 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Efficient Single Image Dehazing and Desnowing
Apr 19, 2022
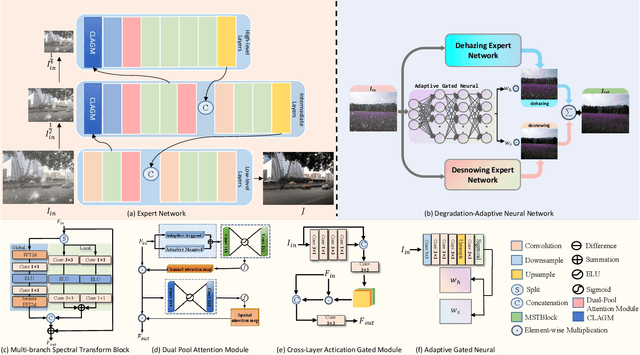
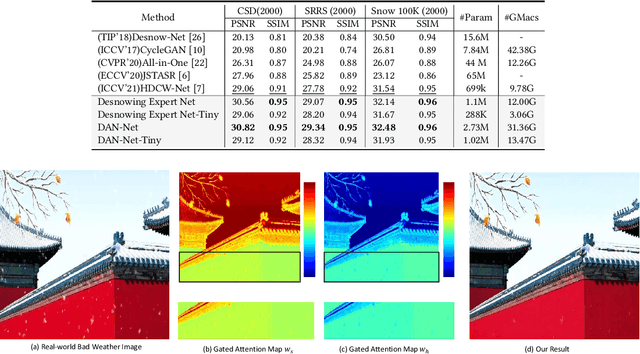

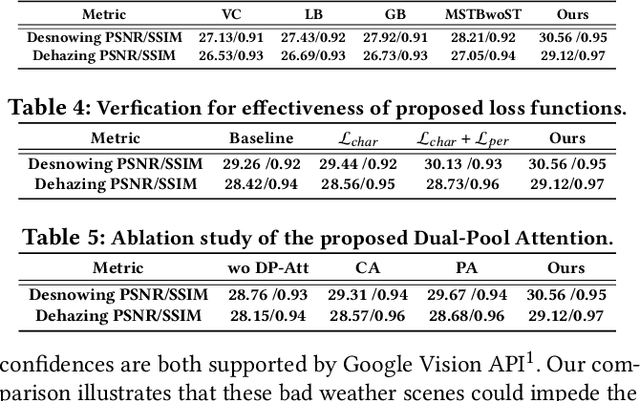
Removing adverse weather conditions like rain, fog, and snow from images is a challenging problem. Although the current recovery algorithms targeting a specific condition have made impressive progress, it is not flexible enough to deal with various degradation types. We propose an efficient and compact image restoration network named DAN-Net (Degradation-Adaptive Neural Network) to address this problem, which consists of multiple compact expert networks with one adaptive gated neural. A single expert network efficiently addresses specific degradation in nasty winter scenes relying on the compact architecture and three novel components. Based on the Mixture of Experts strategy, DAN-Net captures degradation information from each input image to adaptively modulate the outputs of task-specific expert networks to remove various adverse winter weather conditions. Specifically, it adopts a lightweight Adaptive Gated Neural Network to estimate gated attention maps of the input image, while different task-specific experts with the same topology are jointly dispatched to process the degraded image. Such novel image restoration pipeline handles different types of severe weather scenes effectively and efficiently. It also enjoys the benefit of coordinate boosting in which the whole network outperforms each expert trained without coordination. Extensive experiments demonstrate that the presented manner outperforms the state-of-the-art single-task methods on image quality and has better inference efficiency. Furthermore, we have collected the first real-world winter scenes dataset to evaluate winter image restoration methods, which contains various hazy and snowy images snapped in winter. Both the dataset and source code will be publicly available.
