 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Counterfactual Intervention Feature Transfer for Visible-Infrared Person Re-identification
Aug 01, 2022
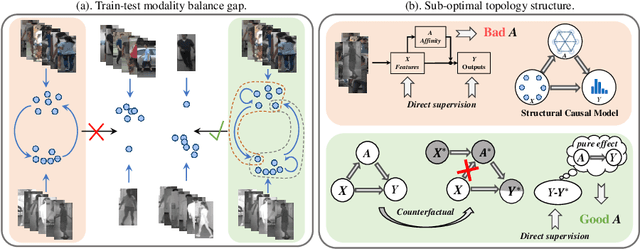
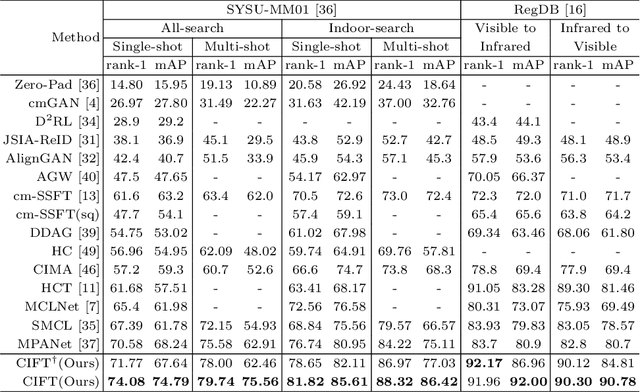
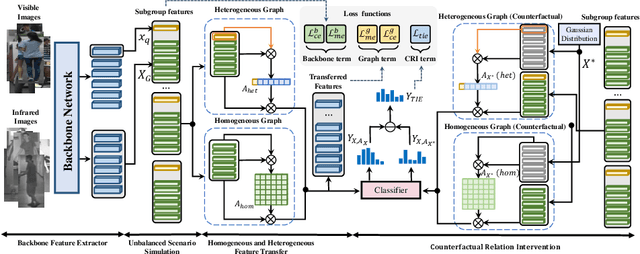
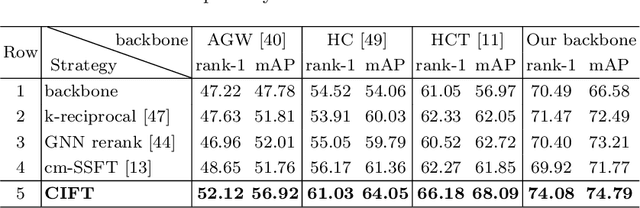
Graph-based models have achieved great success in person re-identification tasks recently, which compute the graph topology structure (affinities) among different people first and then pass the information across them to achieve stronger features. But we find existing graph-based methods in the visible-infrared person re-identification task (VI-ReID) suffer from bad generalization because of two issues: 1) train-test modality balance gap, which is a property of VI-ReID task. The number of two modalities data are balanced in the training stage, but extremely unbalanced in inference, causing the low generalization of graph-based VI-ReID methods. 2) sub-optimal topology structure caused by the end-to-end learning manner to the graph module. We analyze that the well-trained input features weaken the learning of graph topology, making it not generalized enough during the inference process. In this paper, we propose a Counterfactual Intervention Feature Transfer (CIFT) method to tackle these problems. Specifically, a Homogeneous and Heterogeneous Feature Transfer (H2FT) is designed to reduce the train-test modality balance gap by two independent types of well-designed graph modules and an unbalanced scenario simulation. Besides, a Counterfactual Relation Intervention (CRI) is proposed to utilize the counterfactual intervention and causal effect tools to highlight the role of topology structure in the whole training process, which makes the graph topology structure more reliable. Extensive experiments on standard VI-ReID benchmarks demonstrate that CIFT outperforms the state-of-the-art methods under various settings.
