 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bayesian optimization with improved scalability and derivative information for efficient design of nanophotonic structures
Jan 08, 2021
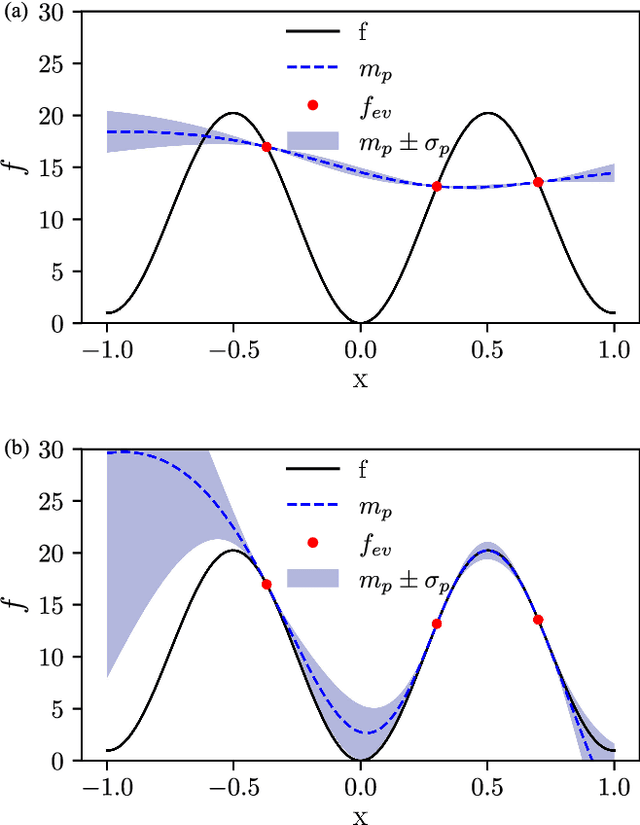
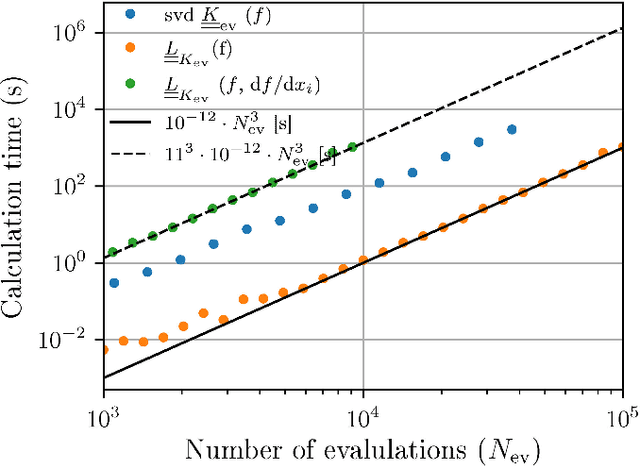
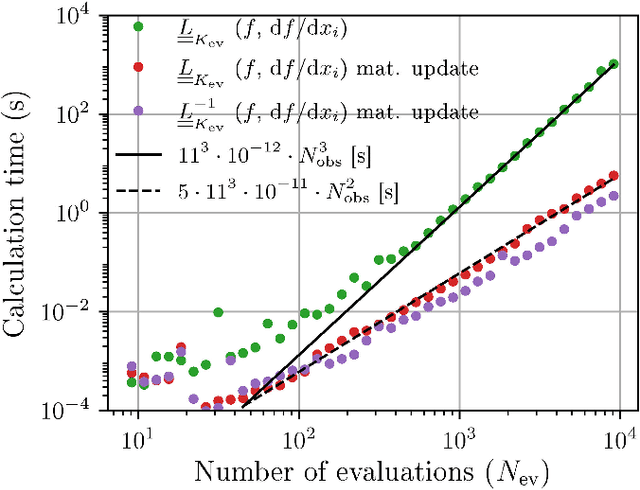
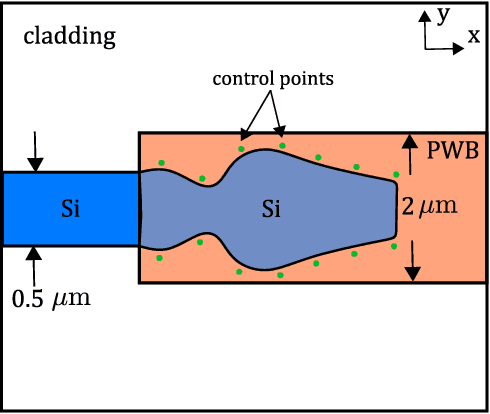
We propose the combination of forward shape derivatives and the use of an iterative inversion scheme for Bayesian optimization to find optimal designs of nanophotonic devices. This approach widens the range of applicability of Bayesian optmization to situations where a larger number of iterations is required and where derivative information is available. This was previously impractical because the computational efforts required to identify the next evaluation point in the parameter space became much larger than the actual evaluation of the objective function. We demonstrate an implementation of the method by optimizing a waveguide edge coupler.
