 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accessing and Interpreting OPC UA Event Traces based on Semantic Process Descriptions
Jul 25, 2022
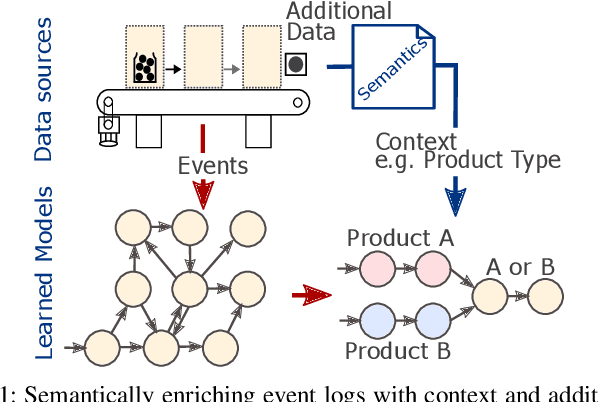
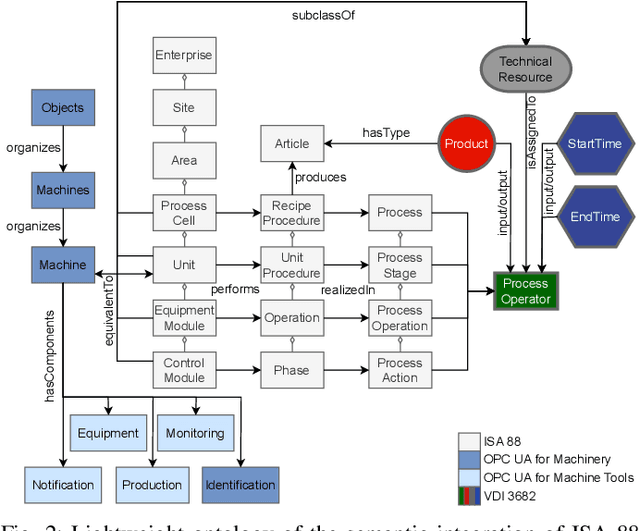
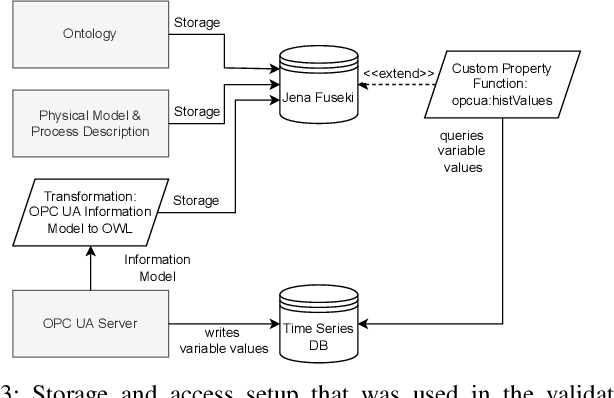
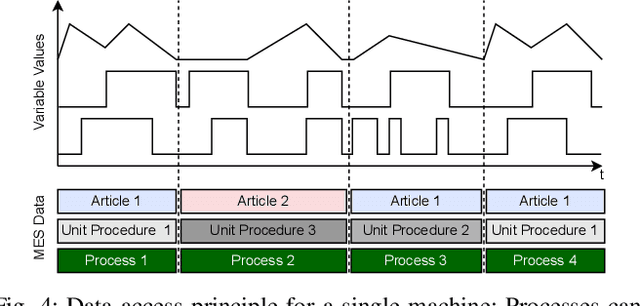
The analysis of event data from production systems is the basis for many applications associated with Industry 4.0. However, heterogeneous and disjoint data is common in this domain. As a consequence, contextual information of an event might be incomplete or improperly interpreted which results in suboptimal analysis results. This paper proposes an approach to access a production systems' event data based on the event data's context (such as the product type, process type or process parameters). The approach extracts filtered event logs from a database system by combining: 1) a semantic model of a production system's hierarchical structure, 2) a formalized process description and 3) an OPC UA information model. As a proof of concept we demonstrate our approach using a sample server based on OPC UA for Machinery Companion Specifications.
