 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021
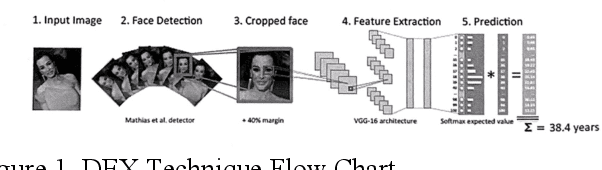
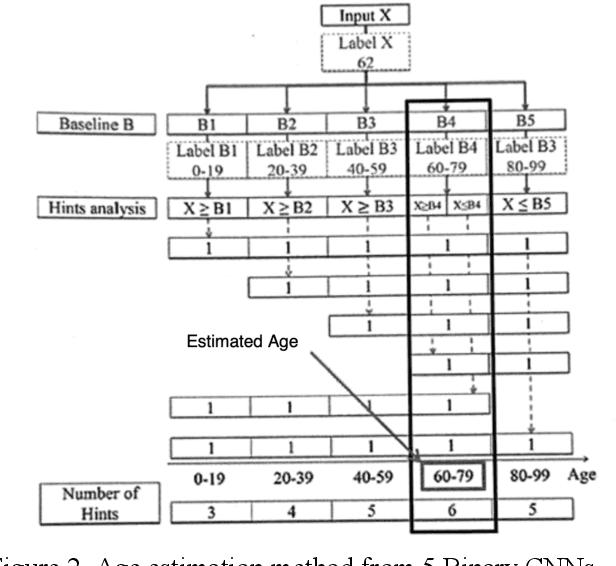
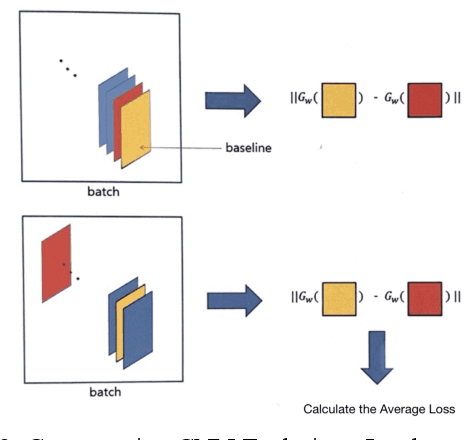
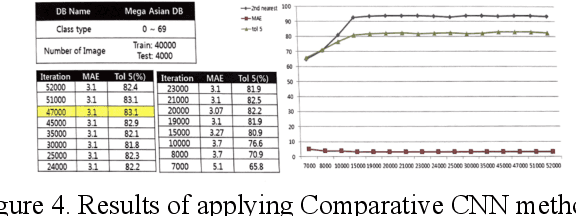
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Interpretable Fake News Detection with Topic and Deep Variational Models
Sep 04, 2022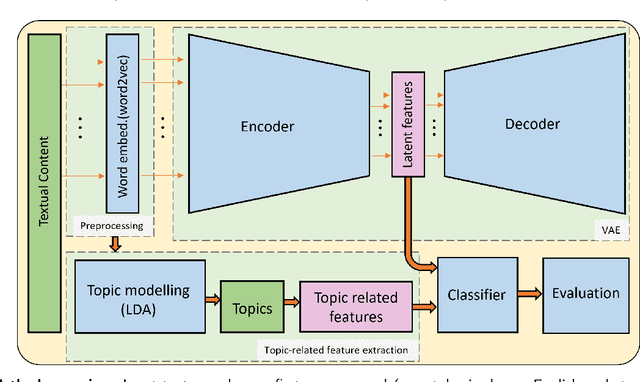
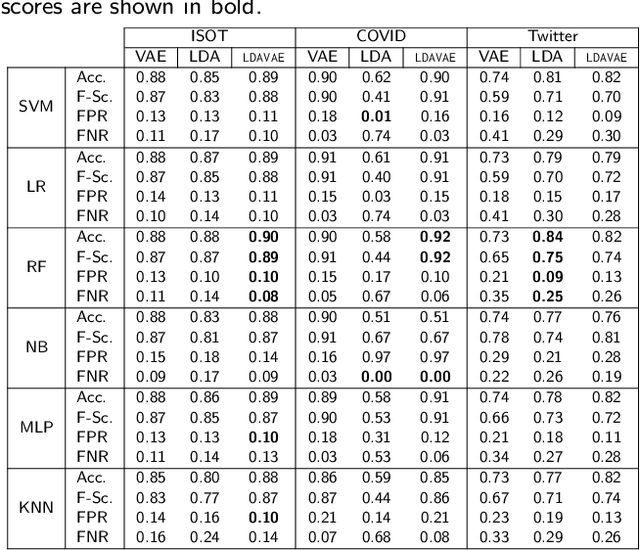
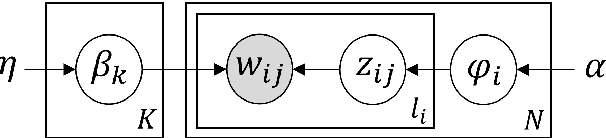
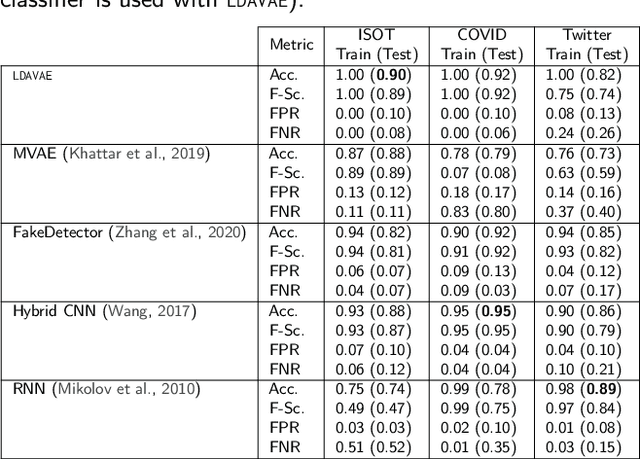
The growing societal dependence on social media and user generated content for news and information has increased the influence of unreliable sources and fake content, which muddles public discourse and lessens trust in the media. Validating the credibility of such information is a difficult task that is susceptible to confirmation bias, leading to the development of algorithmic techniques to distinguish between fake and real news. However, most existing methods are challenging to interpret, making it difficult to establish trust in predictions, and make assumptions that are unrealistic in many real-world scenarios, e.g., the availability of audiovisual features or provenance. In this work, we focus on fake news detection of textual content using interpretable features and methods. In particular, we have developed a deep probabilistic model that integrates a dense representation of textual news using a variational autoencoder and bi-directional