 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SemanticCAP: Chromatin Accessibility Prediction Enhanced by Features Learning from a Language Model
Apr 06, 2022

A large number of inorganic and organic compounds are able to bind DNA and form complexes, among which drug-related molecules are important. Chromatin accessibility changes not only directly affects drug-DNA interactions, but also promote or inhibit the expression of critical genes associated with drug resistance by affecting the DNA binding capacity of TFs and transcriptional regulators. However, Biological experimental techniques for measuring it are expensive and time consuming. In recent years, several kinds of computational methods have been proposed to identify accessible regions of the genome. Existing computational models mostly ignore the contextual information of bases in gene sequences. To address these issues, we proposed a new solution named SemanticCAP. It introduces a gene language model which models the context of gene sequences, thus being able to provide an effective representation of a certain site in gene sequences. Basically, we merge the features provided by the gene language model into our chromatin accessibility model. During the process, we designed some methods to make feature fusion smoother. Compared with other systems under public benchmarks, our model proved to have better performance.
Kernel Proposal Network for Arbitrary Shape Text Detection
Mar 12, 2022


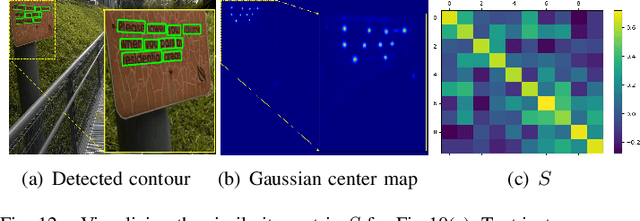
Segmentation-based methods have achieved great success for arbitrary shape text detection. However, separating neighboring text instances is still one of the most challenging problems due to the complexity of texts in scene images. In this paper, we propose an innovative Kernel Proposal Network (dubbed KPN) for arbitrary shape text detection. The proposed KPN can separate neighboring text instances by classifying different texts into instance-independent feature maps, meanwhile avoiding the complex aggregation process existing in segmentation-based arbitrary shape text detection methods. To be concrete, our KPN will predict a Gaussian center map for each text image, which will be used to extract a series of candidate kernel proposals (i.e., dynamic convolution kernel) from the embedding feature maps according to their corresponding keypoint positions. To enforce the independence between kernel proposals, we propose a novel orthogonal learning loss (OLL) via orthogonal constraints. Specifically, our kernel proposals contain important self-information learned by network and location information by position embedding. Finally, kernel proposals will individually convolve all embedding feature maps for generating individual embedded maps of text instances. In this way, our KPN can effectively separate neighboring text instances and improve the robustness against unclear boundaries. To our knowledge, our work is the first to introduce the dynamic convolution kernel strategy to efficiently and effectively tackle the adhesion problem of neighboring text instances in text detection. Experimental results on challenging datasets verify the impressive performance and efficiency of our method. The code and model are available at https://github.com/GXYM/KPN.
