 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
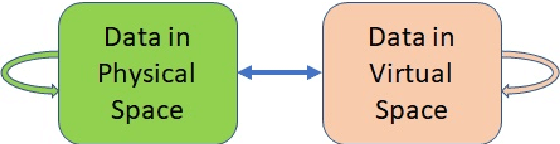
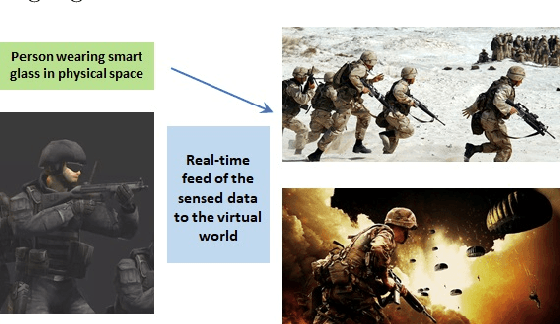
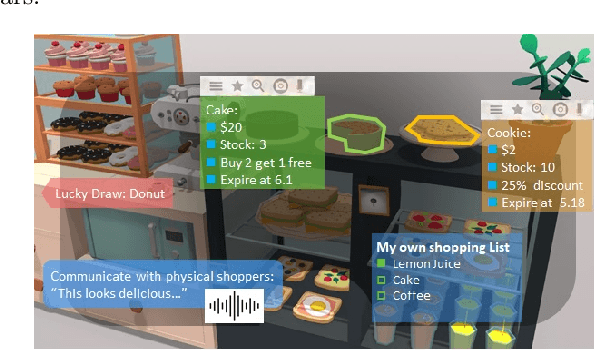

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
Visual processing in context of reinforcement learning
Aug 26, 2022
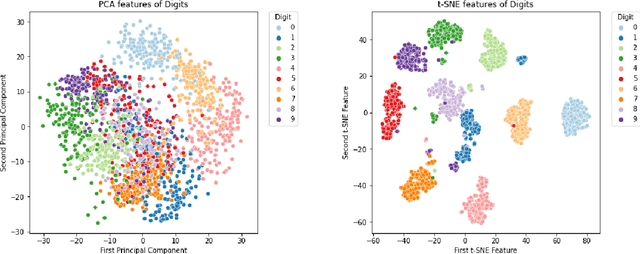
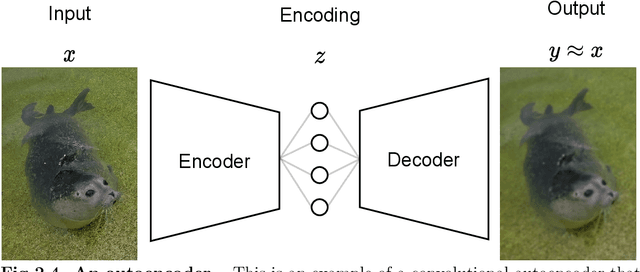
Although deep reinforcement learning (RL) has recently enjoyed many successes, its methods are still data inefficient, which makes solving numerous problems prohibitively expensive in terms of data. We aim to remedy this by taking advantage of the rich supervisory signal in unlabeled data for learning state representations. This thesis introduces three different representation learning algorithms that have access to different subsets of the data sources that traditional RL algorithms use: (i) GRICA is inspired by independent component analysis (ICA) and trains a deep neural network to output statistically independent features of the input. GrICA does so by minimizing the mutual information between each feature and the other features. Additionally, GrICA only requires an unsorted collection of environment states. (ii) Latent Representation Prediction (LARP) requires more context: in addition to requiring a state as an input, it also needs the previous state and an action that connects them. This method learns state representations by predicting the representation of the environment's next state given a current state and action. The predictor is used with a graph search algorithm. (iii) RewPred learns a state representation by training a deep neural network to learn a smoothed version of the reward function. The representation is used for preprocessing inputs to deep RL, while the reward predictor is used for reward shaping. This method needs only state-reward pairs from the environment for learning the representation. We discover that every method has their strengths and weaknesses, and conclude from our experiments that including unsupervised representation learning in RL problem-solving pipelines can speed up learning.
