 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visual Abductive Reasoning
Mar 26, 2022
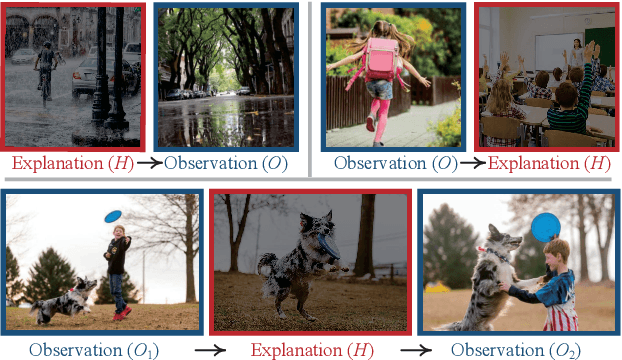
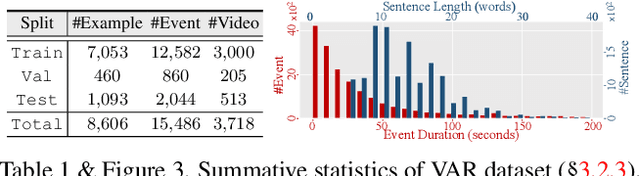
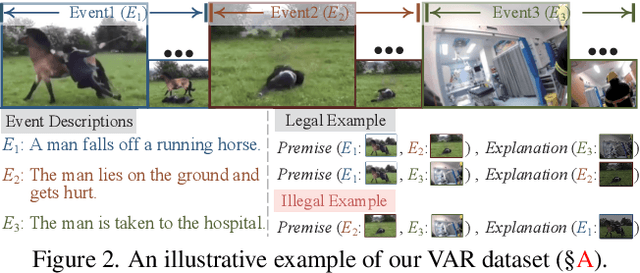
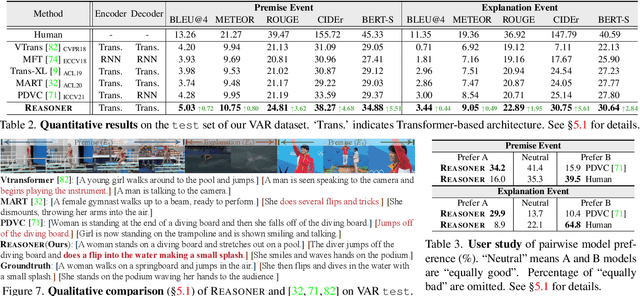
Abductive reasoning seeks the likeliest possible explanation for partial observations. Although abduction is frequently employed in human daily reasoning, it is rarely explored in computer vision literature. In this paper, we propose a new task and dataset, Visual Abductive Reasoning (VAR), for examining abductive reasoning ability of machine intelligence in everyday visual situations. Given an incomplete set of visual events, AI systems are required to not only describe what is observed, but also infer the hypothesis that can best explain the visual premise. Based on our large-scale VAR dataset, we devise a strong baseline model, Reasoner (causal-and-cascaded reasoning Transformer). First, to capture the causal structure of the observations, a contextualized directional position embedding strategy is adopted in the encoder, that yields discriminative representations for the premise and hypothesis. Then, multiple decoders are cascaded to generate and progressively refine the premise and hypothesis sentences. The prediction scores of the sentences are used to guide cross-sentence information flow in the cascaded reasoning procedure. Our VAR benchmarking results show that Reasoner surpasses many famous video-language models, while still being far behind human performance. This work is expected to foster future efforts in the reasoning-beyond-observation paradigm.
