 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NOSMOG: Learning Noise-robust and Structure-aware MLPs on Graphs
Aug 22, 2022
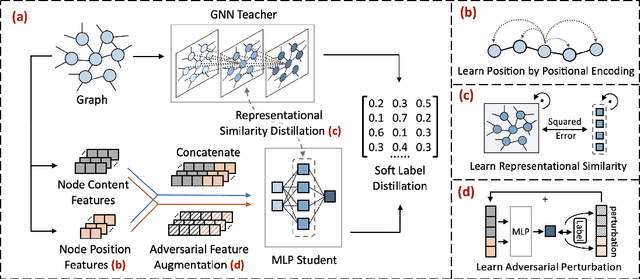
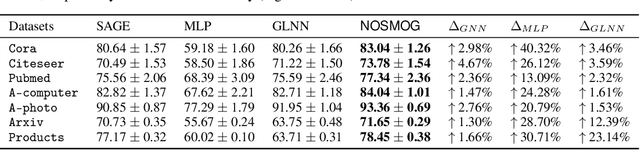
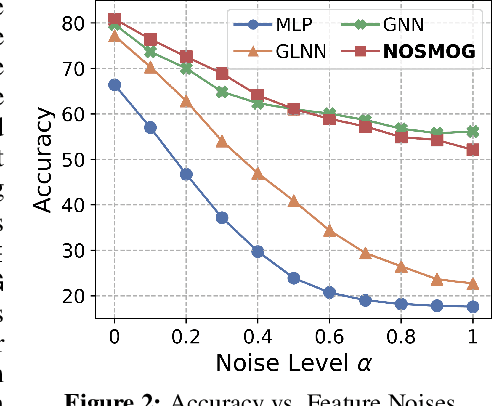
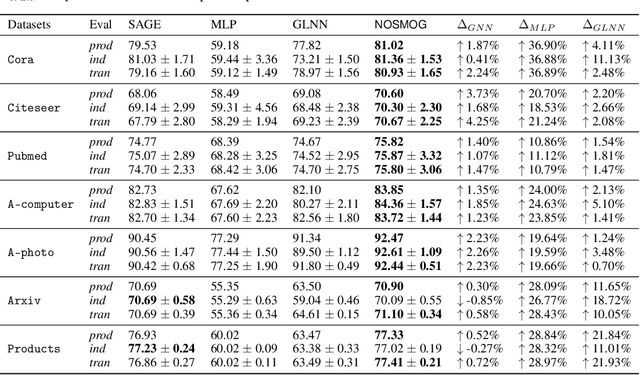
While Graph Neural Networks (GNNs) have demonstrated their efficacy in dealing with non-Euclidean structural data, they are difficult to be deployed in real applications due to the scalability constraint imposed by multi-hop data dependency. Existing methods attempt to address this scalability issue by training multi-layer perceptrons (MLPs) exclusively on node content features using labels derived from trained GNNs. Even though the performance of MLPs can be significantly improved, two issues prevent MLPs from outperforming GNNs and being used in practice: the ignorance of graph structural information and the sensitivity to node feature noises. In this paper, we propose to learn NOise-robust Structure-aware MLPs On Graphs (NOSMOG) to overcome the challenges. Specifically, we first complement node content with position features to help MLPs capture graph structural information. We then design a novel representational similarity distillation strategy to inject structural node similarities into MLPs. Finally, we introduce the adversarial feature augmentation to ensure stable learning against feature noises and further improve performance. Extensive experiments demonstrate that NOSMOG outperforms GNNs and the state-of-the-art method in both transductive and inductive settings across seven datasets, while maintaining a competitive inference efficiency.
