at different time. This requires the model to be able to effectively capture both graph topology information and temporal information. Most existing works are built on recurrent neural networks (RNNs), which are used to exact temporal information of dynamic graphs, and thus they inherit the same drawbacks of RNNs. In this paper, we propose Learning to Evolve on Dynamic Graphs (LEDG) - a novel algorithm that jointly learns graph information and time information. Specifically, our approach utilizes gradient-based meta-learning to learn updating strategies that have better generalization ability than RNN on snapshots. It is model-agnostic and thus can train any message passing based graph neural network (GNN) on dynamic graphs. To enhance the representation power, we disentangle the embeddings into time embeddings and graph intrinsic embeddings. We conduct experiments on various datasets and down-stream tasks, and the experimental results validate the effectiveness of our method.
Deep Co-supervision and Attention Fusion Strategy for Automatic COVID-19 Lung Infection Segmentation on CT Images
Dec 20, 2021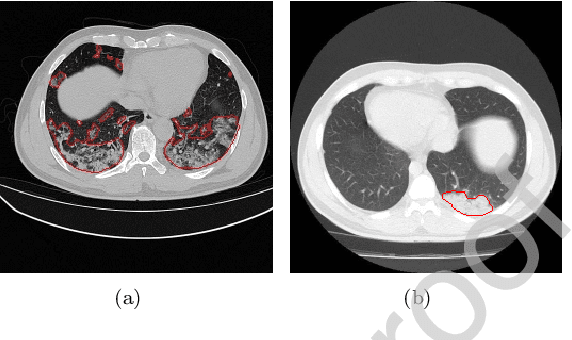
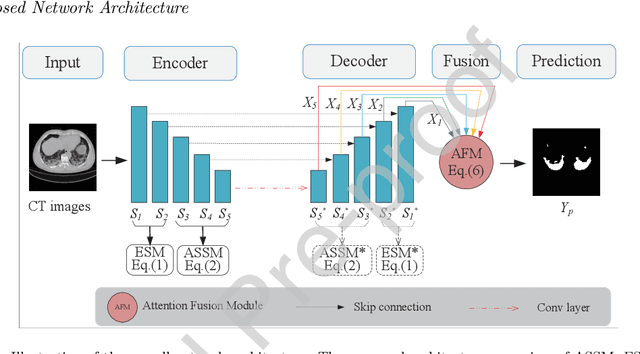
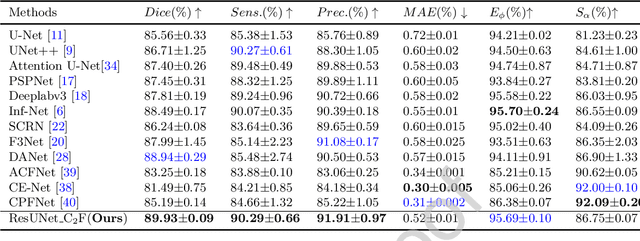
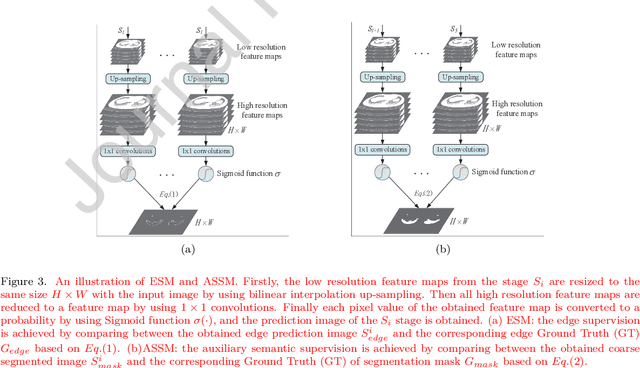
Due to the irregular shapes,various sizes and indistinguishable boundaries between the normal and infected tissues, it is still a challenging task to accurately segment the infected lesions of COVID-19 on CT images. In this paper, a novel segmentation scheme is proposed for the infections of COVID-19 by enhancing supervised information and fusing multi-scale feature maps of different levels based on the encoder-decoder architecture. To this end, a deep collaborative supervision (Co-supervision) scheme is proposed to guide the network learning the features of edges and semantics. More specifically, an Edge Supervised Module (ESM) is firstly designed to highlight low-level boundary features by incorporating the edge supervised information into the initial stage of down-sampling. Meanwhile, an Auxiliary Semantic Supervised Module (ASSM) is proposed to strengthen high-level semantic information by integrating mask supervised information into the later stage. Then an Attention Fusion Module (AFM) is developed to fuse multiple scale feature maps of different levels by using an attention mechanism to reduce the semantic gaps between high-level and low-level feature maps. Finally, the effectiveness of the proposed scheme is demonstrated on four various COVID-19 CT datasets. The results show that the proposed three modules are all promising. Based on the baseline (ResUnet), using ESM, ASSM, or AFM alone can respectively increase Dice metric by 1.12\%, 1.95\%,1.63\% in our dataset, while the integration by incorporating three models together can rise 3.97\%. Compared with the existing approaches in various datasets, the proposed method can obtain better segmentation performance in some main metrics, and can achieve the best generalization and comprehensive performance.