Target Detection within Nonhomogeneous Clutter via Total Bregman Divergence-Based Matrix Information Geometry Detectors
Dec 27, 2020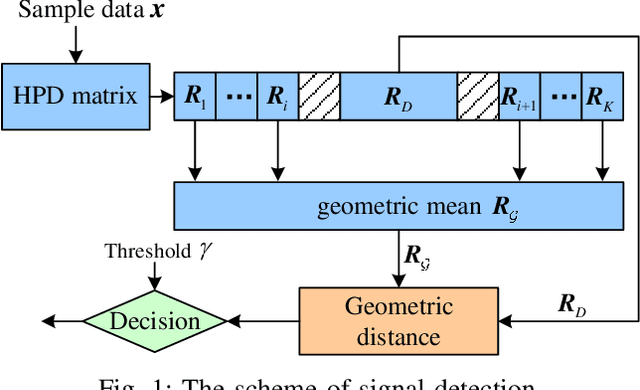
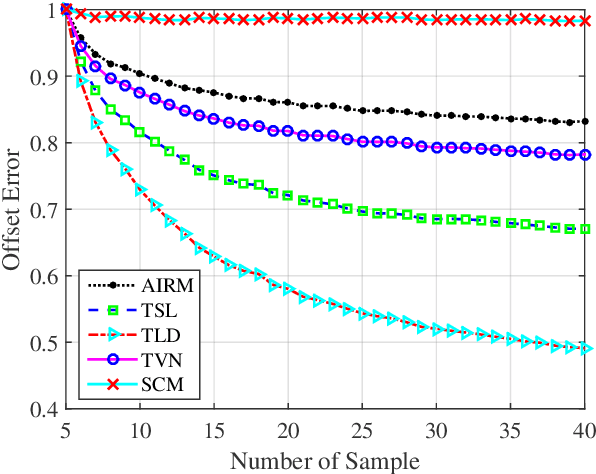
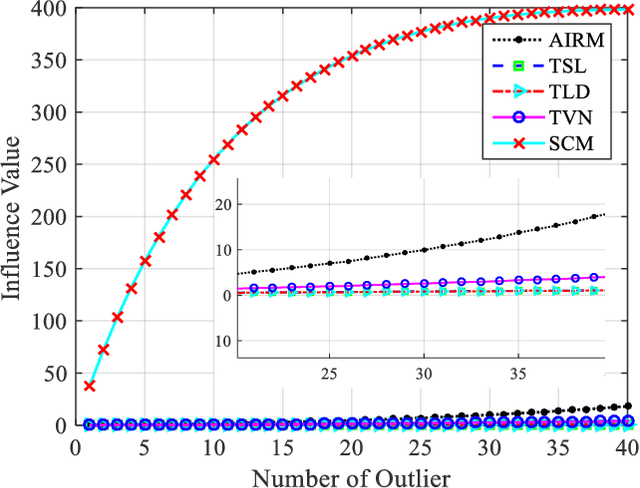
Information divergences are commonly used to measure the dissimilarity of two elements on a statistical manifold. Differentiable manifolds endowed with different divergences may possess different geometric properties, which can result in totally different performances in many practical applications. In this paper, we propose a total Bregman divergence-based matrix information geometry (TBD-MIG) detector and apply it to detect targets emerged into nonhomogeneous clutter. In particular, each sample data is assumed to be modeled as a Hermitian positive-definite (HPD) matrix and the clutter covariance matrix is estimated by the TBD mean of a set of secondary HPD matrices. We then reformulate the problem of signal detection as discriminating two points on the HPD matrix manifold. Three TBD-MIG detectors, referred to as the total square loss, the total log-determinant and the total von Neumann MIG detectors, are proposed, and they can achieve great performances due to their power of discrimination and robustness to interferences. Simulations show the advantage of the proposed TBD-MIG detectors in comparison with the geometric detector using an affine invariant Riemannian metric as well as the adaptive matched filter in nonhomogeneous clutter.
Automated Surface Texture Analysis via Discrete Cosine Transform and Discrete Wavelet Transform
Apr 12, 2022


Surface roughness and texture are critical to the functional performance of engineering components. The ability to analyze roughness and texture effectively and efficiently is much needed to ensure surface quality in many surface generation processes, such as machining, surface mechanical treatment, etc. Discrete Wavelet Transform (DWT) and Discrete Cosine Transform (DCT) are two commonly used signal decomposition tools for surface roughness and texture analysis. Both methods require selecting a threshold to decompose a given surface into its three main components: form, waviness, and roughness. However, although DWT and DCT are part of the ISO surface finish standards, there exists no systematic guidance on how to compute these thresholds, and they are often manually selected on case by case basis. This makes utilizing these methods for studying surfaces dependent on the user's judgment and limits their automation potential. Therefore, we present two automatic threshold selection algorithms based on information theory and signal energy. We use machine learning to validate the success of our algorithms both using simulated surfaces as well as digital microscopy images of machined surfaces. Specifically, we generate feature vectors for each surface area or profile and apply supervised classification. Comparing our results with the heuristic threshold selection approach shows good agreement with mean accuracies as high as 95\%. We also compare our results with Gaussian filtering (GF) and show that while GF results for areas can yield slightly higher accuracies, our results outperform GF for surface profiles. We further show that our automatic threshold selection has significant advantages in terms of computational time as evidenced by decreasing the number of mode computations by an order of magnitude compared to the heuristic thresholding for DCT.
