 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebpage Segmentation for Extracting Images and Their Surrounding Contextual Information
May 18, 2020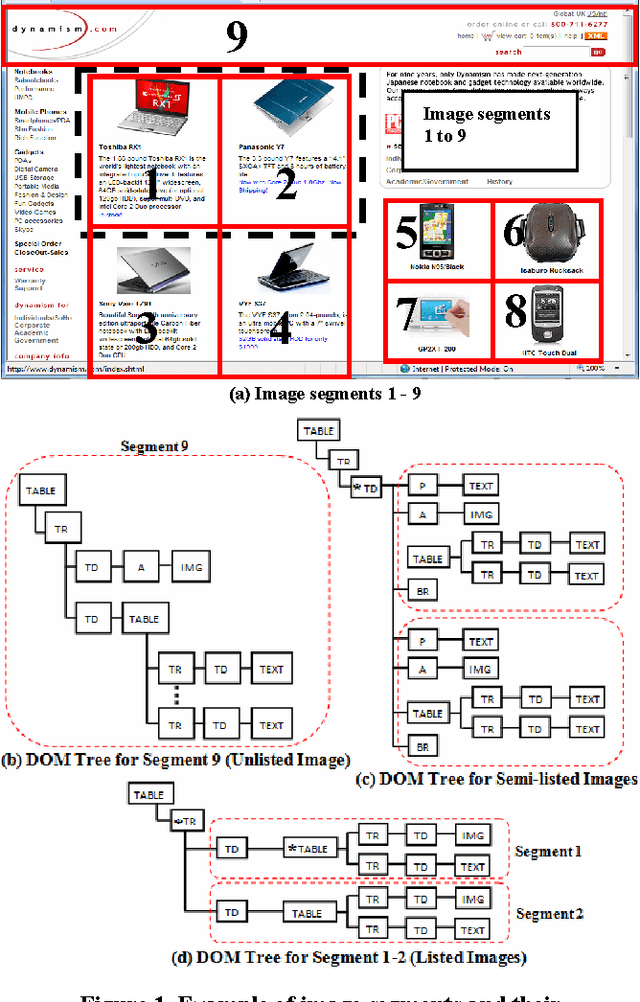
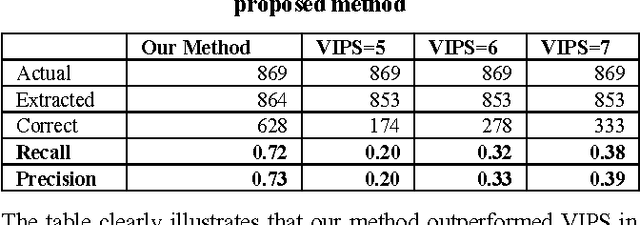
Web images come in hand with valuable contextual information. Although this information has long been mined for various uses such as image annotation, clustering of images, inference of image semantic content, etc., insufficient attention has been given to address issues in mining this contextual information. In this paper, we propose a webpage segmentation algorithm targeting the extraction of web images and their contextual information based on their characteristics as they appear on webpages. We conducted a user study to obtain a human-labeled dataset to validate the effectiveness of our method and experiments demonstrated that our method can achieve better results compared to an existing segmentation algorithm.
Near-duplicate video detection featuring coupled temporal and perceptual visual structures and logical inference based matching
May 15, 2020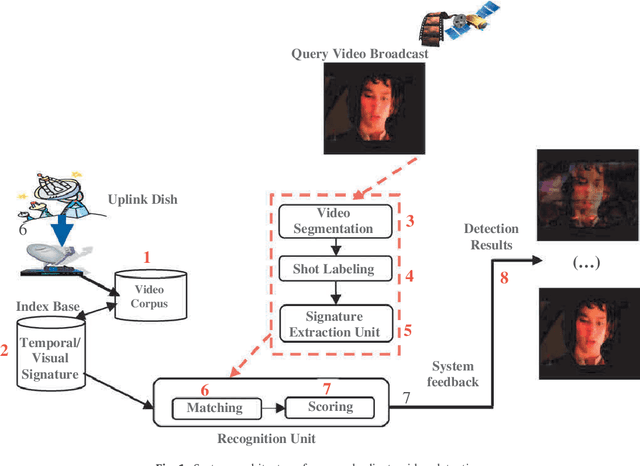



We propose in this paper an architecture for near-duplicate video detection based on: (i) index and query signature based structures integrating temporal and perceptual visual features and (ii) a matching framework computing the logical inference between index and query documents. As far as indexing is concerned, instead of concatenating low-level visual features in high-dimensional spaces which results in curse of dimensionality and redundancy issues, we adopt a perceptual symbolic representation based on color and texture concepts. For matching, we propose to instantiate a retrieval model based on logical inference through the coupling of an N-gram sliding window process and theoretically-sound lattice-based structures. The techniques we cover are robust and insensitive to general video editing and/or degradation, making it ideal for re-broadcasted video search. Experiments are carried out on large quantities of video data collected from the TRECVID 02, 03 and 04 collections and real-world video broadcasts recorded from two German TV stations. An empirical comparison over two state-of-the-art dynamic programming techniques is encouraging and demonstrates the advantage and feasibility of our method.
On the Merging of Domain-Specific Heterogeneous Ontologies using Wordnet and Web Pattern-based Queries
Apr 30, 2020



Ontologies form the basic interest in various computer science disciplines such as semantic web, information retrieval, database design, etc. They aim at providing a formal, explicit and shared conceptualization and understanding of common domains between different communities. In addition, they allow for concepts and their constraints of a specific domain to be explicitly defined. However, the distributed nature of ontology development and the differences in viewpoints of the ontology engineers have resulted in the so called "semantic heterogeneity" between ontologies. Semantic heterogeneity constitutes the major obstacle against achieving interoperability between ontologies. To overcome this obstacle, we present a multi-purpose framework which exploits the WordNet generic knowledge base for: i) Discovering and correcting the incorrect semantic relations between the concepts of the ontology in a specific domain. This step is a primary step of ontology merging. ii) Merging domain-specific ontologies through computing semantic relations between their concepts. iii) Handling the issue of missing concepts in WordNet through the acquisition of statistical information on the Web. And iv) Enriching WordNet with these missing concepts. An experimental instantiation of the framework and comparisons with state-of-the-art syntactic and semantic-based systems validate our proposal.