Long Short-Term Memory (LSTM) networks with semantic topic-related features inferred from a Bayesian admixture model. Extensive experimental studies with 3 real-world datasets demonstrate that our model achieves comparable performance to state-of-the-art competing models while facilitating model interpretability from the learned topics. Finally, we have conducted model ablation studies to justify the effectiveness and accuracy of integrating neural embeddings and topic features both quantitatively by evaluating performance and qualitatively through separability in lower dimensional embeddings.
PIMIP: An Open Source Platform for Pathology Information Management and Integration
Nov 09, 2021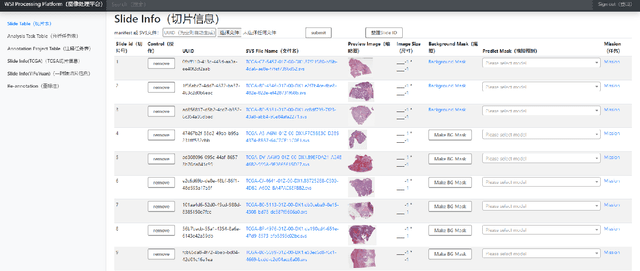
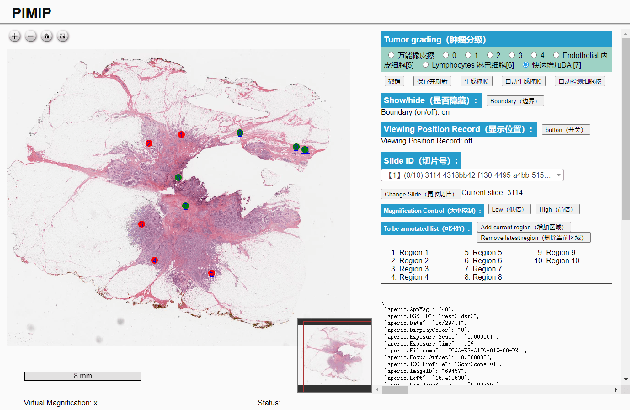
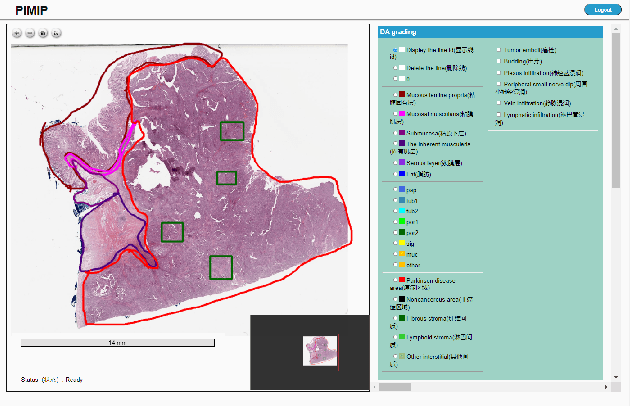
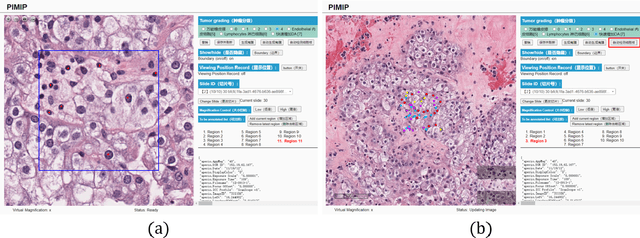
Digital pathology plays a crucial role in the development of artificial intelligence in the medical field. The digital pathology platform can make the pathological resources digital and networked, and realize the permanent storage of visual data and the synchronous browsing processing without the limitation of time and space. It has been widely used in various fields of pathology. However, there is still a lack of an open and universal digital pathology platform to assist doctors in the management and analysis of digital pathological sections, as well as the management and structured description of relevant