 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data Stealing Attack on Medical Images: Is it Safe to Export Networks from Data Lakes?
Jun 07, 2022
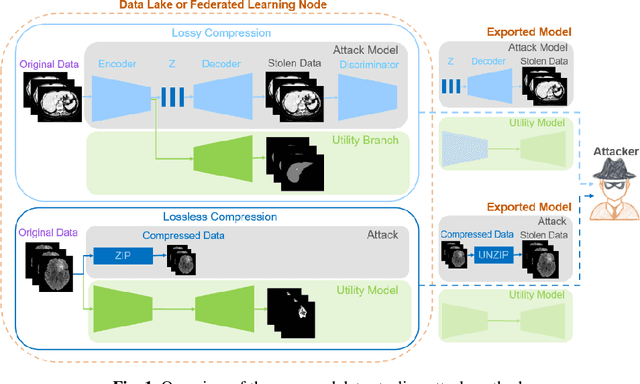
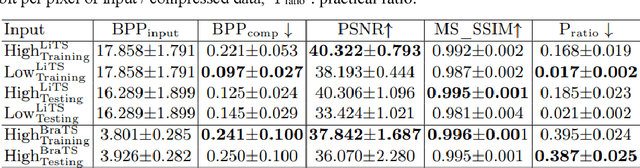
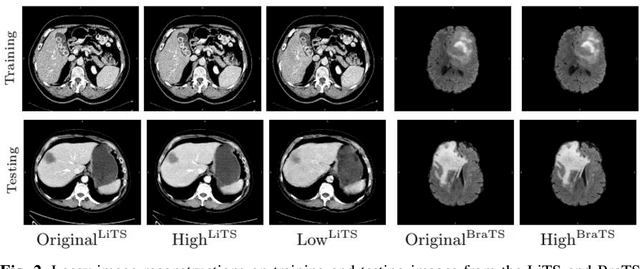

In privacy-preserving machine learning, it is common that the owner of the learned model does not have any physical access to the data. Instead, only a secured remote access to a data lake is granted to the model owner without any ability to retrieve data from the data lake. Yet, the model owner may want to export the trained model periodically from the remote repository and a question arises whether this may cause is a risk of data leakage. In this paper, we introduce the concept of data stealing attack during the export of neural networks. It consists in hiding some information in the exported network that allows the reconstruction outside the data lake of images initially stored in that data lake. More precisely, we show that it is possible to train a network that can perform lossy image compression and at the same time solve some utility tasks such as image segmentation. The attack then proceeds by exporting the compression decoder network together with some image codes that leads to the image reconstruction outside the data lake. We explore the feasibility of such attacks on databases of CT and MR images, showing that it is possible to obtain perceptually meaningful reconstructions of the target dataset, and that the stolen dataset can be used in turns to solve a broad range of tasks. Comprehensive experiments and analyses show that data stealing attacks should be considered as a threat for sensitive imaging data sources.
Multi-Level Modeling Units for End-to-End Mandarin Speech Recognition
May 25, 2022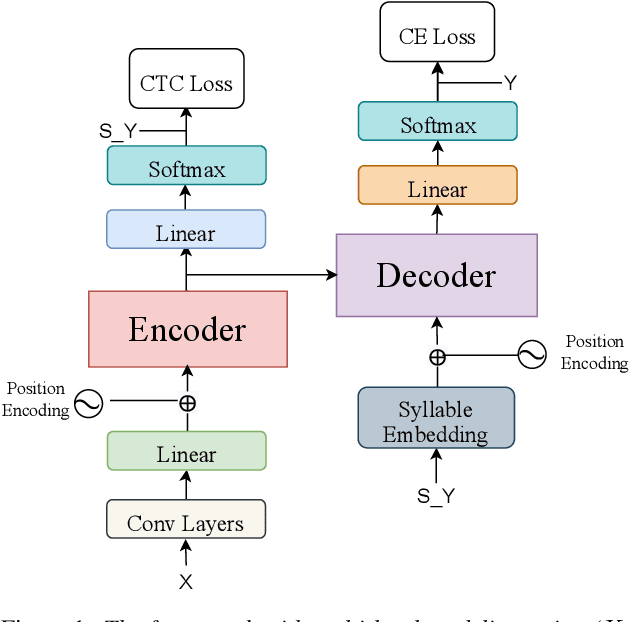

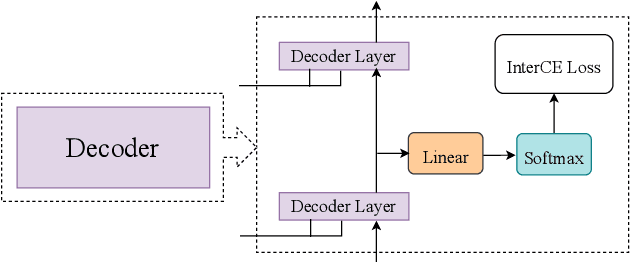
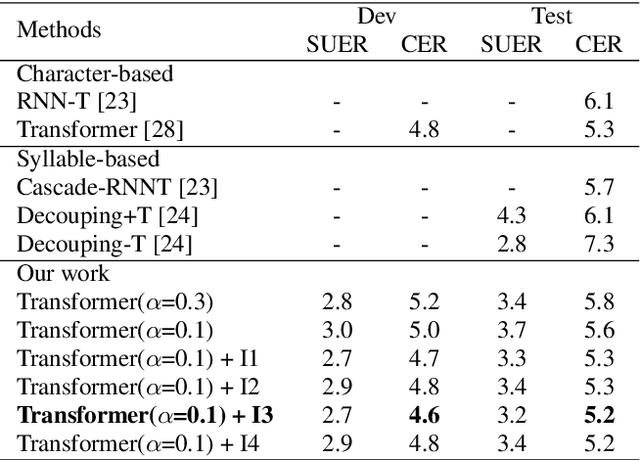