On the Importance of 3D Surface Information for Remote Sensing Classification Tasks
Apr 26, 2021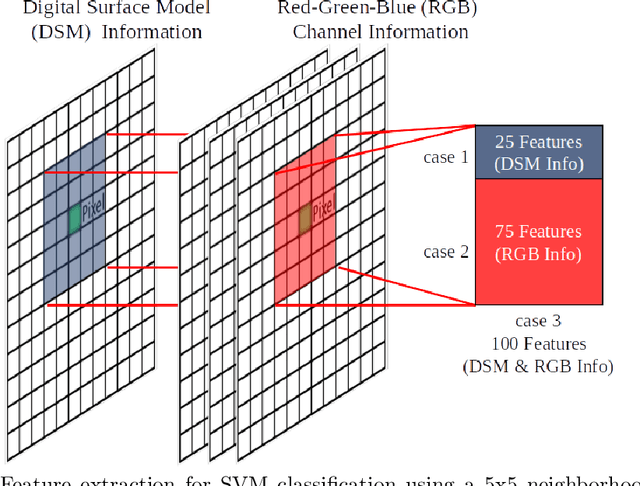

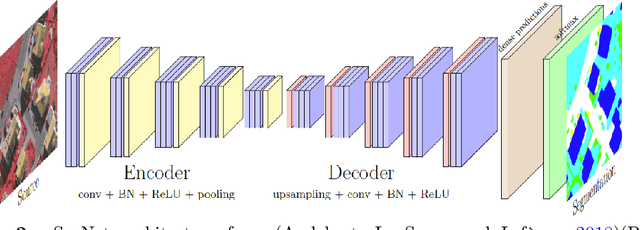
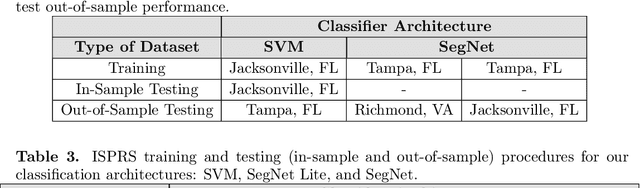
There has been a surge in remote sensing machine learning applications that operate on data from active or passive sensors as well as multi-sensor combinations (Ma et al. (2019)). Despite this surge, however, there has been relatively little study on the comparative value of 3D surface information for machine learning classification tasks. Adding 3D surface information to RGB imagery can provide crucial geometric information for semantic classes such as buildings, and can thus improve out-of-sample predictive performance. In this paper, we examine in-sample and out-of-sample classification performance of Fully Convolutional Neural Networks (FCNNs) and Support Vector Machines (SVMs) trained with and without 3D normalized digital surface model (nDSM) information. We assess classification performance using multispectral imagery from the International Society for Photogrammetry and Remote Sensing (ISPRS) 2D Semantic Labeling contest and the United States Special Operations Command (USSOCOM) Urban 3D Challenge. We find that providing RGB classifiers with additional 3D nDSM information results in little increase in in-sample classification performance, suggesting that spectral information alone may be sufficient for the given classification tasks. However, we observe that providing these RGB classifiers with additional nDSM information leads to significant gains in out-of-sample predictive performance. Specifically, we observe an average improvement in out-of-sample