 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity
Paper and Code
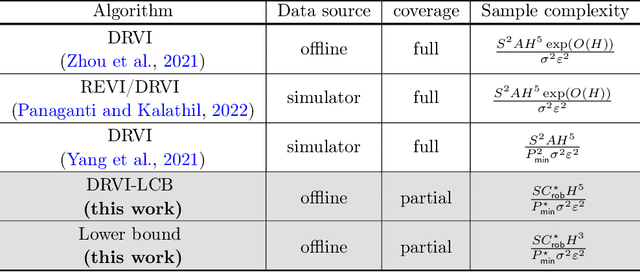
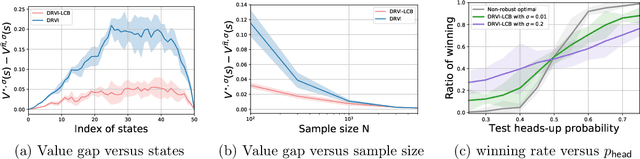
This paper concerns the central issues of model robustness and sample efficiency in offline reinforcement learning (RL), which aims to learn to perform decision making from history data without active exploration. Due to uncertainties and variabilities of the environment, it is critical to learn a robust policy -- with as few samples as possible -- that performs well even when the deployed environment deviates from the nominal one used to collect the history dataset. We consider a distributionally robust formulation of offline RL, focusing on a tabular non-stationary finite-horizon robust Markov decision process with an uncertainty set specified by the Kullback-Leibler divergence. To combat with sample scarcity, a model-based algorithm that combines distributionally robust value iteration with the principle of pessimism in the face of uncertainty is proposed, by penalizing the robust value estimates with a carefully designed data-driven penalty term. Under a mild and tailored assumption of the history dataset that measures distribution shift without requiring full coverage of the state-action space, we establish the finite-sample complexity of the proposed algorithm, and further show it is almost unimprovable in light of a nearly-matching information-theoretic lower bound up to a polynomial factor of the horizon length. To the best our knowledge, this provides the first provably near-optimal robust offline RL algorithm that learns under model uncertainty and partial coverage.