Masked Sinogram Model with Transformer for ill-Posed Computed Tomography Reconstruction: a Preliminary Study
Sep 03, 2022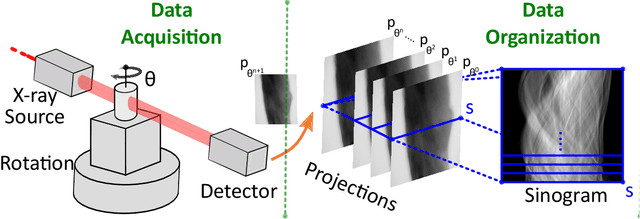

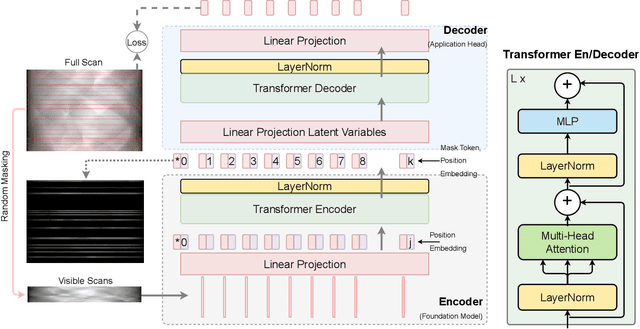

Computed Tomography (CT) is an imaging technique where information about an object are collected at different angles (called projections or scans). Then the cross-sectional image showing the internal structure of the slice is produced by solving an inverse problem. Limited by certain factors such as radiation dosage, projection angles, the produced images can be noisy or contain artifacts. Inspired by the success of transformer for natural language processing, the core idea of this preliminary study is to consider a projection of tomography as a word token, and the whole scan of the cross-section (A.K.A. sinogram) as a sentence in the context of natural language processing. Then we explore the idea of foundation model by training a masked sinogram model (MSM) and fine-tune MSM for various downstream applications including CT reconstruction under data collections restriction (e.g., photon-budget) and a data-driven solution to approximate solutions of the inverse problem for CT reconstruction. Models and data used in this study are available at https://github.com/lzhengchun/TomoTx.
FaceTopoNet: Facial Expression Recognition using Face Topology Learning
Sep 13, 2022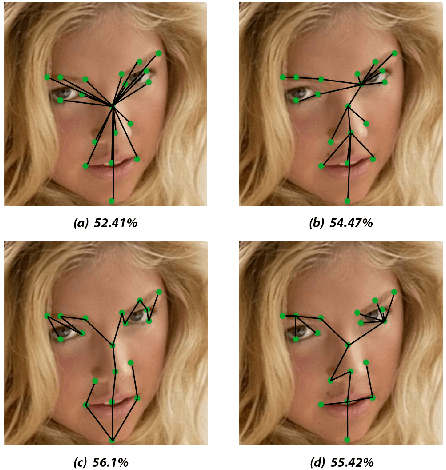

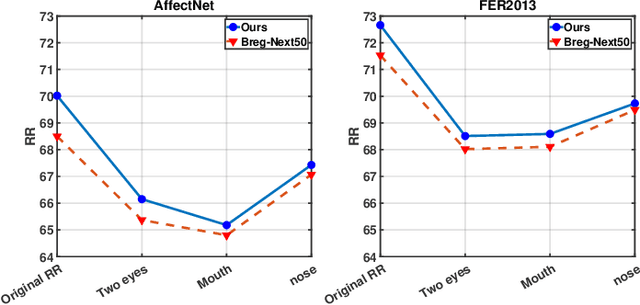
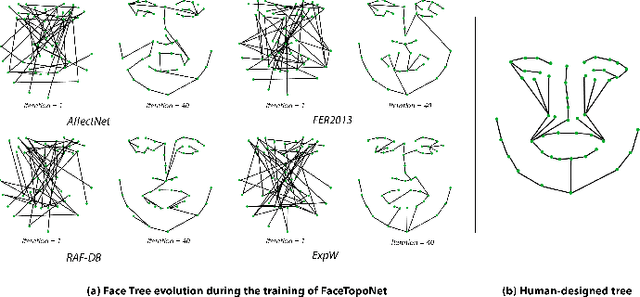
Prior work has shown that the order in which different components of the face are learned using a sequential learner can play an important role in the performance of facial expression recognition systems. We propose FaceTopoNet, an end-to-end deep model for facial expression recognition, which is capable of learning an effective tree topology of the face. Our model then traverses the learned tree to generate