 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Dynamic Mode Decomposition Workflow with In-Situ Visualization and Data Compression
Aug 16, 2022
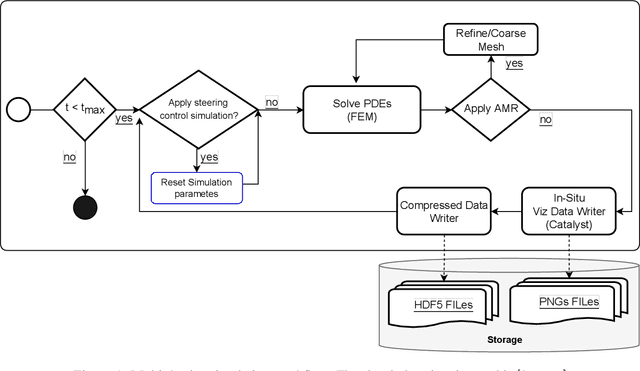

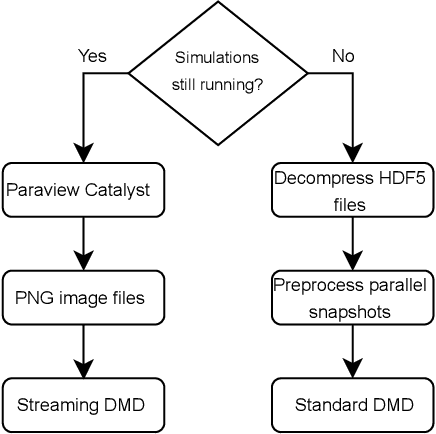
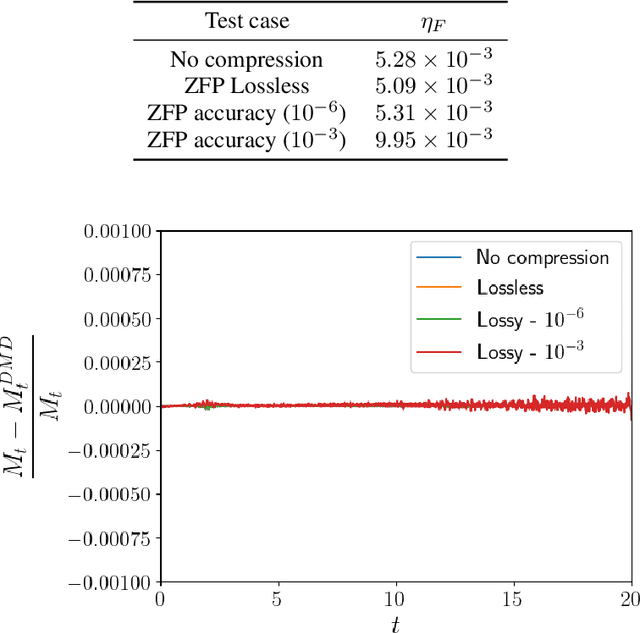
Modern computational science and engineering applications are being improved by the advances in scientific machine learning. Data-driven methods such as Dynamic Mode Decomposition (DMD) can extract coherent structures from spatio-temporal data generated from dynamical systems and infer different scenarios for said systems. The spatio-temporal data comes as snapshots containing spatial information for each time instant. In modern engineering applications, the generation of high-dimensional snapshots can be time and/or resource-demanding. In the present study, we consider two strategies for enhancing DMD workflow in large numerical simulations: (i) snapshots compression to relieve disk pressure; (ii) the use of in situ visualization images to reconstruct the dynamics (or part of) in runtime. We evaluate our approaches with two 3D fluid dynamics simulations and consider DMD to reconstruct the solutions. Results reveal that snapshot compression considerably reduces the required disk space. We have observed that lossy compression reduces storage by almost $50\%$ with low relative errors in the signal reconstructions and other quantities of interest. We also extend our analysis to data generated on-the-fly, using in-situ visualization tools to generate image files of our state vectors during runtime. On large simulations, the generation of snapshots may be slow enough to use batch algorithms for inference. Streaming DMD takes advantage of the incremental SVD algorithm and updates the modes with the arrival of each new snapshot. We use streaming DMD to reconstruct the dynamics from in-situ generated images. We show that this process is efficient, and the reconstructed dynamics are accurate.