GaitFM: Fine-grained Motion Representation for Gait Recognition
Sep 18, 2022
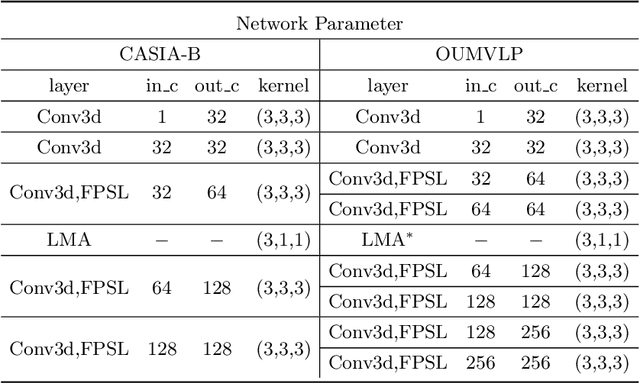
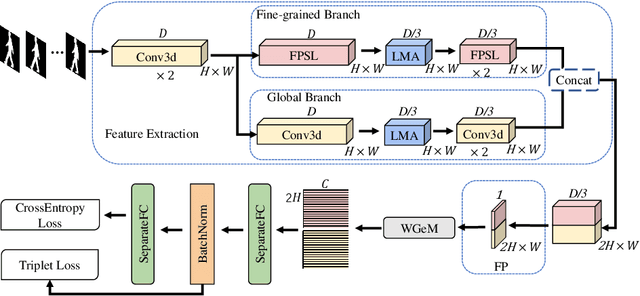
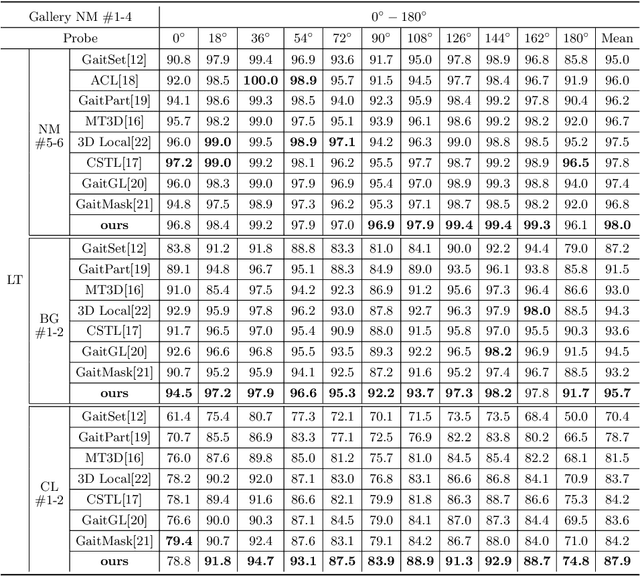
Gait recognition aims at identifying individual-specific walking patterns, which is highly dependent on the observation of the different periodic movements of each body part. However, most existing methods treat each part equally and neglect the data redundancy due to the high sampling rate of gait sequences. In this work, we propose a fine-grained motion representation network (GaitFM) to improve gait recognition performance in three aspects. First, a fine-grained part sequence learning (FPSL) module is designed to explore part-independent spatio-temporal representations. Secondly, a frame-wise compression strategy, called local motion aggregation (LMA), is used to enhance motion variations. Finally, a weighted generalized mean pooling (WGeM) layer works to adaptively keep more discriminative information in the spatial downsampling. Experiments on two public datasets, CASIA-B and OUMVLP, show that our approach reaches state-of-the-art performances. On the CASIA-B dataset, our method achieves rank-1 accuracies of 98.0%, 95.7% and 87.9% for normal walking, walking with a bag and walking with a coat, respectively. On the OUMVLP dataset, our method achieved a rank-1 accuracy of 90.5%.