Evolutionary Diversity Optimisation for The Traveling Thief Problem
Apr 06, 2022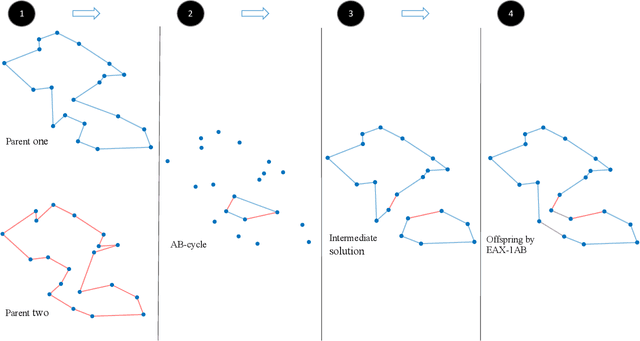

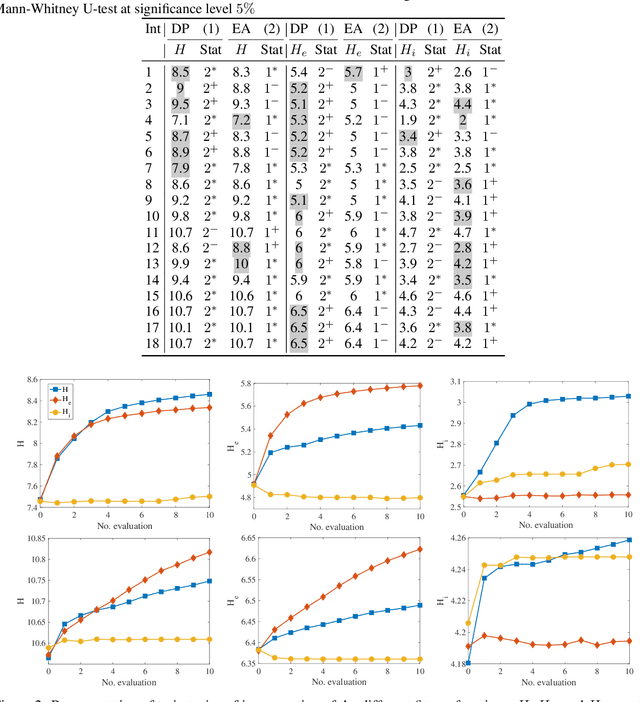
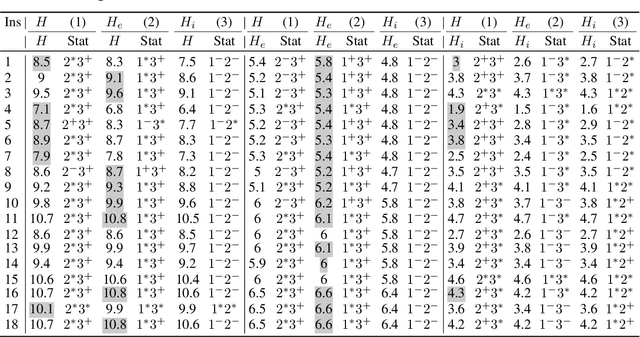
There has been a growing interest in the evolutionary computation community to compute a diverse set of high-quality solutions for a given optimisation problem. This can provide the practitioners with invaluable information about the solution space and robustness against imperfect modelling and minor problems' changes. It also enables the decision-makers to involve their interests and choose between various solutions. In this study, we investigate for the first time a prominent multi-component optimisation problem, namely the Traveling Thief Problem (TTP), in the context of evolutionary diversity optimisation. We introduce a bi-level evolutionary algorithm to maximise the structural diversity of the set of solutions. Moreover, we examine the inter-dependency among the components of the problem in terms of structural diversity and empirically determine the best method to obtain diversity. We also conduct a comprehensive experimental investigation to examine the introduced algorithm and compare the results to another recently introduced framework based on the use of Quality Diversity (QD). Our experimental results show a significant improvement of the QD approach in terms of structural diversity for most TTP benchmark instances.
Lombard Effect for Bilingual Speakers in Cantonese and English: importance of spectro-temporal features
Apr 14, 2022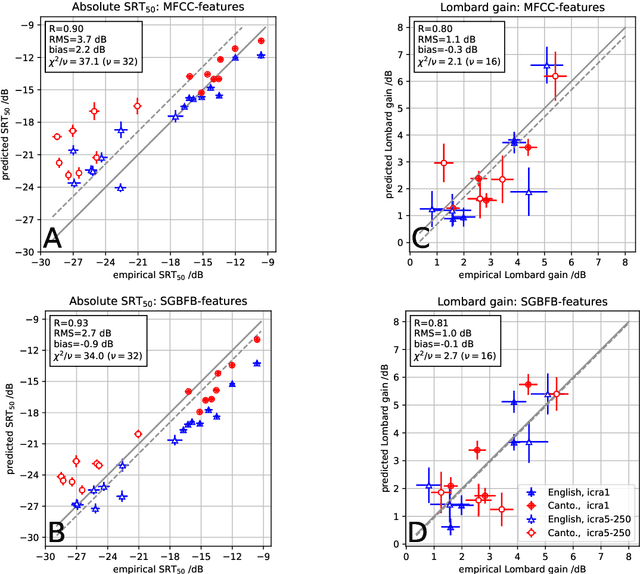
For a better understanding of the mechanisms underlying speech perception and the contribution of different signal features, computational models of speech recognition have a long tradition in hearing research. Due to the diverse range of situations in which speech needs to be recognized, these models need to be generalizable across many acoustic conditions, speakers, and languages. This contribution examines the importance of different features for speech recognition predictions of plain and Lombard speech for English in comparison to Cantonese in stationary and modulated noise. While Cantonese is a tonal language that encodes information in spectro-temporal features, the Lombard effect is known to be associated with spectral changes in the speech signal. These contrasting properties of tonal languages and the Lombard effect form an interesting basis for the assessment of speech recognition models. Here, an automatic speech recognition-based ASR model using spectral or spectro-temporal features is evaluated with empirical data. The results indicate that spectro-temporal features are crucial in order to predict the speaker-specific speech recognition threshold SRT$_{50}$ in both Cantonese and English as well as to account for the improvement of speech recognition in modulated noise, while effects due to Lombard speech can already be predicted by spectral features.