Novel ensemble collaboration method for dynamic scheduling problems
Mar 27, 2022
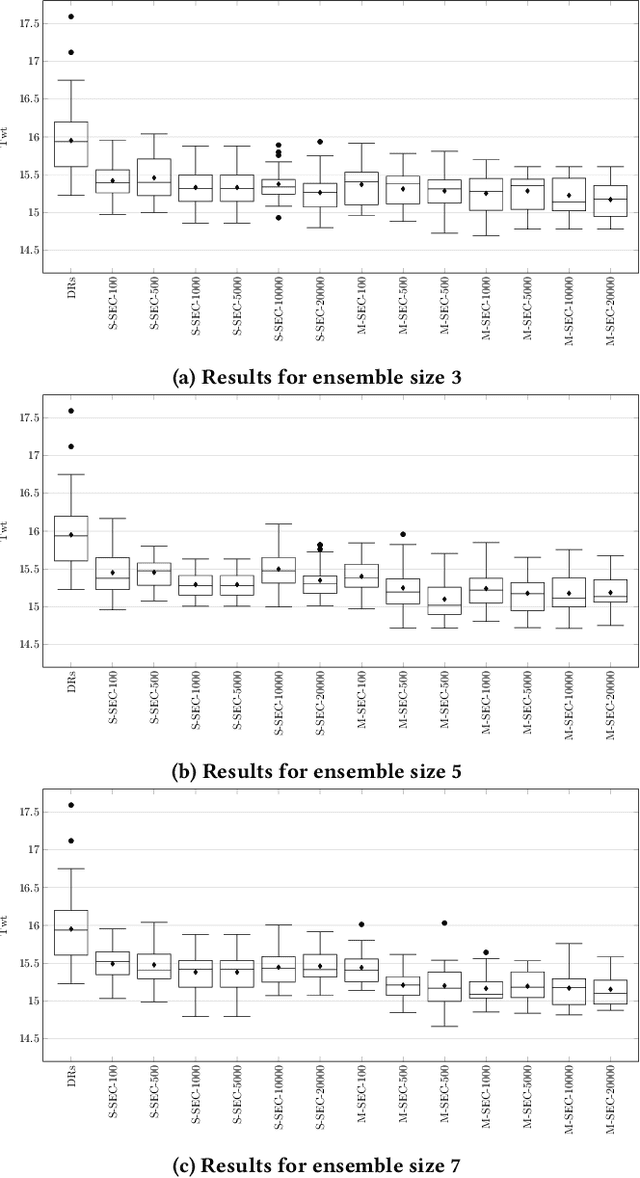
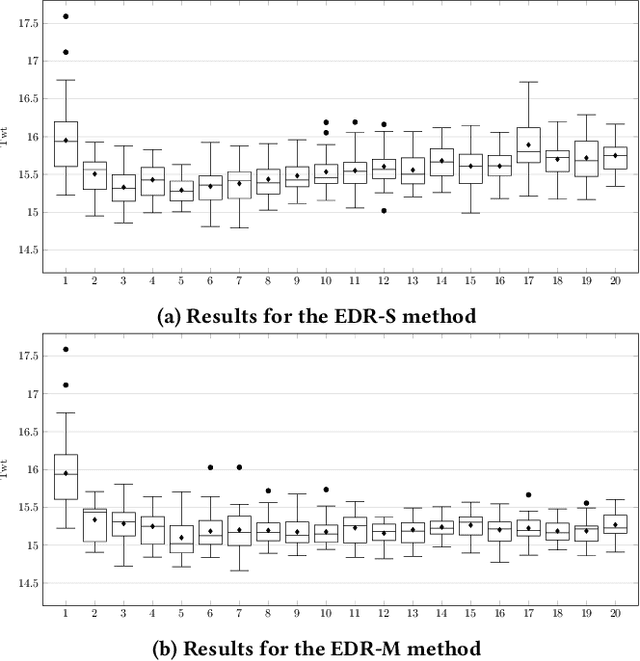
Dynamic scheduling problems are important optimisation problems with many real-world applications. Since in dynamic scheduling not all information is available at the start, such problems are usually solved by dispatching rules (DRs), which create the schedule as the system executes. Recently, DRs have been successfully developed using genetic programming. However, a single DR may not efficiently solve different problem instances. Therefore, much research has focused on using DRs collaboratively by forming ensembles. In this paper, a novel ensemble collaboration method for dynamic scheduling is proposed. In this method, DRs are applied independently at each decision point to create a simulation of the schedule for all currently released jobs. Based on these simulations, it is determined which DR makes the best decision and that decision is applied. The results show that the ensembles easily outperform individual DRs for different ensemble sizes. Moreover, the results suggest that it is relatively easy to create good ensembles from a set of independently evolved DRs.