Speech and the n-Back task as a lens into depression. How combining both may allow us to isolate different core symptoms of depression
Mar 30, 2022
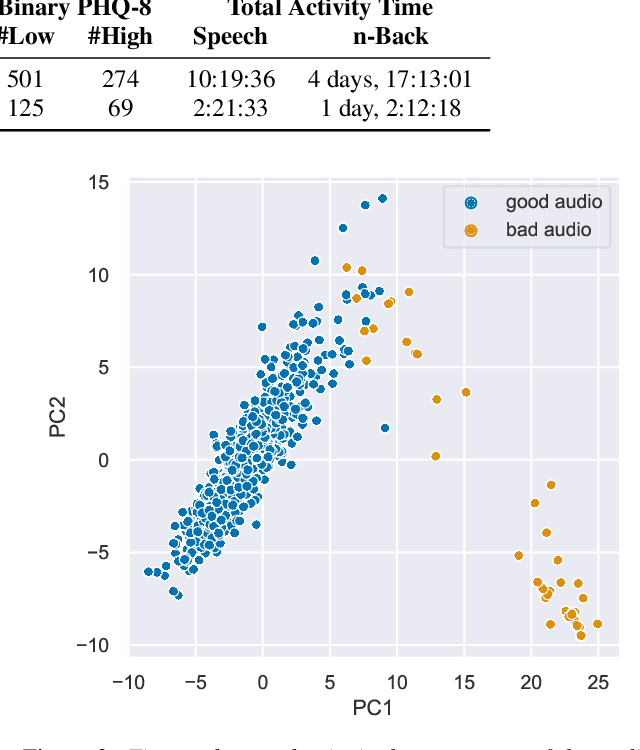
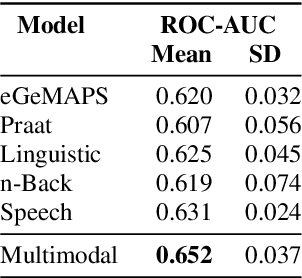
Embedded in any speech signal is a rich combination of cognitive, neuromuscular and physiological information. This richness makes speech a powerful signal in relation to a range of different health conditions, including major depressive disorders (MDD). One pivotal issue in speech-depression research is the assumption that depressive severity is the dominant measurable effect. However, given the heterogeneous clinical profile of MDD, it may actually be the case that speech alterations are more strongly associated with subsets of key depression symptoms. This paper presents strong evidence in support of this argument. First, we present a novel large, cross-sectional, multi-modal dataset collected at Thymia. We then present a set of machine learning experiments that demonstrate that combining speech with features from an n-Back working memory assessment improves classifier performance when predicting the popular eight-item Patient Health Questionnaire depression scale (PHQ-8). Finally, we present a set of experiments that highlight the association between different speech and n-Back markers at the PHQ-8 item level. Specifically, we observe that somatic and psychomotor symptoms are more strongly associated with n-Back performance scores, whilst the other items: anhedonia, depressed mood, change in appetite, feelings of worthlessness and trouble concentrating are more strongly associated with speech changes.