all-class accuracy of 14.4% on the ISPRS dataset and an average improvement in out-of-sample F1 score of 8.6% on the USSOCOM dataset. In addition, the experiments establish that nDSM information is critical in machine learning and classification settings that face training sample scarcity.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022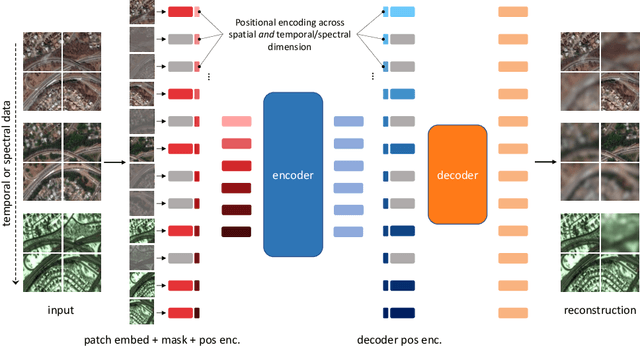

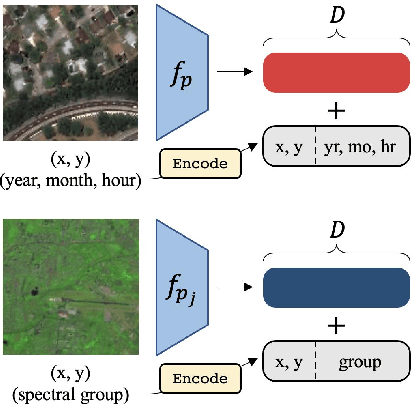
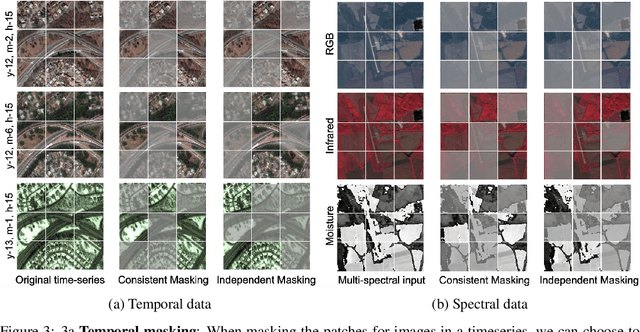
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Minimizing the Expected Posterior Entropy Yields Optimal Summary Statistics
Jun 06, 2022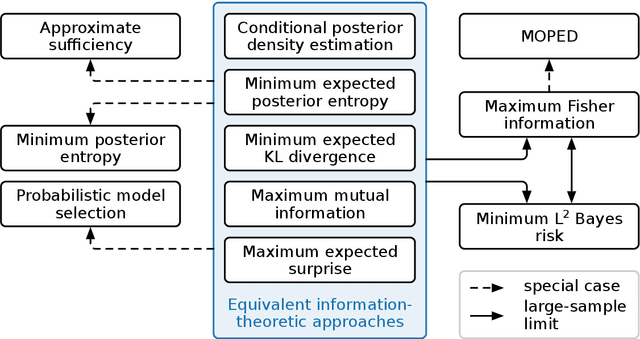
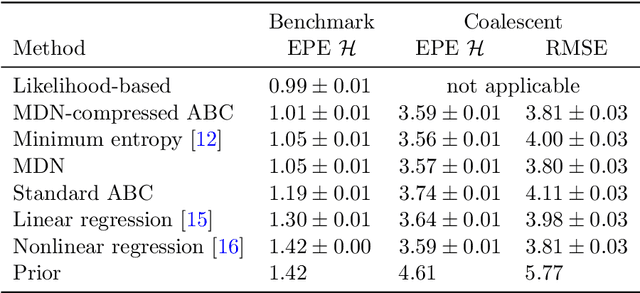
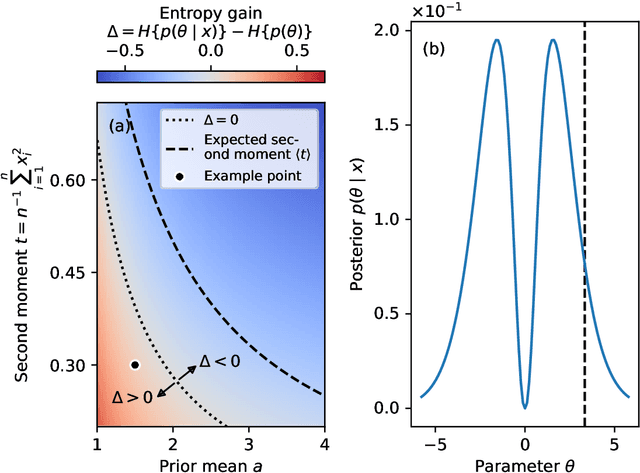
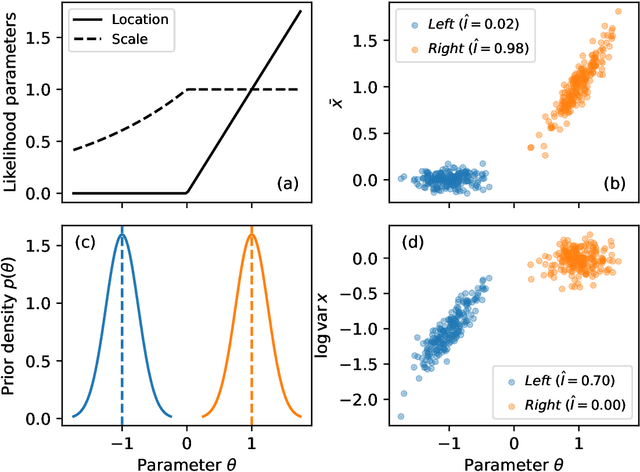
Extracting low-dimensional summary statistics from large datasets is essential for efficient (likelihood-free) inference. We propose obtaining summary statistics by minimizing the expected posterior entropy (EPE) under the prior predictive distribution of the model. We show that minimizing the EPE is equivalent to learning a conditional density estimator for the posterior as well as other information-theoretic approaches. Further summary extraction methods (including minimizing the $L^2$ Bayes risk, maximizing the Fisher information, and model selection approaches) are special or limiting cases of EPE minimization. We demonstrate that the approach yields high fidelity summary statistics by applying it to both a synthetic benchmark as well as a population genetics problem. We not only offer concrete recommendations for practitioners but also provide a unifying perspective for obtaining informative summary statistics.