a sequence, which is then used to form an embedding to feed a sequential learner. The devised model adopts one stream for learning structure and one stream for learning texture. The structure stream focuses on the positions of the facial landmarks, while the main focus of the texture stream is on the patches around the landmarks to learn textural information. We then fuse the outputs of the two streams by utilizing an effective attention-based fusion strategy. We perform extensive experiments on four large-scale in-the-wild facial expression datasets - namely AffectNet, FER2013, ExpW, and RAF-DB - and one lab-controlled dataset (CK+) to evaluate our approach. FaceTopoNet achieves state-of-the-art performance on three of the five datasets and obtains competitive results on the other two datasets. We also perform rigorous ablation and sensitivity experiments to evaluate the impact of different components and parameters in our model. Lastly, we perform robustness experiments and demonstrate that FaceTopoNet is more robust against occlusions in comparison to other leading methods in the area.
SSDPT: Self-Supervised Dual-Path Transformer for Anomalous Sound Detection in Machine Condition Monitoring
Aug 06, 2022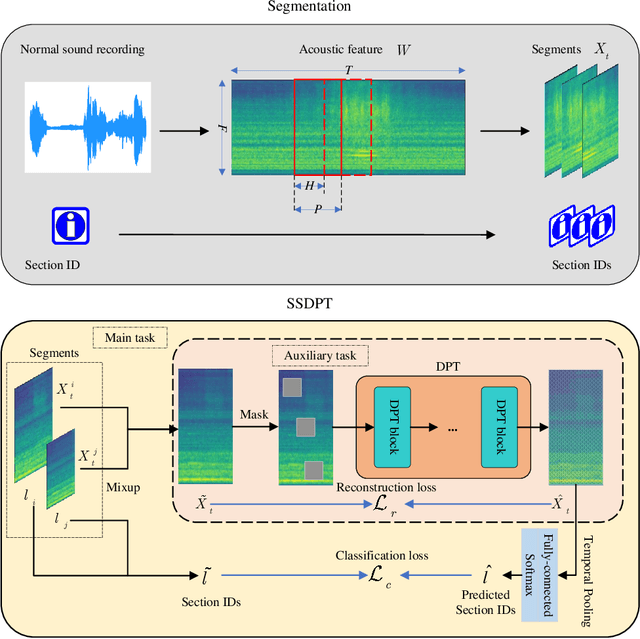
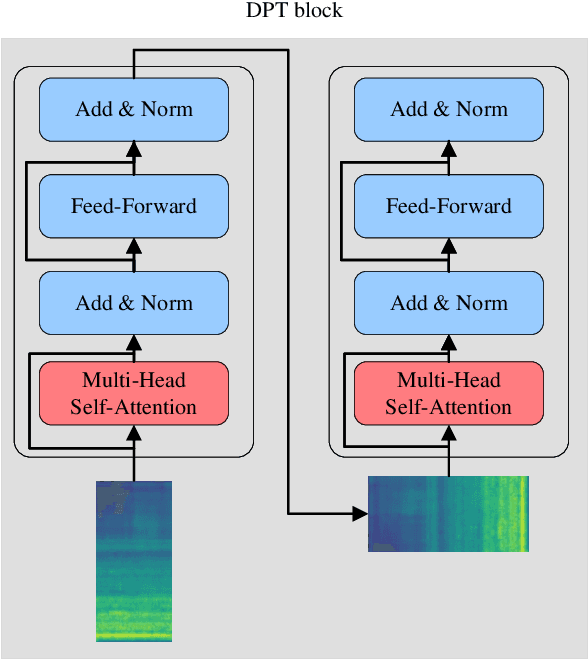

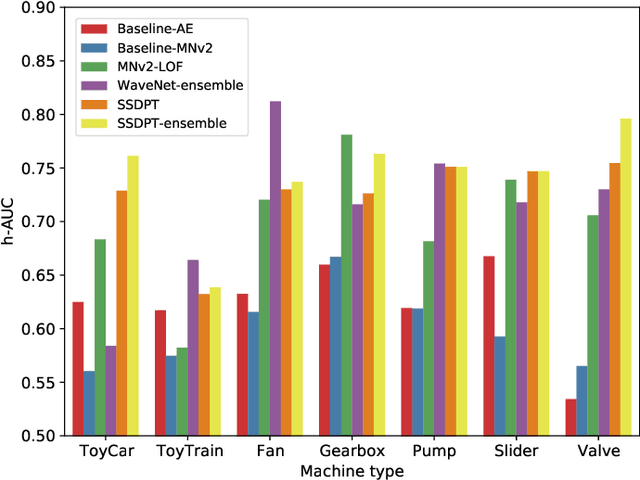
Anomalous sound detection for machine condition monitoring has great potential in the development of Industry 4.0. However, these anomalous sounds of machines are usually unavailable in normal conditions. Therefore, the models employed have to learn acoustic representations with normal sounds for training, and detect anomalous sounds while testing. In this article, we propose a self-supervised dual-path Transformer (SSDPT) network to detect anomalous sounds in machine monitoring. The SSDPT network splits the acoustic features into segments and employs several