 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhost Tool Calls: Issue-Time Privacy for Speculative Agent Tools
Jun 01, 2026Tool-augmented language agents speculatively issue likely future tool calls to hide latency, but those calls leak inferred user intent to external services before the agent commits to the branch. Every external observer that received the call retains the disclosure after the agent abandons the branch. Timing is the issue, not authorization: no commit-time cleanup, read-only restriction, or access-control allow-list unsends what an observer already holds. We call these invocations ghost tool calls and propose Speculative Tool Privacy Contracts, a runtime abstraction that treats observation before commitment as a first-class effect, distinct from state mutation. We implement the contracts in a prototype runtime and evaluate twelve policies across three corpora. Speculative dispatch increases what an observer can infer about user intent; post-hoc filters, read-only restrictions, and access-control allow-lists leave that inference intact; only issue-time policies that change or suppress the speculative call's argument or destination projection before dispatch reduce it.
Statistics, Not Scale: Modular Medical Dialogue with Bayesian Belief Engine
Apr 21, 2026Large language models are increasingly deployed as autonomous diagnostic agents, yet they conflate two fundamentally different capabilities: natural-language communication and probabilistic reasoning. We argue that this conflation is an architectural flaw, not an engineering shortcoming. We introduce BMBE (Bayesian Medical Belief Engine), a modular diagnostic dialogue framework that enforces a strict separation between language and reasoning: an LLM serves only as a sensor, parsing patient utterances into structured evidence and verbalising questions, while all diagnostic inference resides in a deterministic, auditable Bayesian engine. Because patient data never enters the LLM, the architecture is private by construction; because the statistical backend is a standalone module, it can be replaced per target population without retraining. This separation yields three properties no autonomous LLM can offer: calibrated selective diagnosis with a continuously adjustable accuracy-coverage tradeoff, a statistical separation gap where even a cheap sensor paired with the engine outperforms a frontier standalone model from the same family at a fraction of the cost, and robustness to adversarial patient communication styles that cause standalone doctors to collapse. We validate across empirical and LLM-generated knowledge bases against frontier LLMs, confirming the advantage is architectural, not informational.
Atomix: Timely, Transactional Tool Use for Reliable Agentic Workflows
Feb 16, 2026LLM agents increasingly act on external systems, yet tool effects are immediate. Under failures, speculation, or contention, losing branches can leak unintended side effects with no safe rollback. We introduce Atomix, a runtime that provides progress-aware transactional semantics for agent tool calls. Atomix tags each call with an epoch, tracks per-resource frontiers, and commits only when progress predicates indicate safety; bufferable effects can be delayed, while externalized effects are tracked and compensated on abort. Across real workloads with fault injection, transactional retry improves task success, while frontier-gated commit strengthens isolation under speculation and contention.
TiME: Tiny Monolingual Encoders for Efficient NLP Pipelines
Dec 16, 2025Today, a lot of research on language models is focused on large, general-purpose models. However, many NLP pipelines only require models with a well-defined, small set of capabilities. While large models are capable of performing the tasks of those smaller models, they are simply not fast enough to process large amounts of data or offer real-time responses. Furthermore, they often use unnecessarily large amounts of energy, leading to sustainability concerns and problems when deploying them on battery-powered devices. In our work, we show how to train small models for such efficiency-critical applications. As opposed to many off-the-shelf NLP pipelines, our models use modern training techniques such as distillation, and offer support for low-resource languages. We call our models TiME (Tiny Monolingual Encoders) and comprehensively evaluate them on a range of common NLP tasks, observing an improved trade-off between benchmark performance on one hand, and throughput, latency and energy consumption on the other. Along the way, we show that distilling monolingual models from multilingual teachers is possible, and likewise distilling models with absolute positional embeddings from teachers with relative positional embeddings.