A Two-student Learning Framework for Mixed Supervised Target Sound Detection
Apr 05, 2022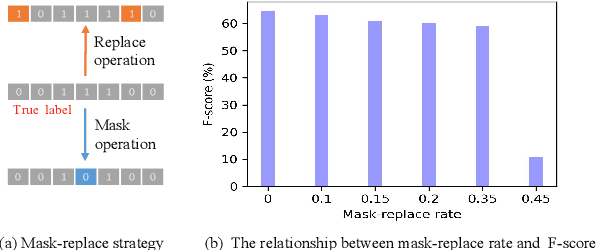
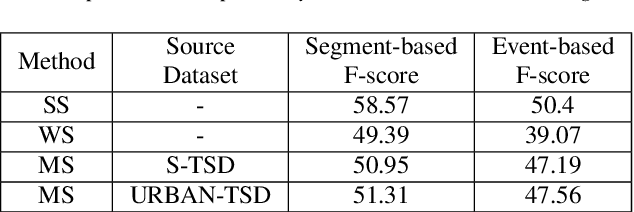
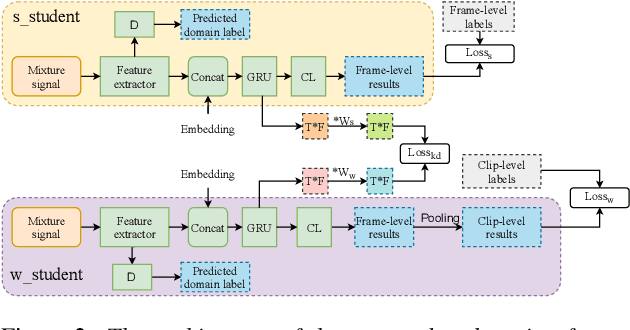
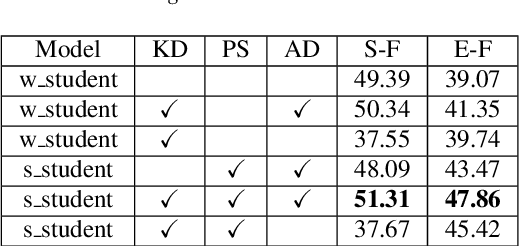
Target sound detection (TSD) aims to detect the target sound from mixture audio given the reference information. Previous work shows that a good detection performance relies on fully-annotated data. However, collecting fully-annotated data is labor-extensive. Therefore, we consider TSD with mixed supervision, which learns novel categories (target domain) using weak annotations with the help of full annotations of existing base categories (source domain). We propose a novel two-student learning framework, which contains two mutual helping student models ($\mathit{s\_student}$ and $\mathit{w\_student}$) that learn from fully- and weakly-annotated datasets, respectively. Specifically, we first propose a frame-level knowledge distillation strategy to transfer the class-agnostic knowledge from $\mathit{s\_student}$ to $\mathit{w\_student}$. After that, a pseudo supervised (PS) training is designed to transfer the knowledge from $\mathit{w\_student}$ to $\mathit{s\_student}$. Lastly, an adversarial training strategy is proposed, which aims to align the data distribution between source and target domains. To evaluate our method, we build three TSD datasets based on UrbanSound and Audioset. Experimental results show that our methods offer about 8\% improvement in event-based F score.