Perfusion imaging in deep prostate cancer detection from mp-MRI: can we take advantage of it?
Jul 06, 2022

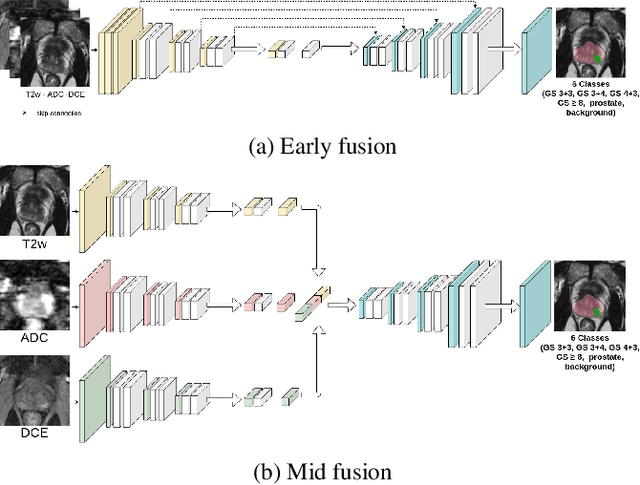
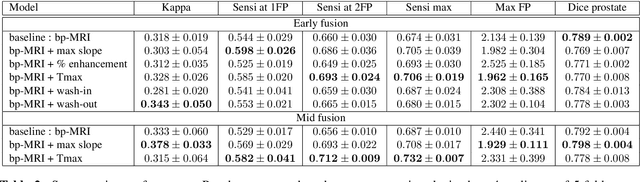
To our knowledge, all deep computer-aided detection and diagnosis (CAD) systems for prostate cancer (PCa) detection consider bi-parametric magnetic resonance imaging (bp-MRI) only, including T2w and ADC sequences while excluding the 4D perfusion sequence,which is however part of standard clinical protocols for this diagnostic task. In this paper, we question strategies to integrate information from perfusion imaging in deep neural architectures. To do so, we evaluate several ways to encode the perfusion information in a U-Net like architecture, also considering early versus mid fusion strategies. We compare performance of multiparametric MRI (mp-MRI) models with the baseline bp-MRI model based on a private dataset of 219 mp-MRI exams. Perfusion maps derived from dynamic contrast enhanced MR exams are shown to positively impact segmentation and grading performance of PCa lesions, especially the 3D MR volume corresponding to the maximum slope of the wash-in curve as well as Tmax perfusion maps. The latter mp-MRI models indeed outperform the bp-MRI one whatever the fusion strategy, with Cohen's kappa score of 0.318$\pm$0.019 for the bp-MRI model and 0.378 $\pm$ 0.033 for the model including the maximum slope with a mid fusion strategy, also achieving competitive Cohen's kappa score compared to state of the art.