patient information. Most platforms cannot integrate image viewing, annotation and analysis, and text information management. To solve the above problems, we propose a comprehensive and extensible platform PIMIP. Our PIMIP has developed the image annotation functions based on the visualization of digital pathological sections. Our annotation functions support multi-user collaborative annotation and multi-device annotation, and realize the automation of some annotation tasks. In the annotation task, we invited a professional pathologist for guidance. We introduce a machine learning module for image analysis. The data we collected included public data from local hospitals and clinical examples. Our platform is more clinical and suitable for clinical use. In addition to image data, we also structured the management and display of text information. So our platform is comprehensive. The platform framework is built in a modular way to support users to add machine learning modules independently, which makes our platform extensible.
Distributed Complementary Fusion for Connected Vehicles
Sep 09, 2022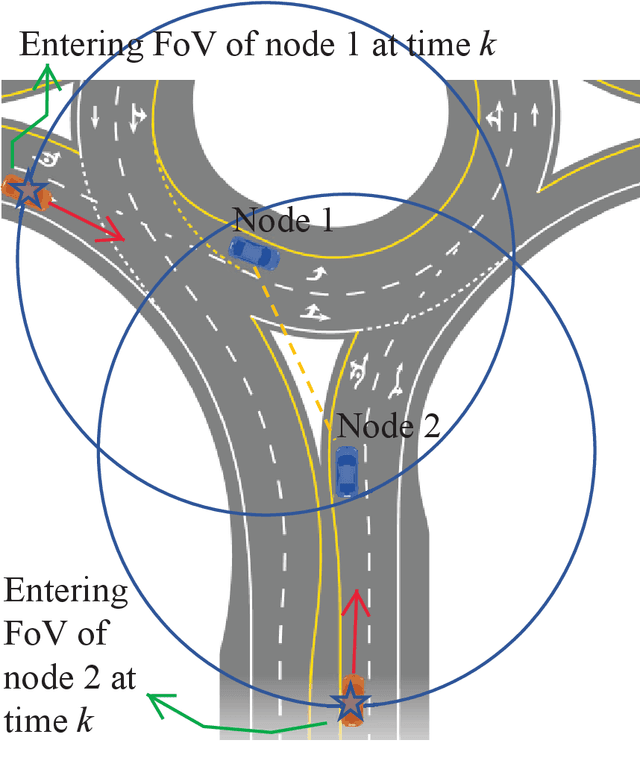
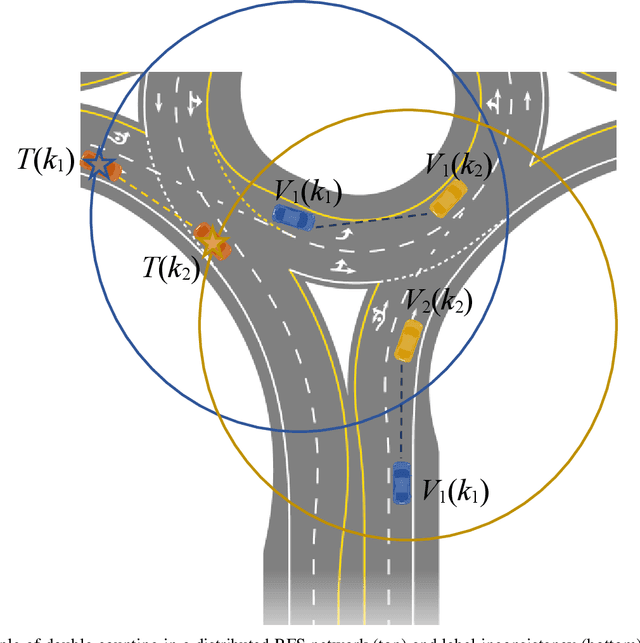
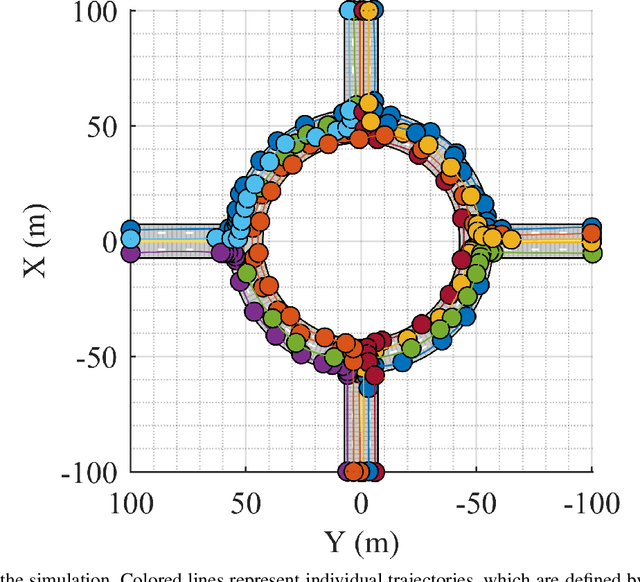
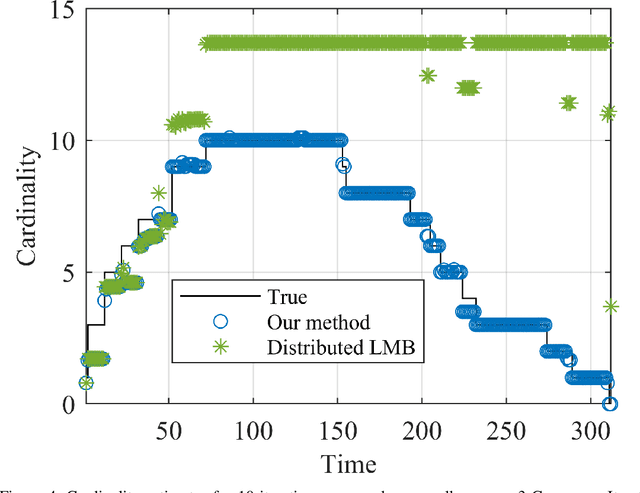