Webpage Segmentation for Extracting Images and Their Surrounding Contextual Information
May 18, 2020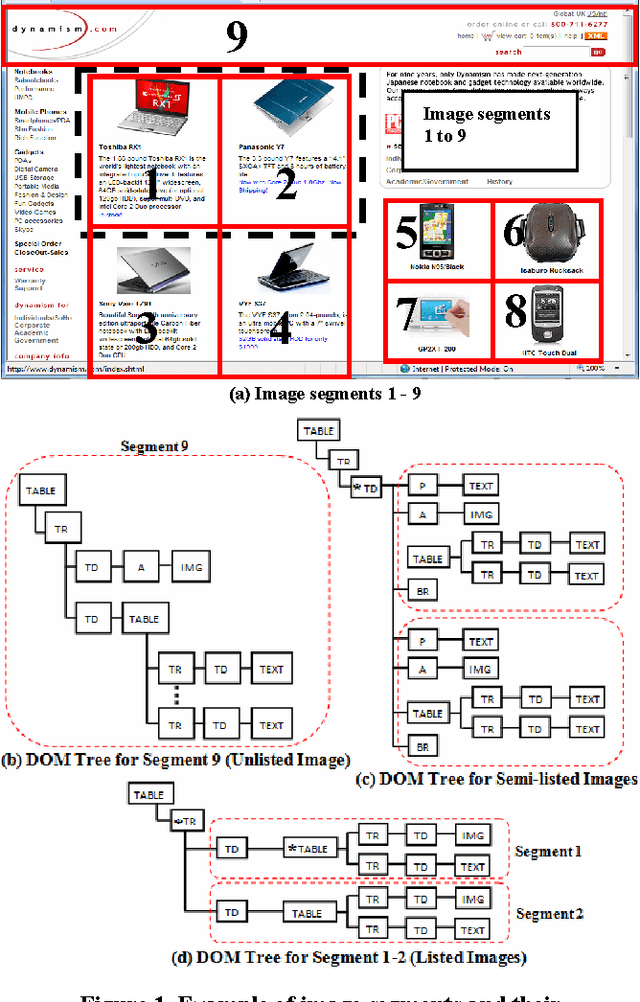
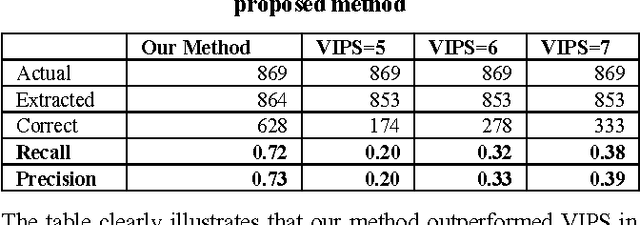
Web images come in hand with valuable contextual information. Although this information has long been mined for various uses such as image annotation, clustering of images, inference of image semantic content, etc., insufficient attention has been given to address issues in mining this contextual information. In this paper, we propose a webpage segmentation algorithm targeting the extraction of web images and their contextual information based on their characteristics as they appear on webpages. We conducted a user study to obtain a human-labeled dataset to validate the effectiveness of our method and experiments demonstrated that our method can achieve better results compared to an existing segmentation algorithm.