Information Ranking Using Optimum-Path Forest
Feb 16, 2021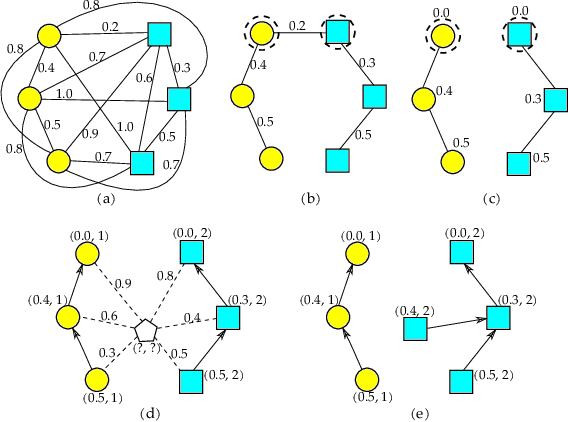
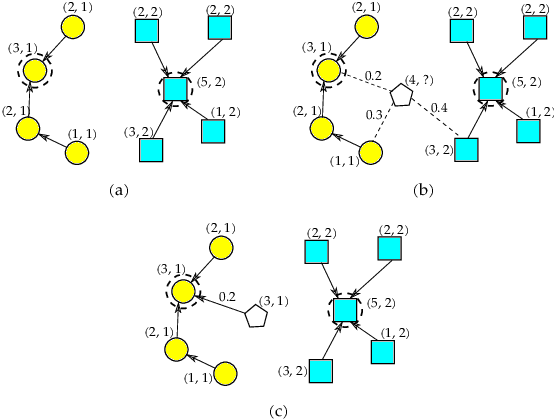
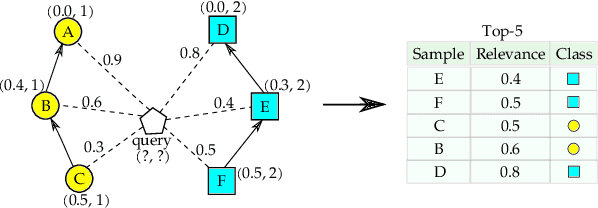

The task of learning to rank has been widely studied by the machine learning community, mainly due to its use and great importance in information retrieval, data mining, and natural language processing. Therefore, ranking accurately and learning to rank are crucial tasks. Context-Based Information Retrieval systems have been of great importance to reduce the effort of finding relevant data. Such systems have evolved by using machine learning techniques to improve their results, but they are mainly dependent on user feedback. Although information retrieval has been addressed in different works along with classifiers based on Optimum-Path Forest (OPF), these have so far not been applied to the learning to rank task. Therefore, the main contribution of this work is to evaluate classifiers based on Optimum-Path Forest, in such a context. Experiments were performed considering the image retrieval and ranking scenarios, and the performance of OPF-based approaches was compared to the well-known SVM-Rank pairwise technique and a baseline based on distance calculation. The experiments showed competitive results concerning precision and outperformed traditional techniques in terms of computational load.
MSP-Former: Multi-Scale Projection Transformer for Single Image Desnowing
Jul 17, 2022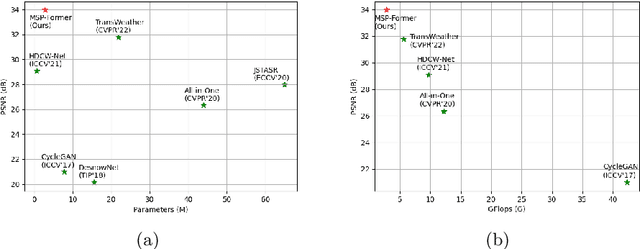
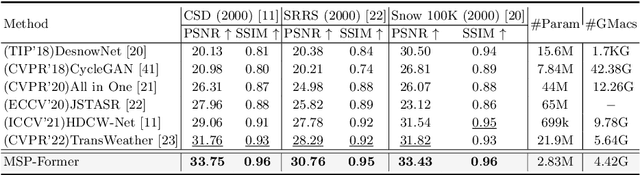

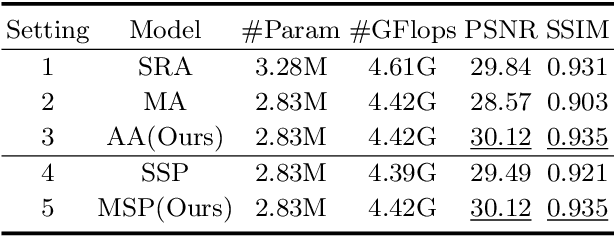
Image restoration of snow scenes in severe weather is a difficult task. Snow images have complex degradations and are cluttered over clean images, changing the distribution of clean images. The previous methods based on CNNs are challenging to remove perfectly in restoring snow scenes due to their local inductive biases' lack of a specific global modeling ability. In this paper, we apply the vision transformer to the task of snow removal from a single image. Specifically, we propose a parallel network architecture split along the channel, performing local feature refinement and global information modeling separately. We utilize a channel shuffle operation to combine their respective strengths to enhance network performance. Second, we propose the MSP module, which utilizes multi-scale avgpool to aggregate information of different sizes and simultaneously performs multi-scale projection self-attention on multi-head self-attention to improve the representation ability of the model under different scale degradations. Finally, we design a lightweight and simple local capture module, which can refine the local capture capability of the model. In the experimental part, we conduct extensive experiments to demonstrate the superiority of our method. We compared the previous snow removal methods on three snow scene datasets. The experimental results show that our method surpasses the state-of-the-art methods with fewer parameters and computation. We achieve substantial growth by 1.99dB and SSIM 0.03 on the CSD test dataset. On the SRRS and Snow100K datasets, we also increased PSNR by 2.47dB and 1.62dB compared with the Transweather approach and improved by 0.03 in SSIM. In the visual comparison section, our MSP-Former also achieves better visual effects than existing methods, proving the usability of our method.