We present a random finite set-based method for achieving comprehensive situation awareness by each vehicle in a distributed vehicle network. Our solution is designed for labeled multi-Bernoulli filters running in each vehicle. It involves complementary fusion of sensor information locally running through consensus iterations. We introduce a novel label merging algorithm to eliminate double counting. We also extend the label space to incorporate sensor identities. This helps to overcome label inconsistencies. We show that the proposed algorithm is able to outperform the standard LMB filter using a distributed complementary approach with limited fields of view.
Data augmentation on graphs for table type classification
Aug 23, 2022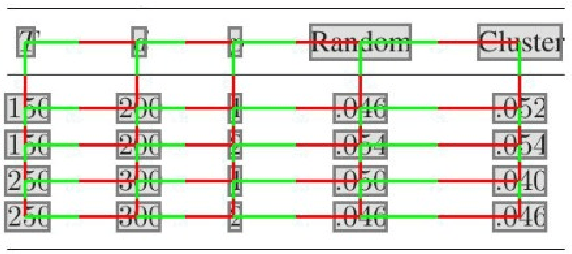
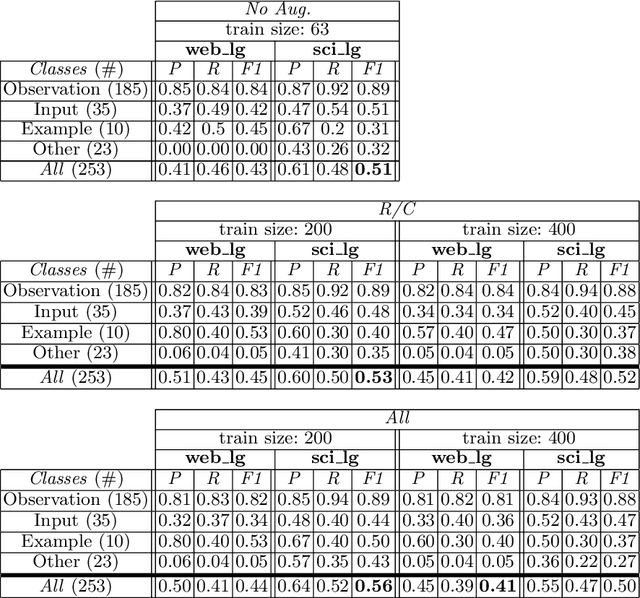
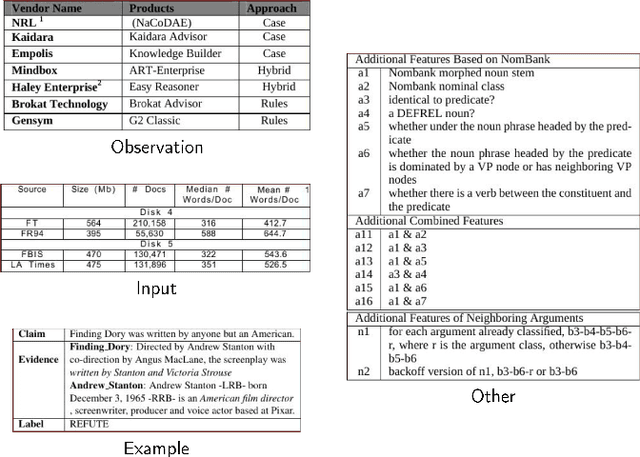
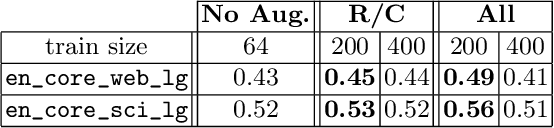
Tables are widely used in documents because of their compact and structured representation of information. In particular, in scientific papers, tables can sum up novel discoveries and summarize experimental results, making the research comparable and easily understandable by scholars. Since the layout of tables is highly variable, it would be useful to interpret their content and classify them into categories. This could be helpful to directly extract information from scientific papers, for instance comparing performance of some models given their paper result tables. In this work, we address the classification of tables using a Graph Neural Network, exploiting the table structure for the message passing algorithm in use. We evaluate our model on a subset of the Tab2Know