Multi-level Cross-view Contrastive Learning for Knowledge-aware Recommender System
Apr 19, 2022



Knowledge graph (KG) plays an increasingly important role in recommender systems. Recently, graph neural networks (GNNs) based model has gradually become the theme of knowledge-aware recommendation (KGR). However, there is a natural deficiency for GNN-based KGR models, that is, the sparse supervised signal problem, which may make their actual performance drop to some extent. Inspired by the recent success of contrastive learning in mining supervised signals from data itself, in this paper, we focus on exploring the contrastive learning in KG-aware recommendation and propose a novel multi-level cross-view contrastive learning mechanism, named MCCLK. Different from traditional contrastive learning methods which generate two graph views by uniform data augmentation schemes such as corruption or dropping, we comprehensively consider three different graph views for KG-aware recommendation, including global-level structural view, local-level collaborative and semantic views. Specifically, we consider the user-item graph as a collaborative view, the item-entity graph as a semantic view, and the user-item-entity graph as a structural view. MCCLK hence performs contrastive learning across three views on both local and global levels, mining comprehensive graph feature and structure information in a self-supervised manner. Besides, in semantic view, a k-Nearest-Neighbor (kNN) item-item semantic graph construction module is proposed, to capture the important item-item semantic relation which is usually ignored by previous work. Extensive experiments conducted on three benchmark datasets show the superior performance of our proposed method over the state-of-the-arts. The implementations are available at: https://github.com/CCIIPLab/MCCLK.
Leaderless Swarm Formation Control: From Global Specifications to Local Control Laws
Apr 09, 2022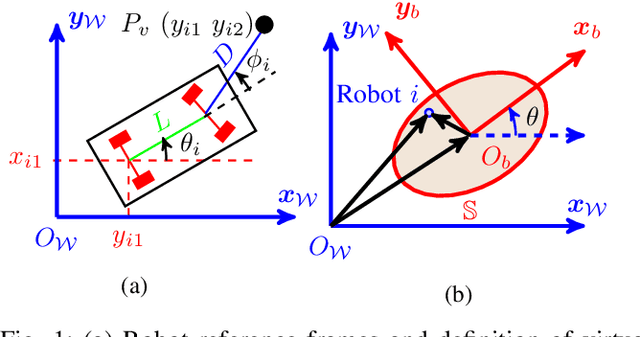
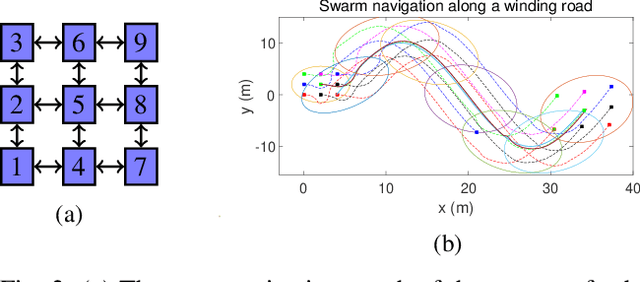
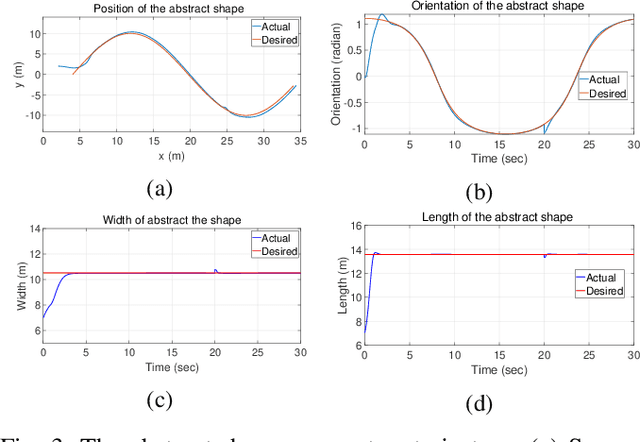
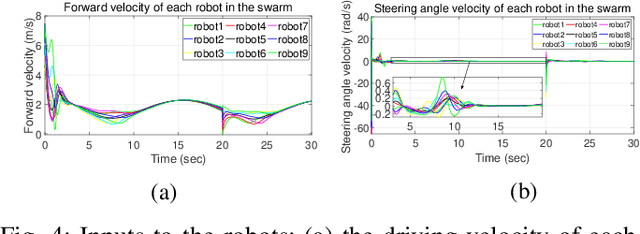
This paper introduces a distributed leaderless swarm formation control framework to address the problem of collectively driving a swarm of robots to track a time-varying formation. The swarm's formation is captured by the trajectory of an abstract shape that circumscribes the convex hull of robots' positions and is independent of the number of robots and their ordering in the swarm. For each robot in the swarm, given global specifications in terms of the trajectory of the abstract shape parameters, the proposed framework synthesizes a control law that steers the swarm to track the desired formation using the information available at the robot's local neighbors. For this purpose, we generate a suitable local reference trajectory that the robot controller tracks by solving the input-output linearization problem. Here, we select the swarm output to be the parameters of the abstract shape. For this purpose, we design a dynamic average consensus estimator to estimate the abstract shape parameters. The abstract shape parameters are used as the swarm state feedback to generate a suitable robot trajectory. We demonstrate the effectiveness and robustness of the proposed control framework by providing the simulation of coordinated collective navigation of a group of car-like robots in the presence of robots and communication link failures.