DPT blocks for time and frequency modeling. DPT blocks use attention modules to alternately model the interactive information about the frequency and temporal components of the segmented acoustic features. To address the problem of lack of anomalous sound, we adopt a self-supervised learning approach to train the network with normal sound. Specifically, this approach randomly masks and reconstructs the acoustic features, and jointly classifies machine identity information to improve the performance of anomalous sound detection. We evaluated our method on the DCASE2021 task2 dataset. The experimental results show that the SSDPT network achieves a significant increase in the harmonic mean AUC score, in comparison to present state-of-the-art methods of anomalous sound detection.
GRASP: Guiding model with RelAtional Semantics using Prompt
Aug 29, 2022
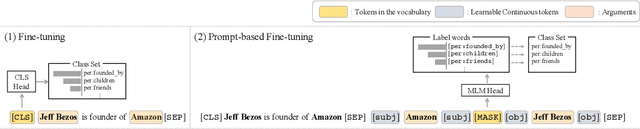
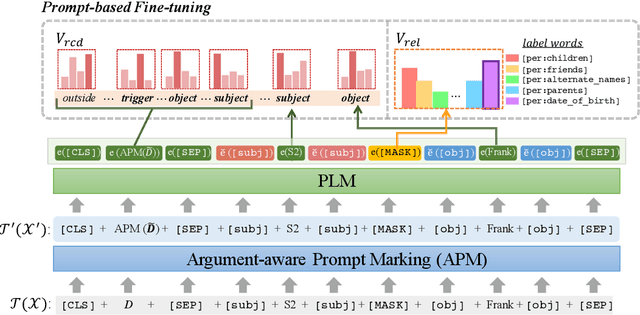
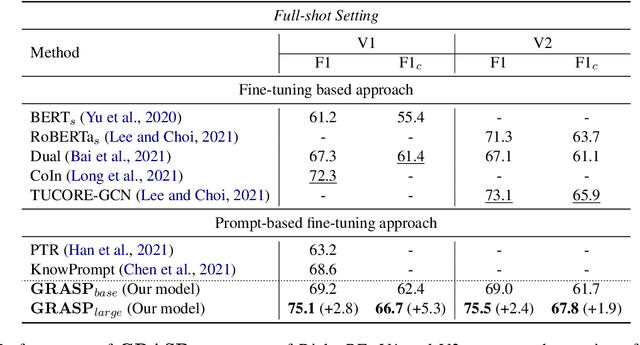
The dialogue-based relation extraction (DialogRE) task aims to predict the relations between argument pairs that appear in dialogue. Most previous studies utilize fine-tuning pre-trained language models (PLMs) only with extensive features to supplement the low information density of the dialogue by multiple speakers. To effectively exploit inherent knowledge of PLMs without extra layers and consider scattered semantic cues on the relation between the arguments, we propose a Guiding model with RelAtional Semantics using Prompt (GRASP). We adopt a prompt-based fine-tuning approach and capture relational semantic clues of a given dialogue with 1) an argument-aware prompt marker strategy and 2) the relational clue detection task. In the experiments, GRASP achieves state-of-the-art performance in terms of both F1 and F1c scores on a DialogRE dataset even though our method only leverages PLMs without adding any extra layers.