V-Coder: Adaptive AutoEncoder for Semantic Disclosure in Knowledge Graphs
Jul 22, 2022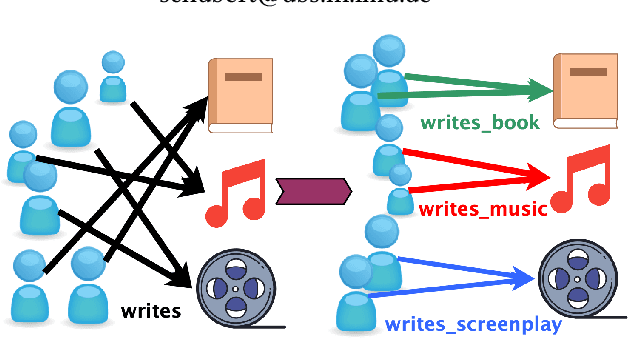

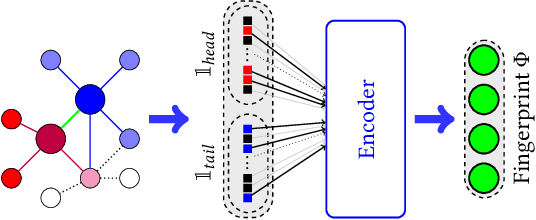
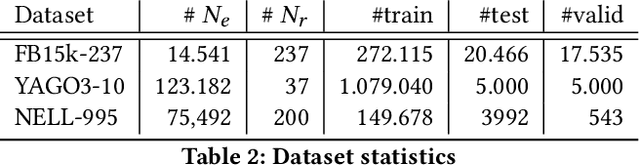
Semantic Web or Knowledge Graphs (KG) emerged to one of the most important information source for intelligent systems requiring access to structured knowledge. One of the major challenges is the extraction and processing of unambiguous information from textual data. Following the human perception, overlapping semantic linkages between two named entities become clear due to our common-sense about the context a relationship lives in which is not the case when we look at it from an automatically driven process of a machine. In this work, we are interested in the problem of Relational Resolution within the scope of KGs, i.e, we are investigating the inherent semantic of relationships between entities within a network. We propose a new adaptive AutoEncoder, called V-Coder, to identify relations inherently connecting entities from different domains. Those relations can be considered as being ambiguous and are candidates for disentanglement. Likewise to the Adaptive Learning Theory (ART), our model learns new patterns from the KG by increasing units in a competitive layer without discarding the previous observed patterns whilst learning the quality of each relation separately. The evaluation on real-world datasets of Freebase, Yago and NELL shows that the V-Coder is not only able to recover links from corrupted input data, but also shows that the semantic disclosure of relations in a KG show the tendency to improve link prediction. A semantic evaluation wraps the evaluation up.
Relational Action Bases: Formalization, Effective Safety Verification, and Invariants (Extended Version)
Aug 12, 2022
Modeling and verification of dynamic systems operating over a relational representation of states are increasingly investigated problems in AI, Business Process Management, and Database Theory. To make these systems amenable to verification, the amount of information stored in each relational state needs to be bounded, or restrictions are imposed on the preconditions and effects of actions. We introduce the general framework of relational action bases (RABs), which generalizes existing models by lifting both these restrictions: unbounded relational states can be evolved through actions that can quantify both existentially and universally over the data, and that can exploit numerical datatypes with arithmetic predicates. We then study parameterized safety of RABs via (approximated) SMT-based backward search, singling out essential meta-properties of the resulting procedure, and showing how it can be realized by an off-the-shelf combination of existing verification modules of the state-of-the-art MCMT model checker. We demonstrate the effectiveness of this approach on a benchmark of data-aware business processes. Finally, we show how universal invariants can be exploited to make this procedure fully correct.
