 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Out-of-distribution Detection via Frequency-regularized Generative Models
Aug 18, 2022
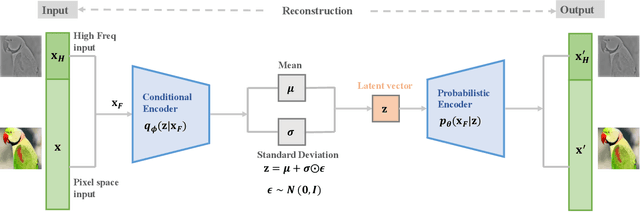
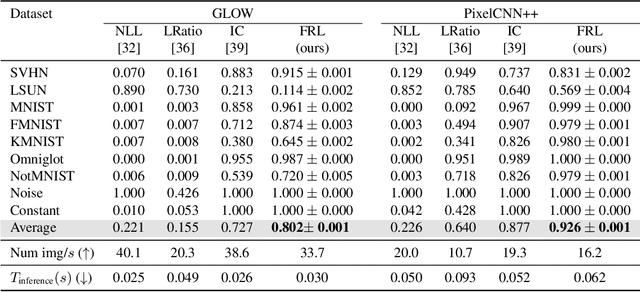

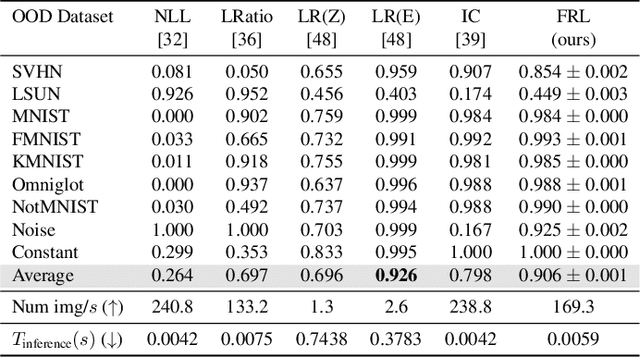
Modern deep generative models can assign high likelihood to inputs drawn from outside the training distribution, posing threats to models in open-world deployments. While much research attention has been placed on defining new test-time measures of OOD uncertainty, these methods do not fundamentally change how deep generative models are regularized and optimized in training. In particular, generative models are shown to overly rely on the background information to estimate the likelihood. To address the issue, we propose a novel frequency-regularized learning FRL framework for OOD detection, which incorporates high-frequency information into training and guides the model to focus on semantically relevant features. FRL effectively improves performance on a wide range of generative architectures, including variational auto-encoder, GLOW, and PixelCNN++. On a new large-scale evaluation task, FRL achieves the state-of-the-art performance, outperforming a strong baseline Likelihood Regret by 10.7% (AUROC) while achieving 147$\times$ faster inference speed. Extensive ablations show that FRL improves the OOD detection performance while preserving the image generation quality. Code is available at https://github.com/mu-cai/FRL.
Active Gaze Control for Foveal Scene Exploration
Aug 24, 2022
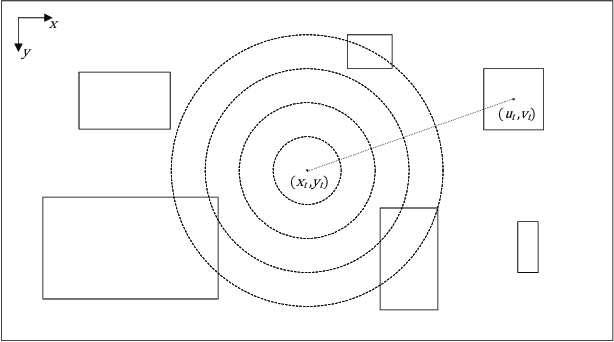

Active perception and foveal vision are the foundations of the human visual system. While foveal vision reduces the amount of information to process during a gaze fixation, active perception will change the gaze direction to the most promising parts of the visual field. We propose a methodology to emulate how humans and robots with foveal cameras would explore a scene, identifying the objects present in their surroundings with in least number of gaze shifts. Our approach is based on three key methods. First, we take an off-the-shelf deep object detector, pre-trained on a large dataset of regular images, and calibrate the classification outputs to the case of foveated images. Second, a body-centered semantic map, encoding the objects classifications and corresponding uncertainties, is sequentially updated with the calibrated detections, considering several data fusion techniques. Third, the next best gaze fixation point is determined based on information-theoretic metrics that aim at minimizing the overall expected uncertainty of the semantic map. When compared to the random selection of next gaze shifts, the proposed method achieves an increase in detection F1-score of 2-3 percentage points for the same number of gaze shifts and reduces to one third the number of required gaze shifts to attain similar performance.