DropKey
Aug 08, 2022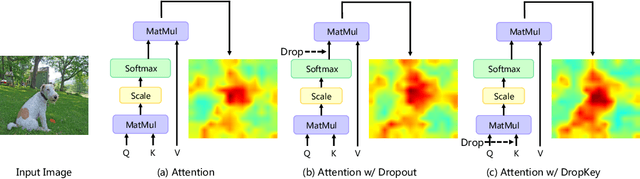

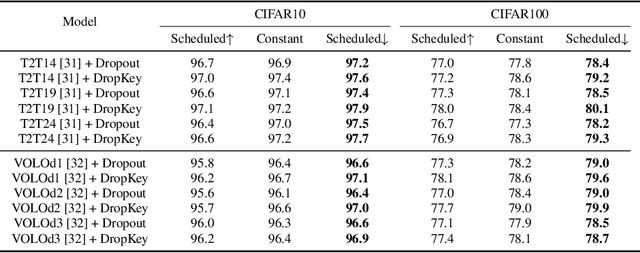
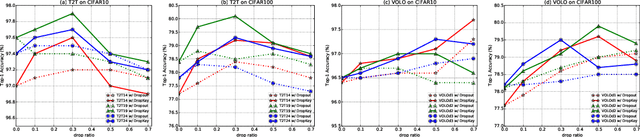
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.
Extracting Radiological Findings With Normalized Anatomical Information Using a Span-Based BERT Relation Extraction Model
Aug 20, 2021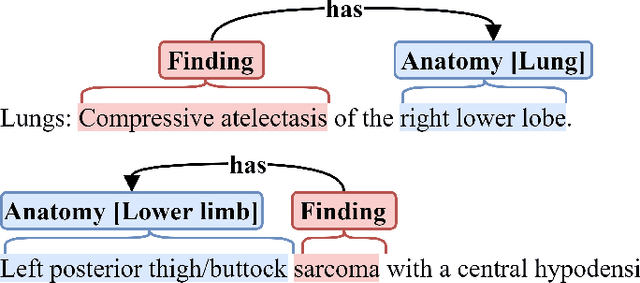
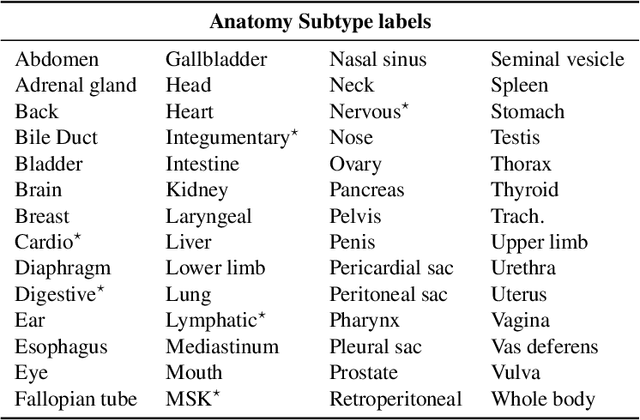
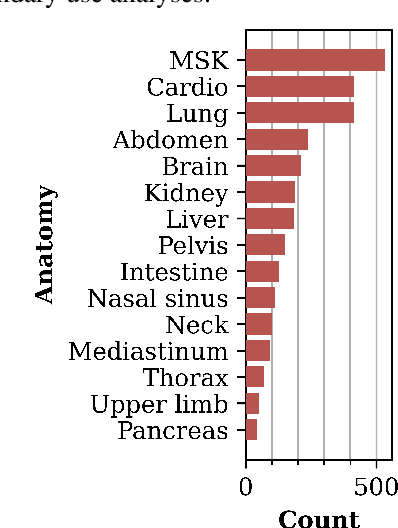
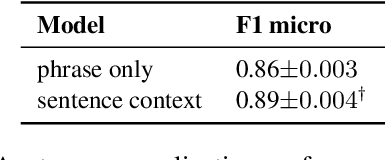
Medical imaging is critical to the diagnosis and treatment of numerous medical problems, including many forms of cancer. Medical imaging reports distill the findings and observations of radiologists, creating an unstructured textual representation of unstructured medical images. Large-scale use of this text-encoded information requires converting the unstructured text to a structured, semantic representation. We explore the extraction and normalization of anatomical information in radiology reports that is associated with radiological findings. We investigate this extraction and normalization task using a span-based relation extraction model that jointly extracts entities and relations using BERT. This work examines the factors that influence extraction and normalization performance, including the body part/organ system, frequency of occurrence, span length, and span diversity. It discusses approaches for improving performance and creating high-quality semantic representations of radiological phenomena.