ReasonBENCH: Benchmarking the (In)Stability of LLM Reasoning
Dec 08, 2025Large language models (LLMs) are increasingly deployed in settings where reasoning, such as multi-step problem solving and chain-of-thought, is essential. Yet, current evaluation practices overwhelmingly report single-run accuracy while ignoring the intrinsic uncertainty that naturally arises from stochastic decoding. This omission creates a blind spot because practitioners cannot reliably assess whether a method's reported performance is stable, reproducible, or cost-consistent. We introduce ReasonBENCH, the first benchmark designed to quantify the underlying instability in LLM reasoning. ReasonBENCH provides (i) a modular evaluation library that standardizes reasoning frameworks, models, and tasks, (ii) a multi-run protocol that reports statistically reliable metrics for both quality and cost, and (iii) a public leaderboard to encourage variance-aware reporting. Across tasks from different domains, we find that the vast majority of reasoning strategies and models exhibit high instability. Notably, even strategies with similar average performance can display confidence intervals up to four times wider, and the top-performing methods often incur higher and less stable costs. Such instability compromises reproducibility across runs and, consequently, the reliability of reported performance. To better understand these dynamics, we further analyze the impact of prompts, model families, and scale on the trade-off between solve rate and stability. Our results highlight reproducibility as a critical dimension for reliable LLM reasoning and provide a foundation for future reasoning methods and uncertainty quantification techniques. ReasonBENCH is publicly available at https://github.com/au-clan/ReasonBench .
Fleet of Agents: Coordinated Problem Solving with Large Language Models using Genetic Particle Filtering
May 07, 2024



Large language models (LLMs) have significantly evolved, moving from simple output generation to complex reasoning and from stand-alone usage to being embedded into broader frameworks. In this paper, we introduce \emph{Fleet of Agents (FoA)}, a novel framework utilizing LLMs as agents to navigate through dynamic tree searches, employing a genetic-type particle filtering approach. FoA spawns a multitude of agents, each exploring autonomously, followed by a selection phase where resampling based on a heuristic value function optimizes the balance between exploration and exploitation. This mechanism enables dynamic branching, adapting the exploration strategy based on discovered solutions. We experimentally validate FoA using two benchmark tasks, "Game of 24" and "Mini-Crosswords". FoA outperforms the previously proposed Tree-of-Thoughts method in terms of efficacy and efficiency: it significantly decreases computational costs (by calling the value function less frequently) while preserving comparable or even superior accuracy.
Flows: Building Blocks of Reasoning and Collaborating AI
Aug 02, 2023



Recent advances in artificial intelligence (AI) have produced highly capable and controllable systems. This creates unprecedented opportunities for structured reasoning as well as collaboration among multiple AI systems and humans. To fully realize this potential, it is essential to develop a principled way of designing and studying such structured interactions. For this purpose, we introduce the conceptual framework of Flows: a systematic approach to modeling complex interactions. Flows are self-contained building blocks of computation, with an isolated state, communicating through a standardized message-based interface. This modular design allows Flows to be recursively composed into arbitrarily nested interactions, with a substantial reduction of complexity. Crucially, any interaction can be implemented using this framework, including prior work on AI--AI and human--AI interactions, prompt engineering schemes, and tool augmentation. We demonstrate the potential of Flows on the task of competitive coding, a challenging task on which even GPT-4 struggles. Our results suggest that structured reasoning and collaboration substantially improve generalization, with AI-only Flows adding +$21$ and human--AI Flows adding +$54$ absolute points in terms of solve rate. To support rapid and rigorous research, we introduce the aiFlows library. The library comes with a repository of Flows that can be easily used, extended, and composed into novel, more complex Flows. The aiFlows library is available at https://github.com/epfl-dlab/aiflows. Data and Flows for reproducing our experiments are available at https://github.com/epfl-dlab/cc_flows.
Fast Interactive Search with a Scale-Free Comparison Oracle
Jun 02, 2023A comparison-based search algorithm lets a user find a target item $t$ in a database by answering queries of the form, ``Which of items $i$ and $j$ is closer to $t$?'' Instead of formulating an explicit query (such as one or several keywords), the user navigates towards the target via a sequence of such (typically noisy) queries. We propose a scale-free probabilistic oracle model called $\gamma$-CKL for such similarity triplets $(i,j;t)$, which generalizes the CKL triplet model proposed in the literature. The generalization affords independent control over the discriminating power of the oracle and the dimension of the feature space containing the items. We develop a search algorithm with provably exponential rate of convergence under the $\gamma$-CKL oracle, thanks to a backtracking strategy that deals with the unavoidable errors in updating the belief region around the target. We evaluate the performance of the algorithm both over the posited oracle and over several real-world triplet datasets. We also report on a comprehensive user study, where human subjects navigate a database of face portraits.