Overparameterized (robust) models from computational constraints
Aug 27, 2022Overparameterized models with millions of parameters have been hugely successful. In this work, we ask: can the need for large models be, at least in part, due to the \emph{computational} limitations of the learner? Additionally, we ask, is this situation exacerbated for \emph{robust} learning? We show that this indeed could be the case. We show learning tasks for which computationally bounded learners need \emph{significantly more} model parameters than what information-theoretic learners need. Furthermore, we show that even more model parameters could be necessary for robust learning. In particular, for computationally bounded learners, we extend the recent result of Bubeck and Sellke [NeurIPS'2021] which shows that robust models might need more parameters, to the computational regime and show that bounded learners could provably need an even larger number of parameters. Then, we address the following related question: can we hope to remedy the situation for robust computationally bounded learning by restricting \emph{adversaries} to also be computationally bounded for sake of obtaining models with fewer parameters? Here again, we show that this could be possible. Specifically, building on the work of Garg, Jha, Mahloujifar, and Mahmoody [ALT'2020], we demonstrate a learning task that can be learned efficiently and robustly against a computationally bounded attacker, while to be robust against an information-theoretic attacker requires the learner to utilize significantly more parameters.
ESTA: An Esports Trajectory and Action Dataset
Sep 20, 2022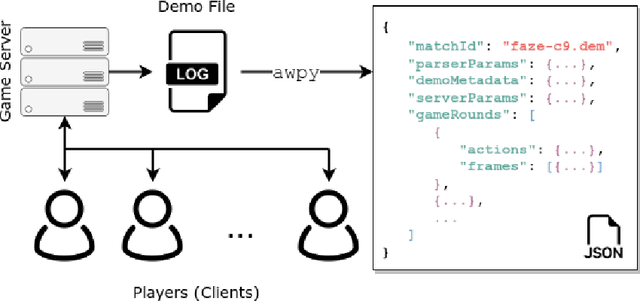
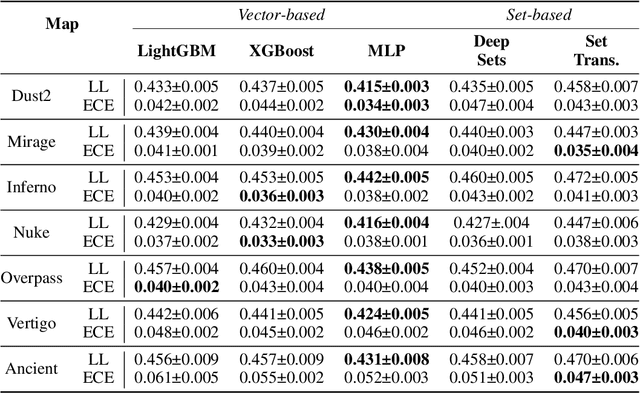

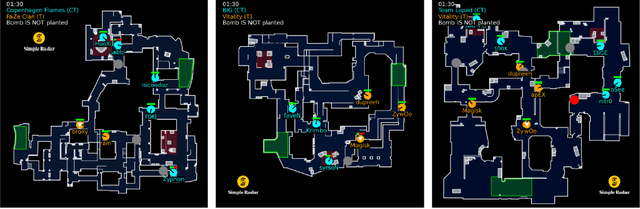
Sports, due to their global reach and impact-rich prediction tasks, are an exciting domain to deploy machine learning models. However, data from conventional sports is often unsuitable for research use due to its size, veracity, and accessibility. To address these issues, we turn to esports, a growing domain that encompasses video games played in a capacity similar to conventional sports. Since esports data is acquired through server logs rather than peripheral sensors, esports provides a unique opportunity to obtain a massive collection of clean and detailed spatiotemporal data, similar to those collected in conventional sports. To parse esports data, we develop awpy, an open-source esports game log parsing library that can extract player trajectories and actions from game logs. Using awpy, we parse 8.6m actions, 7.9m game frames, and 417k trajectories from 1,558 game logs from professional Counter-Strike tournaments to create the Esports Trajectory and Actions (ESTA) dataset. ESTA is one of the largest and most granular publicly available sports data sets to date. We use ESTA to develop benchmarks for win prediction using player-specific information. The ESTA data is available at https://github.com/pnxenopoulos/esta and awpy is made public through PyPI.
