 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recognizing Hand Use and Hand Role at Home After Stroke from Egocentric Video
Jul 18, 2022
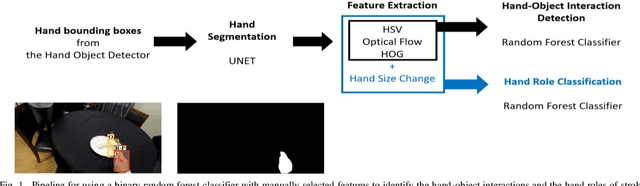



Introduction: Hand function is a central determinant of independence after stroke. Measuring hand use in the home environment is necessary to evaluate the impact of new interventions, and calls for novel wearable technologies. Egocentric video can capture hand-object interactions in context, as well as show how more-affected hands are used during bilateral tasks (for stabilization or manipulation). Automated methods are required to extract this information. Objective: To use artificial intelligence-based computer vision to classify hand use and hand role from egocentric videos recorded at home after stroke. Methods: Twenty-one stroke survivors participated in the study. A random forest classifier, a SlowFast neural network, and the Hand Object Detector neural network were applied to identify hand use and hand role at home. Leave-One-Subject-Out-Cross-Validation (LOSOCV) was used to evaluate the performance of the three models. Between-group differences of the models were calculated based on the Mathews correlation coefficient (MCC). Results: For hand use detection, the Hand Object Detector had significantly higher performance than the other models. The macro average MCCs using this model in the LOSOCV were 0.50 +- 0.23 for the more-affected hands and 0.58 +- 0.18 for the less-affected hands. Hand role classification had macro average MCCs in the LOSOCV that were close to zero for all models. Conclusion: Using egocentric video to capture the hand use of stroke survivors at home is feasible. Pose estimation to track finger movements may be beneficial to classifying hand roles in the future.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
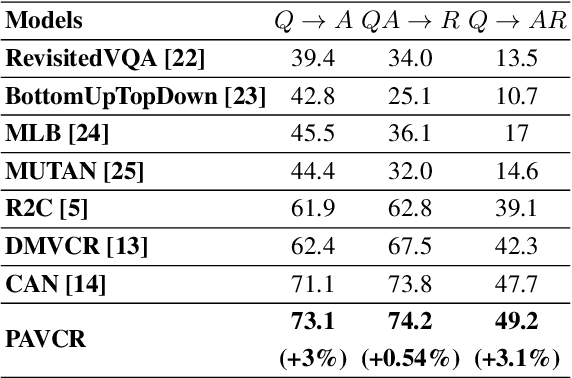
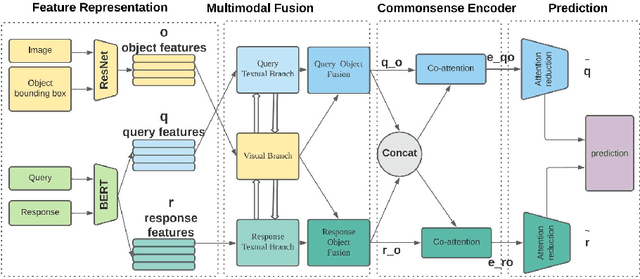

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.