SmartKex: Machine Learning Assisted SSH Keys Extraction From The Heap Dump
Sep 13, 2022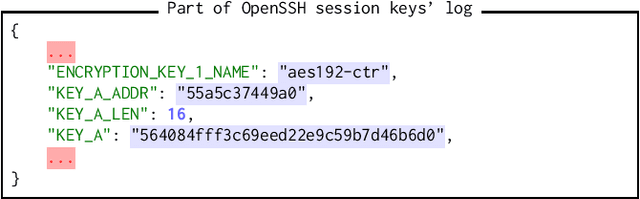

Digital forensics is the process of extracting, preserving, and documenting evidence in digital devices. A commonly used method in digital forensics is to extract data from the main memory of a digital device. However, the main challenge is identifying the important data to be extracted. Several pieces of crucial information reside in the main memory, like usernames, passwords, and cryptographic keys such as SSH session keys. In this paper, we propose SmartKex, a machine-learning assisted method to extract session keys from heap memory snapshots of an OpenSSH process. In addition, we release an openly available dataset and the corresponding toolchain for creating additional data. Finally, we compare SmartKex with naive brute-force methods and empirically show that SmartKex can extract the session keys with high accuracy and high throughput. With the provided resources, we intend to strengthen the research on the intersection between digital forensics, cybersecurity, and machine learning.
A Deep Neural Network for Multiclass Bridge Element Parsing in Inspection Image Analysis
Sep 05, 2022
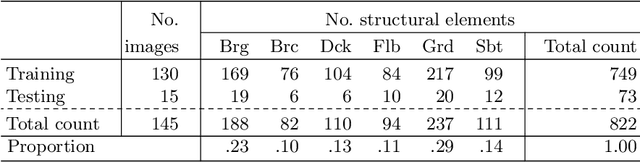


Aerial robots such as drones have been leveraged to perform bridge inspections. Inspection images with both recognizable structural elements and apparent surface defects can be collected by onboard cameras to provide valuable information for the condition assessment. This article aims to determine a suitable deep neural network (DNN) for parsing multiclass bridge elements in inspection images. An extensive set of