Correlation in Neuronal Calcium Spiking: Quantification based on Empirical Mutual Information Rate
May 07, 2021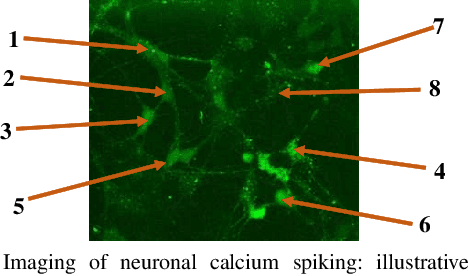

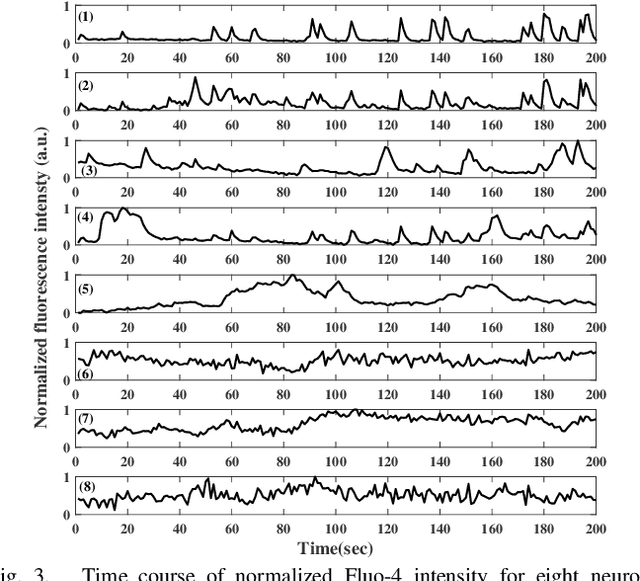

Quantification of neuronal correlations in neuron populations helps us to understand neural coding rules. Such quantification could also reveal how neurons encode information in normal and disease conditions like Alzheimer's and Parkinson's. While neurons communicate with each other by transmitting spikes, there would be a change in calcium concentration within the neurons inherently. Accordingly, there would be correlations in calcium spike trains and they could have heterogeneous memory structures. In this context, estimation of mutual information rate in calcium spike trains assumes primary significance. However, such estimation is difficult with available methods which would consider longer blocks for convergence without noticing that neuronal information changes in short time windows. Against this backdrop, we propose a faster method that exploits the memory structures in pair of calcium spike trains to quantify mutual information shared between them. Our method has shown superior performance with example Markov processes as well as experimental spike trains. Such mutual information rate analysis could be used to identify signatures of neuronal behavior in large populations in normal and abnormal conditions.