Covariance Recovery for One-Bit Sampled Data With Time-Varying Sampling Thresholds-Part I: Stationary Signals
Mar 16, 2022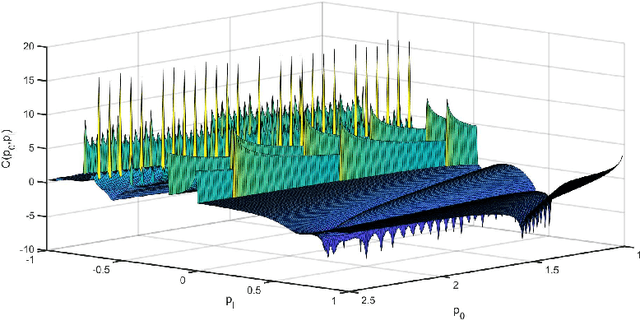
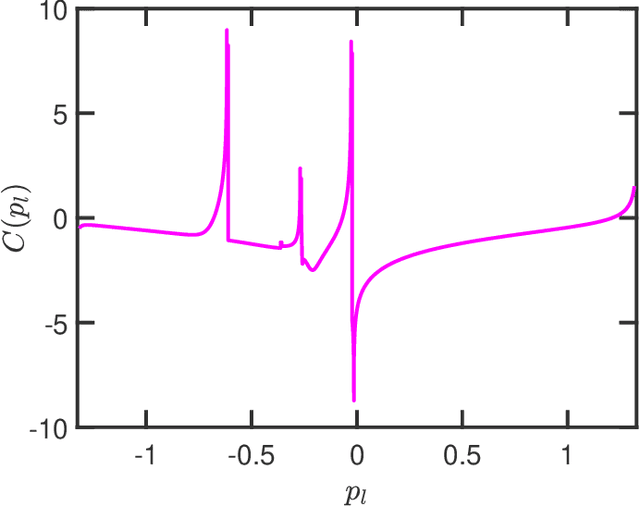
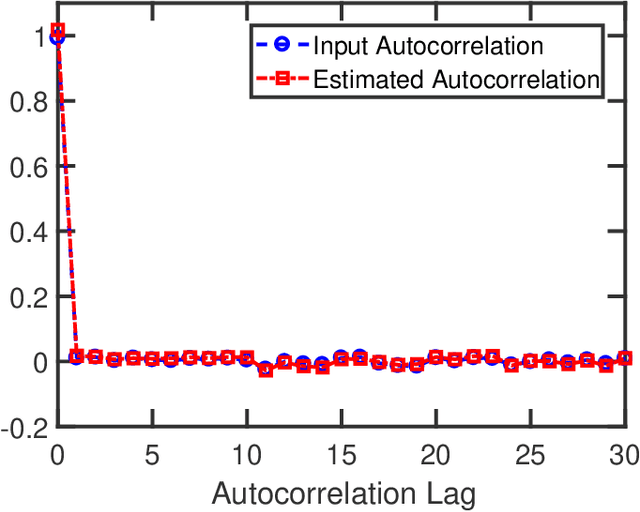
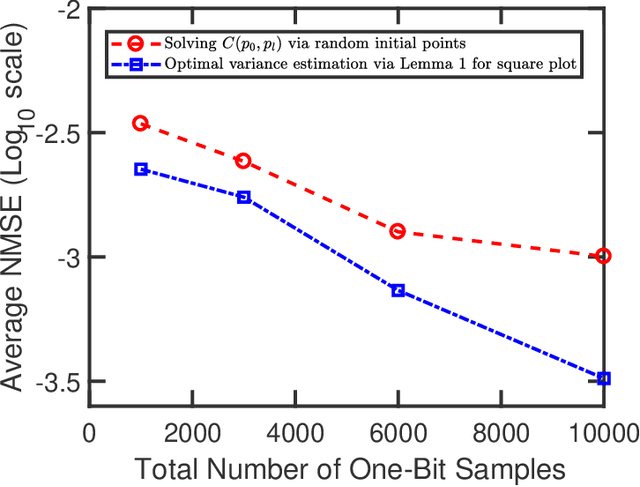
One-bit quantization, which relies on comparing the signals of interest with given threshold levels, has attracted considerable attention in signal processing for communications and sensing. A useful tool for covariance recovery in such settings is the arcsine law, that estimates the normalized covariance matrix of zero-mean stationary input signals. This relation, however, only considers a zero sampling threshold, which can cause a remarkable information loss. In this paper, the idea of the arcsine law is extended to the case where one-bit analog-to-digital converters (ADCs) apply time-varying thresholds. Specifically, three distinct approaches are proposed, investigated, and compared, to recover the autocorrelation sequence of the stationary signals of interest. Additionally, we will study a modification of the Bussgang law, a famous relation facilitating the recovery of the cross-correlation between the one-bit sampled data and the zero-mean stationary input signal. Similar to the case of the arcsine law, the Bussgang law only considers a zero sampling threshold. This relation is also extended to accommodate the more general case of time-varying thresholds for the stationary input signals.