quantitative evaluations along with qualitative examples show that High-Resolution Net (HRNet) possesses the desired ability. With data augmentation and a training sample of 130 images, a pre-trained HRNet is efficiently transferred to the task of structural element parsing and has achieved a 92.67% mean F1-score and 86.33% mean IoU.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022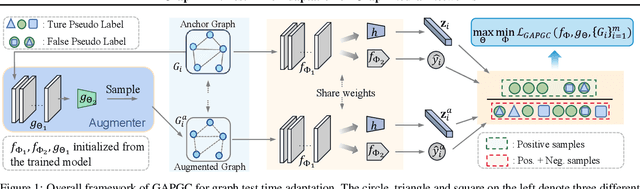
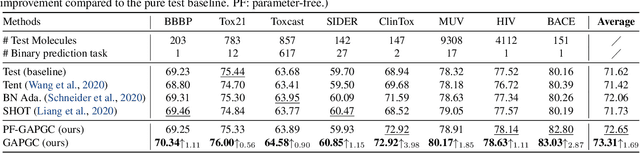
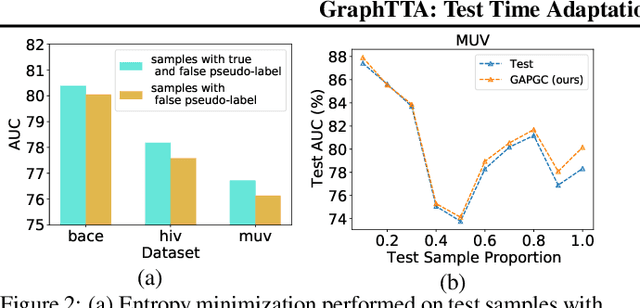

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
TAG: Learning Circuit Spatial Embedding From Layouts
Sep 07, 2022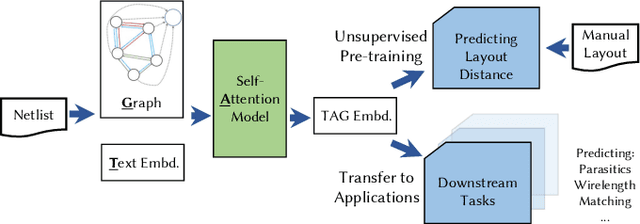
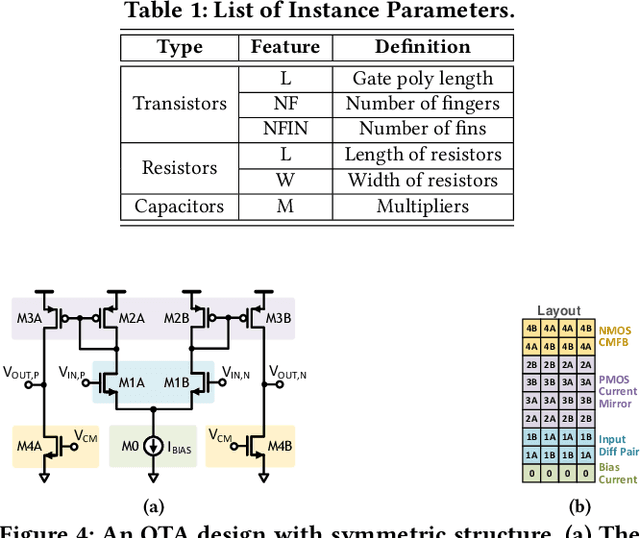
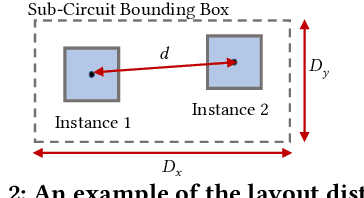
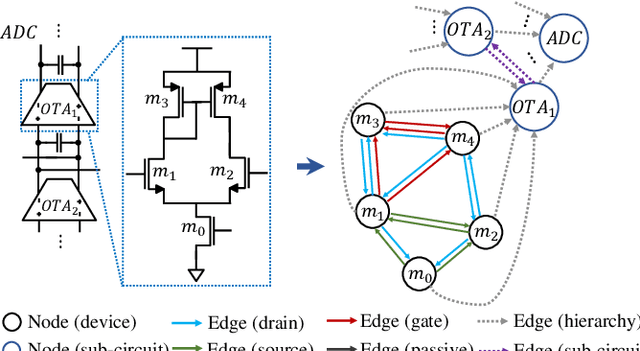
Analog and mixed-signal (AMS) circuit designs still rely on human design expertise. Machine learning has been assisting circuit design automation by replacing human experience with artificial intelligence. This paper presents TAG, a new paradigm of learning the circuit representation from layouts leveraging text, self-attention and graph. The embedding network model learns spatial information without manual labeling. We introduce text embedding and a self-attention mechanism to AMS circuit learning. Experimental results demonstrate the ability to predict layout distances between instances with industrial FinFET technology benchmarks. The effectiveness of the circuit representation is verified by showing the transferability to three other learning tasks with limited data in the case studies: layout matching prediction, wirelength estimation, and net parasitic capacitance prediction.