dataset. Since it contains few examples manually annotated, we propose data augmentation techniques directly on the table graph structures. We achieve promising preliminary results, proposing a data augmentation method suitable for graph-based table representation.
Metal Inpainting in CBCT Projections Using Score-based Generative Model
Sep 20, 2022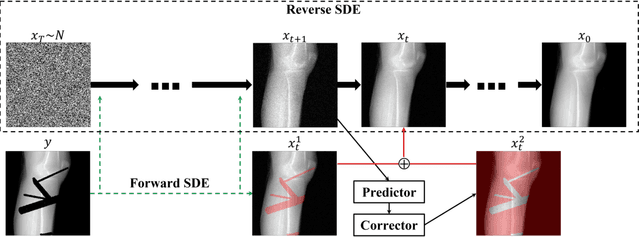
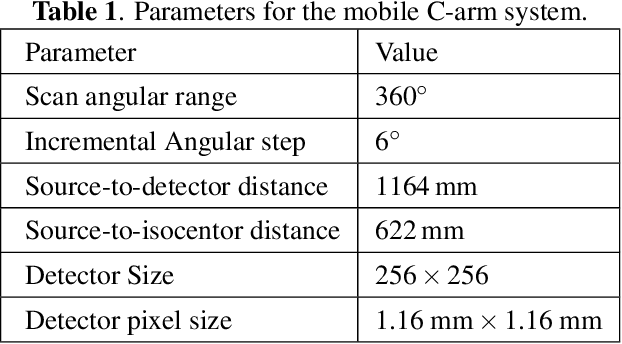
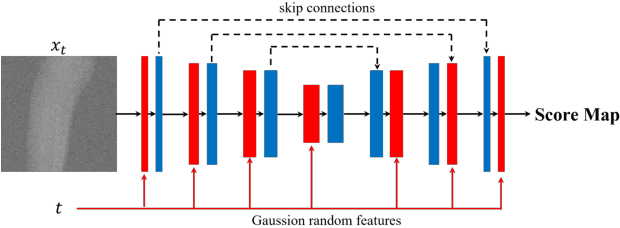
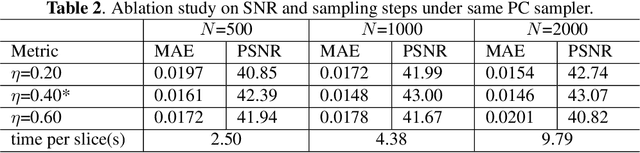
During orthopaedic surgery, the inserting of metallic implants or screws are often performed under mobile C-arm systems. Due to the high attenuation of metals, severe metal artifacts occur in 3D reconstructions, which degrade the image quality greatly. To reduce the artifacts, many metal artifact reduction algorithms have been developed and metal inpainting in projection domain is an essential step. In this work, a score-based generative model is trained on simulated knee projections and the inpainted image is obtained by removing the noise in conditional resampling process. The result implies that the inpainted images by score-based generative model have more detailed information and achieve the lowest mean absolute error and the highest peak-signal-to-noise-ratio compared with interpolation and CNN based method. Besides, the score-based model can also recover projections with big circlar and rectangular masks, showing its generalization in inpainting task.