A Color Image Steganography Based on Frequency Sub-band Selection
Dec 29, 2021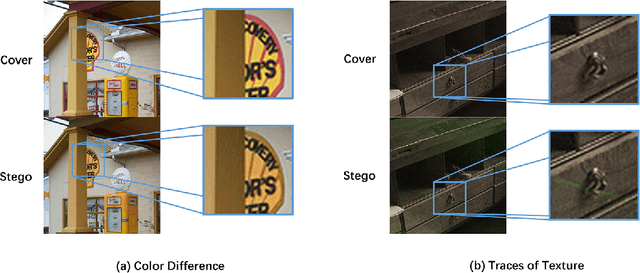
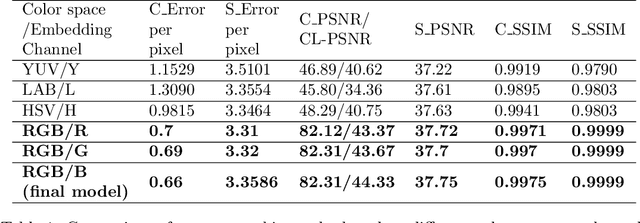

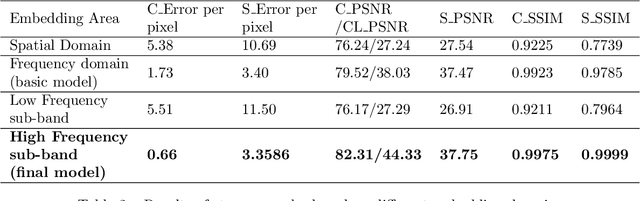
Color image steganography based on deep learning is the art of hiding information in the color image. Among them, image hiding steganography(hiding image with image) has attracted much attention in recent years because of its great steganographic capacity. However, images generated by image hiding steganography may show some obvious color distortion or artificial texture traces. We propose a color image steganographic model based on frequency sub-band selection to solve the above problems. Firstly, we discuss the relationship between the characteristics of different color spaces/frequency sub-bands and the generated image quality. Then, we select the B channel of the RGB image as the embedding channel and the high-frequency sub-band as the embedding domain. DWT(discrete wavelet transformation) transforms B channel information and secret gray image into frequency domain information, and then the secret image is embedded and extracted in the frequency domain. Comprehensive experiments demonstrate that images generated by our model have better image quality, and the imperceptibility is significantly increased.