Utilizing coarse-grained data in low-data settings for event extraction
May 11, 2022
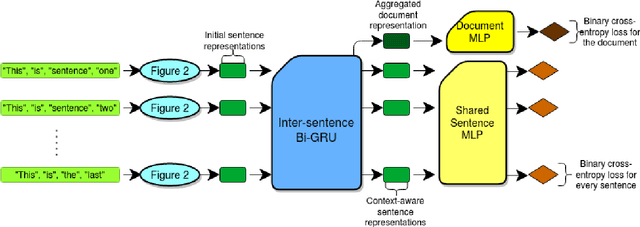
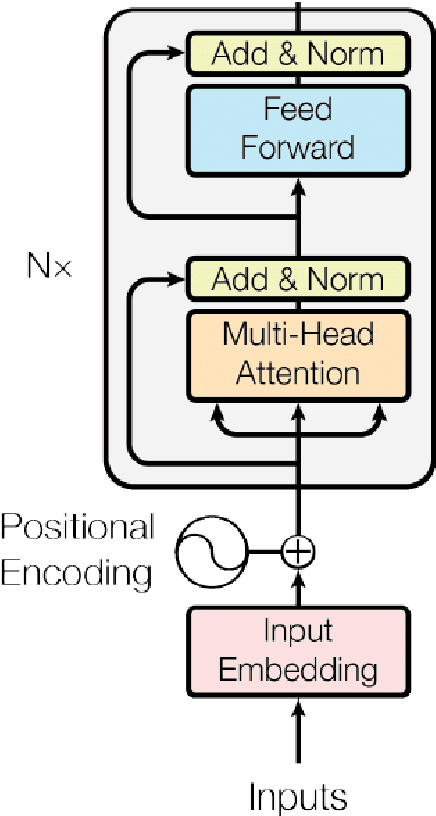
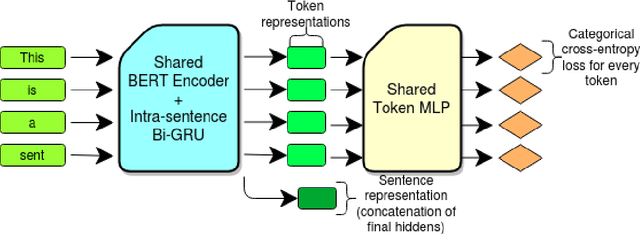
Annotating text data for event information extraction systems is hard, expensive, and error-prone. We investigate the feasibility of integrating coarse-grained data (document or sentence labels), which is far more feasible to obtain, instead of annotating more documents. We utilize a multi-task model with two auxiliary tasks, document and sentence binary classification, in addition to the main task of token classification. We perform a series of experiments with varying data regimes for the aforementioned integration. Results show that while introducing extra coarse-grained data offers greater improvement and robustness, a gain is still possible with only the addition of negative documents that have no information on any event.
Broccoli: Sprinkling Lightweight Vocabulary Learning into Everyday Information Diets
Apr 16, 2021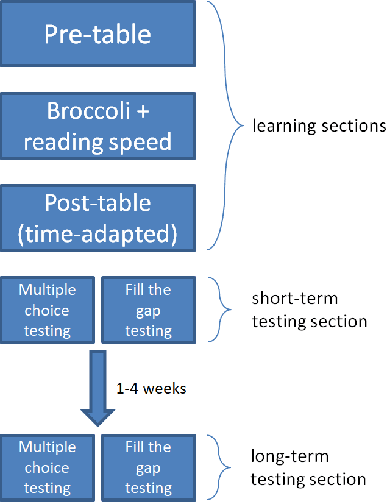
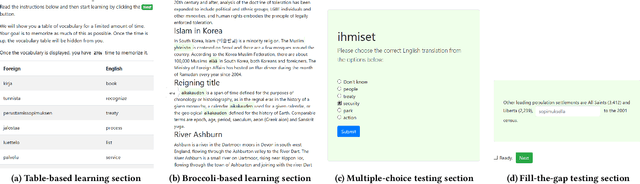
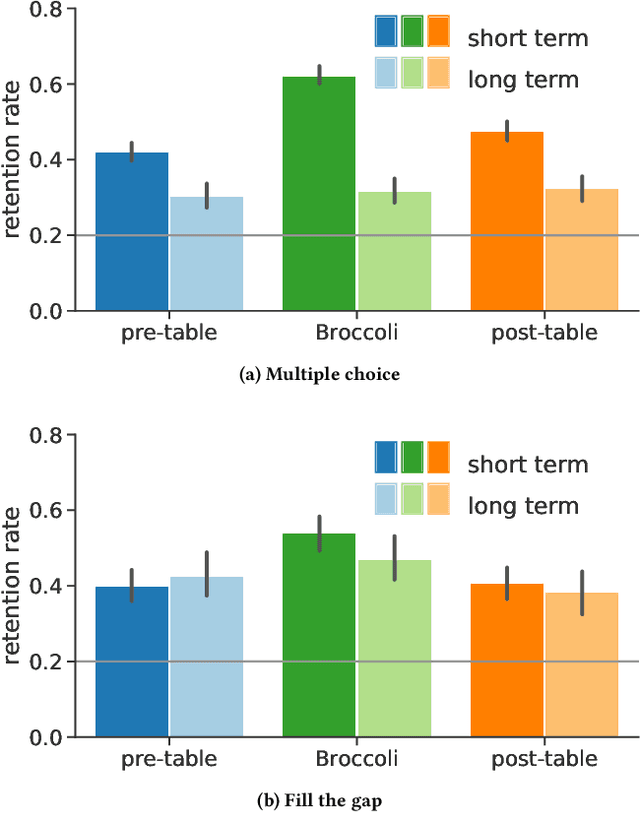
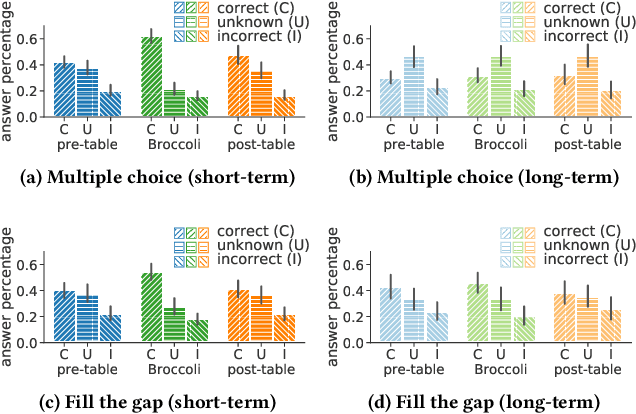