A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning
Jun 09, 2022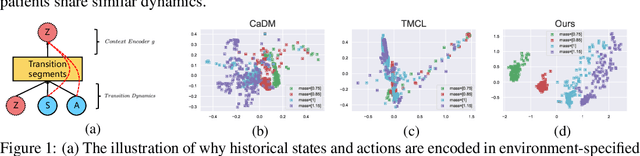
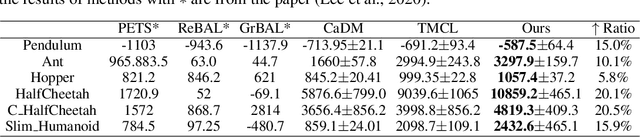
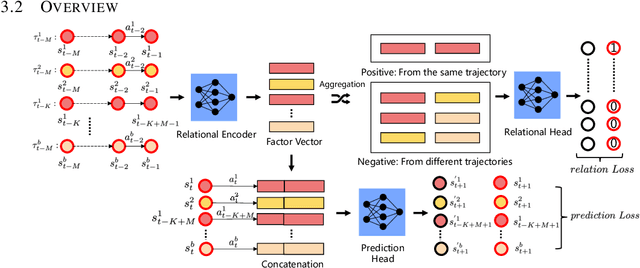
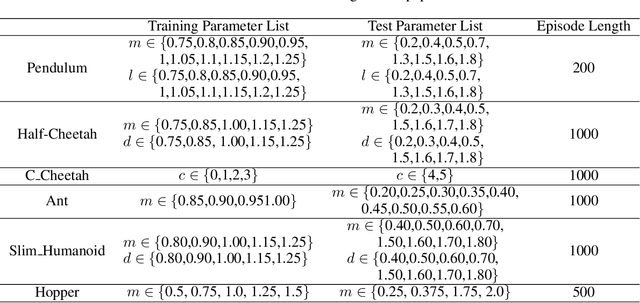
The generalization of model-based reinforcement learning (MBRL) methods to environments with unseen transition dynamics is an important yet challenging problem. Existing methods try to extract environment-specified information $Z$ from past transition segments to make the dynamics prediction model generalizable to different dynamics. However, because environments are not labelled, the extracted information inevitably contains redundant information unrelated to the dynamics in transition segments and thus fails to maintain a crucial property of $Z$: $Z$ should be similar in the same environment and dissimilar in different ones. As a result, the learned dynamics prediction function will deviate from the true one, which undermines the generalization ability. To tackle this problem, we introduce an interventional prediction module to estimate the probability of two estimated $\hat{z}_i, \hat{z}_j$ belonging to the same environment. Furthermore, by utilizing the $Z$'s invariance within a single environment, a relational head is proposed to enforce the similarity between $\hat{{Z}}$ from the same environment. As a result, the redundant information will be reduced in $\hat{Z}$. We empirically show that $\hat{{Z}}$ estimated by our method enjoy less redundant information than previous methods, and such $\hat{{Z}}$ can significantly reduce dynamics prediction errors and improve the performance of model-based RL methods on zero-shot new environments with unseen dynamics. The codes of this method are available at \url{https://github.com/CR-Gjx/RIA}.