The choice of modeling units affects the performance of the acoustic modeling and plays an important role in automatic speech recognition (ASR). In mandarin scenarios, the Chinese characters represent meaning but are not directly related to the pronunciation. Thus only considering the writing of Chinese characters as modeling units is insufficient to capture speech features. In this paper, we present a novel method involves with multi-level modeling units, which integrates multi-level information for mandarin speech recognition. Specifically, the encoder block considers syllables as modeling units, and the decoder block deals with character modeling units. During inference, the input feature sequences are converted into syllable sequences by the encoder block and then converted into Chinese characters by the decoder block. This process is conducted by a unified end-to-end model without introducing additional conversion models. By introducing InterCE auxiliary task, our method achieves competitive results with CER of 4.1%/4.6% and 4.6%/5.2% on the widely used AISHELL-1 benchmark without a language model, using the Conformer and the Transformer backbones respectively.
Deep Unsupervised Image Anomaly Detection: An Information Theoretic Framework
Dec 09, 2020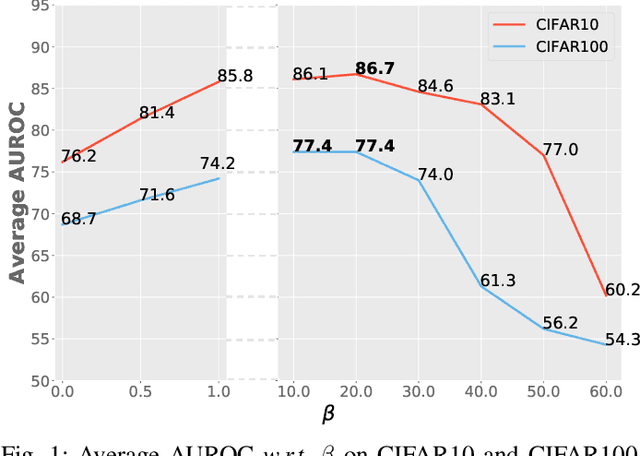
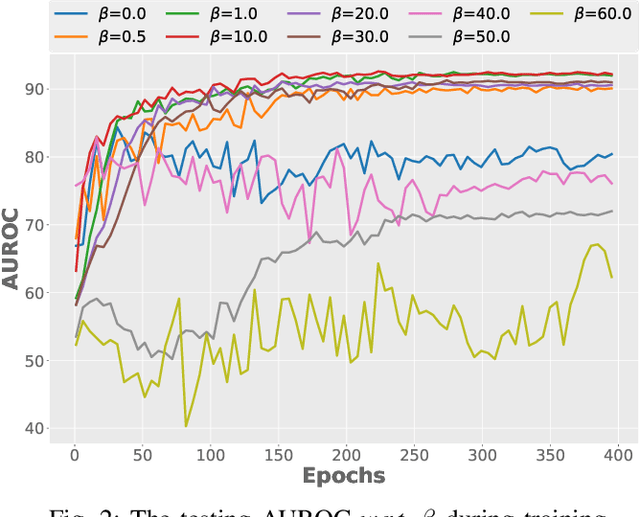
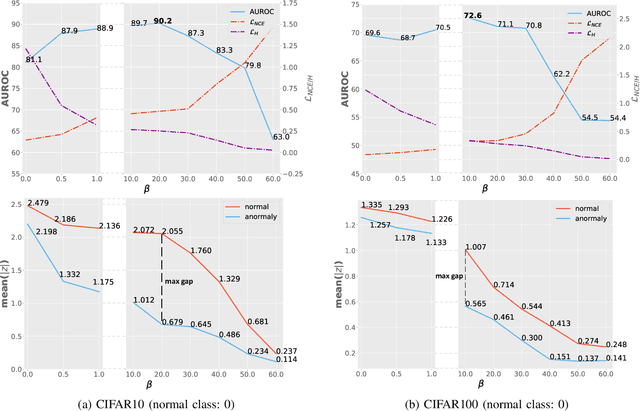
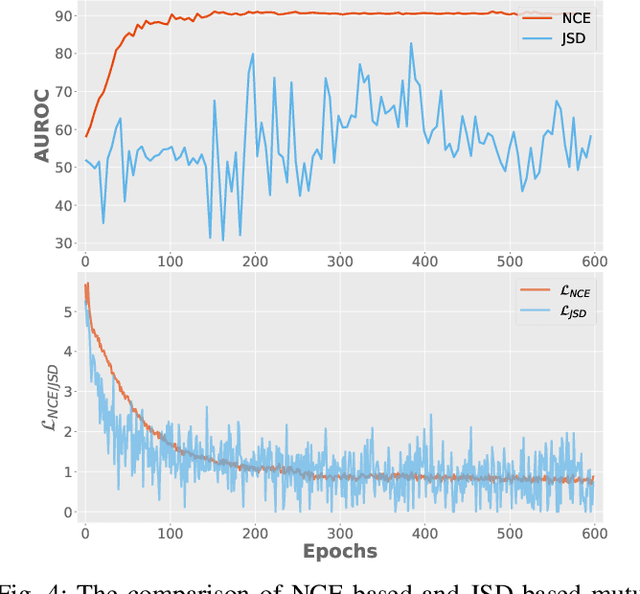
Surrogate task based methods have recently shown great promise for unsupervised image anomaly detection. However, there is no guarantee that the surrogate tasks share the consistent optimization direction with anomaly detection. In this paper, we return to a direct objective function for anomaly detection with information theory, which maximizes the distance between normal and anomalous data in terms of the joint distribution of images and their representation. Unfortunately, this objective function is not directly