Attention-based Dual Supervised Decoder for RGBD Semantic Segmentation
Jan 05, 2022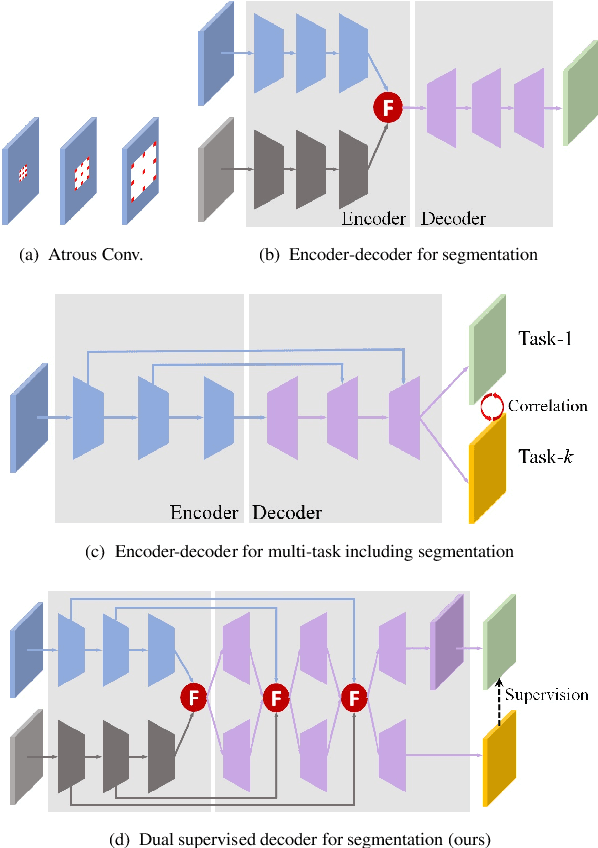
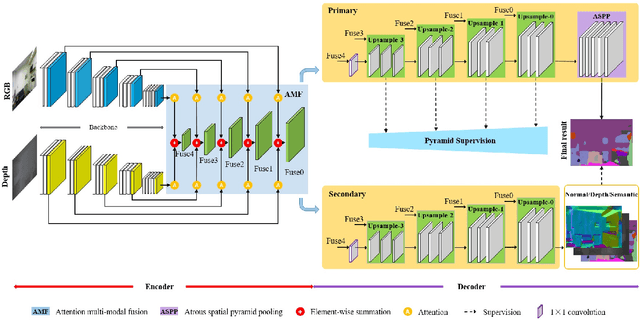
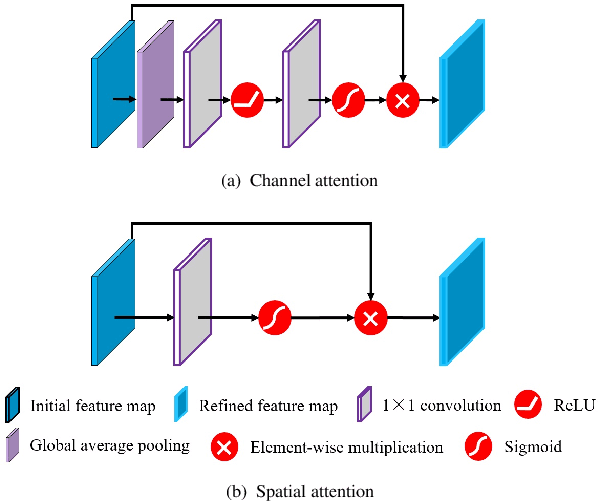
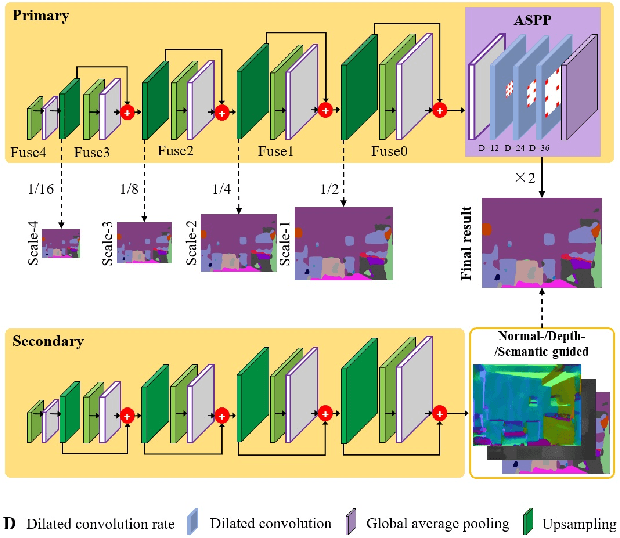
Encoder-decoder models have been widely used in RGBD semantic segmentation, and most of them are designed via a two-stream network. In general, jointly reasoning the color and geometric information from RGBD is beneficial for semantic segmentation. However, most existing approaches fail to comprehensively utilize multimodal information in both the encoder and decoder. In this paper, we propose a novel attention-based dual supervised decoder for RGBD semantic segmentation. In the encoder, we design a simple yet effective attention-based multimodal fusion module to extract and fuse deeply multi-level paired complementary information. To learn more robust deep representations and rich multi-modal information, we introduce a dual-branch decoder to effectively leverage the correlations and complementary cues of different tasks. Extensive experiments on NYUDv2 and SUN-RGBD datasets demonstrate that our method achieves superior performance against the state-of-the-art methods.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Apr 06, 2022

