 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tac2Structure: Object Surface Reconstruction Only through Multi Times Touch
Sep 14, 2022



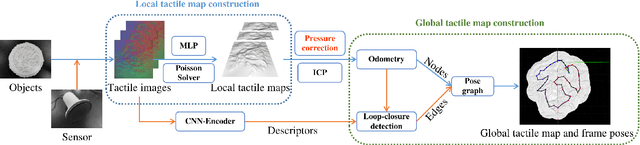
Inspired by the ability of humans to perceive the surface texture of unfamiliar objects without relying on vision, the sense of tactile can play a crucial role in the process of robots exploring the environment, especially in some scenes where vision is difficult to apply or occlusion is inevitable to exist. Existing tactile surface reconstruction methods rely on external sensors or have strong prior assumptions, which will limit their application scenarios and make the operation more complex. This paper presents a surface reconstruction algorithm that uses only a new vision-based tactile sensor where the surface structure of an unfamiliar object is reconstructed by multiple tactile measurements. Compared with existing algorithms, the proposed algorithm doesn't rely on external devices and focuses on improving the reconstruction accuracy of the large-scale object surface. Aiming at the difficulty that the reconstruction accuracy is easily affected by the pressure of sampling, we propose a correction algorithm to adapt it. Multi-frame tactile imprints generated from many times contact can accurately reconstruct global object surface by jointly using the point cloud registration algorithm, loop-closure detection algorithm based on deep learning, and pose graph optimization algorithm. Experiments verify the proposed algorithm can achieve millimeter-level accuracy in reconstructing the surface of interactive objects and provide accurate tactile information for the robot to perceive the surrounding environment.
Heterogeneous Line Graph Transformer for Math Word Problems
Aug 12, 2022
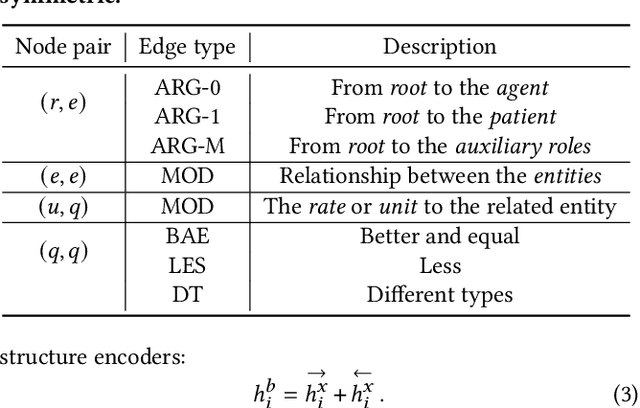
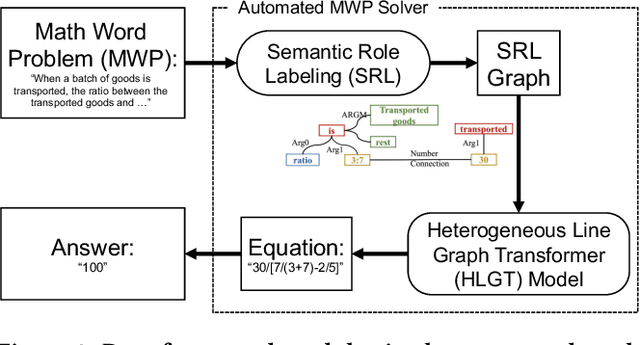
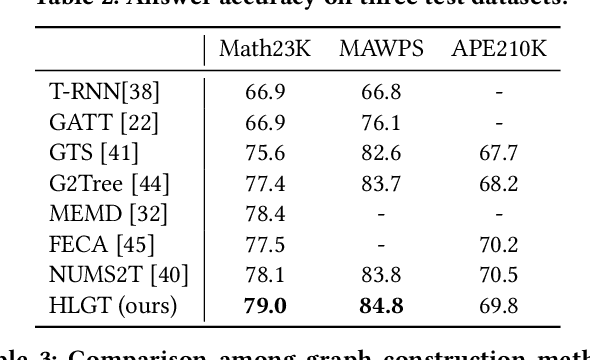
This paper describes the design and implementation of a new machine learning model for online learning systems. We aim at improving the intelligent level of the systems by enabling an automated math word problem solver which can support a wide range of functions such as homework correction, difficulty estimation, and priority recommendation. We originally planned to employ existing models but realized that they processed a math word problem as a sequence or a homogeneous graph of tokens. Relationships between the multiple types of tokens such as entity, unit, rate, and number were ignored. We decided to design and implement a novel model to use such relational data to bridge the information gap between human-readable language and machine-understandable logical form. We propose a heterogeneous line graph transformer (HLGT) model that constructs a heterogeneous line graph via semantic role labeling on math word problems and then perform node representation learning aware of edge types. We add numerical comparison as an auxiliary task to improve model training for real-world use. Experimental results show that the proposed model achieves a better performance than existing models and suggest that it is still far below human performance. Information utilization and knowledge discovery is continuously needed to improve the online learning systems.