optimizable under the unsupervised setting where no anomalous data is provided during training. Through mathematical analysis of the above objective function, we manage to decompose it into four components. In order to optimize in an unsupervised fashion, we show that, under the assumption that distribution of the normal and anomalous data are separable in the latent space, its lower bound can be considered as a function which weights the trade-off between mutual information and entropy. This objective function is able to explain why the surrogate task based methods are effective for anomaly detection and further point out the potential direction of improvement. Based on this object function we introduce a novel information theoretic framework for unsupervised image anomaly detection. Extensive experiments have demonstrated that the proposed framework significantly outperforms several state-of-the-arts on multiple benchmark data sets.
Know Thy Student: Interactive Learning with Gaussian Processes
Apr 26, 2022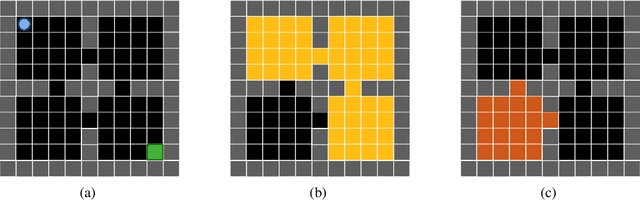
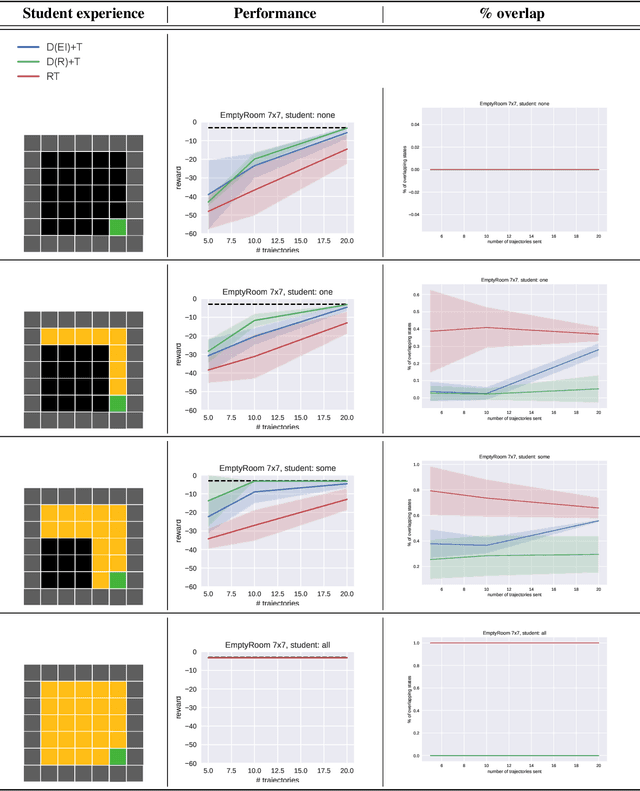

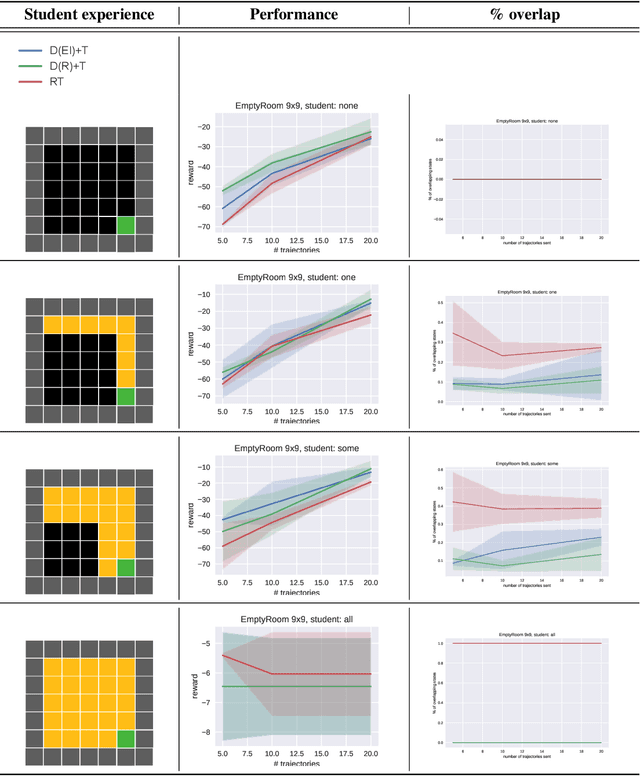
Learning often involves interaction between multiple agents. Human teacher-student settings best illustrate how interactions result in efficient knowledge passing where the teacher constructs a curriculum based on their students' abilities. Prior work in machine teaching studies how the teacher should construct optimal teaching datasets assuming the teacher knows everything about the student. However, in the real world, the teacher doesn't have complete information about the student. The teacher must interact and diagnose the student, before teaching. Our work proposes a simple diagnosis algorithm which uses Gaussian processes for inferring student-related information, before constructing a teaching dataset. We apply this to two settings. One is where the student learns from scratch