Multifaceted Hierarchical Report Identification for Non-Functional Bugs in Deep Learning Frameworks
Oct 04, 2022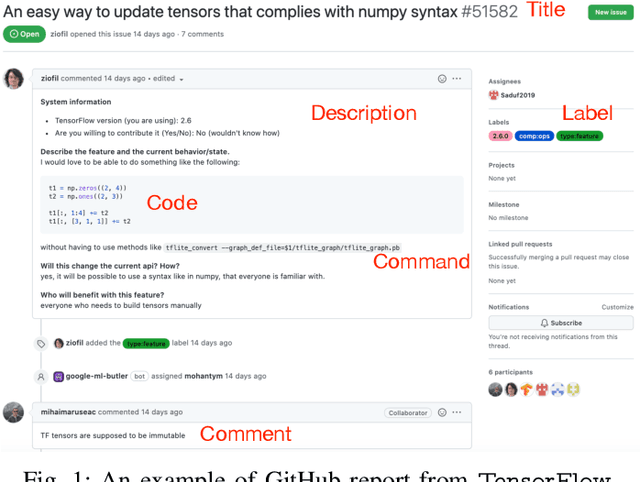

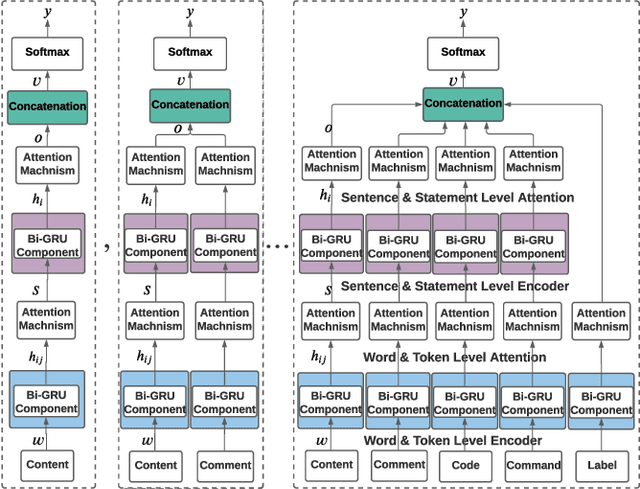
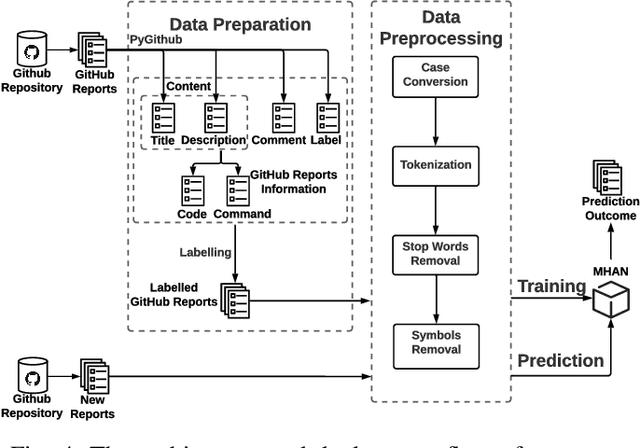
Non-functional bugs (e.g., performance- or accuracy-related bugs) in Deep Learning (DL) frameworks can lead to some of the most devastating consequences. Reporting those bugs on a repository such as GitHub is a standard route to fix them. Yet, given the growing number of new GitHub reports for DL frameworks, it is intrinsically difficult for developers to distinguish those that reveal non-functional bugs among the others, and assign them to the right contributor for investigation in a timely manner. In this paper, we propose MHNurf - an end-to-end tool for automatically identifying non-functional bug related reports in DL frameworks. The core of MHNurf is a Multifaceted Hierarchical Attention Network (MHAN) that tackles three unaddressed challenges: (1) learning the semantic knowledge, but doing so by (2) considering the hierarchy (e.g., words/tokens in sentences/statements) and focusing on the important parts (i.e., words, tokens, sentences, and statements) of a GitHub report, while (3) independently extracting information from different types of features, i.e., content, comment, code, command, and label. To evaluate MHNurf, we leverage 3,721 GitHub reports from five DL frameworks for conducting experiments. The results show that MHNurf works the best with a combination of content, comment, and code, which considerably outperforms the classic HAN where only the content is used. MHNurf also produces significantly more accurate results than nine other state-of-the-art classifiers with strong statistical significance, i.e., up to 71% AUC improvement and has the best Scott-Knott rank on four frameworks while 2nd on the remaining one. To facilitate reproduction and promote future research, we have made our dataset, code, and detailed supplementary results publicly available at: https://github.com/ideas-labo/APSEC2022-MHNurf.