Differentially Private Vertical Federated Clustering
Aug 02, 2022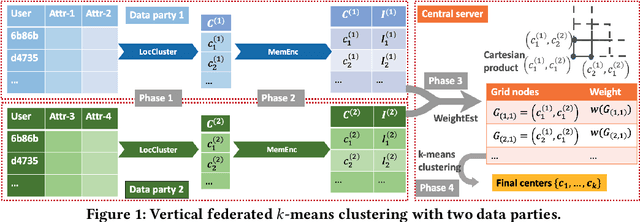
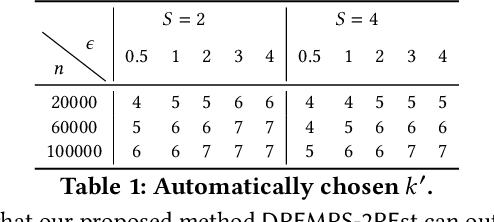
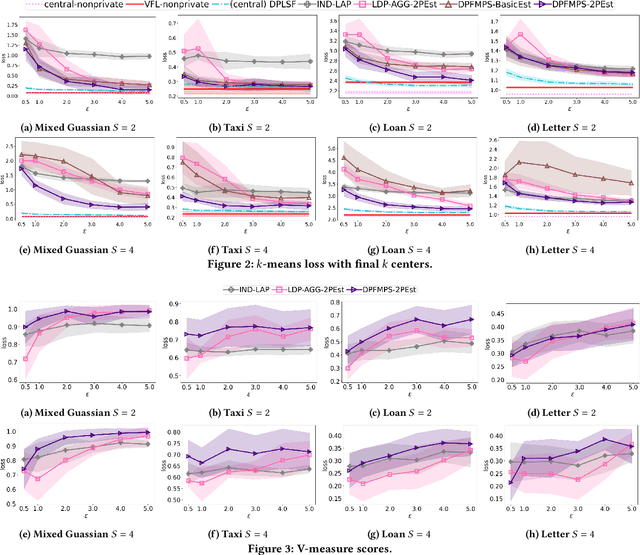
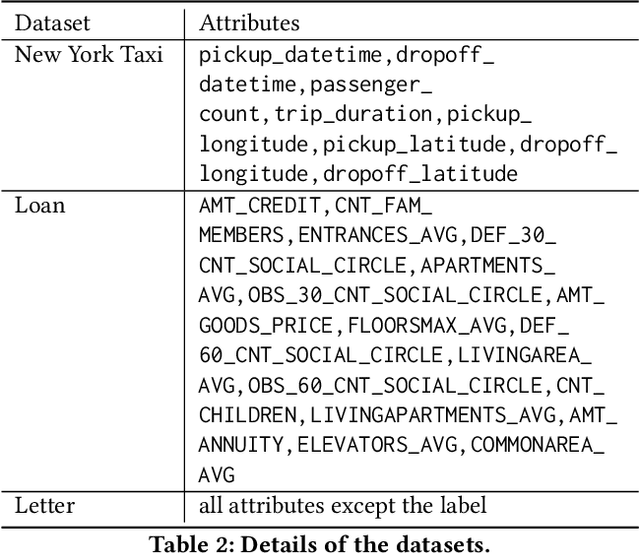
In many applications, multiple parties have private data regarding the same set of users but on disjoint sets of attributes, and a server wants to leverage the data to train a model. To enable model learning while protecting the privacy of the data subjects, we need vertical federated learning (VFL) techniques, where the data parties share only information for training the model, instead of the private data. However, it is challenging to ensure that the shared information maintains privacy while learning accurate models. To the best of our knowledge, the algorithm proposed in this paper is the first practical solution for differentially private vertical federated k-means clustering, where the server can obtain a set of global centers with a provable differential privacy guarantee. Our algorithm assumes an untrusted central server that aggregates differentially private local centers and membership encodings from local data parties. It builds a weighted grid as the synopsis of the global dataset based on the received information. Final centers are generated by running any k-means algorithm on the weighted grid. Our approach for grid weight estimation uses a novel, light-weight, and differentially private set intersection cardinality estimation algorithm based on the Flajolet-Martin sketch. To improve the estimation accuracy in the setting with more than two data parties, we further propose a refined version of the weights estimation algorithm and a parameter