The learning of a new language remains to this date a cognitive task that requires considerable diligence and willpower, recent advances and tools notwithstanding. In this paper, we propose Broccoli, a new paradigm aimed at reducing the required effort by seamlessly embedding vocabulary learning into users' everyday information diets. This is achieved by inconspicuously switching chosen words encountered by the user for their translation in the target language. Thus, by seeing words in context, the user can assimilate new vocabulary without much conscious effort. We validate our approach in a careful user study, finding that the efficacy of the lightweight Broccoli approach is competitive with traditional, memorization-based vocabulary learning. The low cognitive overhead is manifested in a pronounced decrease in learners' usage of mnemonic learning strategies, as compared to traditional learning. Finally, we establish that language patterns in typical information diets are compatible with spaced-repetition strategies, thus enabling an efficient use of the Broccoli paradigm. Overall, our work establishes the feasibility of a novel and powerful "install-and-forget" approach for embedded language acquisition.
The DLCC Node Classification Benchmark for Analyzing Knowledge Graph Embeddings
Jul 13, 2022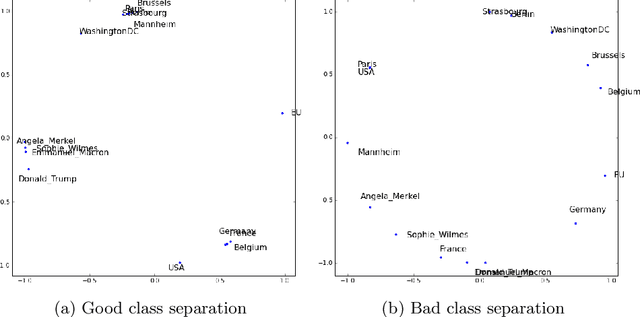
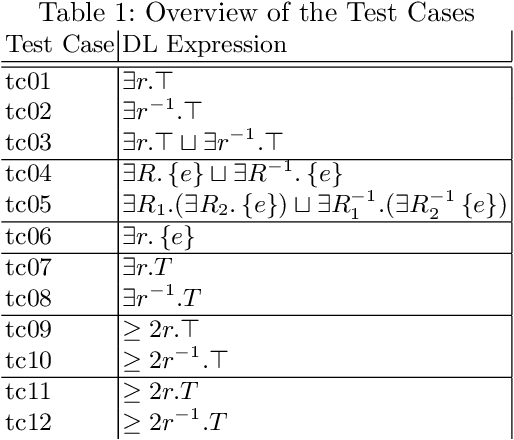
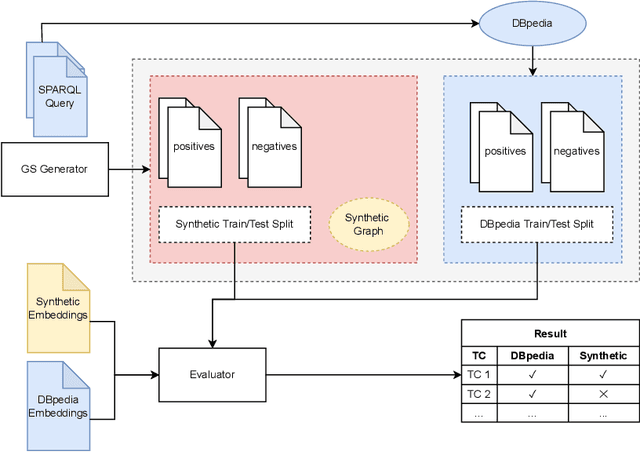
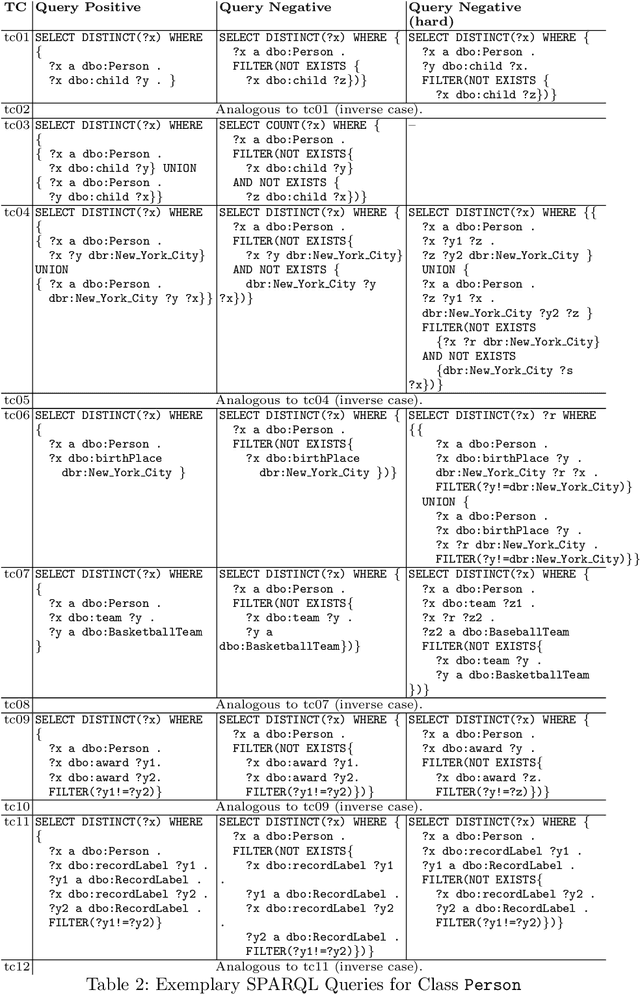
Knowledge graph embedding is a representation learning technique that projects entities and relations in a knowledge graph to continuous vector spaces. Embeddings have gained a lot of uptake and have been heavily used in link prediction and other downstream prediction tasks. Most approaches are evaluated on a single task or a single group of tasks to determine their overall performance. The evaluation is then assessed in terms of how well the embedding approach performs on the task at hand. Still, it is hardly evaluated (and often not even deeply understood) what information the embedding approaches are actually learning to represent. To fill this gap, we present the DLCC (Description Logic Class Constructors) benchmark, a resource to analyze embedding approaches in terms of which kinds of classes they can represent. Two gold standards are presented, one based on the real-world knowledge graph DBpedia and one synthetic gold standard. In addition, an evaluation framework is provided that implements an experiment protocol so that researchers can directly use the gold standard. To demonstrate the use of DLCC, we compare multiple embedding approaches using the gold standards. We find that many DL constructors on DBpedia are actually learned by recognizing different correlated patterns than those defined in the gold standard and that specific DL constructors, such as cardinality constraints, are particularly hard to be learned for most embedding approaches.