Influence Maximization (IM) in Complex Networks with Limited Visibility Using Statistical Methods
Aug 28, 2022

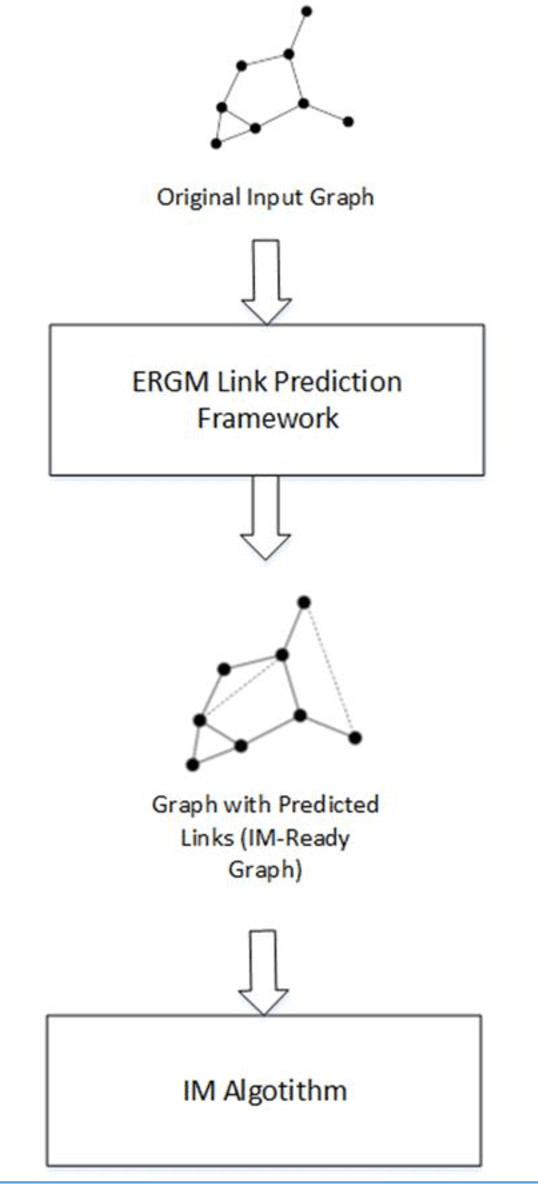
A social network (SN) is a social structure consisting of a group representing the interaction between them. SNs have recently been widely used and, subsequently, have become suitable and popular platforms for product promotion and information diffusion. People in an SN directly influence each other's interests and behavior. One of the most important problems in SNs is to find people who can have the maximum influence on other nodes in the network in a cascade manner if they are chosen as the seed nodes of a network diffusion scenario. Influential diffusers are people who, if they are chosen as the seed set in a publishing issue in the network, that network will have the most people who have learned about that diffused entity. This is a well-known problem in literature known as influence maximization (IM) problem. Although it has been proven that this is an NP-complete problem and does not have a solution in polynomial time, it has been argued that it has the properties of sub modular functions and, therefore, can be solved using a greedy algorithm. Most of the methods proposed to improve this complexity are based on the assumption that the entire graph is visible. However, this assumption does not hold for many real-world graphs. This study is conducted to extend current maximization methods with link prediction techniques to pseudo-visibility graphs. To this end, a graph generation method called the exponential random graph model (ERGM) is used for link prediction. The proposed method is tested using the data from the Snap dataset of Stanford University. According to the experimental tests, the proposed method is efficient on real-world graphs.
Shap-CAM: Visual Explanations for Convolutional Neural Networks based on Shapley Value
Aug 09, 2022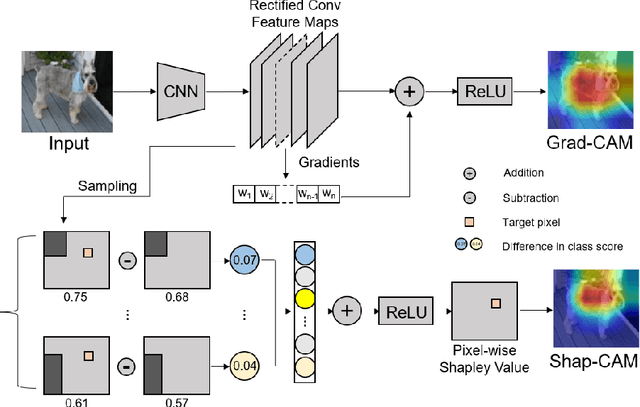

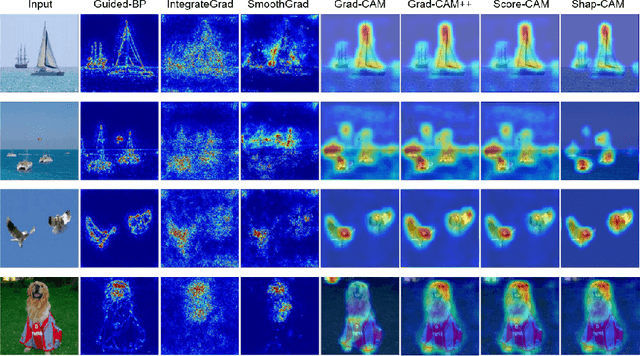

Explaining deep convolutional neural networks has been recently drawing increasing attention since it helps to understand the networks' internal operations and why they make certain decisions. Saliency maps, which emphasize salient regions largely connected to the network's decision-making, are one of the most common ways for visualizing and analyzing deep networks in the computer vision community. However, saliency maps generated by existing methods cannot represent authentic information in images due to the unproven proposals about the weights of activation maps which lack solid theoretical foundation and fail to consider the relations between each pixel. In this paper, we develop a novel post-hoc visual explanation method called Shap-CAM based on class activation mapping. Unlike previous gradient-based approaches, Shap-CAM gets rid of the dependence on gradients by obtaining the importance of each pixel through Shapley value. We demonstrate that Shap-CAM achieves better visual performance and fairness for interpreting the decision making process. Our approach outperforms previous methods on both recognition and localization tasks.