tuning strategy to reduce the final k-means utility to be close to that in the central private setting. We provide theoretical utility analysis and experimental evaluation results for the cluster centers computed by our algorithm and show that our approach performs better both theoretically and empirically than the two baselines based on existing techniques.
Human-Robot Interface to Operate Robotic Systems via Muscle Synergy-Based Kinodynamic Information Transfer
May 11, 2022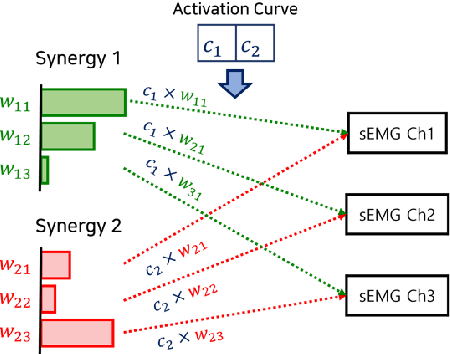
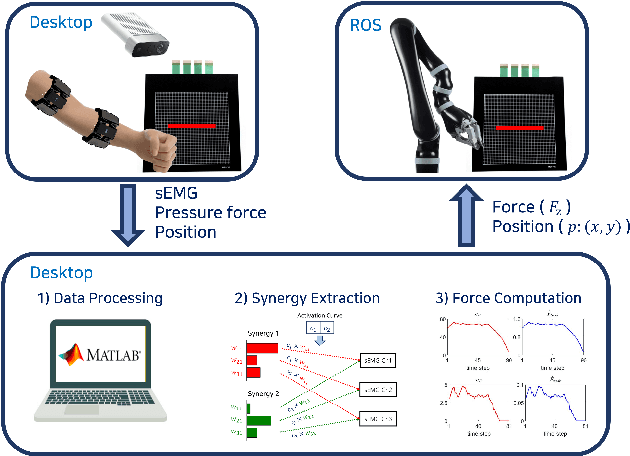
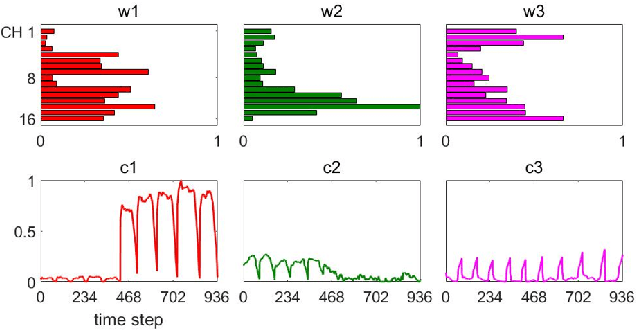
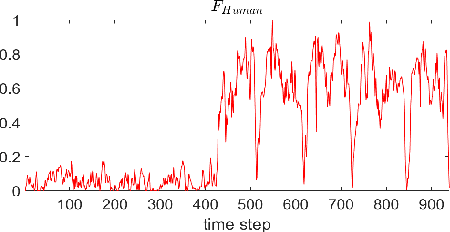
When a human performs a given specific task, it has been known that the central nervous system controls modularized muscle group, which is called muscle synergy. For human-robot interface design problem, therefore, the muscle synergy can be utilized to reduce the dimensionality of control signal as well as the complexity of classifying human posture and motion. In this paper, we propose an approach to design a human-robot interface which enables a human operator to transfer a kinodynamic control command to robotic systems. A key feature of the proposed approach is that the muscle synergy and corresponding activation curve are employed to calculate a force generated by a tool at the robot end effector. A test bed for experiments consisted of two armband type surface electromyography sensors, an RGB-d camera, and a Kinova Gen2 robotic manipulator to verify the proposed approach. The result showed that both force and position commands could be successfully transferred to the robotic manipulator via our muscle synergy-based kinodynamic interface.