Constrained RIS Phase Profile Optimization and Time Sharing for Near-field Localization
Mar 14, 2022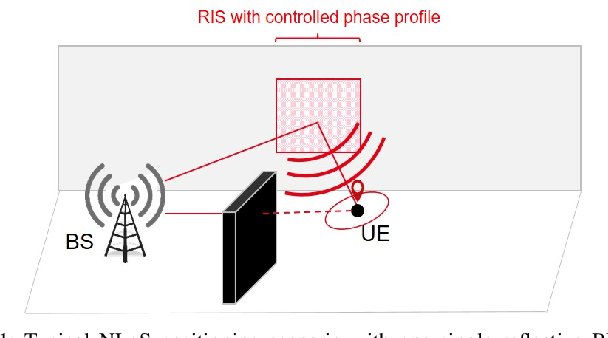
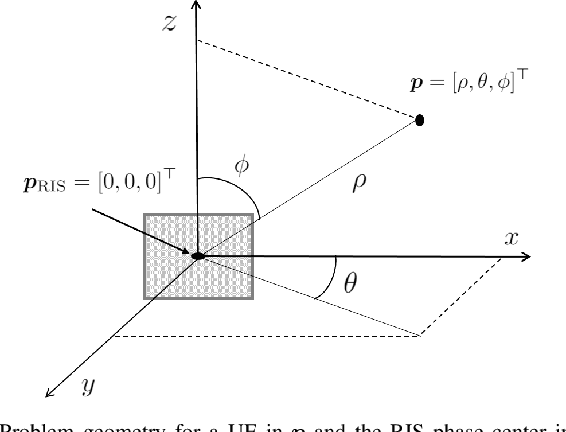
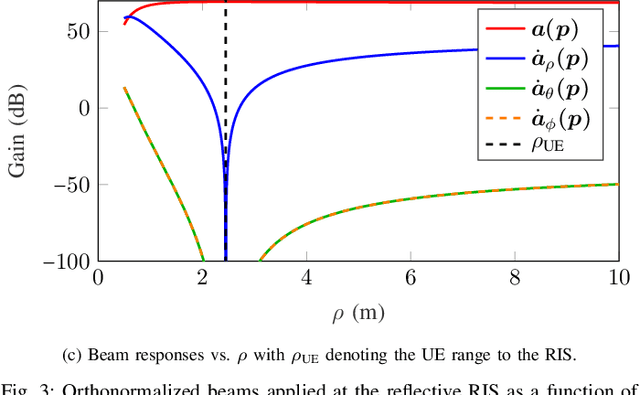
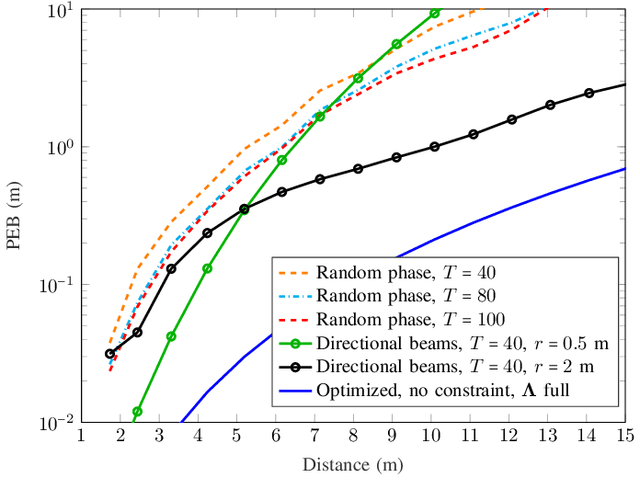
The rising concept of reconfigurable intelligent surface (RIS) has promising potential for Beyond 5G localization applications. We herein investigate different phase profile designs at a reflective RIS, which enable non-line-of-sight positioning in nearfield from downlink single antenna transmissions. We first derive the closed-form expressions of the corresponding Fisher information matrix (FIM) and position error bound (PEB). Accordingly, we then propose a new localization-optimal phase profile design, assuming prior knowledge of the user equipment location. Numerical simulations in a canonical scenario show that our proposal outperforms conventional RIS random and directional beam codebook designs in terms of PEB. We also illustrate the four beams allocated at the RIS (i.e., one directional beam, along with its derivatives with respect to space dimensions) and show how their relative weights according to the optimal solution can be practically implemented through time sharing (i.e., considering feasible beams sequentially).
Low-rank features based double transformation matrices learning for image classification
Jan 28, 2022Linear regression is a supervised method that has been widely used in classification tasks. In order to apply linear regression to classification tasks, a technique for relaxing regression targets was proposed. However, methods based on this technique ignore the pressure on a single transformation matrix due to the complex information contained in the data. A single transformation matrix in this case is too strict to provide a flexible projection, thus it is necessary to adopt relaxation on transformation matrix. This paper proposes a double transformation matrices learning method based on latent low-rank feature extraction. The core idea is to use double transformation matrices for relaxation, and jointly projecting the learned principal and salient features from two directions into the label space, which can share the pressure of a single transformation matrix. Firstly, the low-rank features are learned by the latent low rank representation (LatLRR) method which processes the original data from two directions. In this process, sparse noise is also separated, which alleviates its interference on projection learning to some extent. Then, two transformation matrices are introduced to process the two features separately, and the information useful for the classification is extracted. Finally, the two transformation matrices can be easily obtained by alternate optimization methods. Through such processing, even when a large amount of redundant information is contained in samples, our method can also obtain projection results that are easy to classify. Experiments on multiple data sets demonstrate the effectiveness of our approach for classification, especially for complex scenarios.