ASQA: Factoid Questions Meet Long-Form Answers
Apr 12, 2022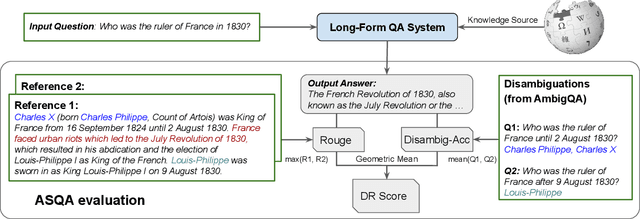

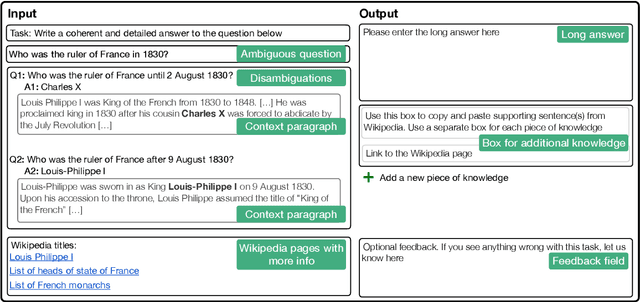
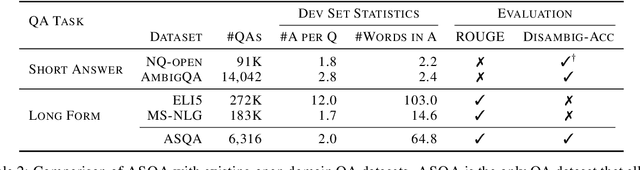
An abundance of datasets and availability of reliable evaluation metrics have resulted in strong progress in factoid question answering (QA). This progress, however, does not easily transfer to the task of long-form QA, where the goal is to answer questions that require in-depth explanations. The hurdles include (i) a lack of high-quality data, and (ii) the absence of a well-defined notion of the answer's quality. In this work, we address these problems by (i) releasing a novel dataset and a task that we call ASQA (Answer Summaries for Questions which are Ambiguous); and (ii) proposing a reliable metric for measuring performance on ASQA. Our task focuses on factoid questions that are ambiguous, that is, have different correct answers depending on interpretation. Answers to ambiguous questions should synthesize factual information from multiple sources into a long-form summary that resolves the ambiguity. In contrast to existing long-form QA tasks (such as ELI5), ASQA admits a clear notion of correctness: a user faced with a good summary should be able to answer different interpretations of the original ambiguous question. We use this notion of correctness to define an automated metric of performance for ASQA. Our analysis demonstrates an agreement between this metric and human judgments, and reveals a considerable gap between human performance and strong baselines.