and the teacher must figure out the student's learning algorithm parameters, eg. the regularization parameters in ridge regression or support vector machines. Two is where the student has partially explored the environment and the teacher must figure out the important areas the student has not explored; we study this in the offline reinforcement learning setting where the teacher must provide demonstrations to the student and avoid sending redundant trajectories. Our experiments highlight the importance of diagosing before teaching and demonstrate how students can learn more efficiently with the help of an interactive teacher. We conclude by outlining where diagnosing combined with teaching would be more desirable than passive learning.
How Useful are Gradients for OOD Detection Really?
May 20, 2022
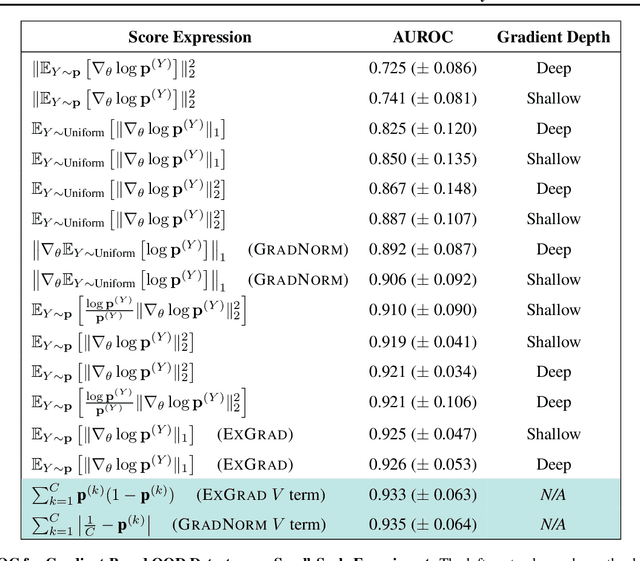
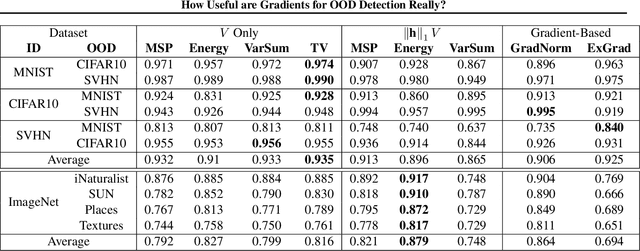
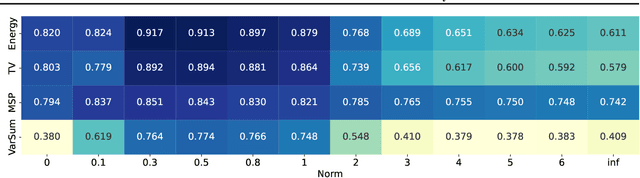
One critical challenge in deploying highly performant machine learning models in real-life applications is out of distribution (OOD) detection. Given a predictive model which is accurate on in distribution (ID) data, an OOD detection system will further equip the model with the option to defer prediction when the input is novel and the model has little confidence in prediction. There has been some recent interest in utilizing the gradient information in pre-trained models for OOD detection. While these methods have shown competitive performance, there are misconceptions about the true mechanism underlying them, which conflate their performance with the necessity of gradients. In this work, we provide an in-depth analysis and comparison of gradient based methods and elucidate the key components that warrant their OOD detection performance. We further propose a general, non-gradient based method of OOD detection which improves over previous baselines in both performance and computational efficiency.
