 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Route and Schedule LLMs from User Retrials via Contextual Queueing Bandits
Feb 02, 2026Explosive demands for LLMs often cause user queries to accumulate in server queues, requiring efficient routing (query-LLM matching) and scheduling (query prioritization) mechanisms. Several online algorithms are being deployed, but they overlook the following two key challenges inherent to conversational LLM services: (1) unsatisfied users may retry queries, increasing the server backlog, and (2) requests for ``explicit" feedback, such as ratings, degrade user experiences. In this paper, we develop a joint routing and scheduling algorithm that leverages ``implicit" feedback inferred from user retrial behaviors. The key idea is to propose and study the framework of contextual queueing bandits with multinomial logit feedback (CQB-MNL). CQB-MNL models query retrials, as well as context-based learning for user preferences over LLMs. Our algorithm, anytime CQB (ACQB), achieves efficient learning while maintaining queue stability by combining Thompson sampling with forced exploration at a decaying rate. We show that ACQB simultaneously achieves a cumulative regret of $\widetilde{\mathcal{O}}(\sqrt{t})$ for routing and a queue length regret of $\widetilde{\mathcal{O}}(t^{-1/4})$ for any large $t$. For experiments, we refine query embeddings via contrastive learning while adopting a disjoint parameter model to learn LLM-specific parameters. Experiments on SPROUT, EmbedLLM, and RouterBench datasets confirm that both algorithms consistently outperform baselines.
From Ambiguity to Accuracy: The Transformative Effect of Coreference Resolution on Retrieval-Augmented Generation systems
Jul 10, 2025Retrieval-Augmented Generation (RAG) has emerged as a crucial framework in natural language processing (NLP), improving factual consistency and reducing hallucinations by integrating external document retrieval with large language models (LLMs). However, the effectiveness of RAG is often hindered by coreferential complexity in retrieved documents, introducing ambiguity that disrupts in-context learning. In this study, we systematically investigate how entity coreference affects both document retrieval and generative performance in RAG-based systems, focusing on retrieval relevance, contextual understanding, and overall response quality. We demonstrate that coreference resolution enhances retrieval effectiveness and improves question-answering (QA) performance. Through comparative analysis of different pooling strategies in retrieval tasks, we find that mean pooling demonstrates superior context capturing ability after applying coreference resolution. In QA tasks, we discover that smaller models benefit more from the disambiguation process, likely due to their limited inherent capacity for handling referential ambiguity. With these findings, this study aims to provide a deeper understanding of the challenges posed by coreferential complexity in RAG, providing guidance for improving retrieval and generation in knowledge-intensive AI applications.
Post-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024



Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
GRASP: Guiding model with RelAtional Semantics using Prompt
Aug 29, 2022
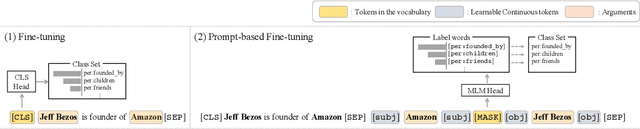
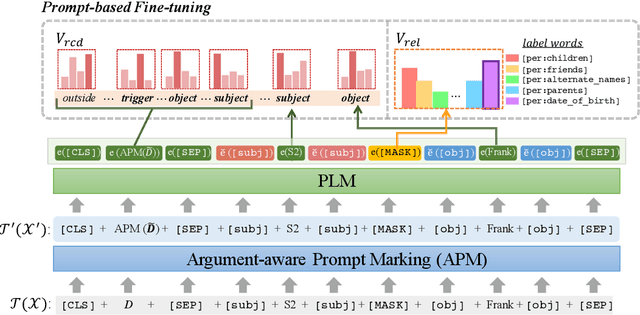
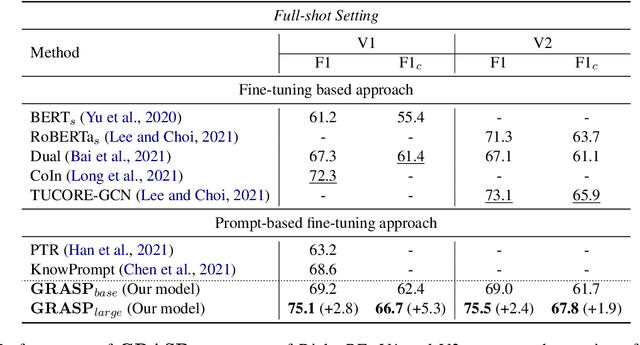
The dialogue-based relation extraction (DialogRE) task aims to predict the relations between argument pairs that appear in dialogue. Most previous studies utilize fine-tuning pre-trained language models (PLMs) only with extensive features to supplement the low information density of the dialogue by multiple speakers. To effectively exploit inherent knowledge of PLMs without extra layers and consider scattered semantic cues on the relation between the arguments, we propose a Guiding model with RelAtional Semantics using Prompt (GRASP). We adopt a prompt-based fine-tuning approach and capture relational semantic clues of a given dialogue with 1) an argument-aware prompt marker strategy and 2) the relational clue detection task. In the experiments, GRASP achieves state-of-the-art performance in terms of both F1 and F1c scores on a DialogRE dataset even though our method only leverages PLMs without adding any extra layers.