Anomalous Sound Detection using Spectral-Temporal Information Fusion
Jan 14, 2022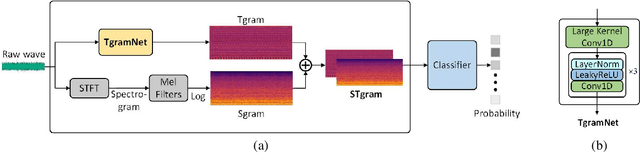

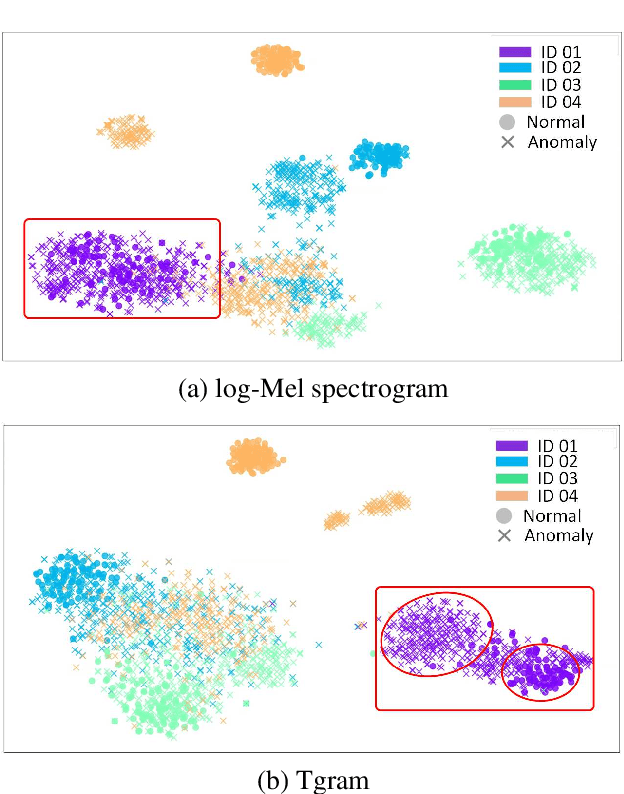
Unsupervised anomalous sound detection aims to detect unknown abnormal sounds of machines from normal sounds. However, the state-of-the-art approaches are not always stable and perform dramatically differently even for machines of the same type, making it impractical for general applications. This paper proposes a spectral-temporal fusion based self-supervised method to model the feature of the normal sound, which improves the stability and performance consistency in detection of anomalous sounds from individual machines, even of the same type. Experiments on the DCASE 2020 Challenge Task 2 dataset show that the proposed method achieved 81.39%, 83.48%, 98.22% and 98.83% in terms of the minimum AUC (worst-case detection performance amongst individuals) in four types of real machines (fan, pump, slider and valve), respectively, giving 31.79%, 17.78%, 10.42% and 21.13% improvement compared to the state-of-the-art method, i.e., Glow_Aff. Moreover, the proposed method has improved AUC (average performance of individuals) for all the types of machines in the dataset.