Switchable Self-attention Module
Sep 13, 2022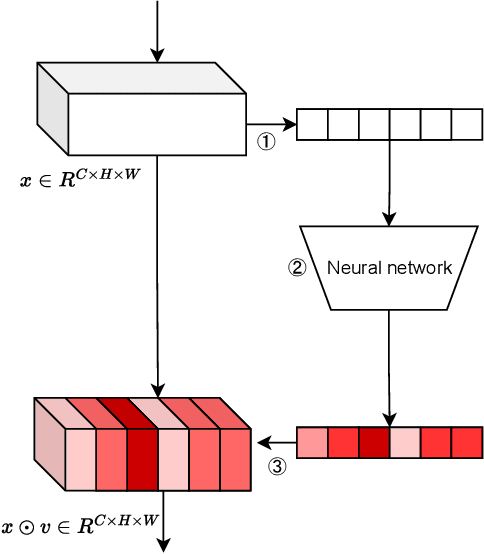
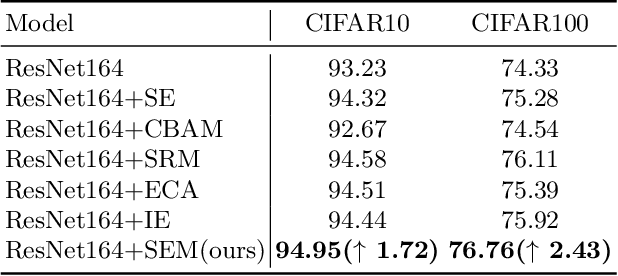
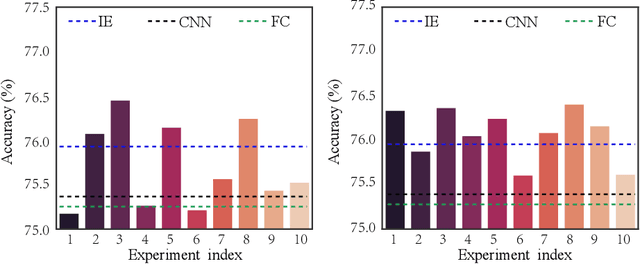
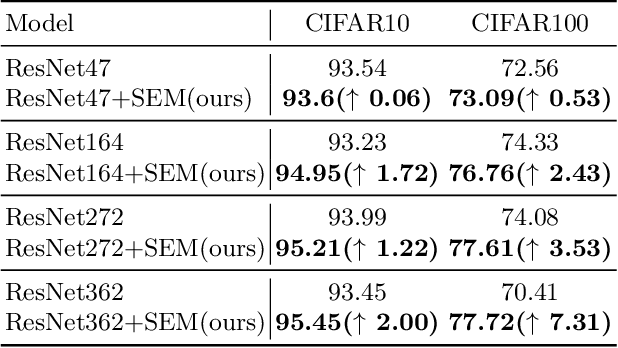
Attention mechanism has gained great success in vision recognition. Many works are devoted to improving the effectiveness of attention mechanism, which finely design the structure of the attention operator. These works need lots of experiments to pick out the optimal settings when scenarios change, which consumes a lot of time and computational resources. In addition, a neural network often contains many network layers, and most studies often use the same attention module to enhance different network layers, which hinders the further improvement of the performance of the self-attention mechanism. To address the above problems, we propose a self-attention module SEM. Based on the input information of the attention module and alternative attention operators, SEM can automatically decide to select and integrate attention operators to compute attention maps. The effectiveness of SEM is demonstrated by extensive experiments on widely used benchmark datasets and popular self-attention networks.
Clustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022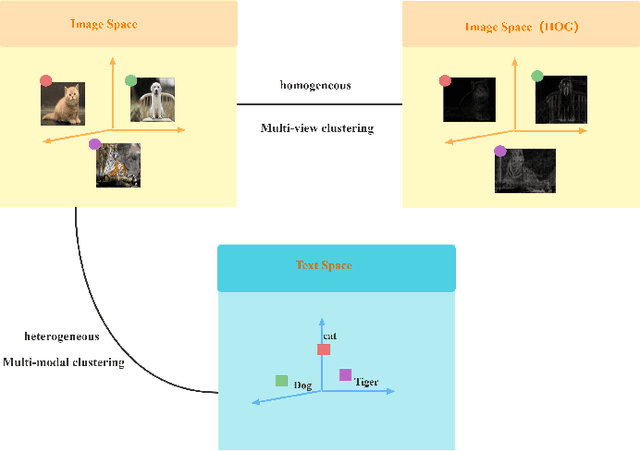
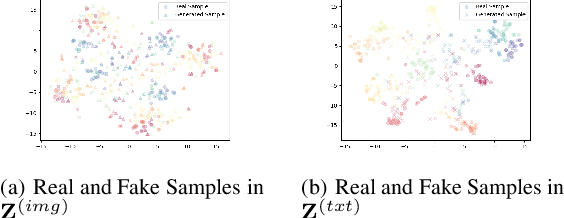

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.
Rethinking Data Augmentation in Knowledge Distillation for Object Detection
Sep 20, 2022
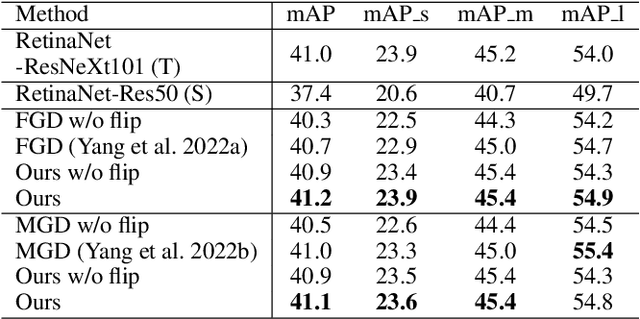

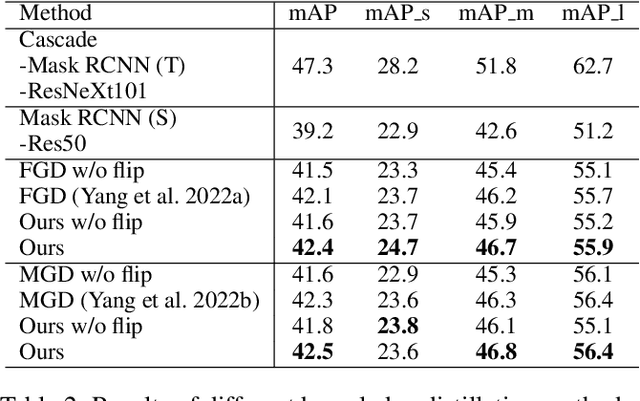
Knowledge distillation (KD) has shown its effectiveness for object detection, where it trains a compact object detector under the supervision of both AI knowledge (teacher detector) and human knowledge (human expert). However, existing studies treat the AI knowledge and human knowledge consistently and adopt a uniform data augmentation strategy during learning, which would lead to the biased learning of multi-scale objects and insufficient learning for the teacher detector causing unsatisfactory distillation performance. To tackle these problems, we propose the sample-specific data augmentation and adversarial feature augmentation. Firstly, to mitigate the impact incurred by multi-scale objects, we propose an adaptive data augmentation based on our observations from the Fourier perspective. Secondly, we propose a feature augmentation method based on adversarial examples for better mimicking AI knowledge to make up for the insufficient information mining of the teacher detector. Furthermore, our proposed method is unified and easily extended to other KD methods. Extensive experiments demonstrate the effectiveness of our framework and improve the performance of state-of-the-art methods in one-stage and two-stage detectors, bringing at most 0.5 mAP gains.
Signed Graph Neural Networks: A Frequency Perspective
Aug 15, 2022
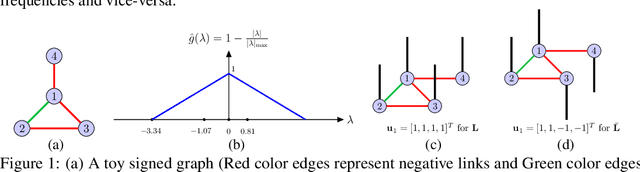
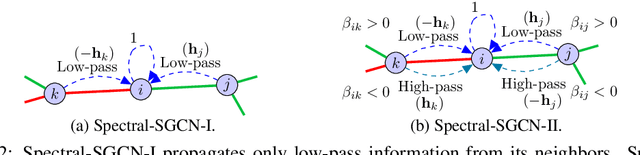

Graph convolutional networks (GCNs) and its variants are designed for unsigned graphs containing only positive links. Many existing GCNs have been derived from the spectral domain analysis of signals lying over (unsigned) graphs and in each convolution layer they perform low-pass filtering of the input features followed by a learnable linear transformation. Their extension to signed graphs with positive as well as negative links imposes multiple issues including computational irregularities and ambiguous frequency interpretation, making the design of computationally efficient low pass filters challenging. In this paper, we address these issues via spectral analysis of signed graphs and propose two different signed graph neural networks, one keeps only low-frequency information and one also retains high-frequency information. We further introduce magnetic signed Laplacian and use its eigendecomposition for spectral analysis of directed signed graphs. We test our methods for node classification and link sign prediction tasks on signed graphs and achieve state-of-the-art performances.