BARCOR: Towards A Unified Framework for Conversational Recommendation Systems
Mar 27, 2022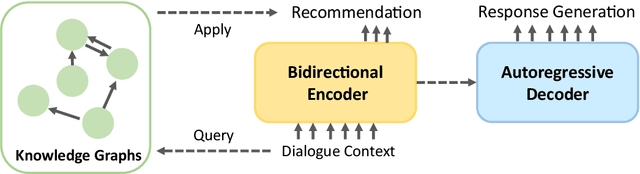

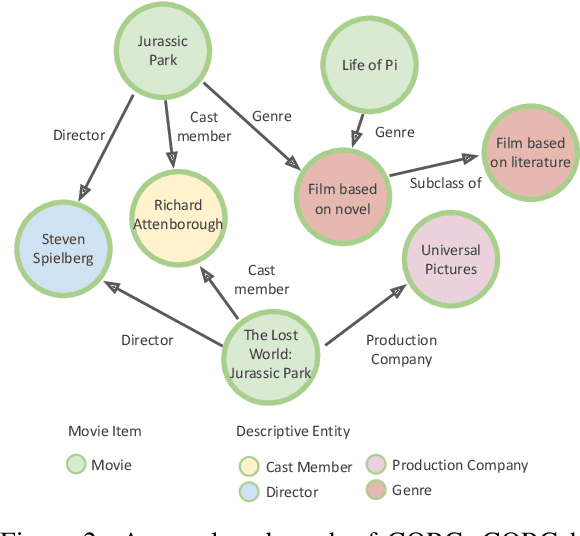

Recommendation systems focus on helping users find items of interest in the situations of information overload, where users' preferences are typically estimated by the past observed behaviors. In contrast, conversational recommendation systems (CRS) aim to understand users' preferences via interactions in conversation flows. CRS is a complex problem that consists of two main tasks: (1) recommendation and (2) response generation. Previous work often tried to solve the problem in a modular manner, where recommenders and response generators are separate neural models. Such modular architectures often come with a complicated and unintuitive connection between the modules, leading to inefficient learning and other issues. In this work, we propose a unified framework based on BART for conversational recommendation, which tackles two tasks in a single model. Furthermore, we also design and collect a lightweight knowledge graph for CRS in the movie domain. The experimental results show that the proposed methods achieve the state-of-the-art performance in terms of both automatic and human evaluation.
Towards an Open Platform for Legal Information
May 27, 2020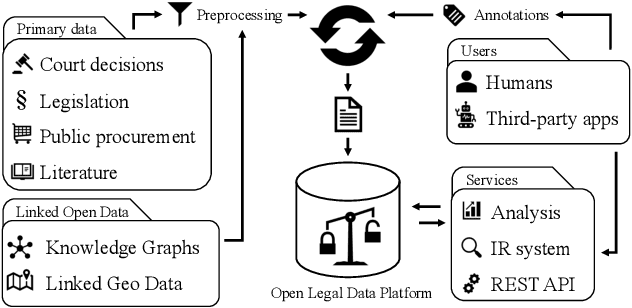

Recent advances in the area of legal information systems have led to a variety of applications that promise support in processing and accessing legal documents. Unfortunately, these applications have various limitations, e.g., regarding scope or extensibility. Furthermore, we do not observe a trend towards open access in digital libraries in the legal domain as we observe in other domains, e.g., economics of computer science. To improve open access in the legal domain, we present our approach for an open source platform to transparently process and access Legal Open Data. This enables the sustainable development of legal applications by offering a single technology stack. Moreover, the approach facilitates the development and deployment of new technologies. As proof of concept, we implemented six technologies and generated metadata for more than 250,000 German laws and court decisions. Thus, we can provide users of our platform not only access to legal documents, but also the contained information.