Unsupervised Hashing with Contrastive Information Bottleneck
May 13, 2021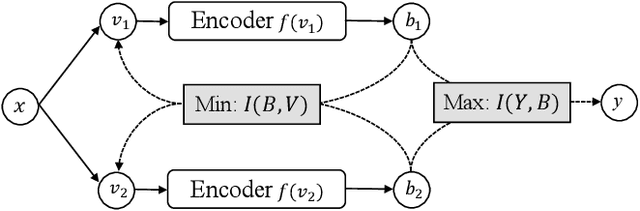
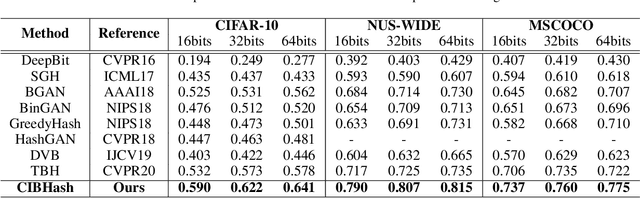
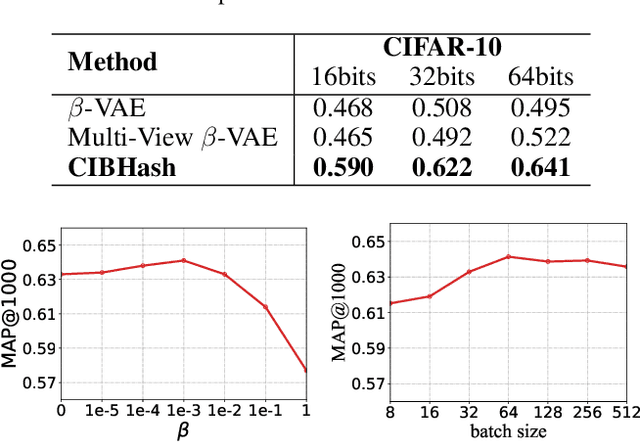
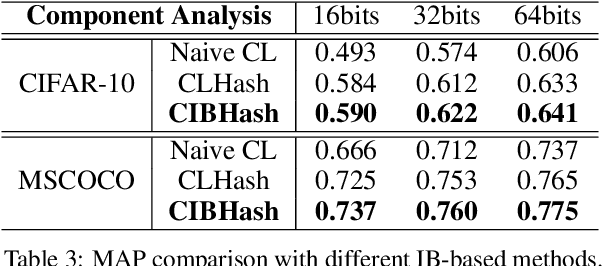
Many unsupervised hashing methods are implicitly established on the idea of reconstructing the input data, which basically encourages the hashing codes to retain as much information of original data as possible. However, this requirement may force the models spending lots of their effort on reconstructing the unuseful background information, while ignoring to preserve the discriminative semantic information that is more important for the hashing task. To tackle this problem, inspired by the recent success of contrastive learning in learning continuous representations, we propose to adapt this framework to learn binary hashing codes. Specifically, we first propose to modify the objective function to meet the specific requirement of hashing and then introduce a probabilistic binary representation layer into the model to facilitate end-to-end training of the entire model. We further prove the strong connection between the proposed contrastive-learning-based hashing method and the mutual information, and show that the proposed model can be considered under the broader framework of the information bottleneck (IB). Under this perspective, a more general hashing model is naturally obtained. Extensive experimental results on three benchmark image datasets demonstrate that the proposed hashing method significantly outperforms existing baselines.
View-Invariant Skeleton-based Action Recognition via Global-Local Contrastive Learning
Sep 23, 2022
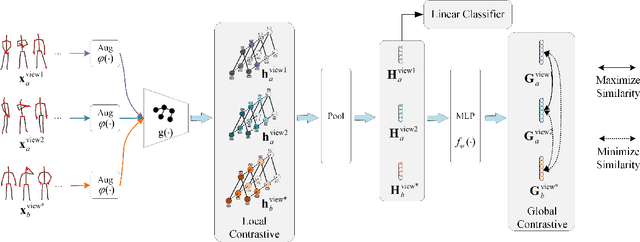
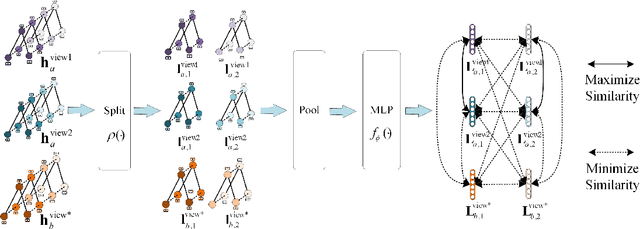
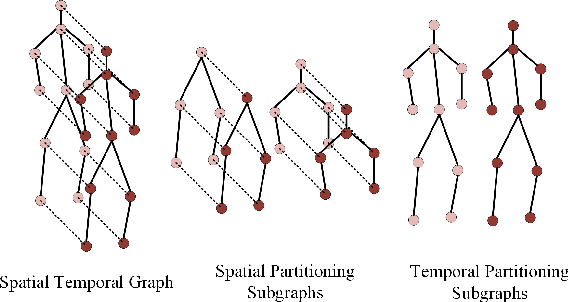
Skeleton-based human action recognition has been drawing more interest recently due to its low sensitivity to appearance changes and the accessibility of more skeleton data. However, even the 3D skeletons captured in practice are still sensitive to the viewpoint and direction gave the occlusion of different human-body joints and the errors in human joint localization. Such view