Multi-Perspective Semantic Information Retrieval in the Biomedical Domain
Jul 17, 2020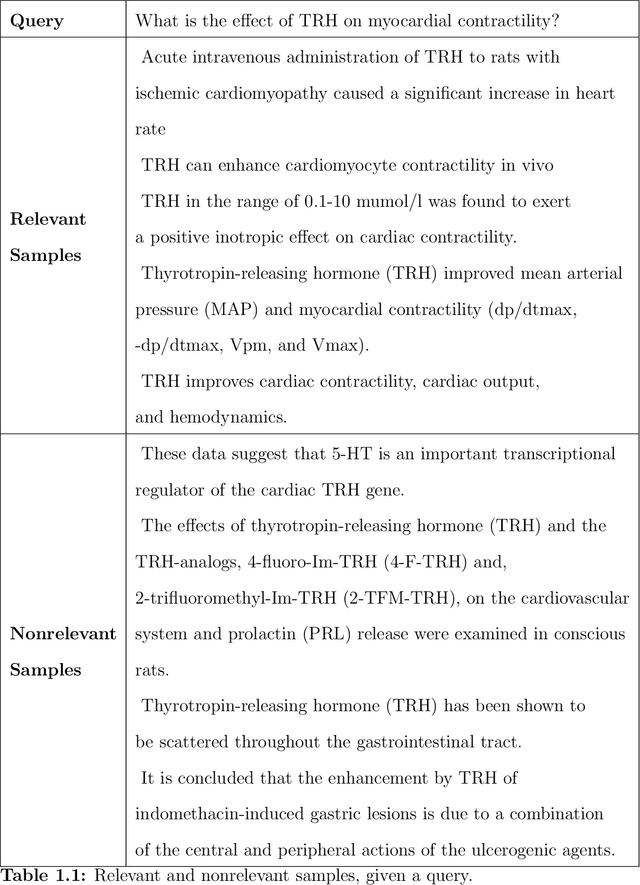
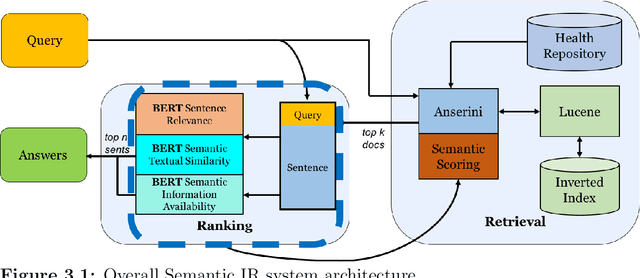
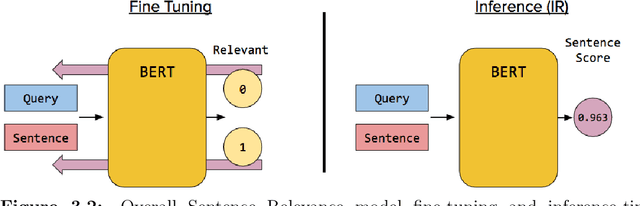
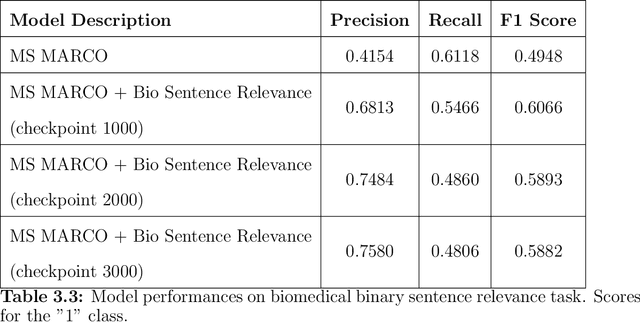
Information Retrieval (IR) is the task of obtaining pieces of data (such as documents) that are relevant to a particular query or need from a large repository of information. IR is a valuable component of several downstream Natural Language Processing (NLP) tasks. Practically, IR is at the heart of many widely-used technologies like search engines. While probabilistic ranking functions like the Okapi BM25 function have been utilized in IR systems since the 1970's, modern neural approaches pose certain advantages compared to their classical counterparts. In particular, the release of BERT (Bidirectional Encoder Representations from Transformers) has had a significant impact in the NLP community by demonstrating how the use of a Masked Language Model trained on a large corpus of data can improve a variety of downstream NLP tasks, including sentence classification and passage re-ranking. IR Systems are also important in the biomedical and clinical domains. Given the increasing amount of scientific literature across biomedical domain, the ability find answers to specific clinical queries from a repository of millions of articles is a matter of practical value to medical professionals. Moreover, there are domain-specific challenges present, including handling clinical jargon and evaluating the similarity or relatedness of various medical symptoms when determining the relevance between a query and a sentence. This work presents contributions to several aspects of the Biomedical Semantic Information Retrieval domain. First, it introduces Multi-Perspective Sentence Relevance, a novel methodology of utilizing BERT-based models for contextual IR. The system is evaluated using the BioASQ Biomedical IR Challenge. Finally, practical contributions in the form of a live IR system for medics and a proposed challenge on the Living Systematic Review clinical task are provided.