Q-Net: Query-Informed Few-Shot Medical Image Segmentation
Aug 24, 2022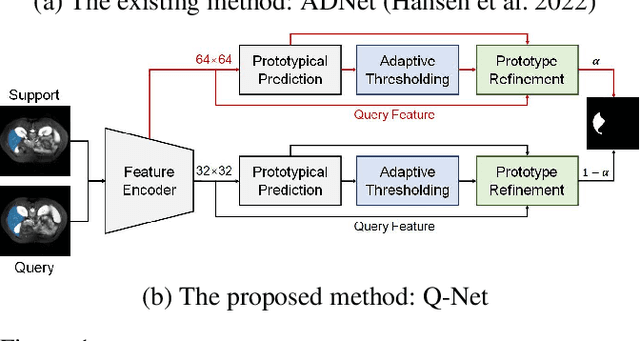
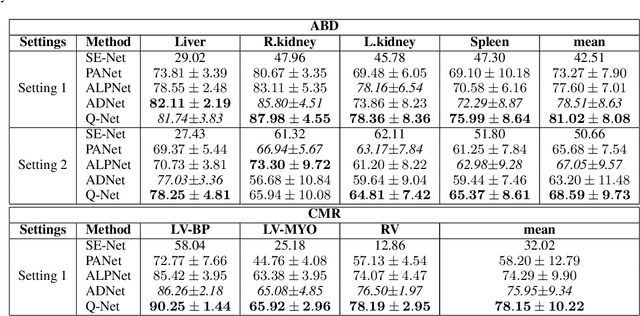
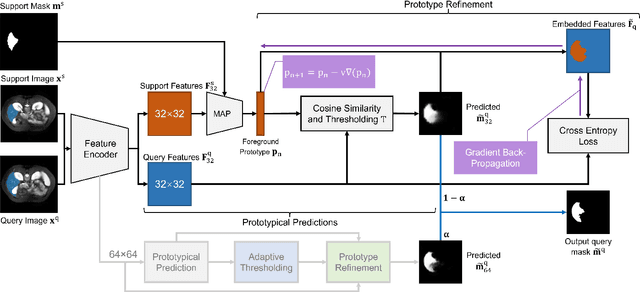
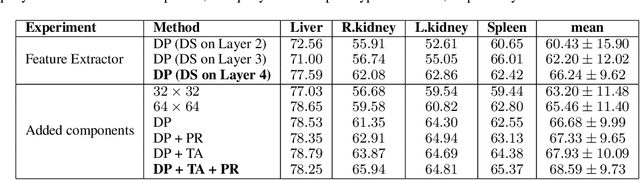
Deep learning has achieved tremendous success in computer vision, while medical image segmentation (MIS) remains a challenge, due to the scarcity of data annotations. Meta-learning techniques for few-shot segmentation (Meta-FSS) have been widely used to tackle this challenge, while they neglect possible distribution shifts between the query image and the support set. In contrast, an experienced clinician can perceive and address such shifts by borrowing information from the query image, then fine-tune or calibrate his (her) prior cognitive model accordingly. Inspired by this, we propose Q-Net, a Query-informed Meta-FSS approach, which mimics in spirit the learning mechanism of an expert clinician. We build Q-Net based on ADNet, a recently proposed anomaly detection-inspired method. Specifically, we add two query-informed computation modules into ADNet, namely a query-informed threshold adaptation module and a query-informed prototype refinement module. Combining them with a dual-path extension of the feature extraction module, Q-Net achieves state-of-the-art performance on two widely used datasets, which are composed of abdominal MR images and cardiac MR images, respectively. Our work sheds light on a novel way to improve Meta-FSS techniques by leveraging query information.