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
Feb 03, 2022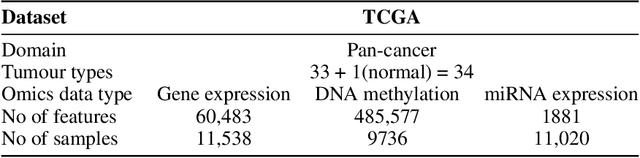
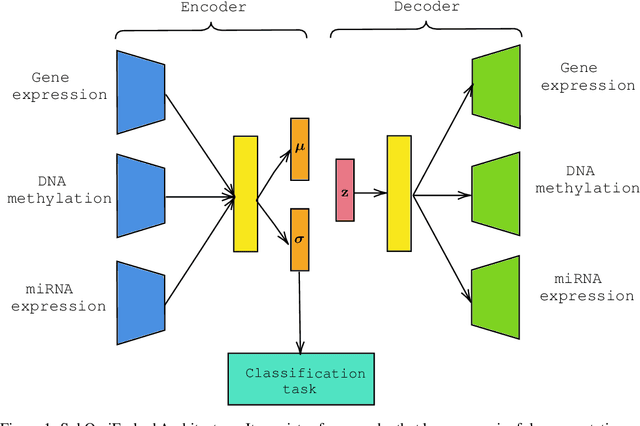

For personalized medicines, very crucial intrinsic information is present in high dimensional omics data which is difficult to capture due to the large number of molecular features and small number of available samples. Different types of omics data show various aspects of samples. Integration and analysis of multi-omics data give us a broad view of tumours, which can improve clinical decision making. Omics data, mainly DNA methylation and gene expression profiles are usually high dimensional data with a lot of molecular features. In recent years, variational autoencoders (VAE) have been extensively used in embedding image and text data into lower dimensional latent spaces. In our project, we extend the idea of using a VAE model for low dimensional latent space extraction with the self-supervised learning technique of feature subsetting. With VAEs, the key idea is to make the model learn meaningful representations from different types of omics data, which could then be used for downstream tasks such as cancer type classification. The main goals are to overcome the curse of dimensionality and integrate methylation and expression data to combine information about different aspects of same tissue samples, and hopefully extract biologically relevant features. Our extension involves training encoder and decoder to reconstruct the data from just a subset of it. By doing this, we force the model to encode most important information in the latent representation. We also added an identity to the subsets so that the model knows which subset is being fed into it during training and testing. We experimented with our approach and found that SubOmiEmbed produces comparable results to the baseline OmiEmbed with a much smaller network and by using just a subset of the data. This work can be improved to integrate mutation-based genomic data as well.
Improving Fraud detection via Hierarchical Attention-based Graph Neural Network
Feb 12, 2022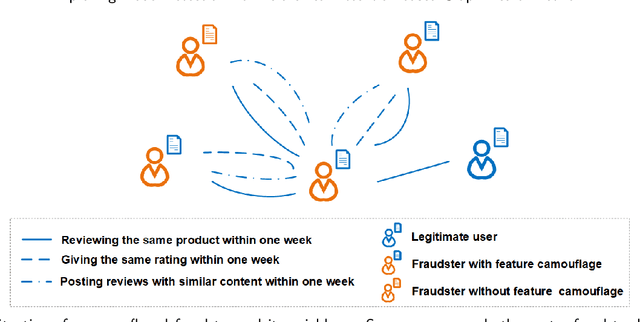
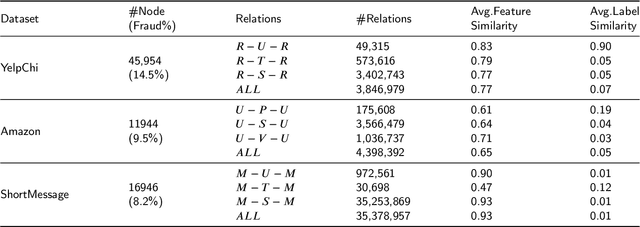
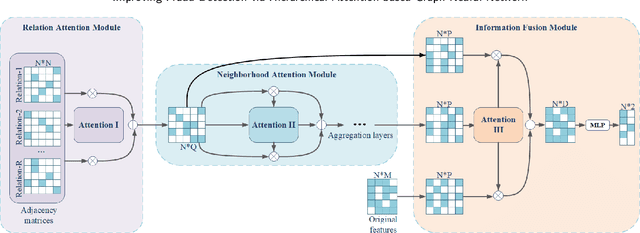
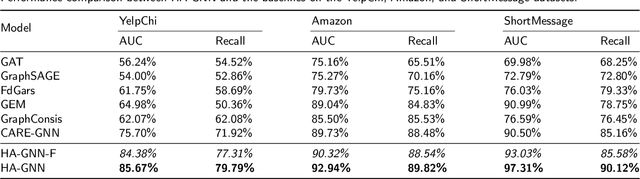