Arbitrary Shape Text Detection via Segmentation with Probability Maps
Aug 26, 2022
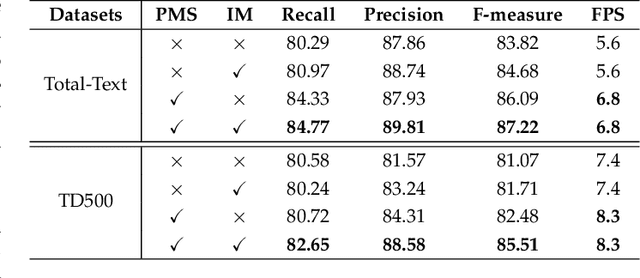

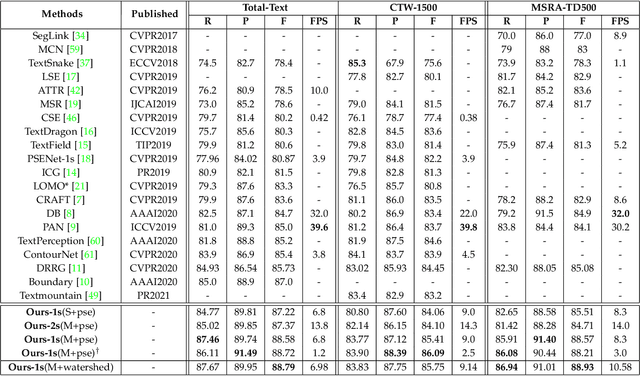
Arbitrary shape text detection is a challenging task due to the significantly varied sizes and aspect ratios, arbitrary orientations or shapes, inaccurate annotations, etc. Due to the scalability of pixel-level prediction, segmentation-based methods can adapt to various shape texts and hence attracted considerable attention recently. However, accurate pixel-level annotations of texts are formidable, and the existing datasets for scene text detection only provide coarse-grained boundary annotations. Consequently, numerous misclassified text pixels or background pixels inside annotations always exist, degrading the performance of segmentation-based text detection methods. Generally speaking, whether a pixel belongs to text or not is highly related to the distance with the adjacent annotation boundary. With this observation, in this paper, we propose an innovative and robust segmentation-based detection method via probability maps for accurately detecting text instances. To be concrete, we adopt a Sigmoid Alpha Function (SAF) to transfer the distances between boundaries and their inside pixels to a probability map. However, one probability map can not cover complex probability distributions well because of the uncertainty of coarse-grained text boundary annotations. Therefore, we adopt a group of probability maps computed by a series of Sigmoid Alpha Functions to describe the possible probability distributions. In addition, we propose an iterative model to learn to predict and assimilate probability maps for providing enough information to reconstruct text instances. Finally, simple region growth algorithms are adopted to aggregate probability maps to complete text instances. Experimental results demonstrate that our method achieves state-of-the-art performance in terms of detection accuracy on several benchmarks.