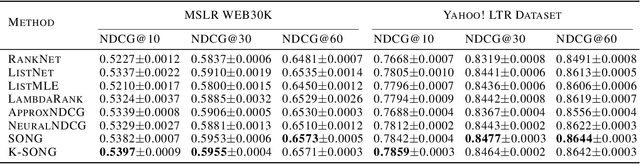

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
Cluster-based ensemble learning for wind power modeling with meteorological wind data
Apr 01, 2022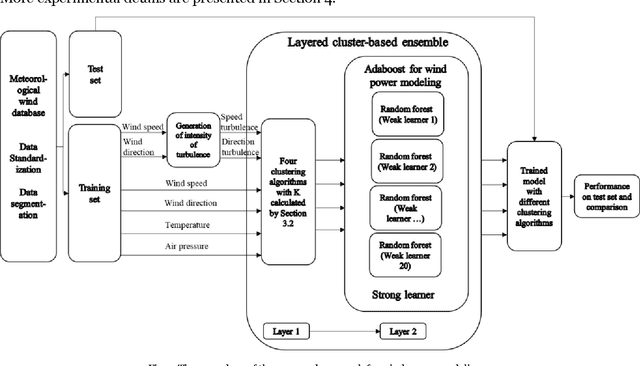
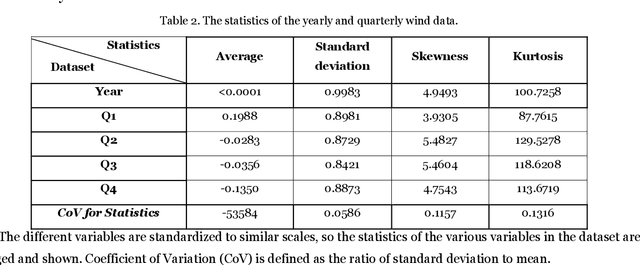
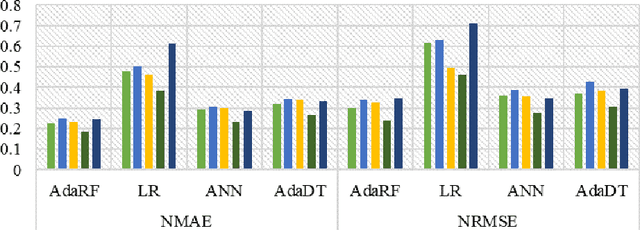
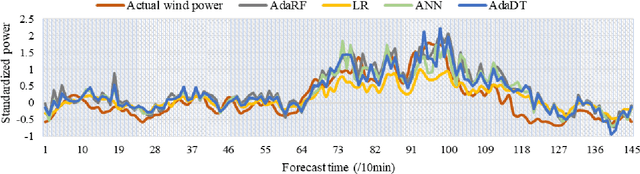
Optimal implementation and monitoring of wind energy generation hinge on reliable power modeling that is vital for understanding turbine control, farm operational optimization, and grid load balance. Based on the idea of similar wind condition leads to similar wind power; this paper constructs a modeling scheme that orderly integrates three types of ensemble learning algorithms, bagging, boosting, and stacking, and clustering approaches to achieve optimal power modeling. It also investigates applications of different clustering algorithms and methodology for determining cluster numbers in wind power modeling. The results reveal that all ensemble models with clustering exploit the intrinsic information of wind data and thus outperform models without it by approximately 15% on average. The model with the best farthest first