AoI-based Temporal Attention Graph Neural Network for Popularity Prediction and Content Caching
Aug 18, 2022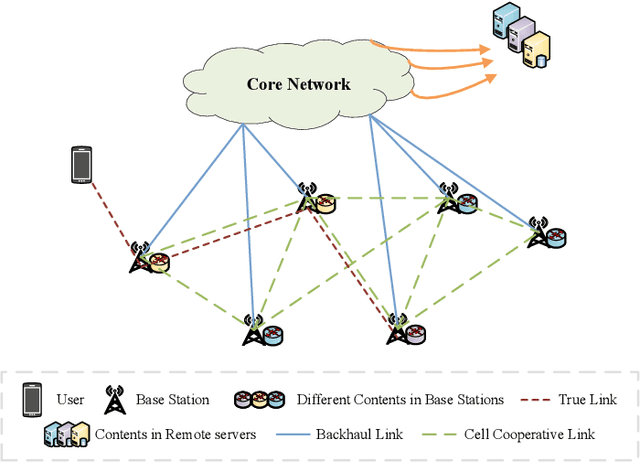
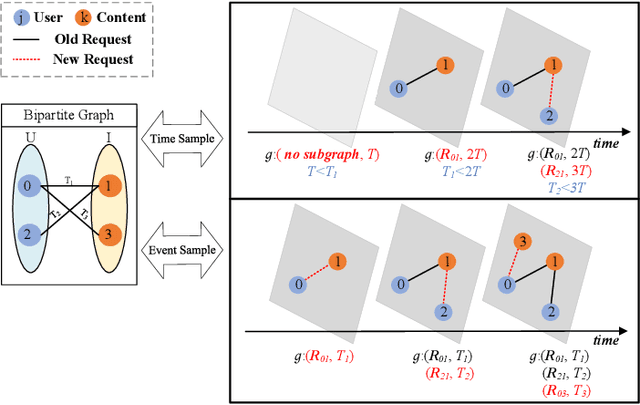
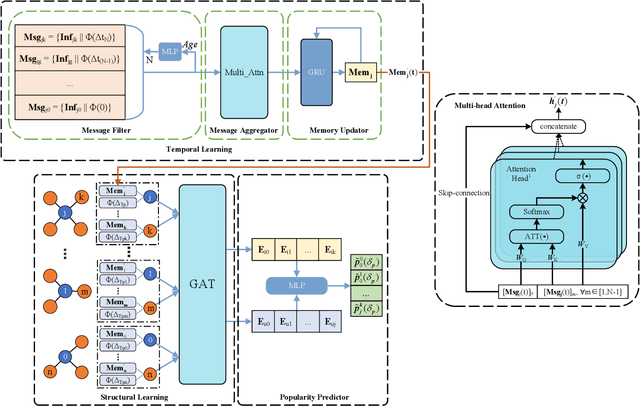
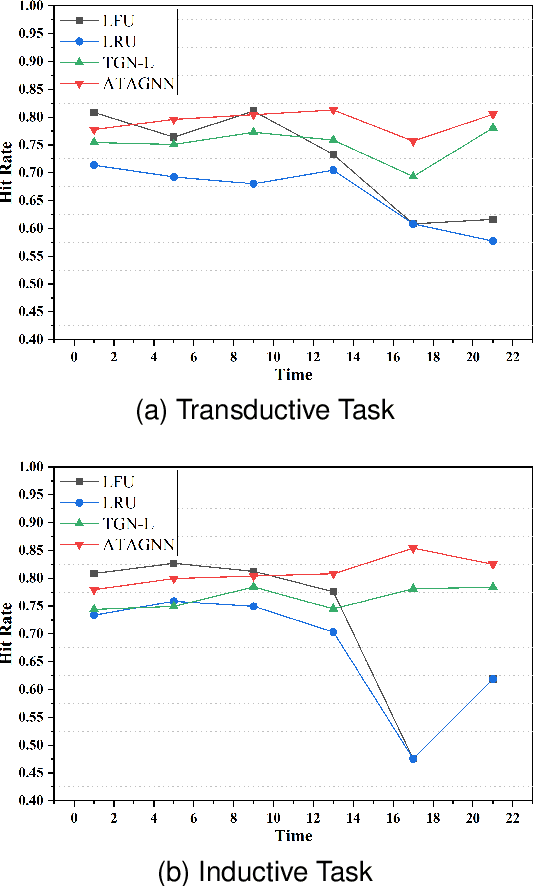
Along with the fast development of network technology and the rapid growth of network equipment, the data throughput is sharply increasing. To handle the problem of backhaul bottleneck in cellular network and satisfy people's requirements about latency, the network architecture like information-centric network (ICN) intends to proactively keep limited popular content at the edge of network based on predicted results. Meanwhile, the interactions between the content (e.g., deep neural network models, Wikipedia-alike knowledge base) and users could be regarded as a dynamic bipartite graph. In this paper, to maximize the cache hit rate, we leverage an effective dynamic graph neural network (DGNN) to jointly learn the structural and temporal patterns embedded in the bipartite graph. Furthermore, in order to have deeper insights into the dynamics within the evolving graph, we propose an age of information (AoI) based attention mechanism to extract valuable historical information while avoiding the problem of message staleness. Combining this aforementioned prediction model, we also develop a cache selection algorithm to make caching decisions in accordance with the prediction results. Extensive results demonstrate that our model can obtain a higher prediction accuracy than other state-of-the-art schemes in two real-world datasets. The results of hit rate further verify the superiority of the caching policy based on our proposed model over other traditional ways.