Learning Interacting Dynamical Systems with Latent Gaussian Process ODEs
May 24, 2022
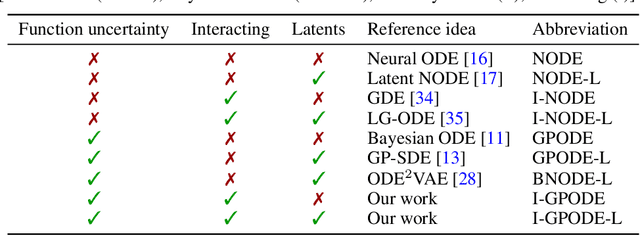
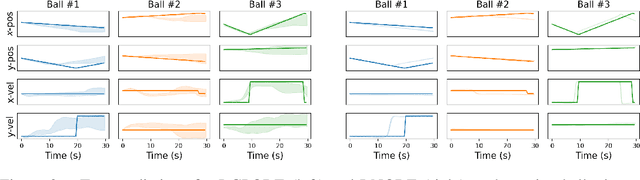
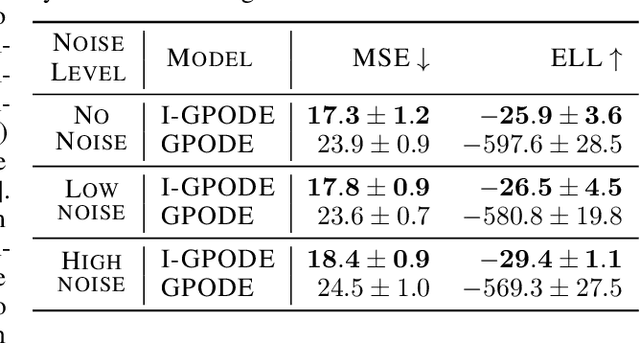
We study for the first time uncertainty-aware modeling of continuous-time dynamics of interacting objects. We introduce a new model that decomposes independent dynamics of single objects accurately from their interactions. By employing latent Gaussian process ordinary differential equations, our model infers both independent dynamics and their interactions with reliable uncertainty estimates. In our formulation, each object is represented as a graph node and interactions are modeled by accumulating the messages coming from neighboring objects. We show that efficient inference of such a complex network of variables is possible with modern variational sparse Gaussian process inference techniques. We empirically demonstrate that our model improves the reliability of long-term predictions over neural network based alternatives and it successfully handles missing dynamic or static information. Furthermore, we observe that only our model can successfully encapsulate independent dynamics and interaction information in distinct functions and show the benefit from this disentanglement in extrapolation scenarios.
Neural Network Normal Estimation and Bathymetry Reconstruction from Sidescan Sonar
Jun 15, 2022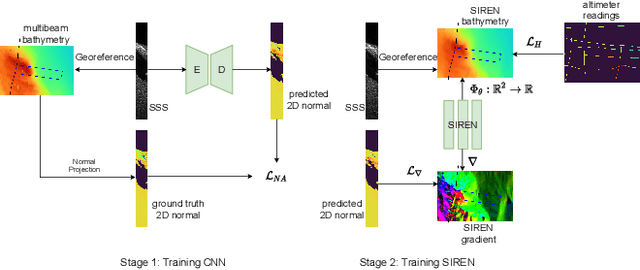
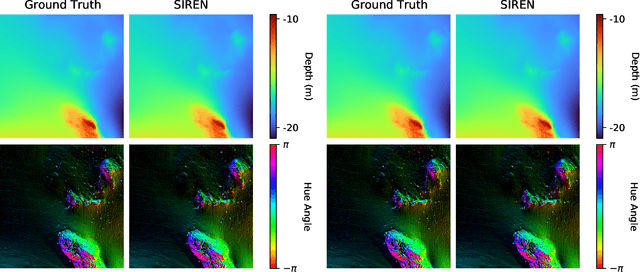
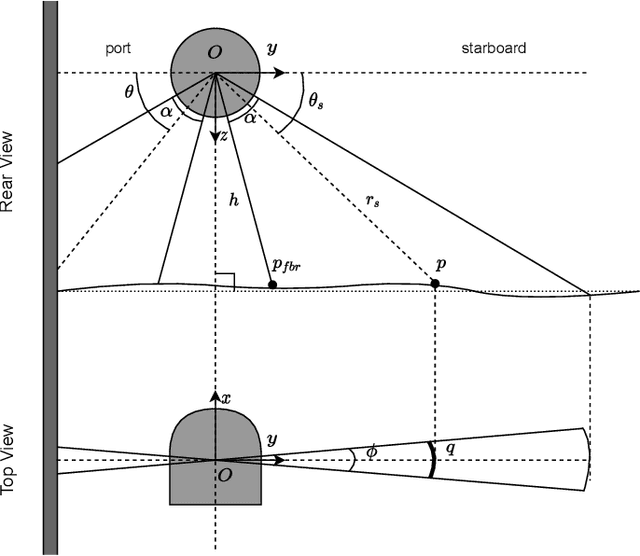
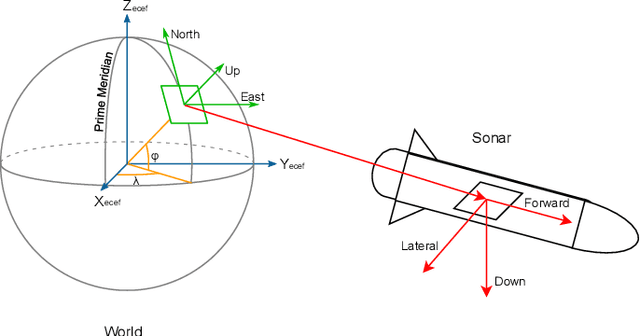
Sidescan sonar intensity encodes information about the changes of surface normal of the seabed. However, other factors such as seabed geometry as well as its material composition also affect the return intensity. One can model these intensity changes in a forward direction from the surface normals from bathymetric map and physical properties to the measured intensity or alternatively one can use an inverse model which starts from the intensities and models the surface normals. Here we use an inverse model which leverages deep learning's ability to learn from data; a convolutional neural network is used to estimate the surface normal from the sidescan. Thus the internal properties of the seabed are only implicitly learned. Once this information is estimated, a bathymetric map can be reconstructed through an optimization framework that also includes altimeter readings to provide a sparse depth profile as a constraint. Implicit neural representation learning was recently proposed to represent the bathymetric map in such an optimization framework. In this article, we use a neural network to represent the map and optimize it under constraints of altimeter points and estimated surface normal from