A bio-inspired implementation of a sparse-learning spike-based hippocampus memory model
Jun 10, 2022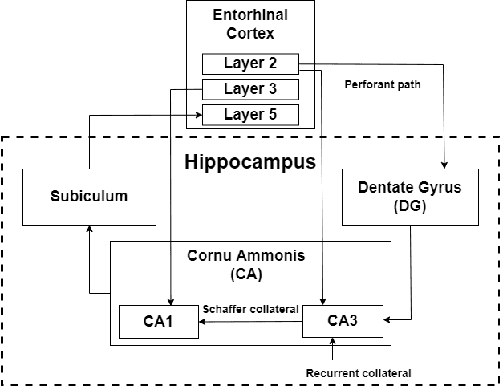
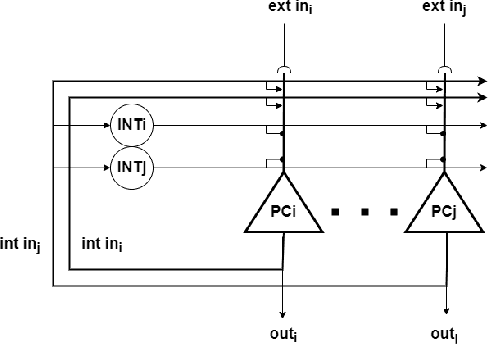
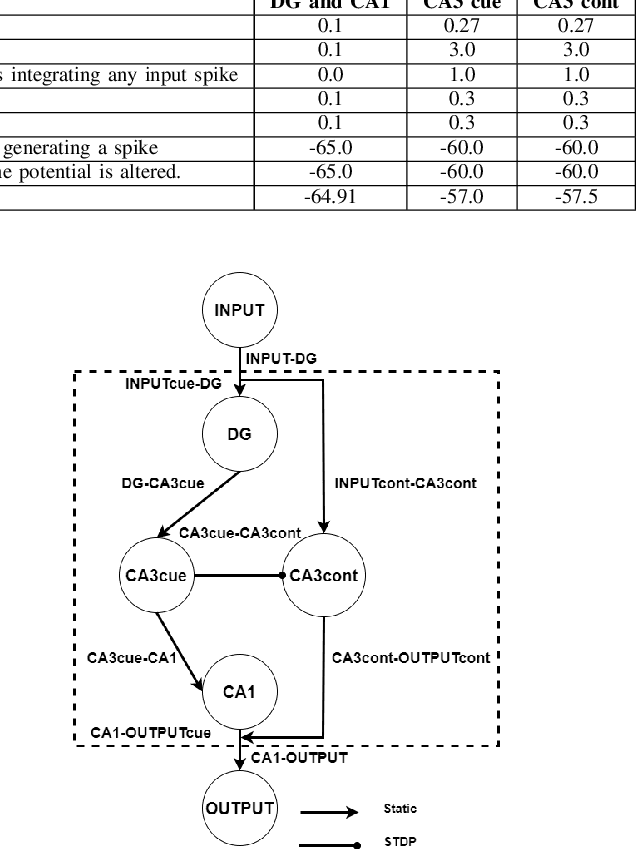
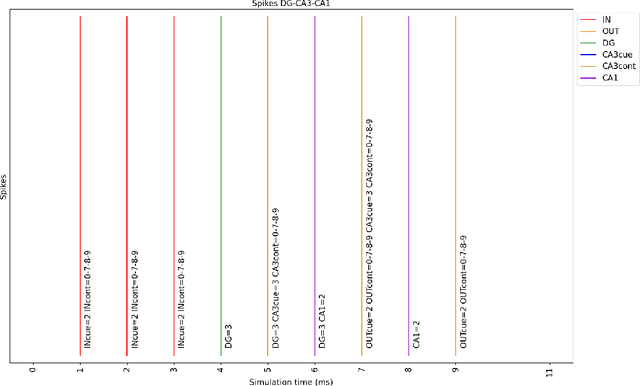
The nervous system, more specifically, the brain, is capable of solving complex problems simply and efficiently, far surpassing modern computers. In this regard, neuromorphic engineering is a research field that focuses on mimicking the basic principles that govern the brain in order to develop systems that achieve such computational capabilities. Within this field, bio-inspired learning and memory systems are still a challenge to be solved, and this is where the hippocampus is involved. It is the region of the brain that acts as a short-term memory, allowing the learning and unstructured and rapid storage of information from all the sensory nuclei of the cerebral cortex and its subsequent recall. In this work, we propose a novel bio-inspired memory model based on the hippocampus with the ability to learn memories, recall them from a cue (a part of the memory associated with the rest of the content) and even forget memories when trying to learn others with the same cue. This model has been implemented on the SpiNNaker hardware platform using Spiking Neural Networks, and a set of experiments and tests were performed to demonstrate its correct and expected operation. The proposed spike-based memory model generates spikes only when it receives an input, being energy efficient, and it needs 7 timesteps for the learning step and 6 timesteps for recalling a previously-stored memory. This work presents the first hardware implementation of a fully functional bio-inspired spike-based hippocampus memory model, paving the road for the development of future more complex neuromorphic systems.