M2HF: Multi-level Multi-modal Hybrid Fusion for Text-Video Retrieval
Aug 16, 2022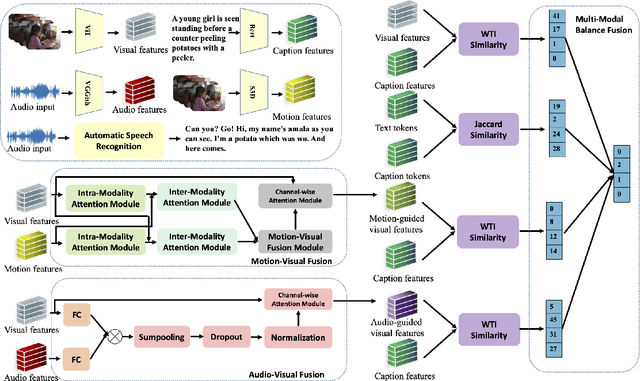
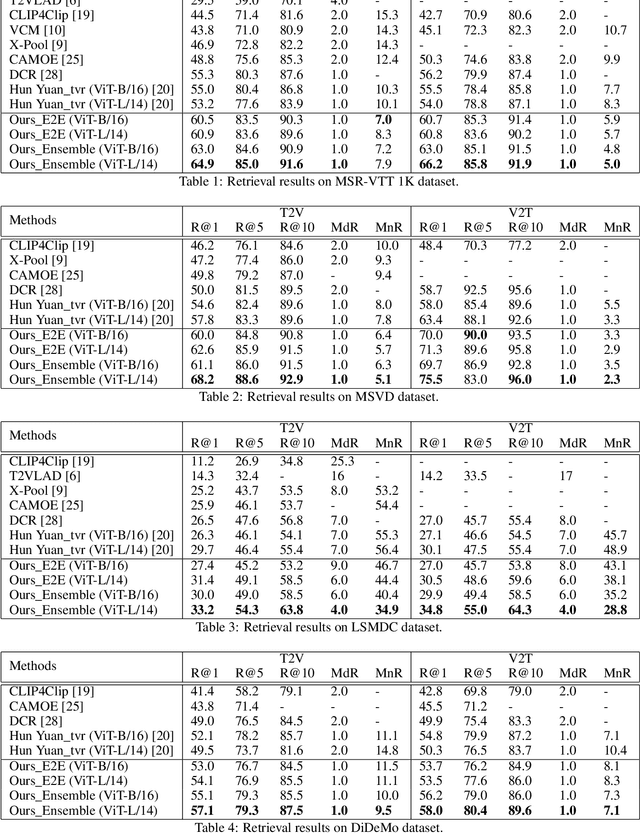


Videos contain multi-modal content, and exploring multi-level cross-modal interactions with natural language queries can provide great prominence to text-video retrieval task (TVR). However, new trending methods applying large-scale pre-trained model CLIP for TVR do not focus on multi-modal cues in videos. Furthermore, the traditional methods simply concatenating multi-modal features do not exploit fine-grained cross-modal information in videos. In this paper, we propose a multi-level multi-modal hybrid fusion (M2HF) network to explore comprehensive interactions between text queries and each modality content in videos. Specifically, M2HF first utilizes visual features extracted by CLIP to early fuse with audio and motion features extracted from videos, obtaining audio-visual fusion features and motion-visual fusion features respectively. Multi-modal alignment problem is also considered in this process. Then, visual features, audio-visual fusion features, motion-visual fusion features, and texts extracted from videos establish cross-modal relationships with caption queries in a multi-level way. Finally, the retrieval outputs from all levels are late fused to obtain final text-video retrieval results. Our framework provides two kinds of training strategies, including an ensemble manner and an end-to-end manner. Moreover, a novel multi-modal balance loss function is proposed to balance the contributions of each modality for efficient end-to-end training. M2HF allows us to obtain state-of-the-art results on various benchmarks, eg, Rank@1 of 64.9\%, 68.2\%, 33.2\%, 57.1\%, 57.8\% on MSR-VTT, MSVD, LSMDC, DiDeMo, and ActivityNet, respectively.
Distributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity
Aug 11, 2022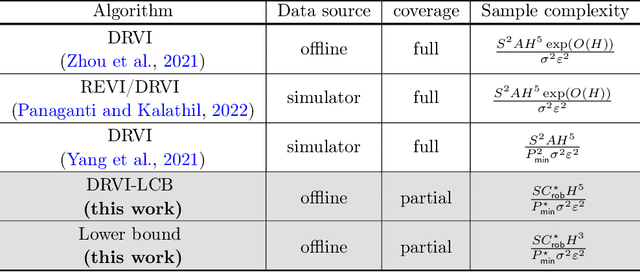
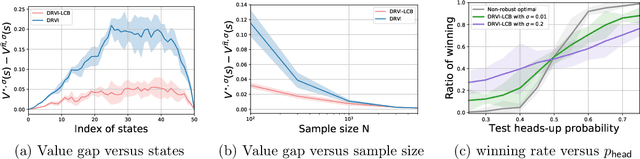
This paper concerns the central issues of model robustness and sample efficiency in offline reinforcement learning (RL), which aims to learn to perform decision making from history data without active exploration. Due to uncertainties and variabilities of the environment, it is critical to learn a robust policy -- with as few samples as possible -- that performs well even when the deployed environment deviates from the nominal one used to collect the history dataset. We consider a distributionally robust formulation of offline RL, focusing on a tabular non-stationary finite-horizon robust Markov decision process with an uncertainty set specified by the Kullback-Leibler divergence. To combat with sample scarcity, a model-based algorithm that combines distributionally robust value iteration with the principle of pessimism in the face of uncertainty is proposed, by penalizing the robust value estimates with a carefully designed data-driven penalty term. Under a mild and tailored assumption of the history dataset that measures distribution shift without requiring full coverage of the state-action space, we establish the finite-sample complexity of the proposed algorithm, and further show it is almost unimprovable in light of a nearly-matching information-theoretic lower bound up to a polynomial factor of the horizon length. To the best our knowledge, this provides the first provably near-optimal robust offline RL algorithm that learns under model uncertainty and partial coverage.
Comparing Performance of Different Linguistically-Backed Word Embeddings for Cyberbullying Detection
Jun 04, 2022In most cases, word embeddings are learned only from raw tokens or in some cases, lemmas. This includes pre-trained language models like BERT. To investigate on the potential of capturing deeper relations between lexical items and structures and to filter out redundant information, we propose to preserve the morphological, syntactic and other types