sidescan. By fusing multiple observations from different angles from several sidescan lines, the estimated results are improved through optimization. We demonstrate the efficiency and scalability of the approach by reconstructing a high-quality bathymetry using sidescan data from a large sidescan survey. We compare the proposed data-driven inverse model approach of modeling a sidescan with a forward Lambertian model. We assess the quality of each reconstruction by comparing it with data constructed from a multibeam sensor. We are thus able to discuss the strengths and weaknesses of each approach.
Profiling and Evolution of Intellectual Property
Apr 20, 2022In recent years, with the rapid growth of Internet data, the number and types of scientific and technological resources are also rapidly expanding. However, the increase in the number and category of information data will also increase the cost of information acquisition. For technology-based enterprises or users, in addition to general papers, patents, etc., policies related to technology or the development of their industries should also belong to a type of scientific and technological resources. The cost and difficulty of acquiring users. Extracting valuable science and technology policy resources from a huge amount of data with mixed contents and providing accurate and fast retrieval will help to break down information barriers and reduce the cost of information acquisition, which has profound social significance and social utility. This article focuses on the difficulties and problems in the field of science and technology policy, and introduces related technologies and developments.
Two-Stage COVID19 Classification Using BERT Features
Jun 29, 2022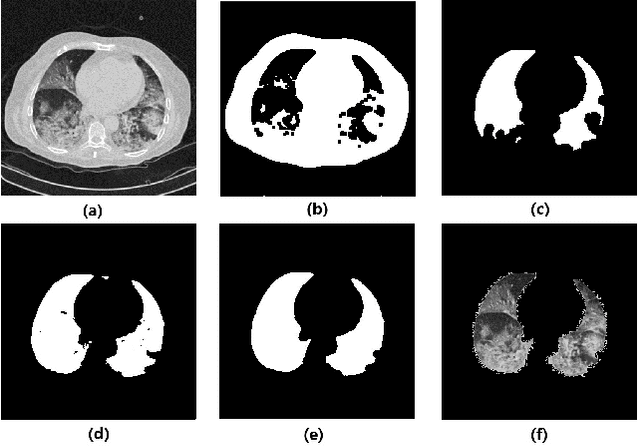
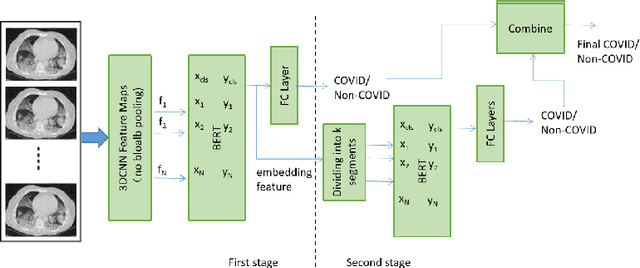
We propose an automatic COVID1-19 diagnosis framework from lung CT-scan slice images using double BERT feature extraction. In the first BERT feature extraction, A 3D-CNN is first used to extract CNN internal feature maps. Instead of using the global average pooling, a late BERT temporal pooing is used to aggregate the temporal information in these feature maps, followed by a classification layer. This 3D-CNN-BERT classification network is first trained on sampled fixed number of slice images from every original CT scan volume. In the second stage, the 3D-CNN-BERT embedding features are extracted on all slice images of every CT scan volume, and these features are averaged into a fixed number of segments. Then another BERT network is used to aggregate these multiple features into a single feature followed by another classification layer. The classification results of both stages are combined to generate final outputs. On the validation dataset, we achieve macro F1 score of 0.9164.