Learning Dense Reward with Temporal Variant Self-Supervision
May 20, 2022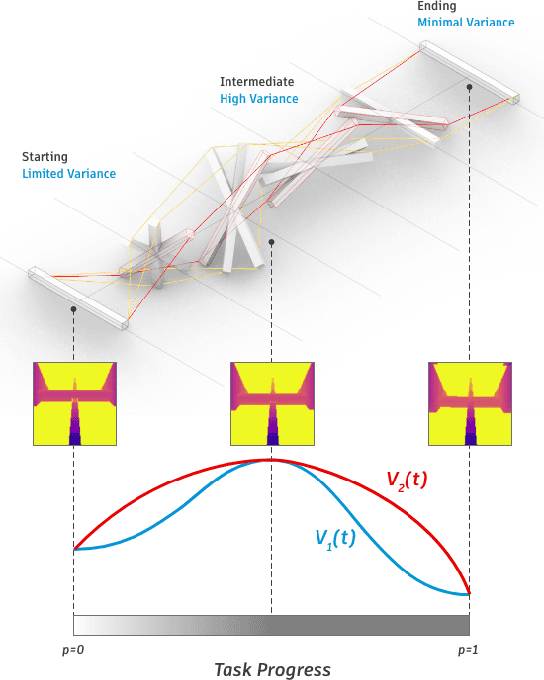
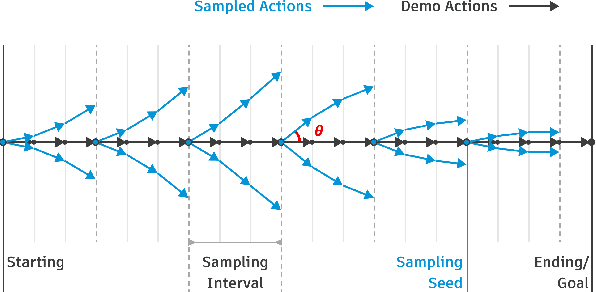
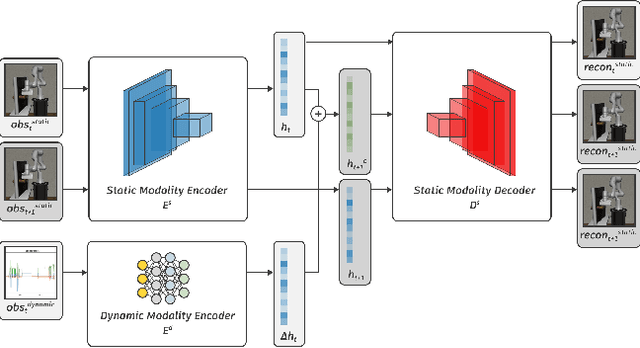
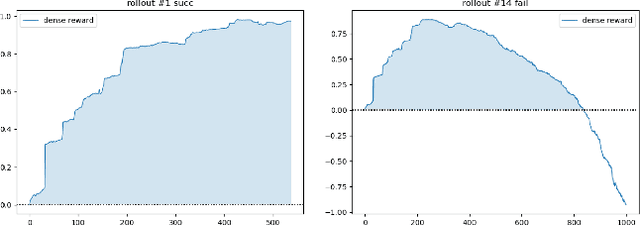
Rewards play an essential role in reinforcement learning. In contrast to rule-based game environments with well-defined reward functions, complex real-world robotic applications, such as contact-rich manipulation, lack explicit and informative descriptions that can directly be used as a reward. Previous effort has shown that it is possible to algorithmically extract dense rewards directly from multimodal observations. In this paper, we aim to extend this effort by proposing a more efficient and robust way of sampling and learning. In particular, our sampling approach utilizes temporal variance to simulate the fluctuating state and action distribution of a manipulation task. We then proposed a network architecture for self-supervised learning to better incorporate temporal information in latent representations. We tested our approach in two experimental setups, namely joint-assembly and door-opening. Preliminary results show that our approach is effective and efficient in learning dense rewards, and the learned rewards lead to faster convergence than baselines.