A Data-Efficient Deep Learning Framework for Segmentation and Classification of Histopathology Images
Jul 16, 2022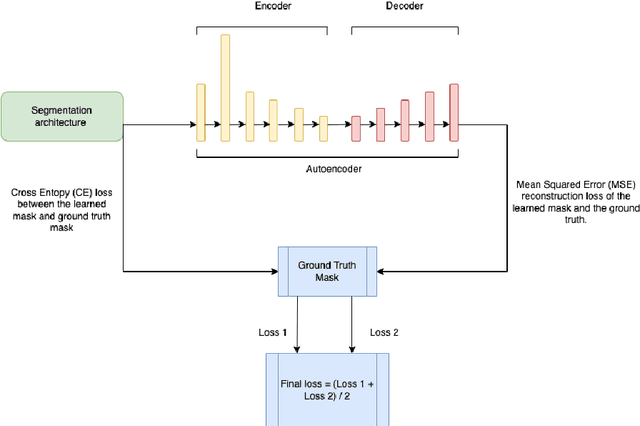
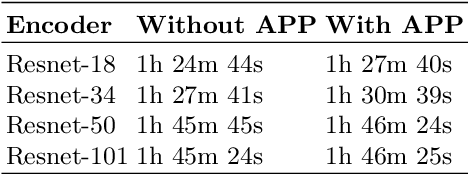
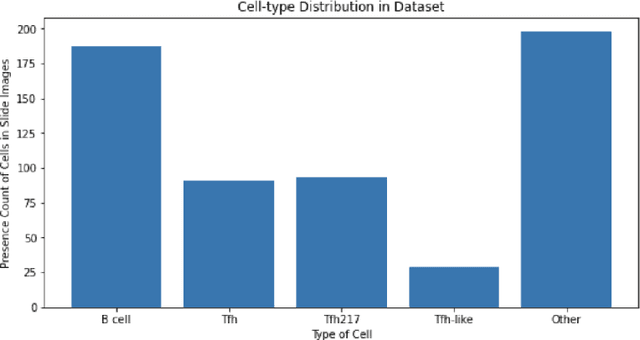
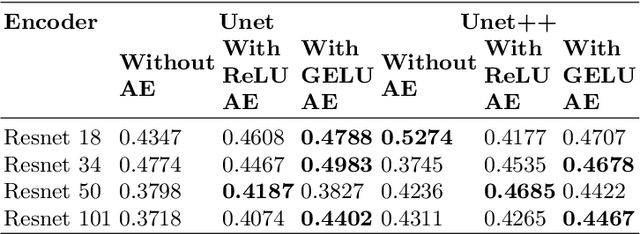
The current study of cell architecture of inflammation in histopathology images commonly performed for diagnosis and research purposes excludes a lot of information available on the biopsy slide. In autoimmune diseases, major outstanding research questions remain regarding which cell types participate in inflammation at the tissue level,and how they interact with each other. While these questions can be partially answered using traditional methods, artificial intelligence approaches for segmentation and classification provide a much more efficient method to understand the architecture of inflammation in autoimmune disease, holding a great promise for novel insights. In this paper, we empirically develop deep learning approaches that uses dermatomyositis biopsies of human tissue to detect and identify inflammatory cells. Our approach improves classification performance by 26% and segmentation performance by 5%. We also propose a novel post-processing autoencoder architecture that improves segmentation performance by an additional 3%. We have open-sourced our approach and architecture at https://github.com/pranavsinghps1/DEDL