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022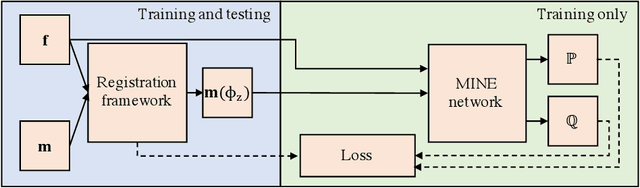
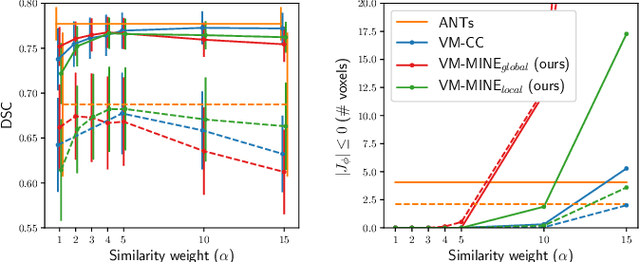
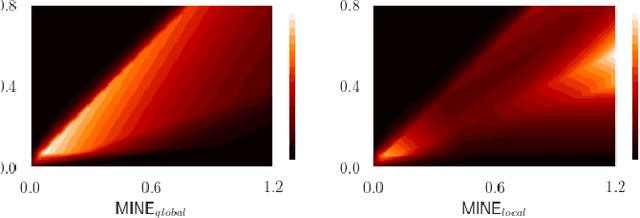
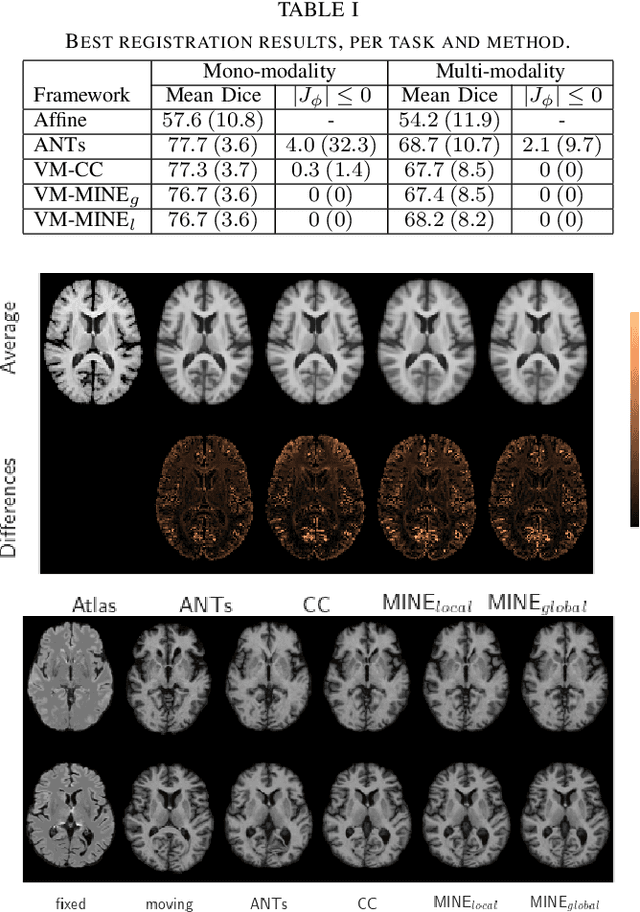
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Deep Learning for Wireless Networked Systems: a joint Estimation-Control-Scheduling Approach
Oct 03, 2022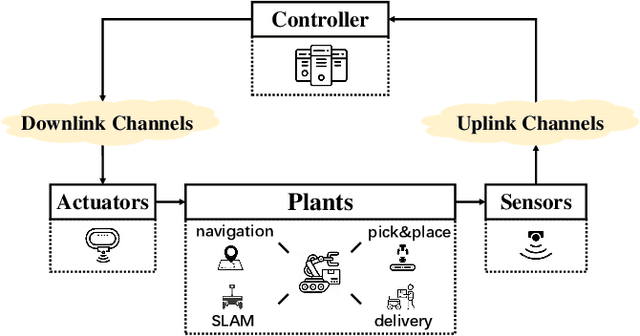
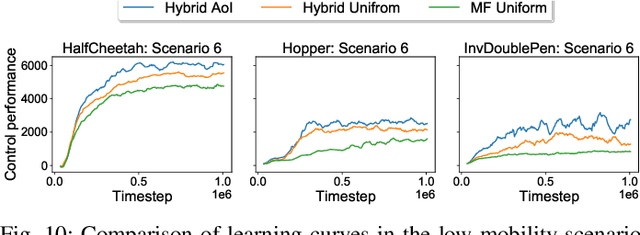
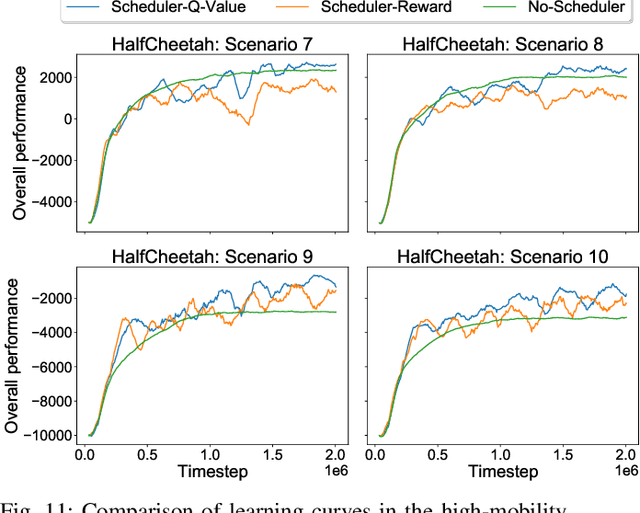
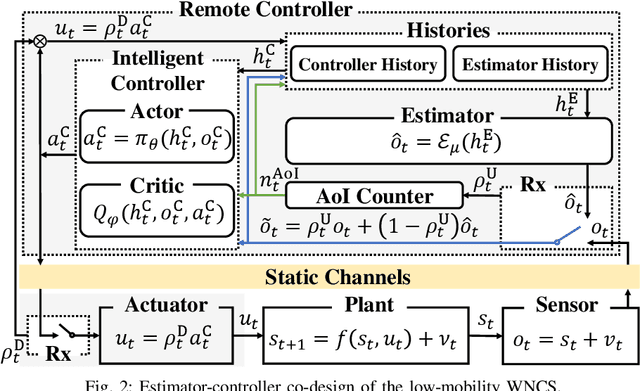
Wireless networked control system (WNCS) connecting sensors, controllers, and actuators via wireless communications is a key enabling technology for highly scalable and low-cost deployment of control systems in the Industry 4.0 era. Despite the tight interaction of control and communications in WNCSs, most existing works adopt separative design approaches. This is mainly because the co-design of control-communication policies requires large and hybrid state and action spaces, making the optimal problem mathematically intractable and difficult to be solved effectively by classic algorithms. In this paper, we systematically investigate deep learning (DL)-based estimator-control-scheduler co-design for a model-unknown nonlinear WNCS over wireless fading channels. In particular, we propose a co-design framework with the awareness of the sensor's age-of-information (AoI) states and dynamic channel states. We propose a novel deep reinforcement learning (DRL)-based algorithm for controller and scheduler optimization utilizing both model-free and model-based data. An AoI-based importance sampling algorithm that takes into account the data accuracy is proposed for enhancing learning efficiency. We also develop novel schemes for enhancing the stability of joint training. Extensive experiments demonstrate that the proposed joint training algorithm can effectively solve the estimation-control-scheduling co-design problem in various scenarios and provide significant performance gain compared to separative design and some benchmark policies.
Progressive Glass Segmentation
Sep 06, 2022



Glass is very common in the real world. Influenced by the uncertainty about the glass region and the varying complex scenes behind the glass, the existence of glass poses severe challenges to many computer vision tasks, making glass segmentation as an important computer vision task. Glass does not have its own visual appearances but only transmit/reflect the appearances of its surroundings, making it fundamentally different from other common objects. To address such a challenging task, existing methods typically explore and combine useful cues from different levels of features in the deep network. As there exists a characteristic gap between level-different features, i.e., deep layer features embed more high-level semantics and are better at locating the target objects while shallow layer features have larger spatial sizes and keep richer and more detailed low-level information, fusing these features naively thus would lead to a sub-optimal solution. In this paper, we approach the effective features fusion towards accurate glass segmentation in two steps. First, we attempt to bridge the characteristic gap between different levels of features by developing a Discriminability Enhancement (DE) module which enables level-specific features to be a more discriminative representation, alleviating the features incompatibility for fusion. Second, we design a Focus-and-Exploration Based Fusion (FEBF) module to richly excavate useful information in the fusion process by highlighting the common and exploring the difference between level-different features.