A Practical Consideration on Convex Mutual Information
May 24, 2021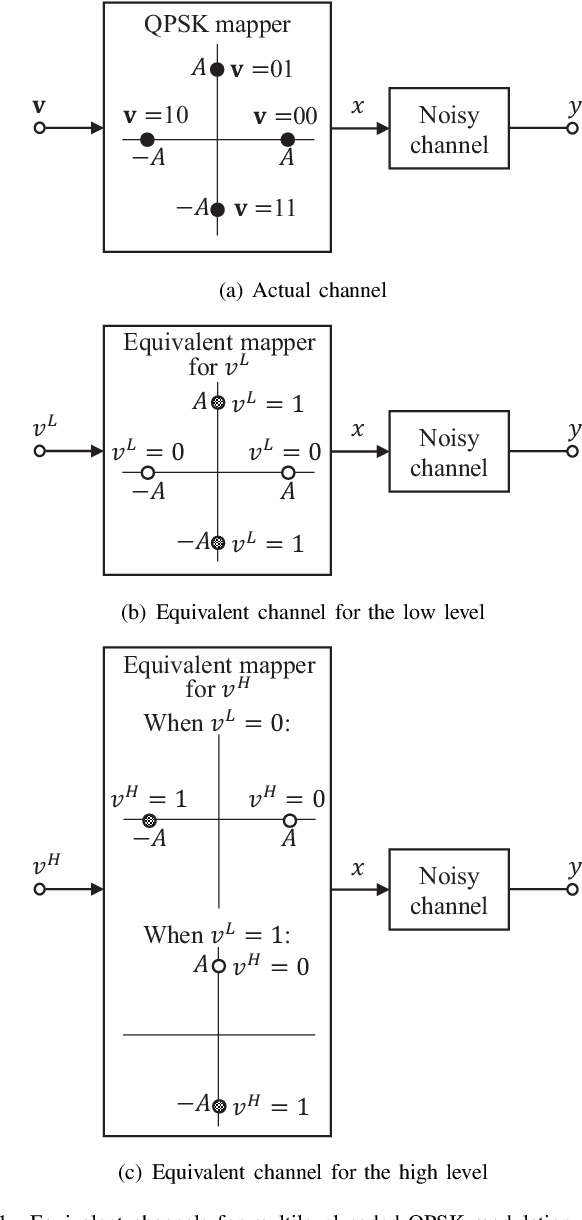
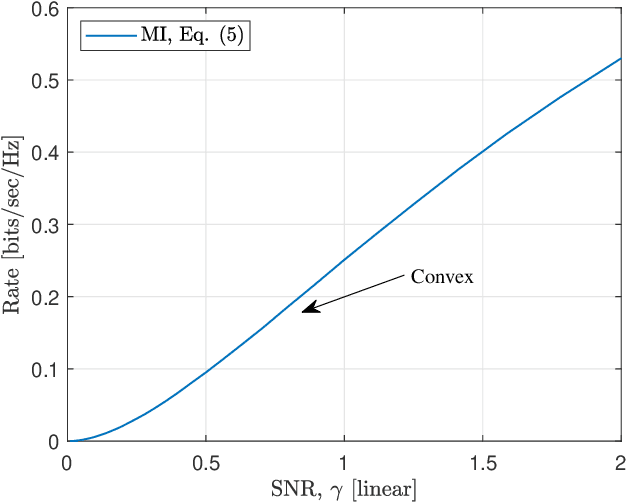
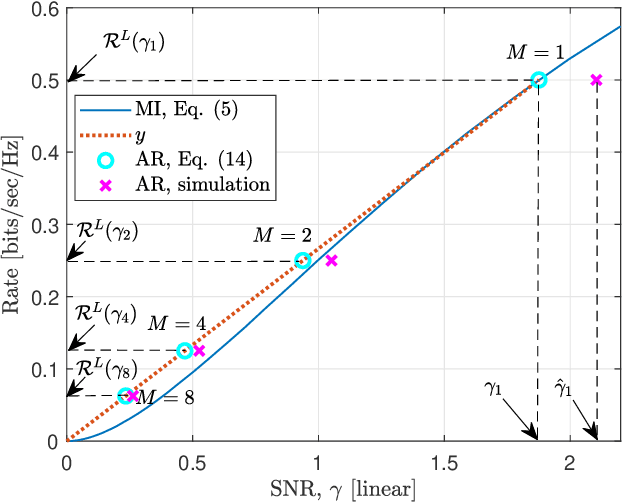
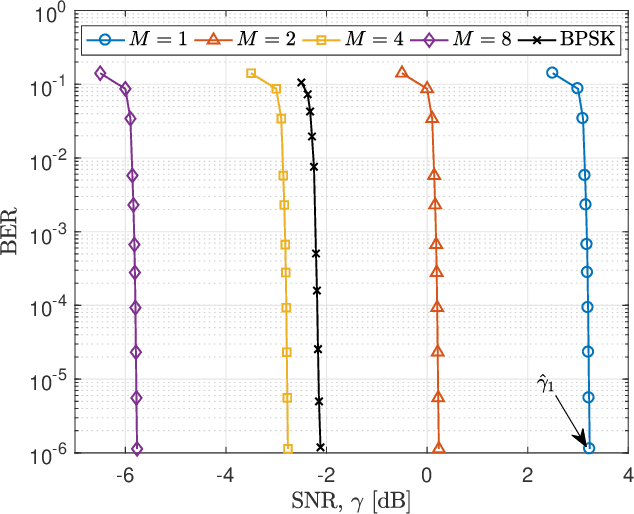
In this paper, we focus on the convex mutual information, which was found at the lowest level split in multilevel coding schemes with communications over the additive white Gaussian noise (AWGN) channel. Theoretical analysis shows that communication achievable rates (ARs) do not necessarily below mutual information in the convex region. In addition, simulation results are provided as an evidence.