Graph Neural Networks for Double-Strand DNA Breaks Prediction
Jan 04, 2022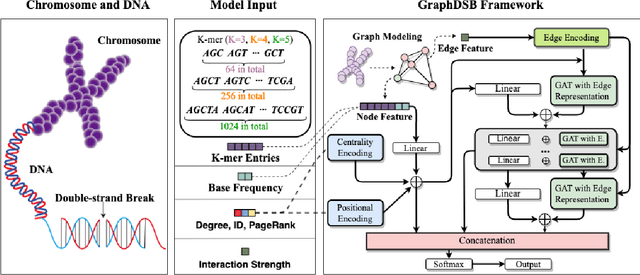
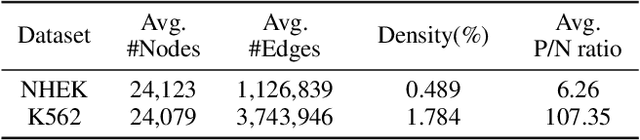

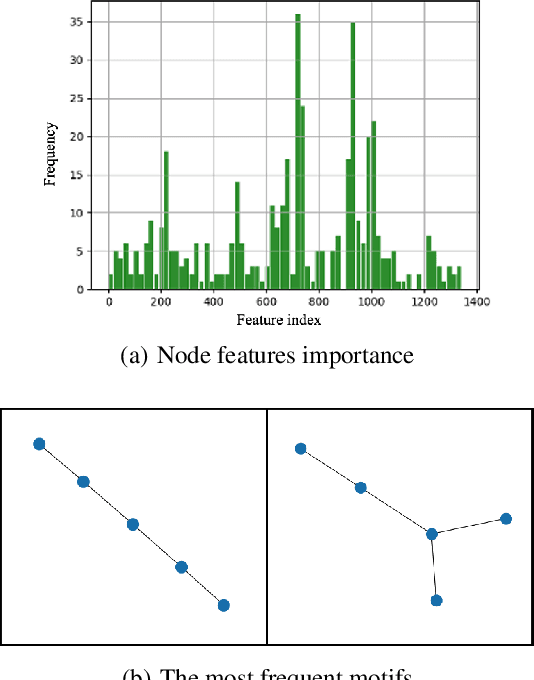
Double-strand DNA breaks (DSBs) are a form of DNA damage that can cause abnormal chromosomal rearrangements. Recent technologies based on high-throughput experiments have obvious high costs and technical challenges.Therefore, we design a graph neural network based method to predict DSBs (GraphDSB), using DNA sequence features and chromosome structure information. In order to improve the expression ability of the model, we introduce Jumping Knowledge architecture and several effective structural encoding methods. The contribution of structural information to the prediction of DSBs is verified by the experiments on datasets from normal human epidermal keratinocytes (NHEK) and chronic myeloid leukemia cell line (K562), and the ablation studies further demonstrate the effectiveness of the designed components in the proposed GraphDSB framework. Finally, we use GNNExplainer to analyze the contribution of node features and topology to DSBs prediction, and proved the high contribution of 5-mer DNA sequence features and two chromatin interaction modes.
A Self-Supervised Descriptor for Image Copy Detection
Feb 21, 2022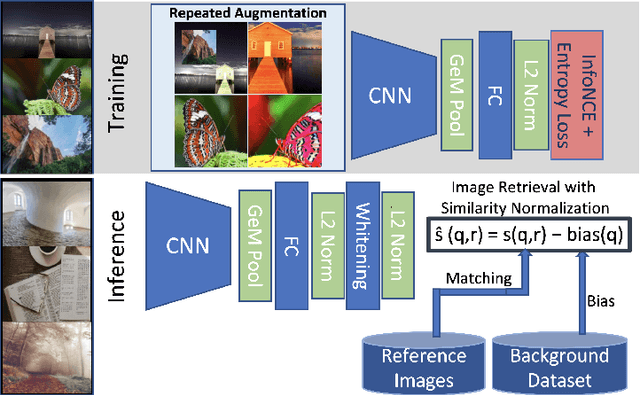


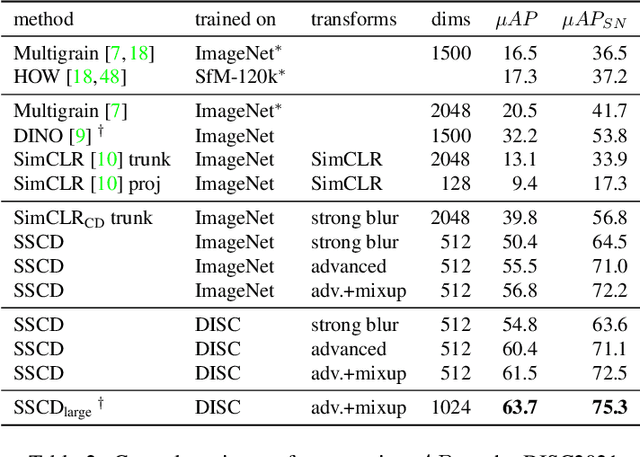
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute.