 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identifying the exterior image of buildings on a 3D map and extracting elevation information using deep learning and digital image processing
Jan 04, 2022
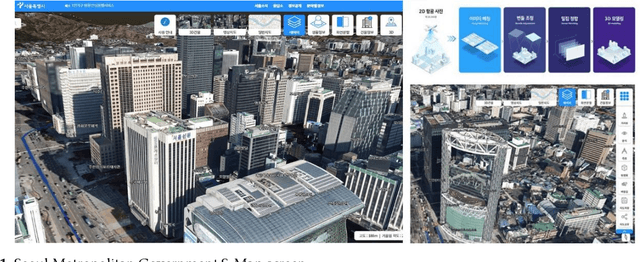


Despite the fact that architectural administration information in Korea has been providing high-quality information for a long period of time, the level of utility of the information is not high because it focuses on administrative information. While this is the case, a three-dimensional (3D) map with higher resolution has emerged along with the technological development. However, it cannot function better than visual transmission, as it includes only image information focusing on the exterior of the building. If information related to the exterior of the building can be extracted or identified from a 3D map, it is expected that the utility of the information will be more valuable as the national architectural administration information can then potentially be extended to include such information regarding the building exteriors to the level of BIM(Building Information Modeling). This study aims to present and assess a basic method of extracting information related to the appearance of the exterior of a building for the purpose of 3D mapping using deep learning and digital image processing. After extracting and preprocessing images from the map, information was identified using the Fast R-CNN(Regions with Convolutional Neuron Networks) model. The information was identified using the Faster R-CNN model after extracting and preprocessing images from the map. As a result, it showed approximately 93% and 91% accuracy in terms of detecting the elevation and window parts of the building, respectively, as well as excellent performance in an experiment aimed at extracting the elevation information of the building. Nonetheless, it is expected that improved results will be obtained by supplementing the probability of mixing the false detection rate or noise data caused by the misunderstanding of experimenters in relation to the unclear boundaries of windows.
Entailment Semantics Can Be Extracted from an Ideal Language Model
Sep 26, 2022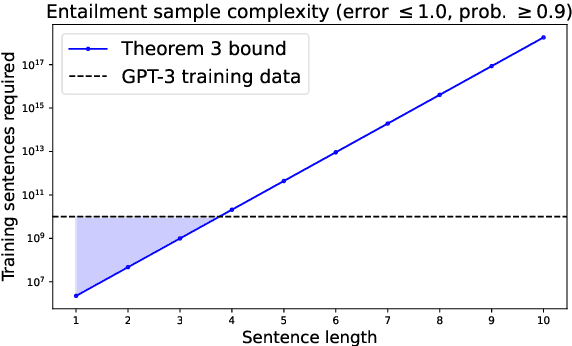
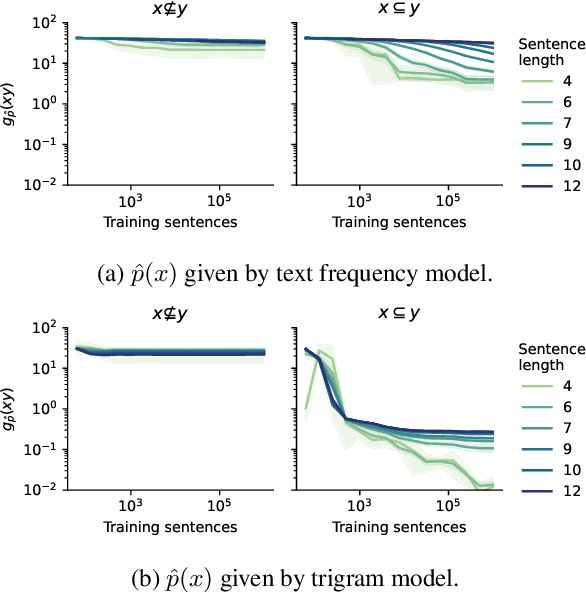
Language models are often trained on text alone, without additional grounding. There is debate as to how much of natural language semantics can be inferred from such a procedure. We prove that entailment judgments between sentences can be extracted from an ideal language model that has perfectly learned its target distribution, assuming the training sentences are generated by Gricean agents, i.e., agents who follow fundamental principles of communication from the linguistic theory of pragmatics. We also show entailment judgments can be decoded from the predictions of a language model trained on such Gricean data. Our results reveal a pathway for understanding the semantic information encoded in unlabeled linguistic data and a potential framework for extracting semantics from language models.
Scene Text Image Super-Resolution via Content Perceptual Loss and Criss-Cross Transformer Blocks
Oct 13, 2022

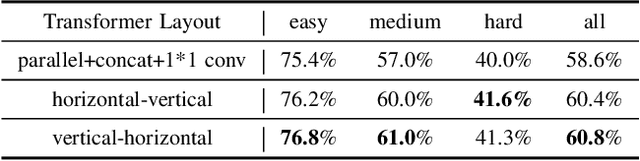

Text image super-resolution is a unique and important task to enhance readability of text images to humans. It is widely used as pre-processing in scene text recognition. However, due to the complex degradation in natural scenes, recovering high-resolution texts from the low-resolution inputs is ambiguous and challenging. Existing methods mainly leverage deep neural networks trained with pixel-wise losses designed for natural image reconstruction, which ignore the unique character characteristics of texts. A few works proposed content-based losses. However, they only focus on text recognizers' accuracy, while the reconstructed images may still be ambiguous to humans. Further, they often have weak generalizability to handle cross languages. To this end, we present TATSR, a Text-Aware Text Super-Resolution framework, which effectively learns the unique text characteristics using Criss-Cross Transformer Blocks (CCTBs) and a novel Content Perceptual (CP) Loss. The CCTB extracts vertical and horizontal content information from text images by two orthogonal transformers, respectively. The CP Loss supervises the text reconstruction with content semantics by multi-scale text recognition features, which effectively incorporates content awareness into the framework. Extensive experiments on various language datasets demonstrate that TATSR outperforms state-of-the-art methods in terms of both recognition accuracy and human perception.
Frustratingly Easy Sentiment Analysis of Text Streams: Generating High-Quality Emotion Arcs Using Emotion Lexicons
Oct 13, 2022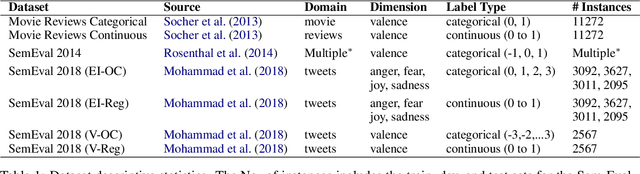
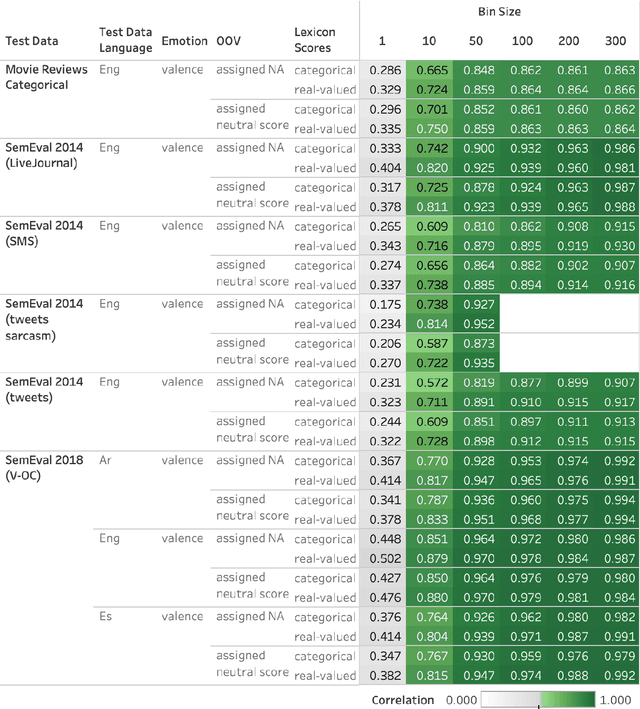

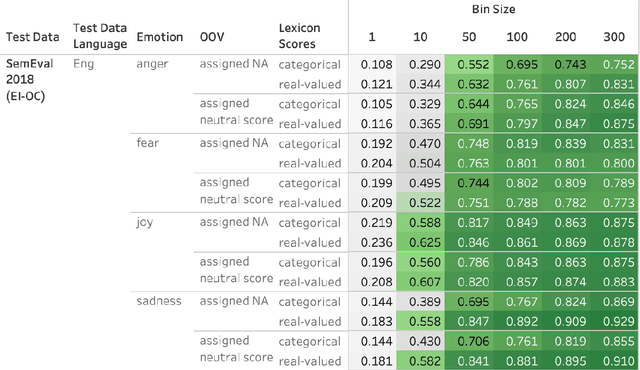
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs. This is in part due to the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. Using a number of diverse datasets, we systematically study the relationship between the quality of an emotion lexicon and the quality of the emotion arc that can be generated with it. We also study the relationship between the quality of an instance-level emotion detection system (say from an ML model) and the quality of emotion arcs that can be generated with it. We show that despite being markedly poor at instance level, LexO methods are highly accurate at generating emotion arcs by aggregating information from hundreds of instances. This has wide-spread implications for commercial development, as well as research in psychology, public health, digital humanities, etc. that values simple interpretable methods and disprefers the need for domain-specific training data, programming expertise, and high-carbon-footprint models.
Deep Gesture Generation for Social Robots Using Type-Specific Libraries
Oct 13, 2022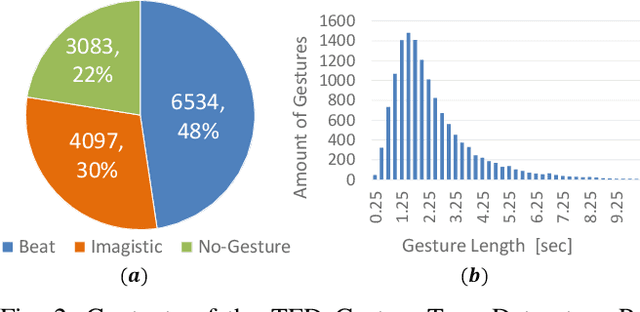
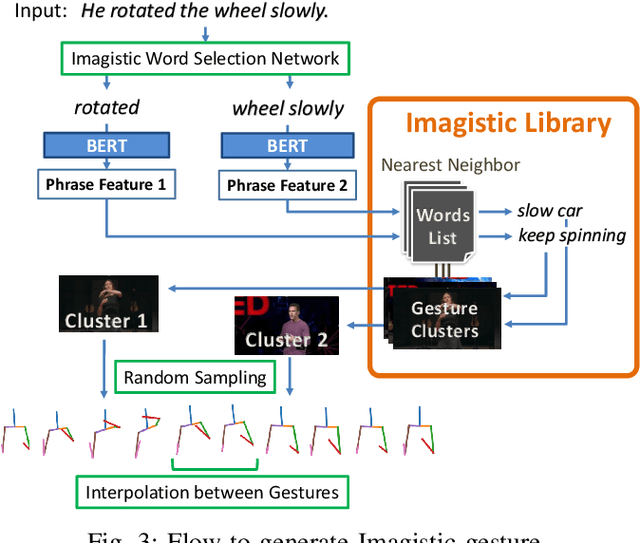
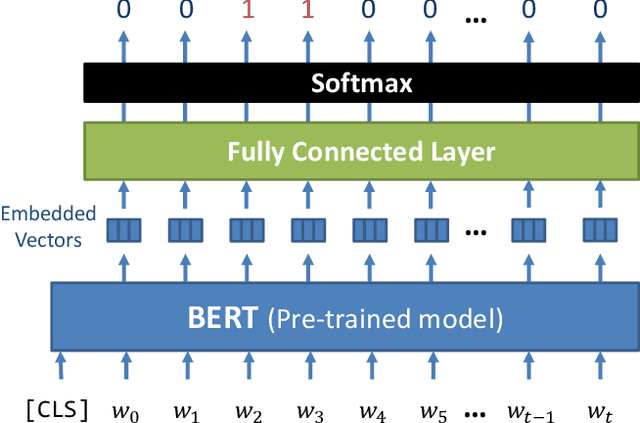
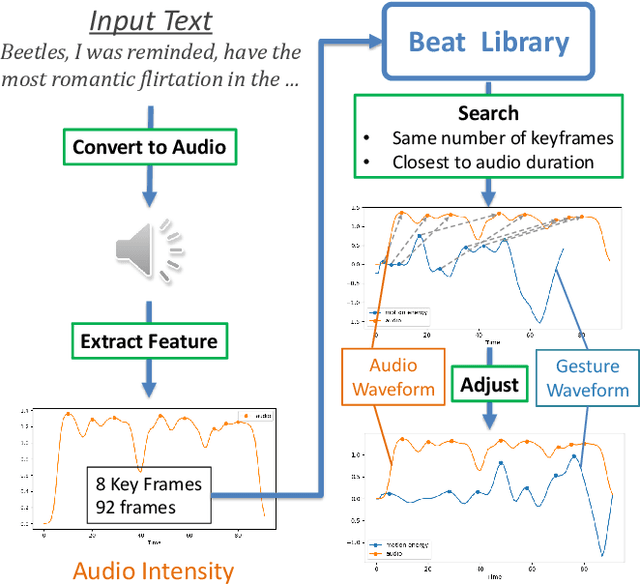
Body language such as conversational gesture is a powerful way to ease communication. Conversational gestures do not only make a speech more lively but also contain semantic meaning that helps to stress important information in the discussion. In the field of robotics, giving conversational agents (humanoid robots or virtual avatars) the ability to properly use gestures is critical, yet remain a task of extraordinary difficulty. This is because given only a text as input, there are many possibilities and ambiguities to generate an appropriate gesture. Different to previous works we propose a new method that explicitly takes into account the gesture types to reduce these ambiguities and generate human-like conversational gestures. Key to our proposed system is a new gesture database built on the TED dataset that allows us to map a word to one of three types of gestures: "Imagistic" gestures, which express the content of the speech, "Beat" gestures, which emphasize words, and "No gestures." We propose a system that first maps the words in the input text to their corresponding gesture type, generate type-specific gestures and combine the generated gestures into one final smooth gesture. In our comparative experiments, the effectiveness of the proposed method was confirmed in user studies for both avatar and humanoid robot.
Marginalized particle Gibbs for multiple state-space models coupled through shared parameters
Oct 13, 2022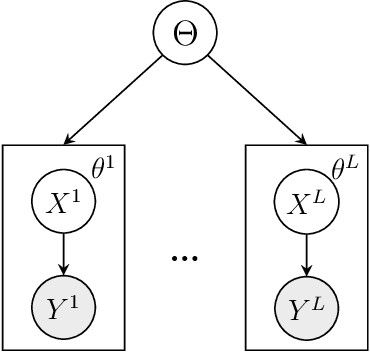
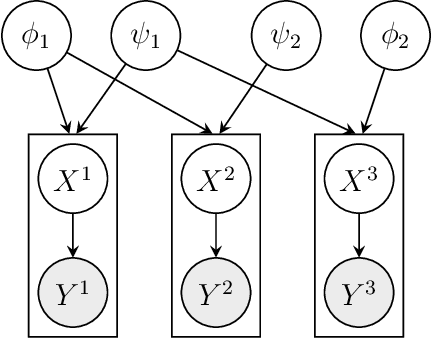
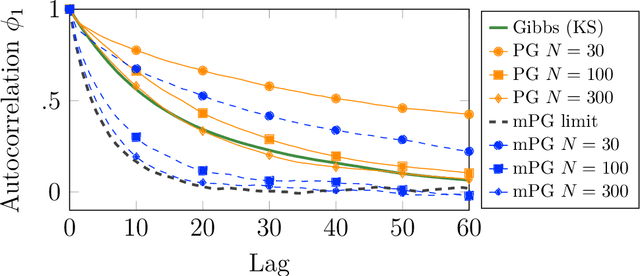
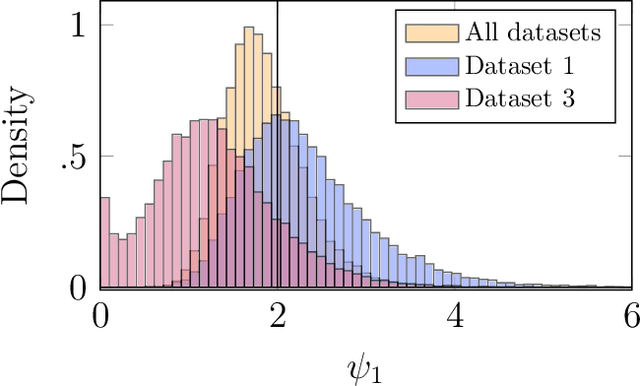
We consider Bayesian inference from multiple time series described by a common state-space model (SSM) structure, but where different subsets of parameters are shared between different submodels. An important example is disease-dynamics, where parameters can be either disease or location specific. Parameter inference in these models can be improved by systematically aggregating information from the different time series, most notably for short series. Particle Gibbs (PG) samplers are an efficient class of algorithms for inference in SSMs, in particular when conjugacy can be exploited to marginalize out model parameters from the state update. We present two different PG samplers that marginalize static model parameters on-the-fly: one that updates one model at a time conditioned on the datasets for the other models, and one that concurrently updates all models by stacking them into a high-dimensional SSM. The distinctive features of each sampler make them suitable for different modelling contexts. We provide insights on when each sampler should be used and show that they can be combined to form an efficient PG sampler for a model with strong dependencies between states and parameters. The performance is illustrated on two linear-Gaussian examples and on a real-world example on the spread of mosquito-borne diseases.