variance of skeleton data may significantly affect the performance of action recognition. To address this issue, we propose in this paper a new view-invariant representation learning approach, without any manual action labeling, for skeleton-based human action recognition. Specifically, we leverage the multi-view skeleton data simultaneously taken for the same person in the network training, by maximizing the mutual information between the representations extracted from different views, and then propose a global-local contrastive loss to model the multi-scale co-occurrence relationships in both spatial and temporal domains. Extensive experimental results show that the proposed method is robust to the view difference of the input skeleton data and significantly boosts the performance of unsupervised skeleton-based human action methods, resulting in new state-of-the-art accuracies on two challenging multi-view benchmarks of PKUMMD and NTU RGB+D.
Accelerated RRT* By Local Directional Visibility
Jul 17, 2022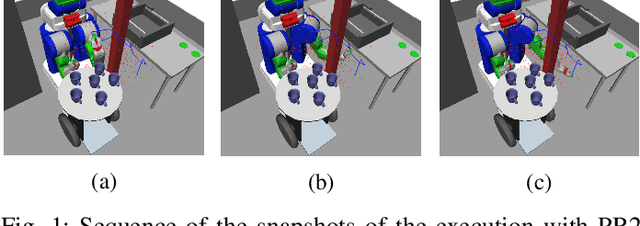
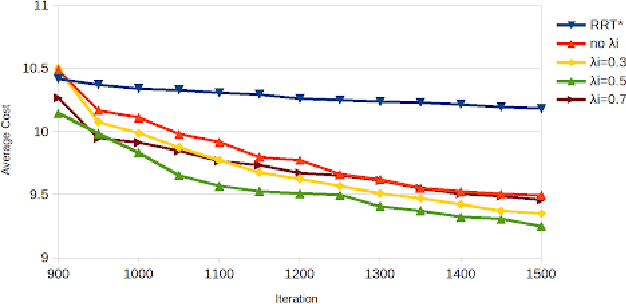
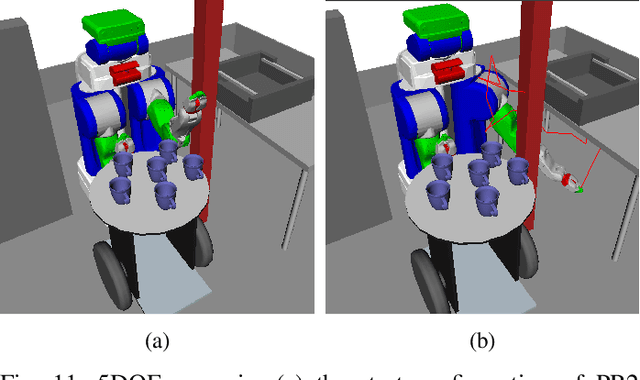
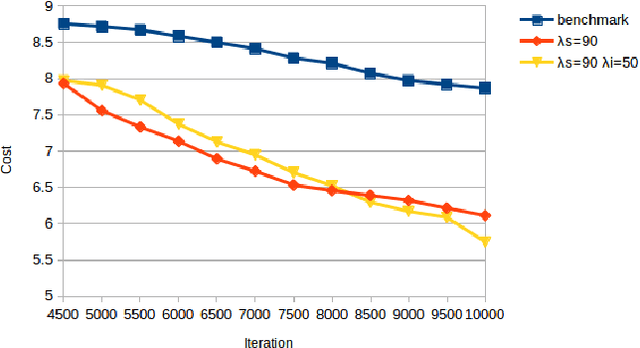
RRT* is an efficient sampling-based motion planning algorithm. However, without taking advantages of accessible environment information, sampling-based algorithms usually result in sampling failures, generate useless nodes, and/or fail in exploring narrow passages. For this paper, in order to better utilize environment information and further improve searching efficiency, we proposed a novel approach to improve RRT* by 1) quantifying local knowledge of the obstacle configurations during neighbour rewiring in terms of directional visibility, 2) collecting environment information during searching, and 3) changing the sampling strategy biasing toward near-obstacle nodes after the first solution found. The proposed algorithm RRT* by Local Directional Visibility (RRT*-LDV) better utilizes local known information and innovates a weighted sampling strategy. The accelerated RRT*-LDV outperforms RRT* in convergence rate and success rate of finding narrow passages. A high Degree-Of-Freedom scenario is also experimented.