Motif-based Graph Representation Learning with Application to Chemical Molecules
Aug 09, 2022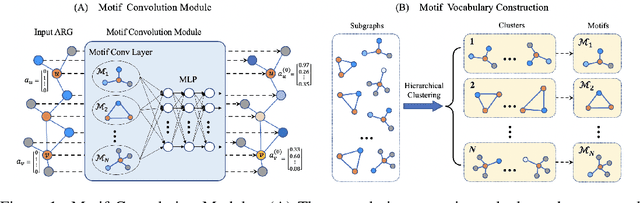

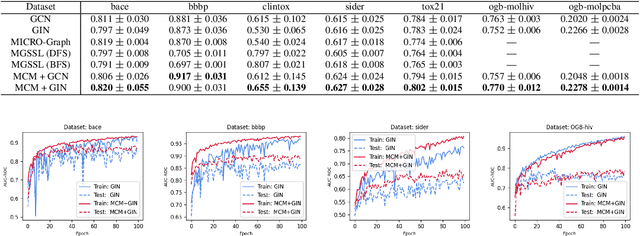
This work considers the task of representation learning on the attributed relational graph (ARG). Both the nodes and edges in an ARG are associated with attributes/features allowing ARGs to encode rich structural information widely observed in real applications. Existing graph neural networks offer limited ability to capture complex interactions within local structural contexts, which hinders them from taking advantage of the expression power of ARGs. We propose Motif Convolution Module (MCM), a new motif-based graph representation learning technique to better utilize local structural information. The ability to handle continuous edge and node features is one of MCM's advantages over existing motif-based models. MCM builds a motif vocabulary in an unsupervised way and deploys a novel motif convolution operation to extract the local structural context of individual nodes, which is then used to learn higher-level node representations via multilayer perceptron and/or message passing in graph neural networks. When compared with other graph learning approaches to classifying synthetic graphs, our approach is substantially better in capturing structural context. We also demonstrate the performance and explainability advantages of our approach by applying it to several molecular benchmarks.
Graph Information Bottleneck
Oct 24, 2020
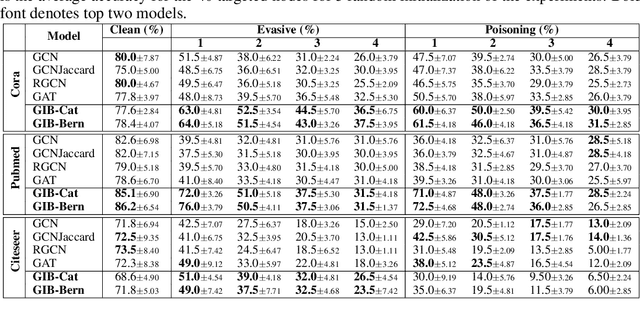
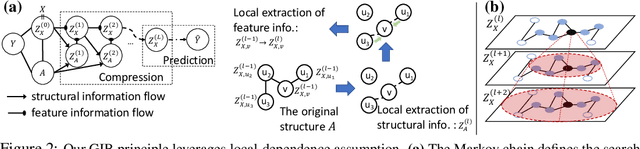

Representation learning of graph-structured data is challenging because both graph structure and node features carry important information. Graph Neural Networks (GNNs) provide an expressive way to fuse information from network structure and node features. However, GNNs are prone to adversarial attacks. Here we introduce Graph Information Bottleneck (GIB), an information-theoretic principle that optimally balances expressiveness and robustness of the learned representation of graph-structured data. Inheriting from the general Information Bottleneck (IB), GIB aims to learn the minimal sufficient representation for a given task by maximizing the mutual information between the representation and the target, and simultaneously constraining the mutual information between the representation and the input data. Different from the general IB, GIB regularizes the structural as well as the feature information. We design two sampling algorithms for structural regularization and instantiate the GIB principle with two new models: GIB-Cat and GIB-Bern, and demonstrate the benefits by evaluating the resilience to adversarial attacks. We show that our proposed models are more robust than state-of-the-art graph defense models. GIB-based models empirically achieve up to 31% improvement with adversarial perturbation of the graph structure as well as node features.