Towards Climate Awareness in NLP Research
May 16, 2022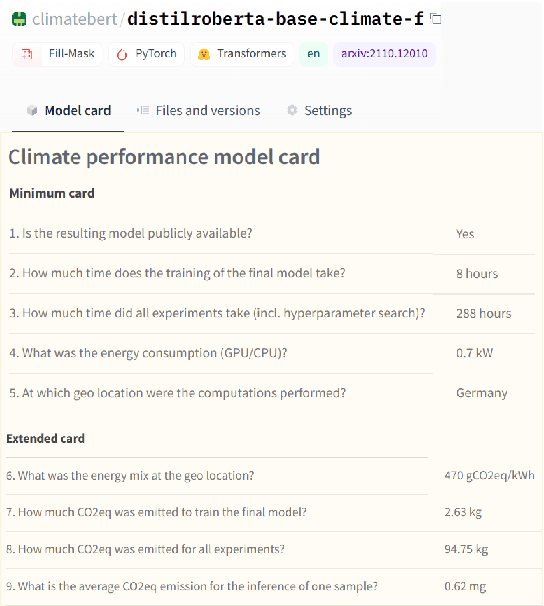

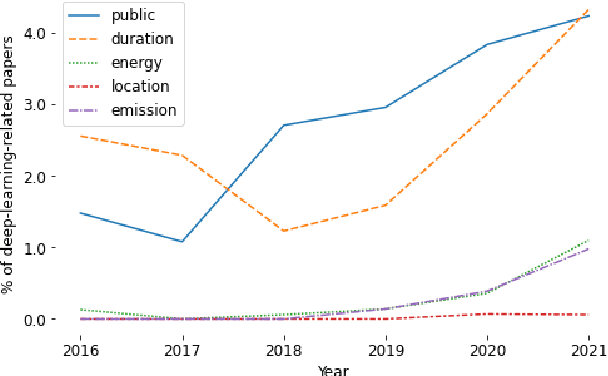

The climate impact of AI, and NLP research in particular, has become a serious issue given the enormous amount of energy that is increasingly being used for training and running computational models. Consequently, increasing focus is placed on efficient NLP. However, this important initiative lacks simple guidelines that would allow for systematic climate reporting of NLP research. We argue that this deficiency is one of the reasons why very few publications in NLP report key figures that would allow a more thorough examination of environmental impact. As a remedy, we propose a climate performance model card with the primary purpose of being practically usable with only limited information about experiments and the underlying computer hardware. We describe why this step is essential to increase awareness about the environmental impact of NLP research and, thereby, paving the way for more thorough discussions.
PLAtE: A Large-scale Dataset for List Page Web Extraction
May 24, 2022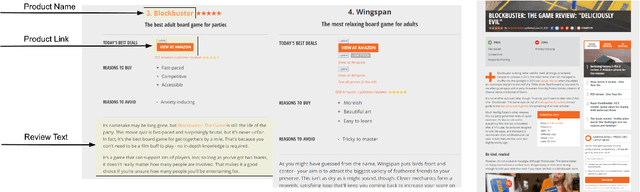
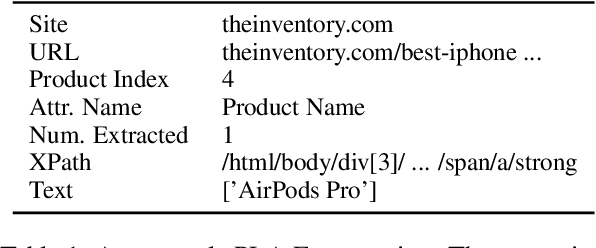
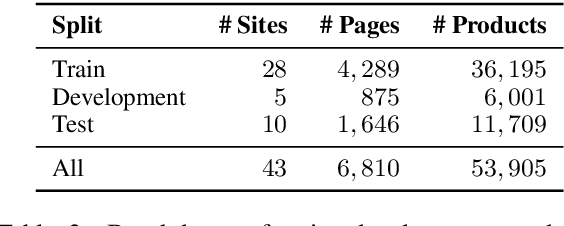
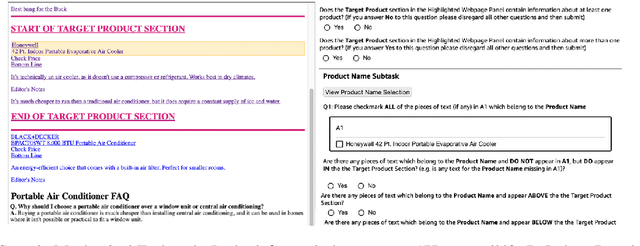
Recently, neural models have been leveraged to significantly improve the performance of information extraction from semi-structured websites. However, a barrier for continued progress is the small number of datasets large enough to train these models. In this work, we introduce the PLAtE (Pages of Lists Attribute Extraction) dataset as a challenging new web extraction task. PLAtE focuses on shopping data, specifically extractions from product review pages with multiple items. PLAtE encompasses both the tasks of: (1) finding product-list segmentation boundaries and (2) extracting attributes for each product. PLAtE is composed of 53, 905 items from 6, 810 pages, making it the first large-scale list page web extraction dataset. We construct PLAtE by collecting list pages from Common Crawl, then annotating them on Mechanical Turk. Quantitative and qualitative analyses are performed to demonstrate PLAtE has high-quality annotations. We establish strong baseline performance on PLAtE with a SOTA model achieving an F1-score of 0.750 for attribute classification and 0.915 for segmentation, indicating opportunities for future research innovations in web extraction.