clustering is computationally rapid and performs exceptionally well with an improvement of around 30%. The modeling is further boosted by about 5% by introducing stacking that fuses ensembles with varying clusters. The proposed modeling framework thus demonstrates promise by delivering efficient and robust modeling performance.
Evaluating a Generative Adversarial Framework for Information Retrieval
Oct 01, 2020
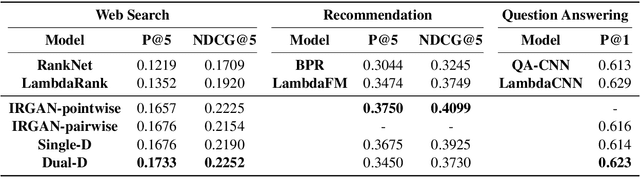
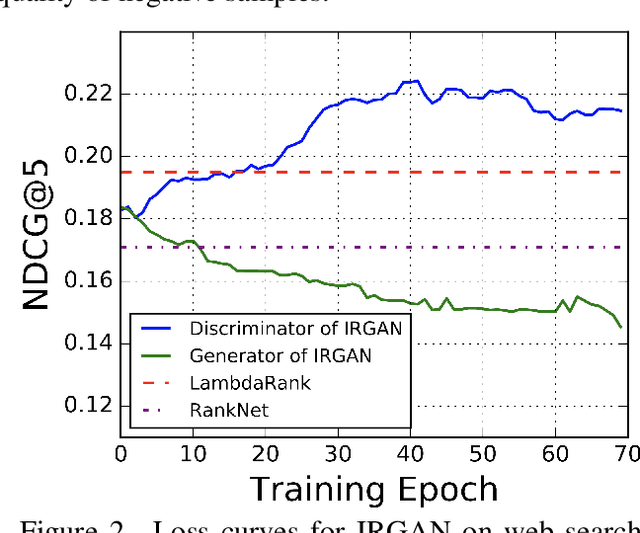

Recent advances in Generative Adversarial Networks (GANs) have resulted in its widespread applications to multiple domains. A recent model, IRGAN, applies this framework to Information Retrieval (IR) and has gained significant attention over the last few years. In this focused work, we critically analyze multiple components of IRGAN, while providing experimental and theoretical evidence of some of its shortcomings. Specifically, we identify issues with the constant baseline term in the policy gradients optimization and show that the generator harms IRGAN's performance. Motivated by our findings, we propose two models influenced by self-contrastive estimation and co-training which outperform IRGAN on two out of the three tasks considered.