Neuromorphic implementation of ECG anomaly detection using delay chains
Sep 02, 2022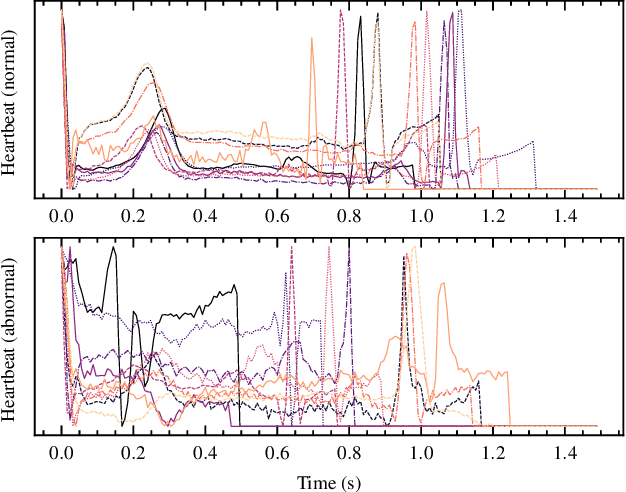
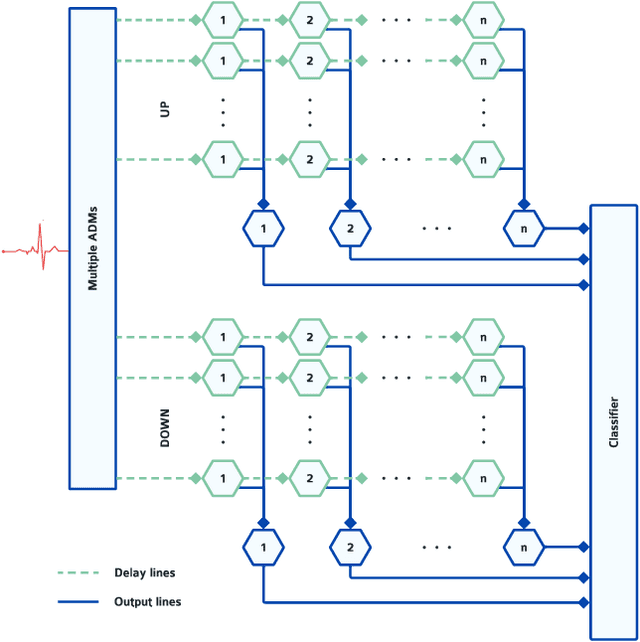
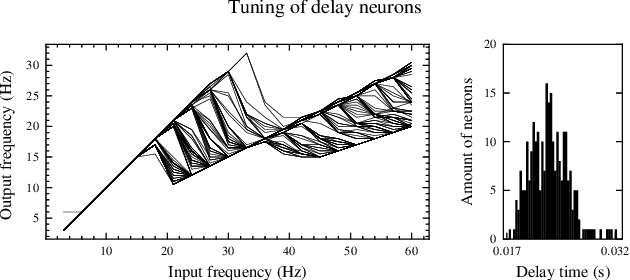
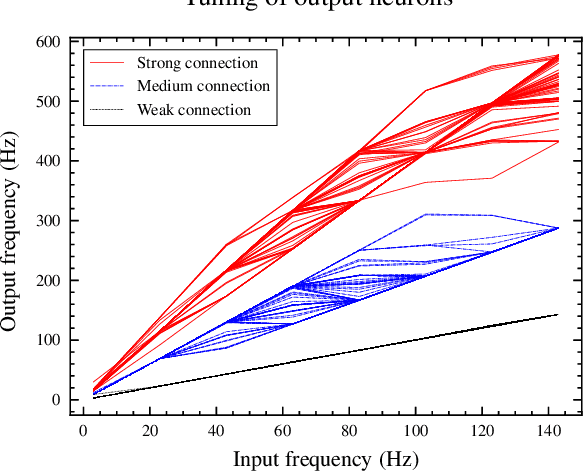
Real-time analysis and classification of bio-signals measured using wearable devices is computationally costly and requires dedicated low-power hardware. One promising approach is to use spiking neural networks implemented using in-memory computing architectures and neuromorphic electronic circuits. However, as these circuits process data in streaming mode without the possibility of storing it in external buffers, a major challenge lies in the processing of spatio-temporal signals that last longer than the time constants present in the network synapses and neurons. Here we propose to extend the memory capacity of a spiking neural network by using parallel delay chains. We show that it is possible to map temporal signals of multiple seconds into spiking activity distributed across multiple neurons which have time constants of few milliseconds. We validate this approach on an ECG anomaly detection task and present experimental results that demonstrate how temporal information is properly preserved in the network activity.