Deep Preconditioners and their application to seismic wavefield processing
Jul 20, 2022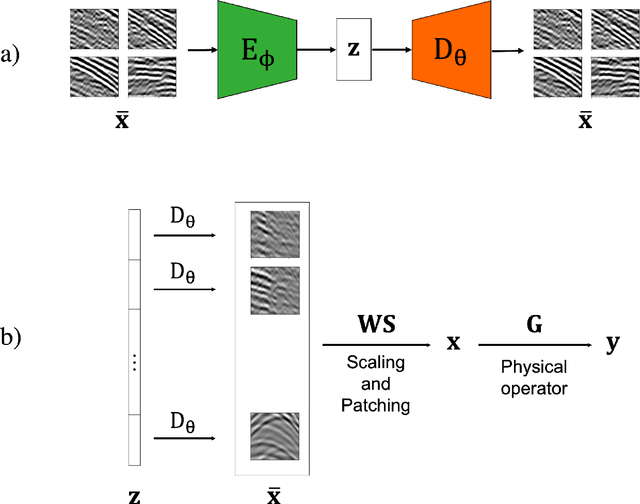
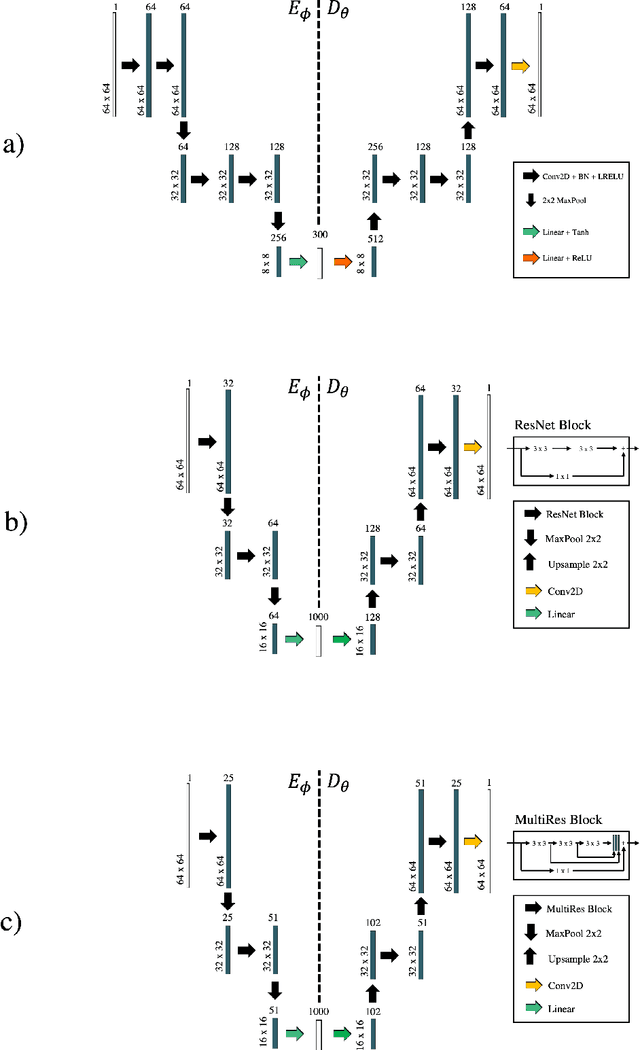
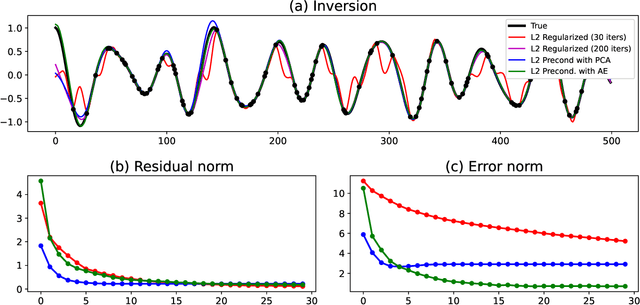
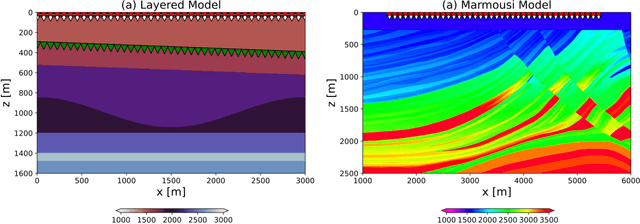
Seismic data processing heavily relies on the solution of physics-driven inverse problems. In the presence of unfavourable data acquisition conditions (e.g., regular or irregular coarse sampling of sources and/or receivers), the underlying inverse problem becomes very ill-posed and prior information is required to obtain a satisfactory solution. Sparsity-promoting inversion, coupled with fixed-basis sparsifying transforms, represent the go-to approach for many processing tasks due to its simplicity of implementation and proven successful application in a variety of acquisition scenarios. Leveraging the ability of deep neural networks to find compact representations of complex, multi-dimensional vector spaces, we propose to train an AutoEncoder network to learn a direct mapping between the input seismic data and a representative latent manifold. The trained decoder is subsequently used as a nonlinear preconditioner for the physics-driven inverse problem at hand. Synthetic and field data are presented for a variety of seismic processing tasks and the proposed nonlinear, learned transformations are shown to outperform fixed-basis transforms and convergence faster to the sought solution.