A multiplicity-preserving crossover operator on graphs. Extended version
Aug 23, 2022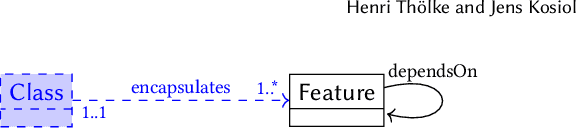
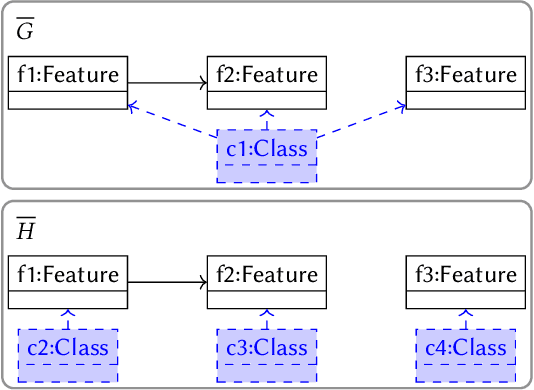
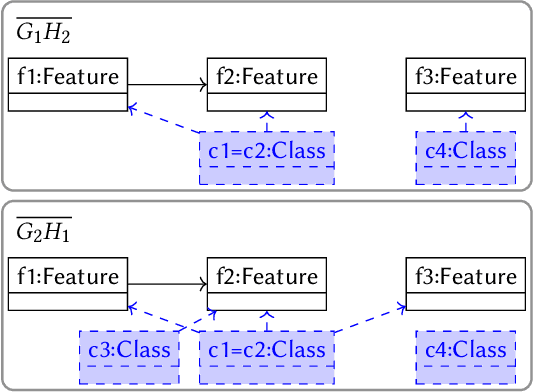
Evolutionary algorithms usually explore a search space of solutions by means of crossover and mutation. While a mutation consists of a small, local modification of a solution, crossover mixes the genetic information of two solutions to compute a new one. For model-driven optimization (MDO), where models directly serve as possible solutions (instead of first transforming them into another representation), only recently a generic crossover operator has been developed. Using graphs as a formal foundation for models, we further refine this operator in such a way that additional well-formedness constraints are preserved: We prove that, given two models that satisfy a given set of multiplicity constraints as input, our refined crossover operator computes two new models as output that also satisfy the set of constraints.