A Hybrid Deep Learning Model-based Remaining Useful Life Estimation for Reed Relay with Degradation Pattern Clustering
Sep 14, 2022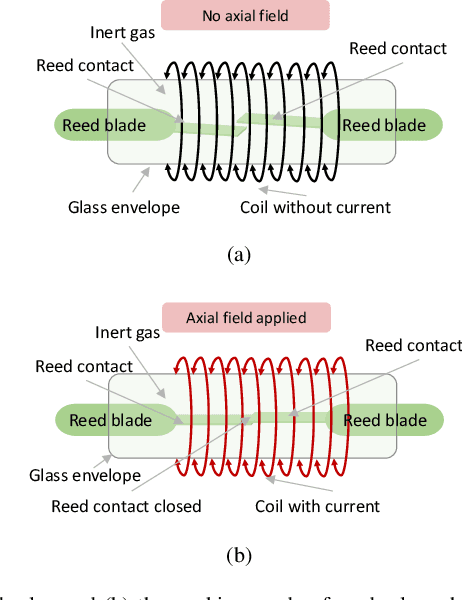
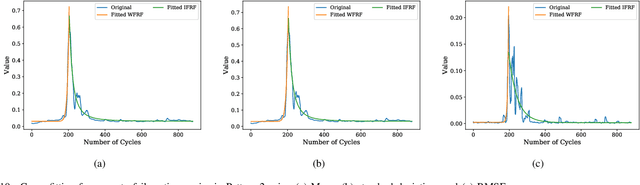
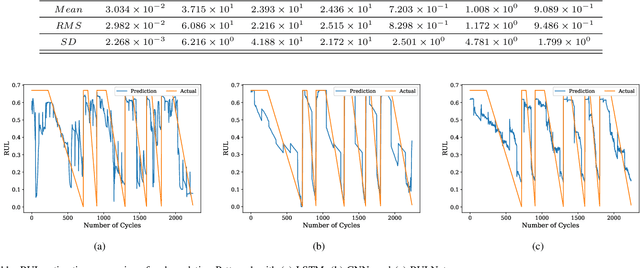
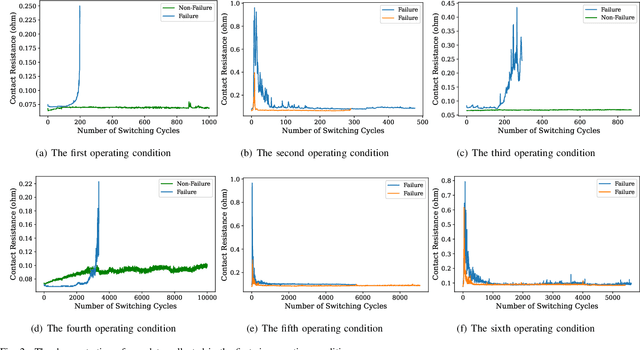
Reed relay serves as the fundamental component of functional testing, which closely relates to the successful quality inspection of electronics. To provide accurate remaining useful life (RUL) estimation for reed relay, a hybrid deep learning network with degradation pattern clustering is proposed based on the following three considerations. First, multiple degradation behaviors are observed for reed relay, and hence a dynamic time wrapping-based $K$-means clustering is offered to distinguish degradation patterns from each other. Second, although proper selections of features are of great significance, few studies are available to guide the selection. The proposed method recommends operational rules for easy implementation purposes. Third, a neural network for remaining useful life estimation (RULNet) is proposed to address the weakness of the convolutional neural network (CNN) in capturing temporal information of sequential data, which incorporates temporal correlation ability after high-level feature representation of convolutional operation. In this way, three variants of RULNet are constructed with health indicators, features with self-organizing map, or features with curve fitting. Ultimately, the proposed hybrid model is compared with the typical baseline models, including CNN and long short-term memory network (LSTM), through a practical reed relay dataset with two distinct degradation manners. The results from both degradation cases demonstrate that the proposed method outperforms CNN and LSTM regarding the index root mean squared error.