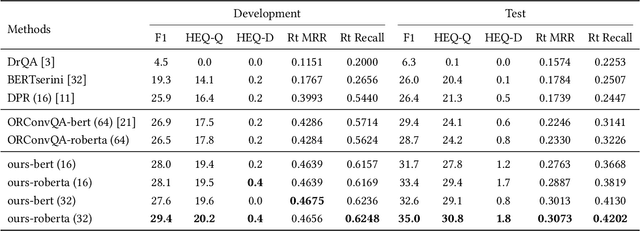
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
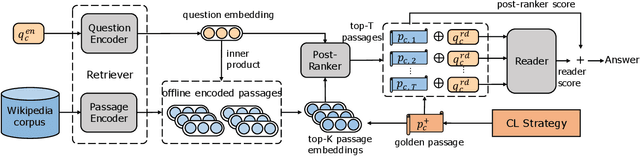
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
Information-theoretic User Interaction: Significant Inputs for Program Synthesis
Jun 22, 2020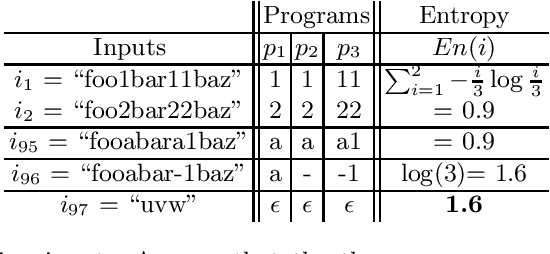
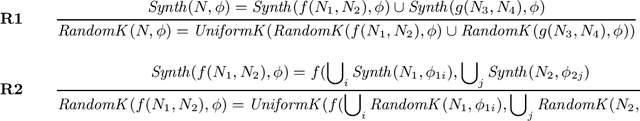
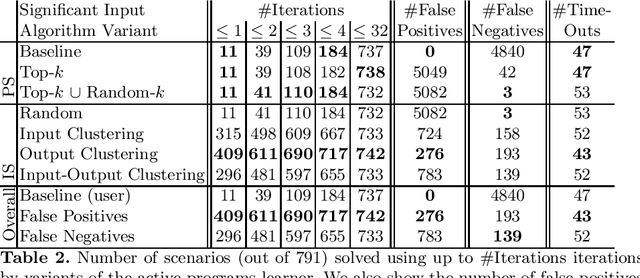
Programming-by-example technologies are being deployed in industrial products for real-time synthesis of various kinds of data transformations. These technologies rely on the user to provide few representative examples of the transformation task. Motivated by the need to find the most pertinent question to ask the user, in this paper, we introduce the {\em significant questions problem}, and show that it is hard in general. We then develop an information-theoretic greedy approach for solving the problem. We justify the greedy algorithm using the conditional entropy result, which informally says that the question that achieves the maximum information gain is the one that we know least about. In the context of interactive program synthesis, we use the above result to develop an {\em{active program learner}} that generates the significant inputs to pose as queries to the user in each iteration. The procedure requires extending a {\em{passive program learner}} to a {\em{sampling program learner}} that is able to sample candidate programs from the set of all consistent programs to enable estimation of information gain. It also uses clustering of inputs based on features in the inputs and the corresponding outputs to sample a small set of candidate significant inputs. Our active learner is able to tradeoff false negatives for false positives and converge in a small number of iterations on a real-world dataset of %around 800 string transformation tasks.