Graph neural networks (GNN) have emerged as a powerful tool for fraud detection tasks, where fraudulent nodes are identified by aggregating neighbor information via different relations. To get around such detection, crafty fraudsters resort to camouflage via connecting to legitimate users (i.e., relation camouflage) or providing seemingly legitimate feedbacks (i.e., feature camouflage). A wide-spread solution reinforces the GNN aggregation process with neighbor selectors according to original node features. This method may carry limitations when identifying fraudsters not only with the relation camouflage, but with the feature camouflage making them hard to distinguish from their legitimate neighbors. In this paper, we propose a Hierarchical Attention-based Graph Neural Network (HA-GNN) for fraud detection, which incorporates weighted adjacency matrices across different relations against camouflage. This is motivated in the Relational Density Theory and is exploited for forming a hierarchical attention-based graph neural network. Specifically, we design a relation attention module to reflect the tie strength between two nodes, while a neighborhood attention module to capture the long-range structural affinity associated with the graph. We generate node embeddings by aggregating information from local/long-range structures and original node features. Experiments on three real-world datasets demonstrate the effectiveness of our model over the state-of-the-arts.
A Bayesian approach to translators' reliability assessment
Apr 12, 2022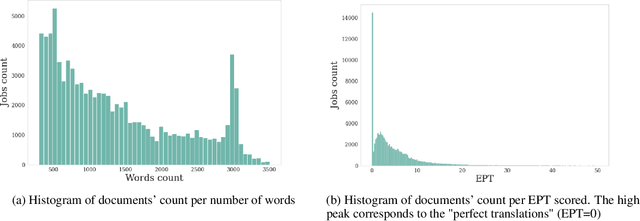
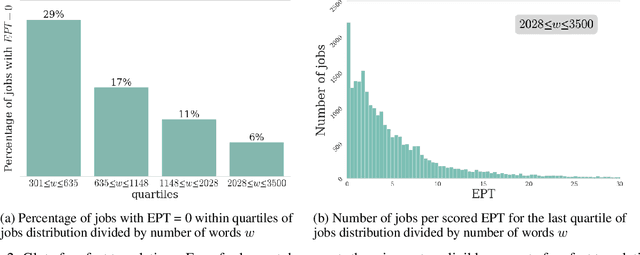
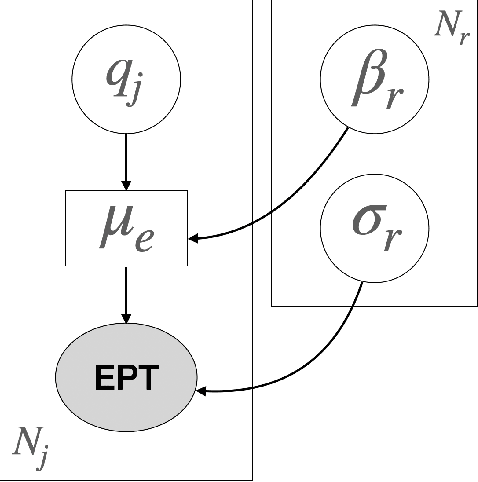
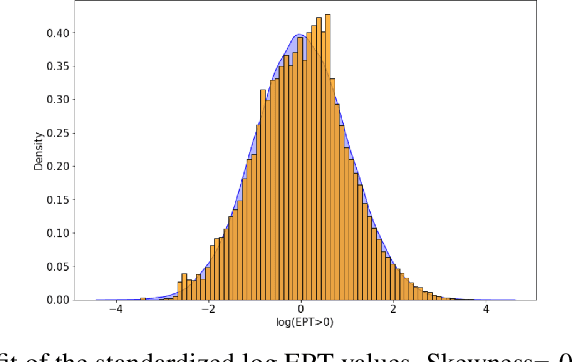
Translation Quality Assessment (TQA) is a process conducted by human translators and is widely used, both for estimating the performance of (increasingly used) Machine Translation, and for finding an agreement between translation providers and their customers. While translation scholars are aware of the importance of having a reliable way to conduct the TQA process, it seems that there is limited literature that tackles the issue of reliability with a quantitative approach. In this work, we consider the TQA as a complex process from the point of view of physics of complex systems and approach the reliability issue from the Bayesian paradigm. Using a dataset of translation quality evaluations (in the form of error annotations), produced entirely by the Professional Translation Service Provider Translated SRL, we compare two Bayesian models that parameterise the following features involved in the TQA process: the translation difficulty, the characteristics of the translators involved in producing the translation, and of those assessing its quality - the reviewers. We validate the models in an unsupervised setting and show that it is possible to get meaningful insights into translators even with just one review per translation; subsequently, we extract information like translators' skills and reviewers' strictness, as well as their consistency in their respective roles. Using this, we show that the reliability of reviewers cannot be taken for granted even in the case of expert translators: a translator's expertise can induce a cognitive bias when reviewing a translation produced by another translator. The most expert translators, however, are characterised by the highest level of consistency, both in translating and in assessing the translation quality.
A two-step approach to leverage contextual data: speech recognition in air-traffic communications
Feb 08, 2022

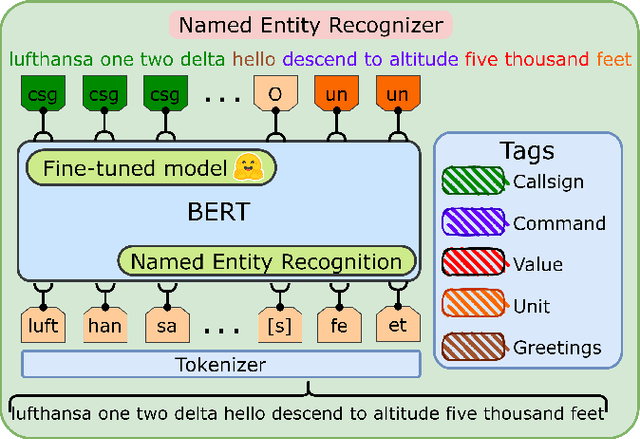
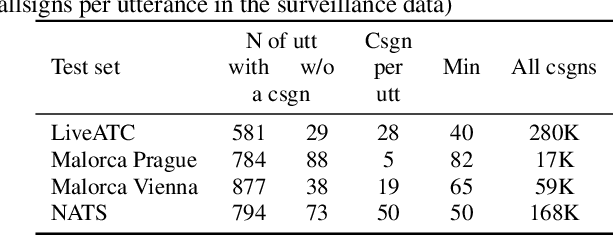
Automatic Speech Recognition (ASR), as the assistance of speech communication between pilots and air-traffic controllers, can significantly reduce the complexity of the task and increase the reliability of transmitted information. ASR application can lead to a lower number of incidents caused by misunderstanding and improve air traffic management (ATM) efficiency. Evidently, high accuracy predictions, especially, of key information, i.e., callsigns and commands, are required to minimize the risk of errors. We prove that combining the benefits of ASR and Natural Language Processing (NLP) methods to make use of surveillance data (i.e. additional modality) helps to considerably improve the recognition of callsigns (named entity). In this paper, we investigate a two-step callsign boosting approach: (1) at the 1 step (ASR), weights of probable callsign n-grams are reduced in G.fst and/or in the decoding FST (lattices), (2) at the 2 step (NLP), callsigns extracted from the improved recognition outputs with Named Entity Recognition (NER) are correlated with the surveillance data to select the most suitable one. Boosting callsign n-grams with the combination of ASR and NLP methods eventually leads up to 53.7% of an absolute, or 60.4% of a relative, improvement in callsign recognition.
* 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv admin note: text overlap with arXiv:2108.12156