Broccoli: Sprinkling Lightweight Vocabulary Learning into Everyday Information Diets
Apr 16, 2021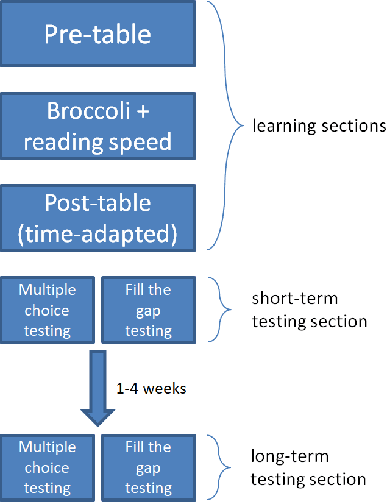
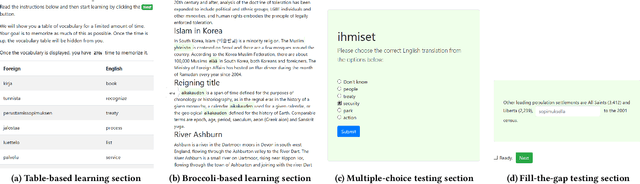
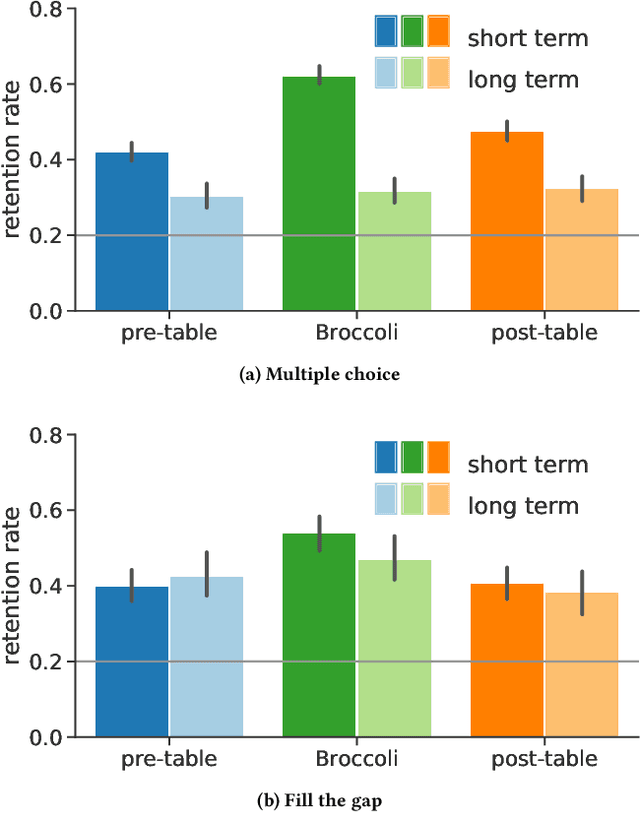
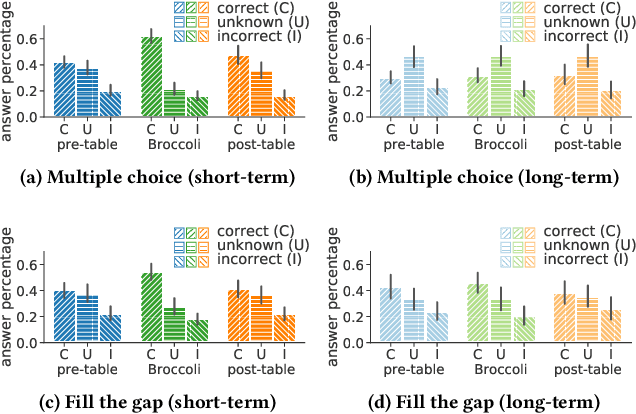
The learning of a new language remains to this date a cognitive task that requires considerable diligence and willpower, recent advances and tools notwithstanding. In this paper, we propose Broccoli, a new paradigm aimed at reducing the required effort by seamlessly embedding vocabulary learning into users' everyday information diets. This is achieved by inconspicuously switching chosen words encountered by the user for their translation in the target language. Thus, by seeing words in context, the user can assimilate new vocabulary without much conscious effort. We validate our approach in a careful user study, finding that the efficacy of the lightweight Broccoli approach is competitive with traditional, memorization-based vocabulary learning. The low cognitive overhead is manifested in a pronounced decrease in learners' usage of mnemonic learning strategies, as compared to traditional learning. Finally, we establish that language patterns in typical information diets are compatible with spaced-repetition strategies, thus enabling an efficient use of the Broccoli paradigm. Overall, our work establishes the feasibility of a novel and powerful "install-and-forget" approach for embedded language acquisition.