Less is More: Summary of Long Instructions is Better for Program Synthesis
Mar 16, 2022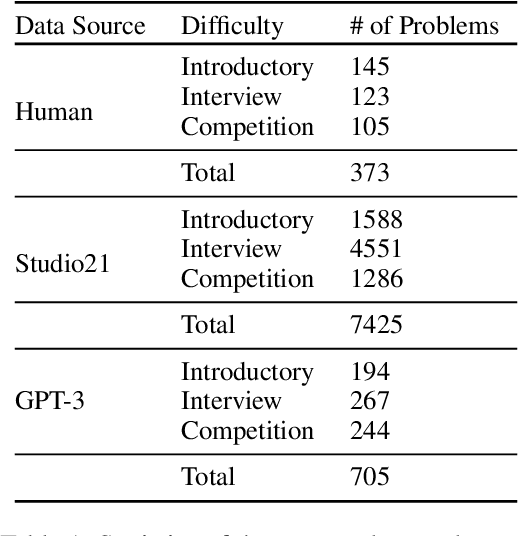

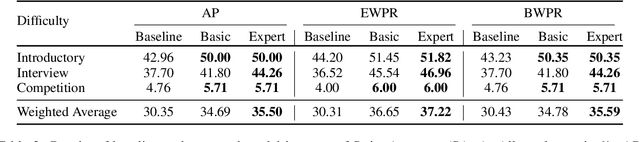
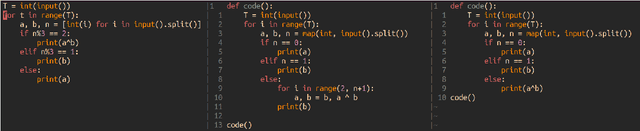
Despite the success of large pre-trained language models (LMs) such as Codex, they show below-par performance on the larger and more complicated programming related questions. We show that LMs benefit from the summarized version of complicated questions. Our findings show that superfluous information often present in problem description such as human characters, background stories, names (which are included to help humans in understanding a task) does not help models in understanding a task. To this extent, we create a meta-dataset from the frequently used APPS dataset for the program synthesis task. Our meta-dataset consists of human and synthesized summary of the long and complicated programming questions. Experimental results on Codex show that our proposed approach outperforms baseline by 8.13% on an average in terms of strict accuracy. Our analysis shows that summary significantly improve performance for introductory (9.86%) and interview (11.48%) related programming questions. However, it shows improvement by a small margin (~2%) for competitive programming questions, implying the scope for future research direction.
MUSCLE: Strengthening Semi-Supervised Learning Via Concurrent Unsupervised Learning Using Mutual Information Maximization
Nov 30, 2020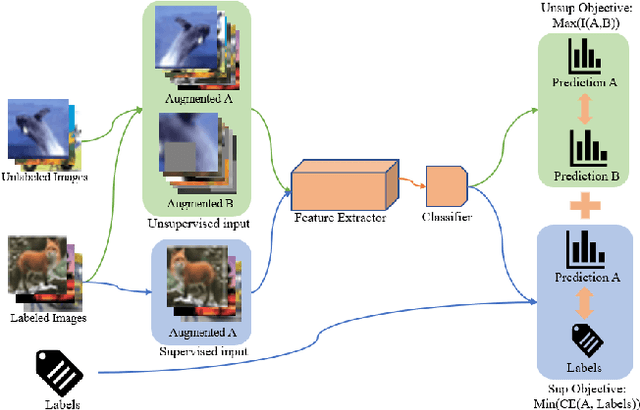
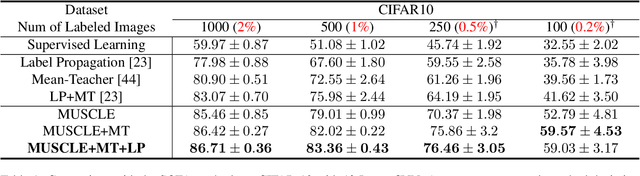

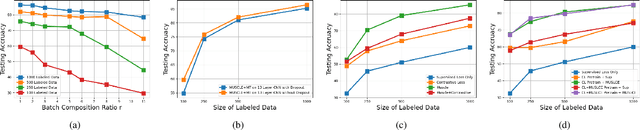
Deep neural networks are powerful, massively parameterized machine learning models that have been shown to perform well in supervised learning tasks. However, very large amounts of labeled data are usually needed to train deep neural networks. Several semi-supervised learning approaches have been proposed to train neural networks using smaller amounts of labeled data with a large amount of unlabeled data. The performance of these semi-supervised methods significantly degrades as the size of labeled data decreases. We introduce Mutual-information-based Unsupervised & Semi-supervised Concurrent LEarning (MUSCLE), a hybrid learning approach that uses mutual information to combine both unsupervised and semi-supervised learning. MUSCLE can be used as a stand-alone training scheme for neural networks, and can also be incorporated into other learning approaches. We show that the proposed hybrid model outperforms state of the art on several standard benchmarks, including CIFAR-10, CIFAR-100, and Mini-Imagenet. Furthermore, the performance gain consistently increases with the reduction in the amount of labeled data, as well as in the presence of bias. We also show that MUSCLE has the potential to boost the classification performance when used in the fine-tuning phase for a model pre-trained only on unlabeled data.