Uzbek Sentiment Analysis based on local Restaurant Reviews
May 31, 2022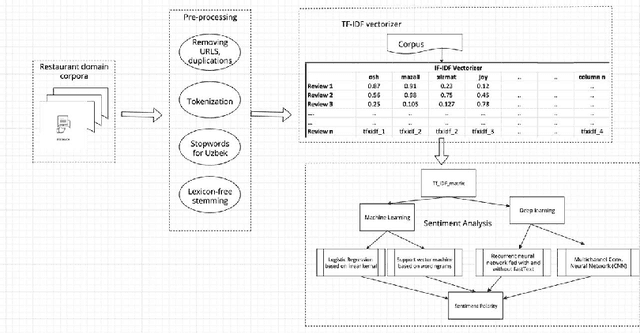

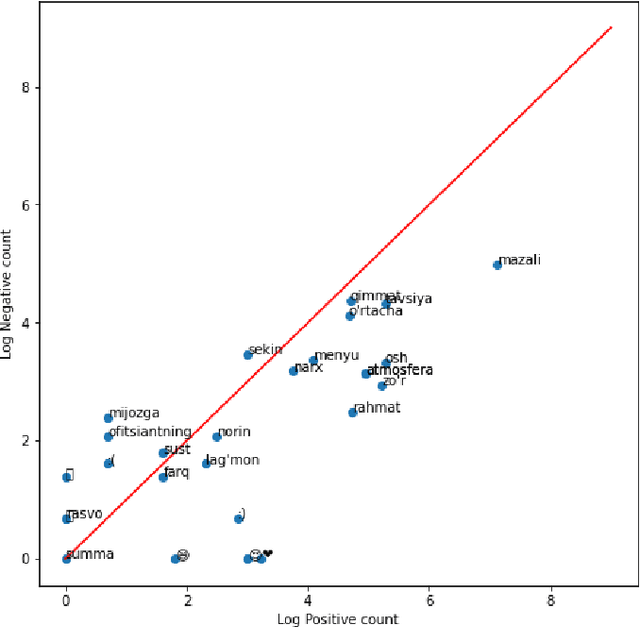
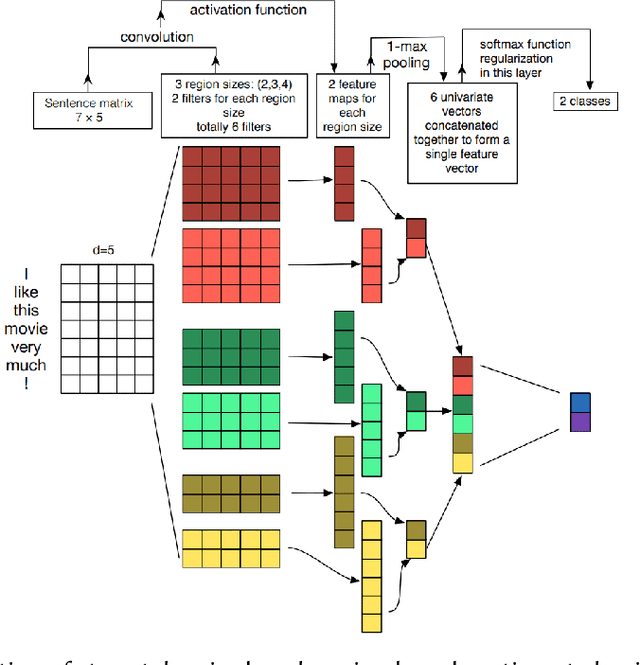
Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model