CSDN: Cross-modal Shape-transfer Dual-refinement Network for Point Cloud Completion
Aug 01, 2022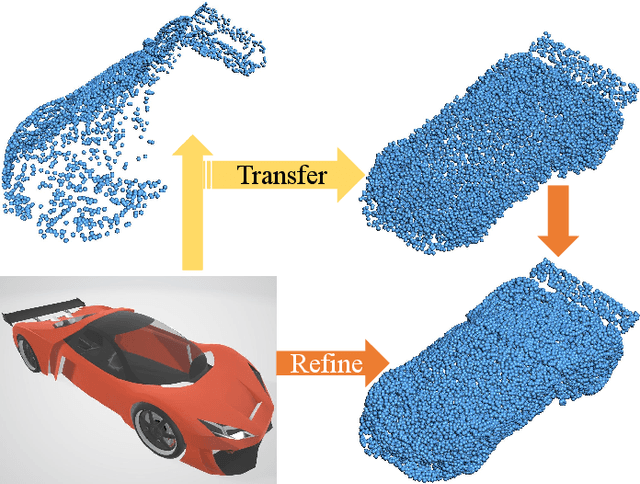
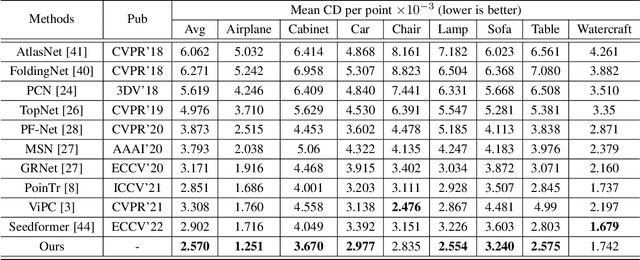
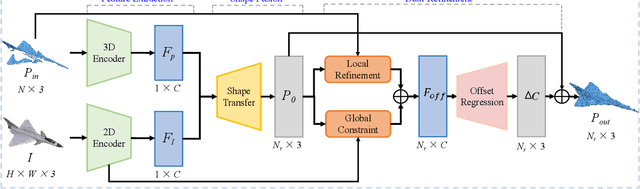
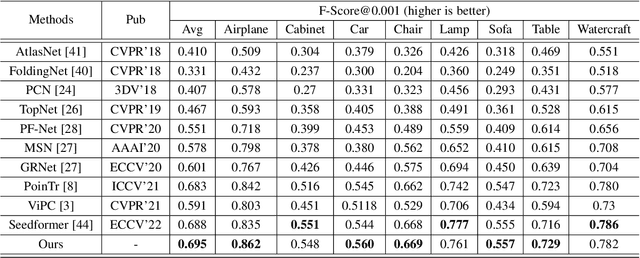
How will you repair a physical object with some missings? You may imagine its original shape from previously captured images, recover its overall (global) but coarse shape first, and then refine its local details. We are motivated to imitate the physical repair procedure to address point cloud completion. To this end, we propose a cross-modal shape-transfer dual-refinement network (termed CSDN), a coarse-to-fine paradigm with images of full-cycle participation, for quality point cloud completion. CSDN mainly consists of "shape fusion" and "dual-refinement" modules to tackle the cross-modal challenge. The first module transfers the intrinsic shape characteristics from single images to guide the geometry generation of the missing regions of point clouds, in which we propose IPAdaIN to embed the global features of both the image and the partial point cloud into completion. The second module refines the coarse output by adjusting the positions of the generated points, where the local refinement unit exploits the geometric relation between the novel and the input points by graph convolution, and the global constraint unit utilizes the input image to fine-tune the generated offset. Different from most existing approaches, CSDN not only explores the complementary information from images but also effectively exploits cross-modal data in the whole coarse-to-fine completion procedure. Experimental results indicate that CSDN performs favorably against ten competitors on the cross-modal benchmark.