of linguistic information by combining them with the raw tokens or lemmas. This means, for example, including parts-of-speech or dependency information within the used lexical features. The word embeddings can then be trained on the combinations instead of just raw tokens. It is also possible to later apply this method to the pre-training of huge language models and possibly enhance their performance. This would aid in tackling problems which are more sophisticated from the point of view of linguistic representation, such as detection of cyberbullying.
Signal Detection and Inference Based on the Beta Binomial Autoregressive Moving Average Model
Jul 29, 2022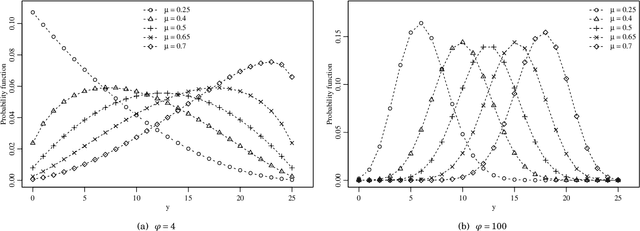
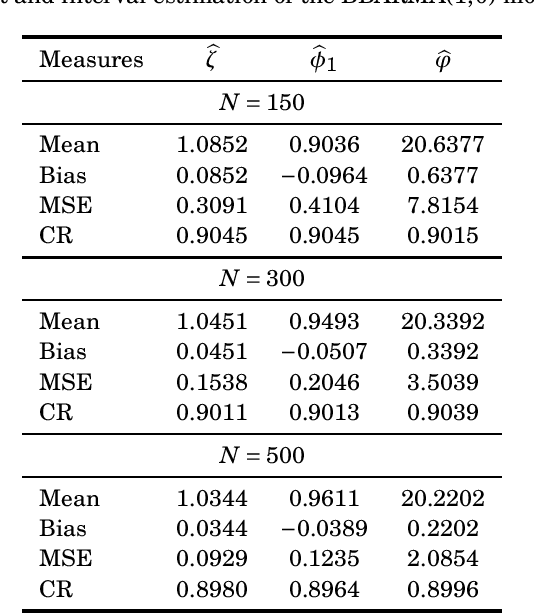
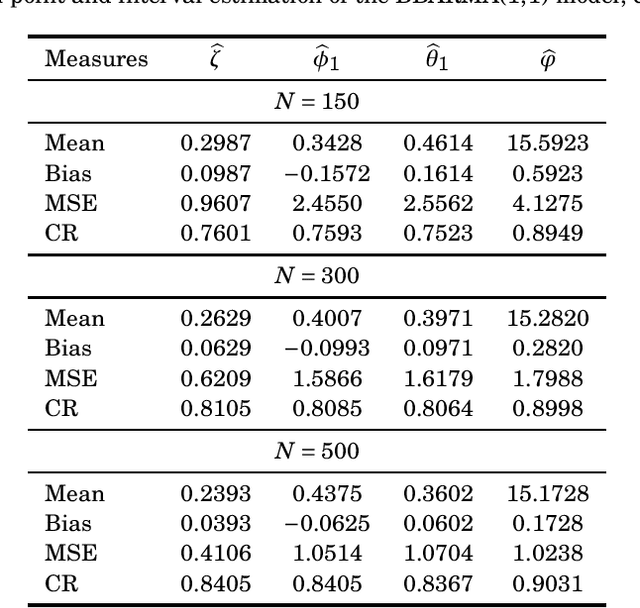
This paper proposes the beta binomial autoregressive moving average model (BBARMA) for modeling quantized amplitude data and bounded count data. The BBARMA model estimates the conditional mean of a beta binomial distributed variable observed over the time by a dynamic structure including: (i) autoregressive and moving average terms; (ii) a set of regressors; and (iii) a link function. Besides introducing the new model, we develop parameter estimation, detection tools, an out-of-signal forecasting scheme, and diagnostic measures. In particular, we provide closed-form expressions for the conditional score vector and the conditional information matrix. The proposed model was submitted to extensive Monte Carlo simulations in order to evaluate the performance of the conditional maximum likelihood estimators and of the proposed detector. The derived detector outperforms the usual ARMA- and Gaussian-based detectors for sinusoidal signal detection. We also presented an experiment for modeling and forecasting the monthly number of rainy days in Recife, Brazil.
* 17 pages, 4 tables, 5 figures
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022
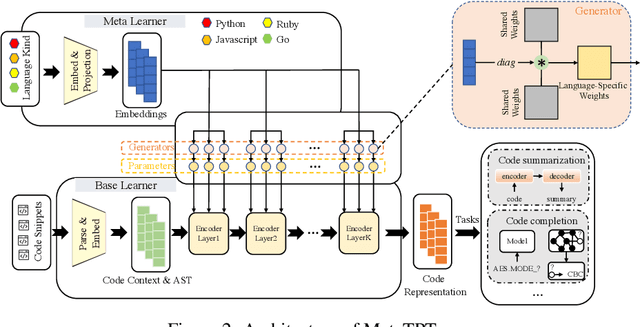
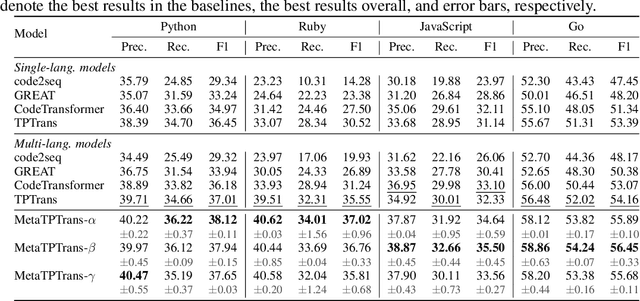
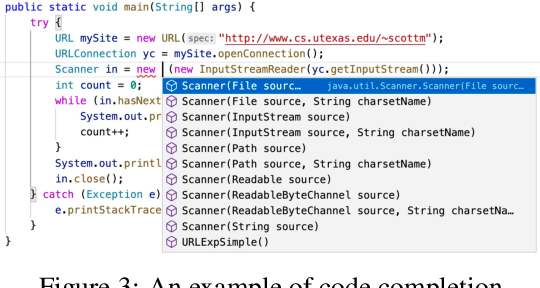
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.