A Multimodal Transformer: Fusing Clinical Notes with Structured EHR Data for Interpretable In-Hospital Mortality Prediction
Aug 09, 2022
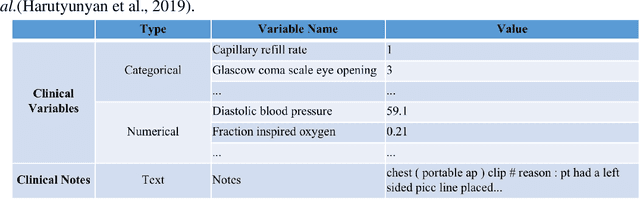
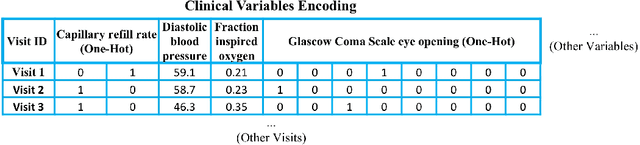
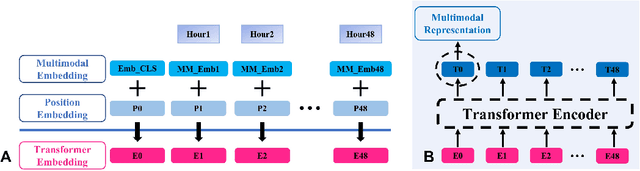
Deep-learning-based clinical decision support using structured electronic health records (EHR) has been an active research area for predicting risks of mortality and diseases. Meanwhile, large amounts of narrative clinical notes provide complementary information, but are often not integrated into predictive models. In this paper, we provide a novel multimodal transformer to fuse clinical notes and structured EHR data for better prediction of in-hospital mortality. To improve interpretability, we propose an integrated gradients (IG) method to select important words in clinical notes and discover the critical structured EHR features with Shapley values. These important words and clinical features are visualized to assist with interpretation of the prediction outcomes. We also investigate the significance of domain adaptive pretraining and task adaptive fine-tuning on the Clinical BERT, which is used to learn the representations of clinical notes. Experiments demonstrated that our model outperforms other methods (AUCPR: 0.538, AUCROC: 0.877, F1:0.490).
VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction
Aug 09, 2022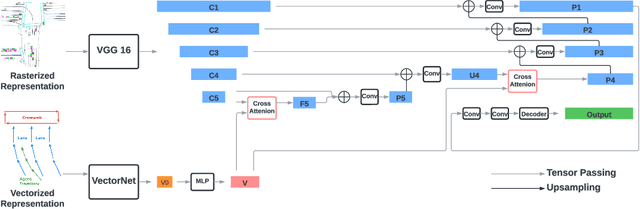
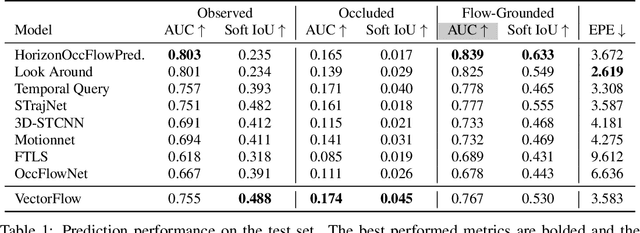

Predicting future behaviors of road agents is a key task in autonomous driving. While existing models have demonstrated great success in predicting marginal agent future behaviors, it remains a challenge to efficiently predict consistent joint behaviors of multiple agents. Recently, the occupancy flow fields representation was proposed to represent joint future states of road agents through a combination of occupancy grid and flow, which supports efficient and consistent joint predictions. In this work, we propose a novel occupancy flow fields predictor to produce accurate occupancy and flow predictions, by combining the power of an image encoder that learns features from a rasterized traffic image and a vector encoder that captures information of continuous agent trajectories and map states. The two encoded features are fused by multiple attention modules before generating final predictions. Our simple but effective model ranks 3rd place on the Waymo Open Dataset Occupancy and Flow Prediction Challenge, and achieves the best performance in the occluded occupancy and flow prediction task.