Information Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021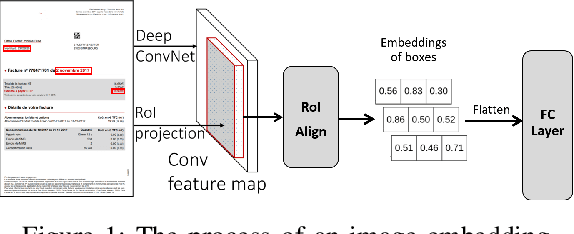
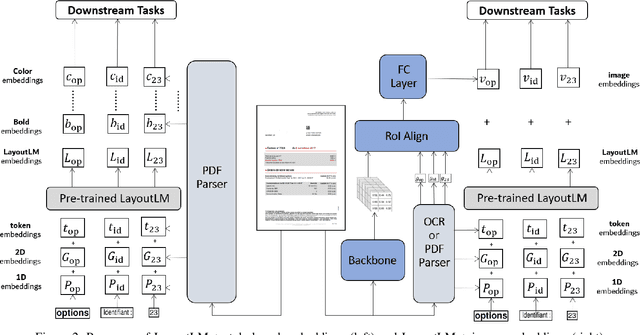

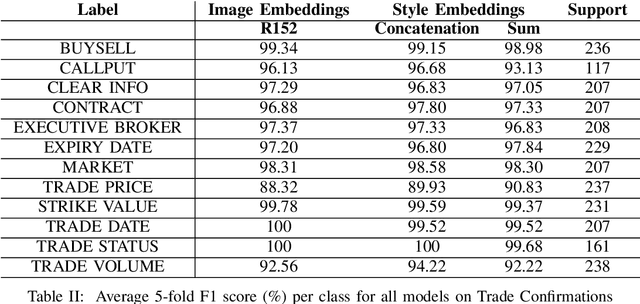
Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.
White-Box Adversarial Policies in Deep Reinforcement Learning
Sep 05, 2022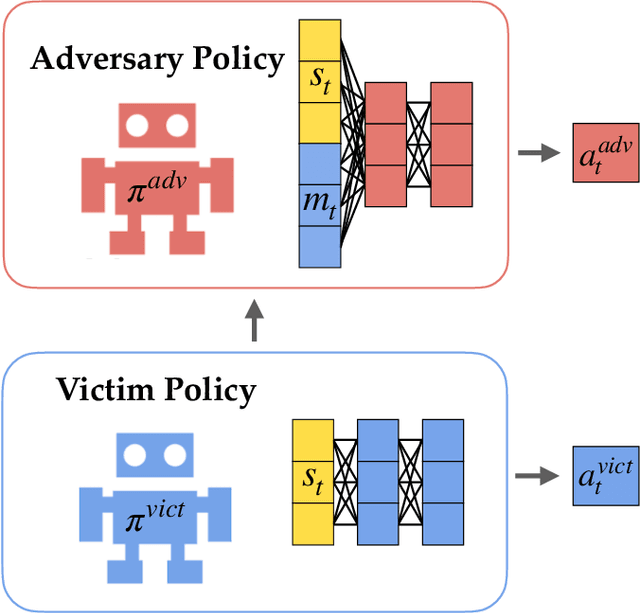
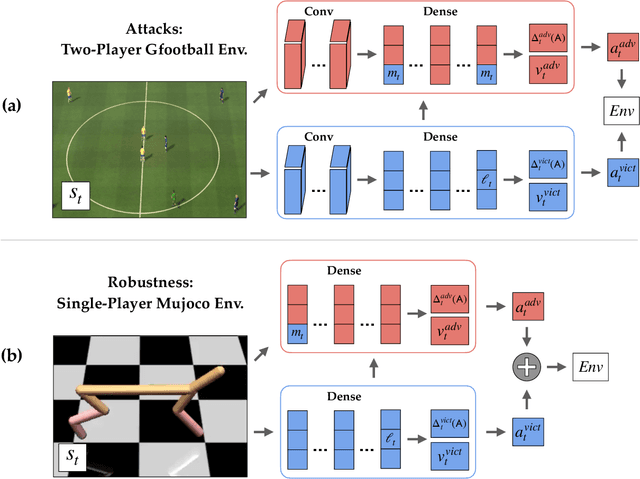
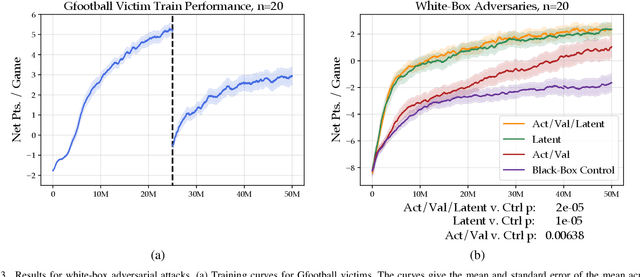
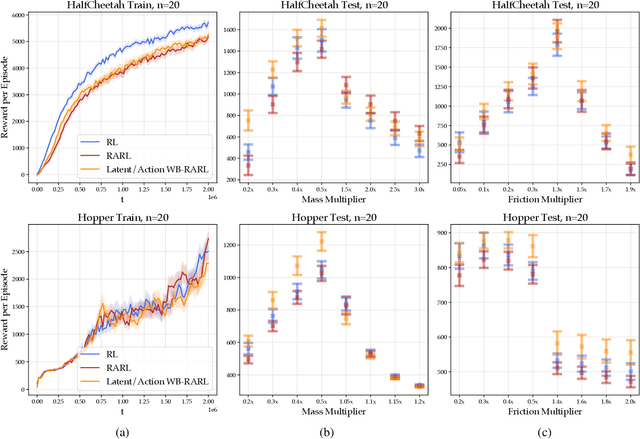
Adversarial examples against AI systems pose both risks via malicious attacks and opportunities for improving robustness via adversarial training. In multiagent settings, adversarial policies can be developed by training an adversarial agent to minimize a victim agent's rewards. Prior work has studied black-box attacks where the adversary only sees the state observations and effectively treats the victim as any other part of the environment. In this work, we experiment with white-box adversarial policies to study whether an agent's internal state can offer useful information for other agents. We make three contributions. First, we introduce white-box adversarial policies in which an attacker can observe a victim's internal state at each timestep. Second, we demonstrate that white-box access to a victim makes for better attacks in two-agent environments, resulting in both faster initial learning and higher asymptotic performance against the victim. Third, we show that training against white-box adversarial policies can be used to make learners in single-agent environments more robust to domain shifts.
A New Scheme for Image Compression and Encryption Using ECIES, Henon Map, and AEGAN
Aug 24, 2022


Providing security in the transmission of images and other multimedia data has become one of the most important scientific and practical issues. In this paper, a method for compressing and encryption images is proposed, which can safely transmit images in low-bandwidth data transmission channels. At first, using the autoencoding generative adversarial network (AEGAN) model, the images are mapped to a vector in the latent space with low dimensions. In the next step, the obtained vector is encrypted using public key encryption methods. In the proposed method, Henon chaotic map is used for permutation, which makes information transfer more secure. To evaluate the results of the proposed scheme, three criteria SSIM, PSNR, and execution time have been used.