VREN: Volleyball Rally Dataset with Expression Notation Language
Sep 28, 2022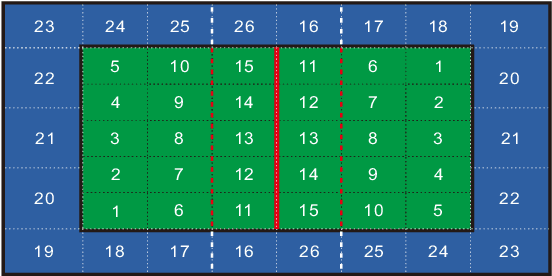

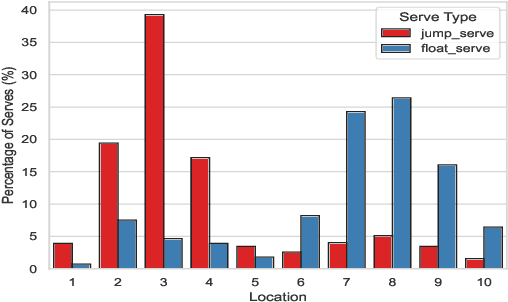
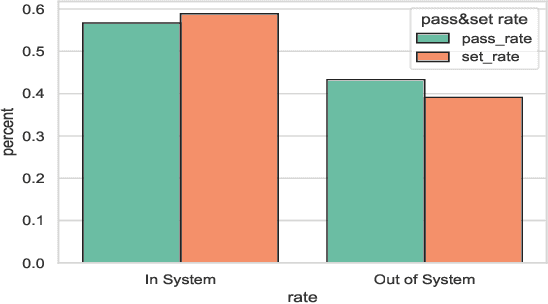
This research is intended to accomplish two goals: The first goal is to curate a large and information rich dataset that contains crucial and succinct summaries on the players' actions and positions and the back-and-forth travel patterns of the volleyball in professional and NCAA Div-I indoor volleyball games. While several prior studies have aimed to create similar datasets for other sports (e.g. badminton and soccer), creating such a dataset for indoor volleyball is not yet realized. The second goal is to introduce a volleyball descriptive language to fully describe the rally processes in the games and apply the language to our dataset. Based on the curated dataset and our descriptive sports language, we introduce three tasks for automated volleyball action and tactic analysis using our dataset: (1) Volleyball Rally Prediction, aimed at predicting the outcome of a rally and helping players and coaches improve decision-making in practice, (2) Setting Type and Hitting Type Prediction, to help coaches and players prepare more effectively for the game, and (3) Volleyball Tactics and Attacking Zone Statistics, to provide advanced volleyball statistics and help coaches understand the game and opponent's tactics better. We conducted case studies to show how experimental results can provide insights to the volleyball analysis community. Furthermore, experimental evaluation based on real-world data establishes a baseline for future studies and applications of our dataset and language. This study bridges the gap between the indoor volleyball field and computer science.