Understanding Graph Convolutional Networks for Text Classification
Mar 30, 2022
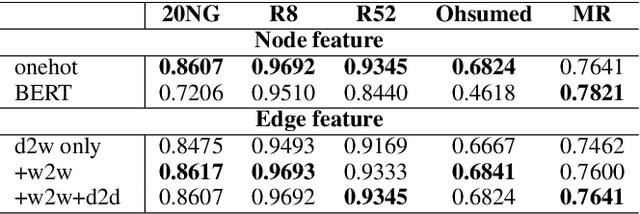
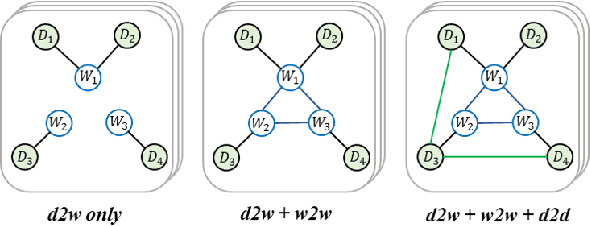
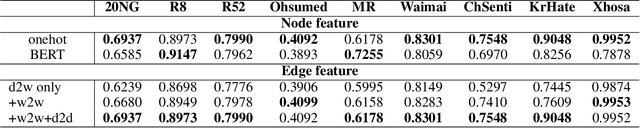
Graph Convolutional Networks (GCN) have been effective at tasks that have rich relational structure and can preserve global structure information of a dataset in graph embeddings. Recently, many researchers focused on examining whether GCNs could handle different Natural Language Processing tasks, especially text classification. While applying GCNs to text classification is well-studied, its graph construction techniques, such as node/edge selection and their feature representation, and the optimal GCN learning mechanism in text classification is rather neglected. In this paper, we conduct a comprehensive analysis of the role of node and edge embeddings in a graph and its GCN learning techniques in text classification. Our analysis is the first of its kind and provides useful insights into the importance of each graph node/edge construction mechanism when applied at the GCN training/testing in different text classification benchmarks, as well as under its semi-supervised environment.
Multi-task recommendation system for scientific papers with high-way networks
Apr 21, 2022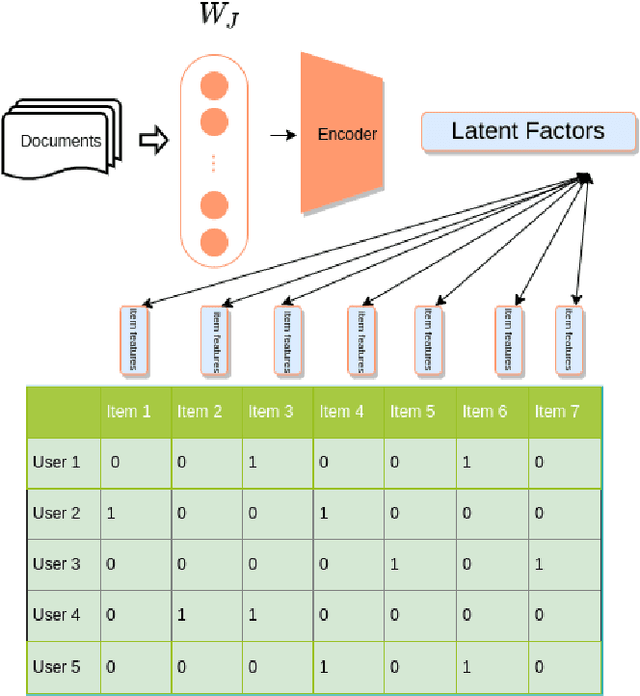
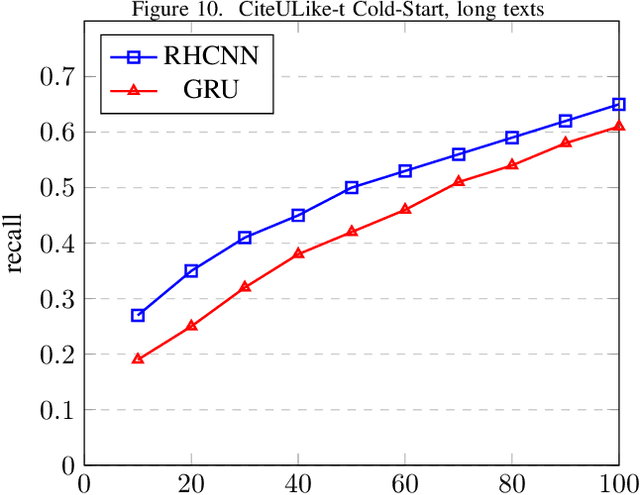
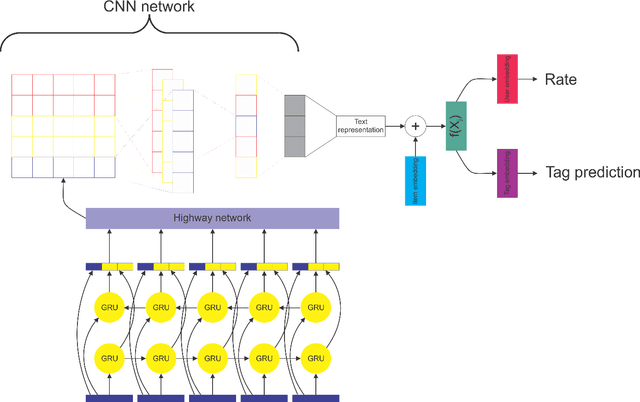
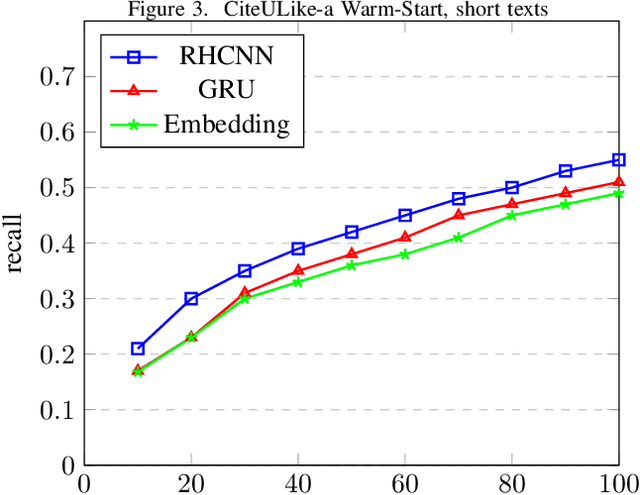
Finding and selecting the most relevant scientific papers from a large number of papers written in a research community is one of the key challenges for researchers these days. As we know, much information around research interest for scholars and academicians belongs to papers they read. Analysis and extracting contextual features from these papers could help us to suggest the most related paper to them. In this paper, we present a multi-task recommendation system (RS) that predicts a paper recommendation and generates its meta-data such as keywords. The system is implemented as a three-stage deep neural network encoder that tries to maps longer sequences of text to an embedding vector and learns simultaneously to predict the recommendation rate for a particular user and the paper's keywords. The motivation behind this approach is that the paper's topics expressed as keywords are a useful predictor of preferences of researchers. To achieve this goal, we use a system combination of RNNs, Highway and Convolutional Neural Networks to train end-to-end a context-aware collaborative matrix. Our application uses Highway networks to train the system very deep, combine the benefits of RNN and CNN to find the most important factor and make latent representation. Highway Networks allow us to enhance the traditional RNN and CNN pipeline by learning more sophisticated semantic structural representations. Using this method we can also overcome the cold start problem and learn latent features over large sequences of text.