Hold On and Swipe: A Touch-Movement Based Continuous Authentication Schema based on Machine Learning
Jan 21, 2022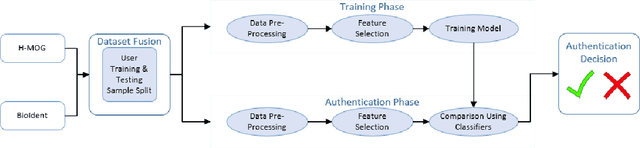
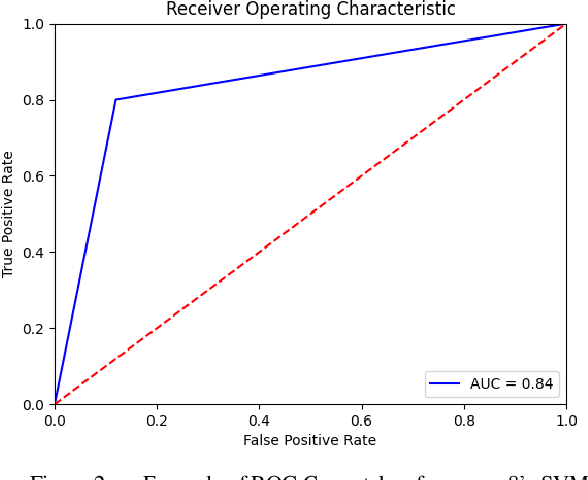
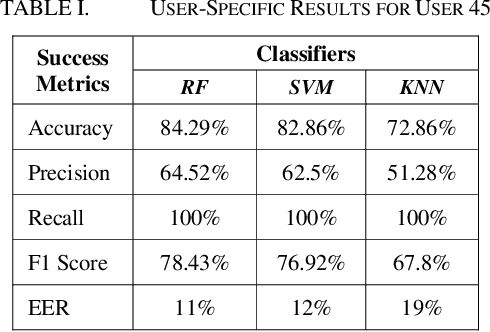
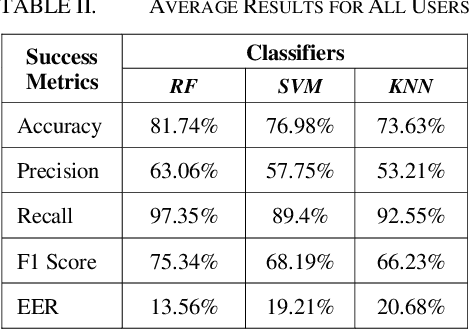
In recent years the amount of secure information being stored on mobile devices has grown exponentially. However, current security schemas for mobile devices such as physiological biometrics and passwords are not secure enough to protect this information. Behavioral biometrics have been heavily researched as a possible solution to this security deficiency for mobile devices. This study aims to contribute to this innovative research by evaluating the performance of a multimodal behavioral biometric based user authentication scheme using touch dynamics and phone movement. This study uses a fusion of two popular publicly available datasets the Hand Movement Orientation and Grasp dataset and the BioIdent dataset. This study evaluates our model performance using three common machine learning algorithms which are Random Forest Support Vector Machine and K-Nearest Neighbor reaching accuracy rates as high as 82% with each algorithm performing respectively for all success metrics reported.