RecipeRec: A Heterogeneous Graph Learning Model for Recipe Recommendation
May 24, 2022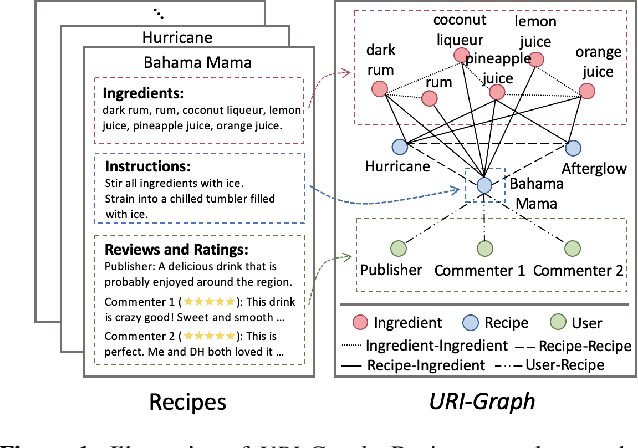
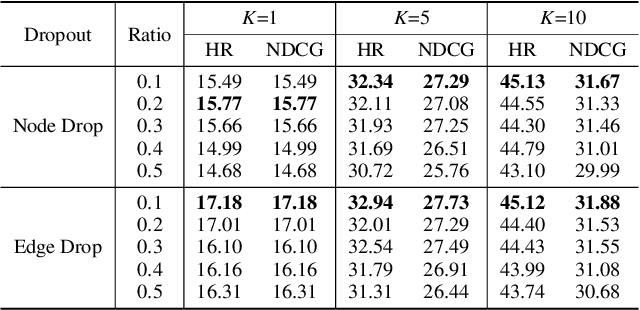
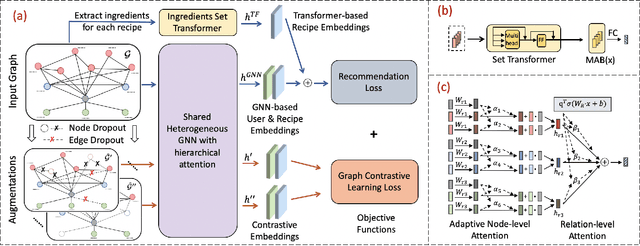
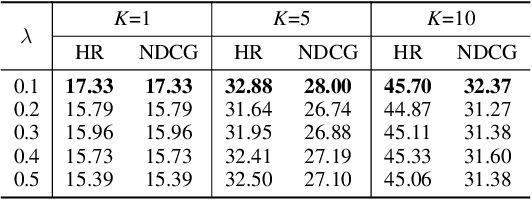
Recipe recommendation systems play an essential role in helping people decide what to eat. Existing recipe recommendation systems typically focused on content-based or collaborative filtering approaches, ignoring the higher-order collaborative signal such as relational structure information among users, recipes and food items. In this paper, we formalize the problem of recipe recommendation with graphs to incorporate the collaborative signal into recipe recommendation through graph modeling. In particular, we first present URI-Graph, a new and large-scale user-recipe-ingredient graph. We then propose RecipeRec, a novel heterogeneous graph learning model for recipe recommendation. The proposed model can capture recipe content and collaborative signal through a heterogeneous graph neural network with hierarchical attention and an ingredient set transformer. We also introduce a graph contrastive augmentation strategy to extract informative graph knowledge in a self-supervised manner. Finally, we design a joint objective function of recommendation and contrastive learning to optimize the model. Extensive experiments demonstrate that RecipeRec outperforms state-of-the-art methods for recipe recommendation. Dataset and codes are available at https://github.com/meettyj/RecipeRec.