SMA-NBO: A Sequential Multi-Agent Planning with Nominal Belief-State Optimization in Target Tracking
Mar 03, 2022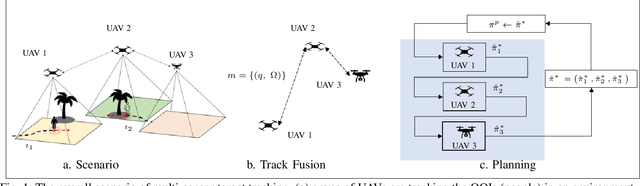
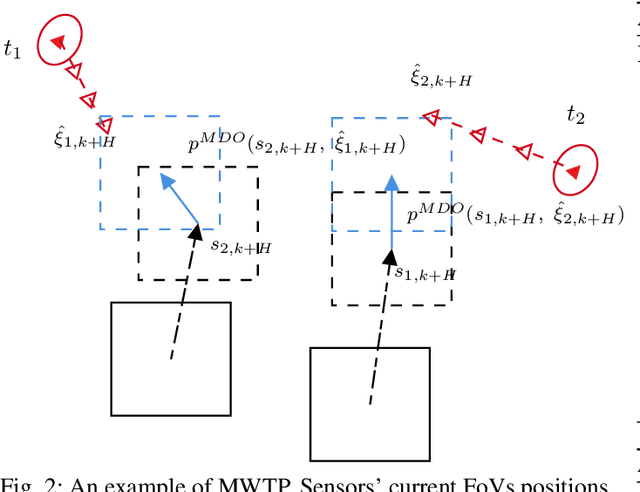
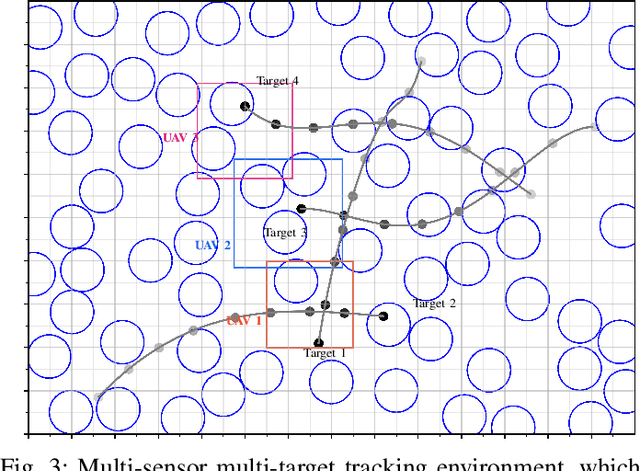
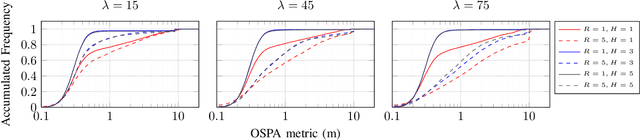
In target tracking with mobile multi-sensor systems, sensor deployment impacts the observation capabilities and the resulting state estimation quality. Based on a partially observable Markov decision process (POMDP) formulation comprised of the observable sensor dynamics, unobservable target states, and accompanying observation laws, we present a distributed information-driven solution approach to the multi-agent target tracking problem, namely, sequential multi-agent nominal belief-state optimization (SMA-NBO). SMA-NBO seeks to minimize the expected tracking error via receding horizon control including a heuristic expected cost-to-go (HECTG). SMA-NBO incorporates a computationally efficient approximation of the target belief-state over the horizon. The agent-by-agent decision-making is capable of leveraging on-board (edge) compute for selecting (sub-optimal) target-tracking maneuvers exhibiting non-myopic cooperative fleet behavior. The optimization problem explicitly incorporates semantic information defining target occlusions from a world model. To illustrate the efficacy of our approach, a random occlusion forest environment is simulated. SMA-NBO is compared to other baseline approaches. The simulation results show SMA-NBO 1) maintains tracking performance and reduces the computational cost by replacing the calculation of the expected target trajectory with a single sample trajectory based on maximum a posteriori estimation; 2) generates cooperative fleet decision by sequentially optimizing single-agent policy with efficient usage of other agents' policy of intent; 3) aptly incorporates the multiple weighted trace penalty (MWTP) HECTG, which improves tracking performance with a computationally efficient heuristic.