Biomimetic Evaluation of an Underwater Soft Hand Through Deep Learning-based 3D Pose Reconstruction
Mar 16, 2022
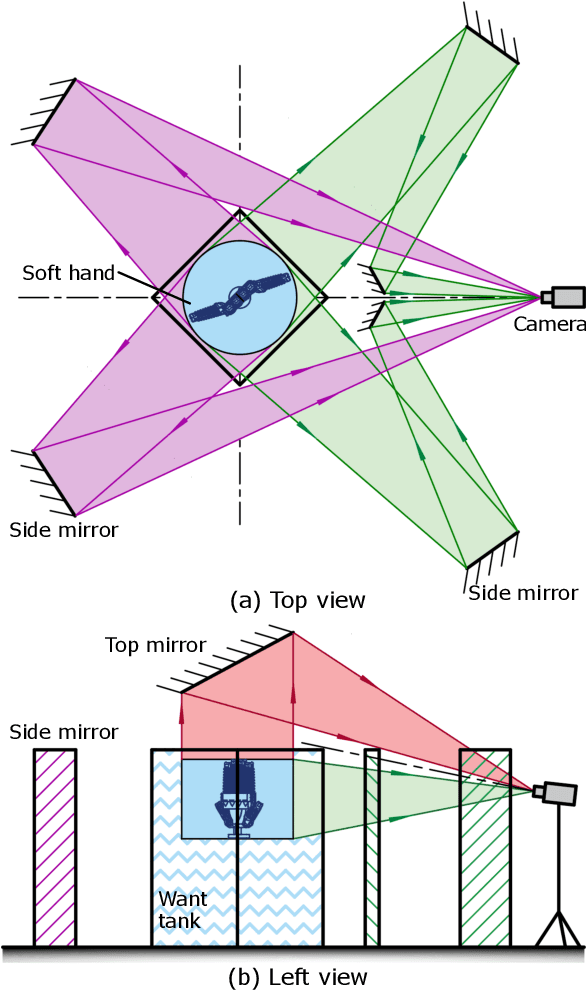
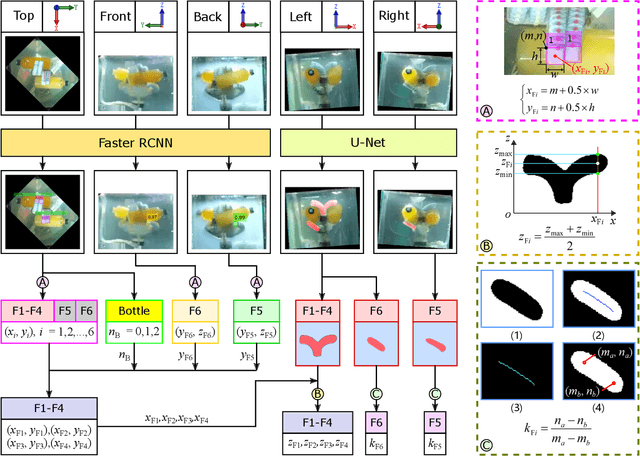
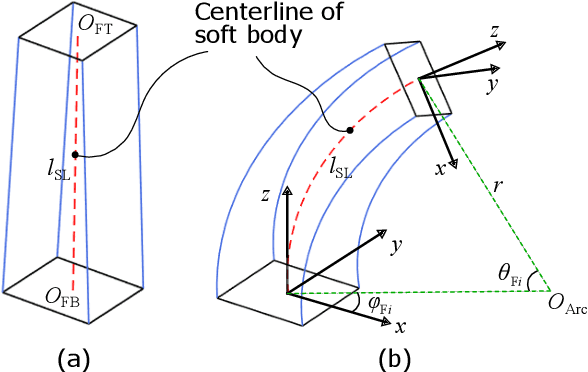
Soft robotic hand shows considerable promise for various grasping applications. However, the sensing and reconstruction of the robot pose will cause limitation during the design and fabrication. In this work, we present a novel 3D pose reconstruction approach to analyze the grasping motion of a bidirectional soft robotic hand using experiment videos. The images from top, front, back, left, right view were collected using an one-camera-multiple-mirror imaging device. The coordinate and orientation information of soft fingers are detected based on deep learning methods. Faster RCNN model is used to detect the position of fingertips, while U-Net model is applied to calculate the side boundary of the fingers. Based on the kinematics, the corresponding coordinate and orientation databases are established. The 3D pose reconstructed result presents a satisfactory performance and good accuracy. Using efficacy coefficient method, the finger contribution of the bending angle and distance between fingers of soft robot hand is analyzed by compared with that of human hand. The results show that the soft robot hand perform a human-like motion in both single-direction and bidirectional grasping.