Invariant Information Bottleneck for Domain Generalization
Jun 11, 2021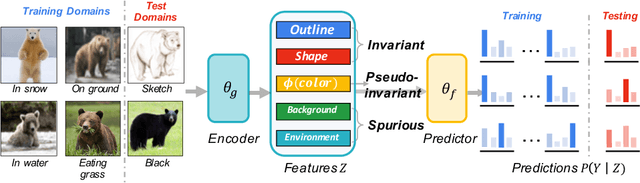
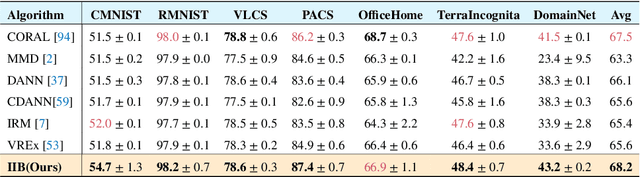
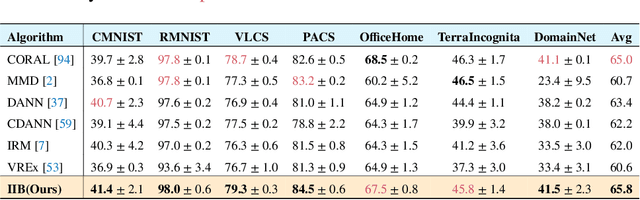
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.
Improving Fine-tuning of Self-supervised Models with Contrastive Initialization
Jul 30, 2022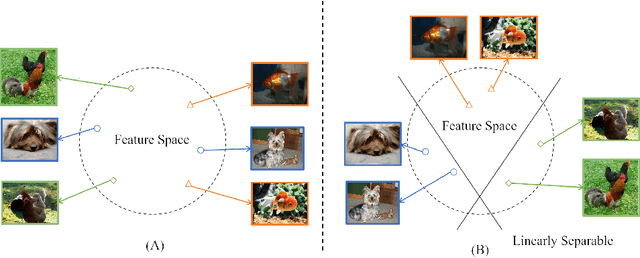
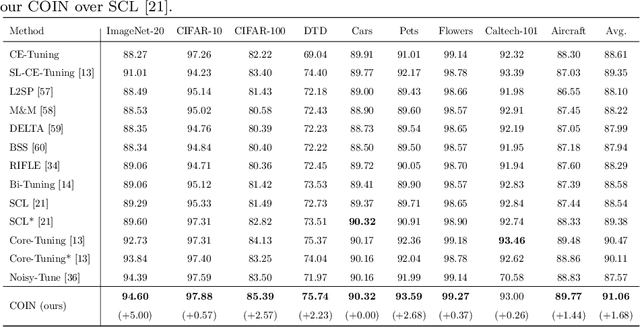
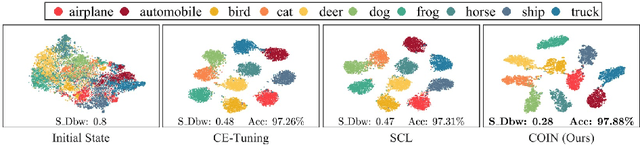
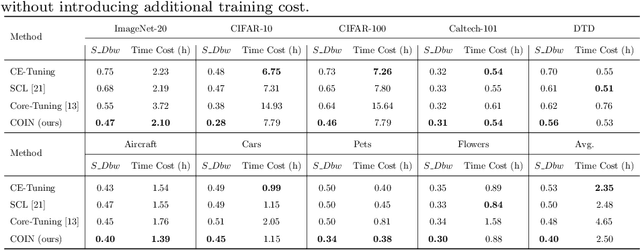
Self-supervised learning (SSL) has achieved remarkable performance in pretraining the models that can be further used in downstream tasks via fine-tuning. However, these self-supervised models may not capture meaningful semantic information since the images belonging to the same class are always regarded as negative pairs in the contrastive loss. Consequently, the images of the same class are often located far away from each other in learned feature space, which would inevitably hamper the fine-tuning process. To address this issue, we seek to provide a better initialization for the self-supervised models by enhancing the semantic information. To this end, we propose a Contrastive Initialization (COIN) method that breaks the standard fine-tuning pipeline by introducing an extra initialization stage before fine-tuning. Extensive experiments show that, with the enriched semantics, our COIN significantly outperforms existing methods without introducing extra training cost and sets new state-of-the-arts on multiple downstream tasks.