Closed-book Question Generation via Contrastive Learning
Oct 13, 2022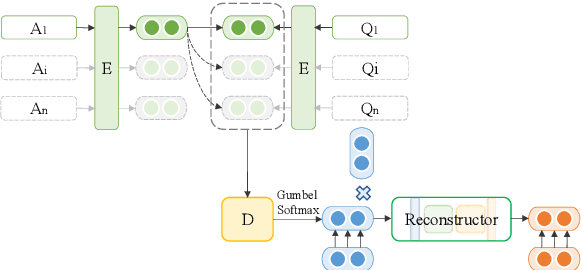

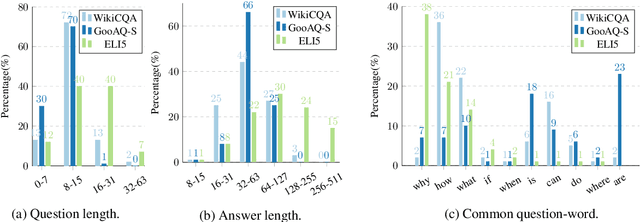
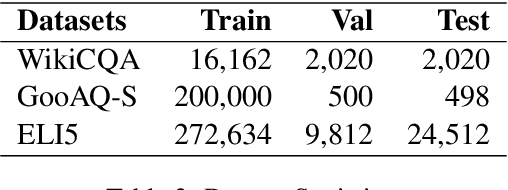
Question Generation (QG) is a fundamental NLP task for many downstream applications. Recent studies on open-book QG, where supportive question-context pairs are provided to models, have achieved promising progress. However, generating natural questions under a more practical closed-book setting that lacks these supporting documents still remains a challenge. In this work, to learn better representations from semantic information hidden in question-answer pairs under the closed-book setting, we propose a new QG model empowered by a contrastive learning module and an answer reconstruction module. We present a new closed-book QA dataset -- WikiCQA involving abstractive long answers collected from a wiki-style website. In the experiments, we validate the proposed QG model on both public datasets and the new WikiCQA dataset. Empirical results show that the proposed QG model outperforms baselines in both automatic evaluation and human evaluation. In addition, we show how to leverage the proposed model to improve existing closed-book QA systems. We observe that by pre-training a closed-book QA model on our generated synthetic QA pairs, significant QA improvement can be achieved on both seen and unseen datasets, which further demonstrates the effectiveness of our QG model for enhancing unsupervised and semi-supervised QA.
Sliding Window Recurrent Network for Efficient Video Super-Resolution
Aug 24, 2022


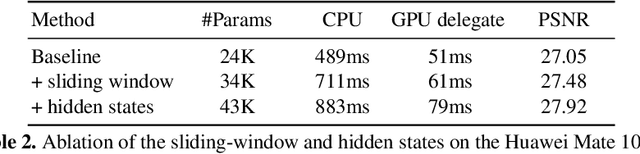
Video super-resolution (VSR) is the task of restoring high-resolution frames from a sequence of low-resolution inputs. Different from single image super-resolution, VSR can utilize frames' temporal information to reconstruct results with more details. Recently, with the rapid development of convolution neural networks (CNN), the VSR task has drawn increasing attention and many CNN-based methods have achieved remarkable results. However, only a few VSR approaches can be applied to real-world mobile devices due to the computational resources and runtime limitations. In this paper, we propose a \textit{Sliding Window based Recurrent Network} (SWRN) which can be real-time inference while still achieving superior performance. Specifically, we notice that video frames should have both spatial and temporal relations that can help to recover details, and the key point is how to extract and aggregate information. Address it, we input three neighboring frames and utilize a hidden state to recurrently store and update the important temporal information. Our experiment on REDS dataset shows that the proposed method can be well adapted to mobile devices and produce visually pleasant results.
Toward Improving Health Literacy in Patient Education Materials with Neural Machine Translation Models
Sep 14, 2022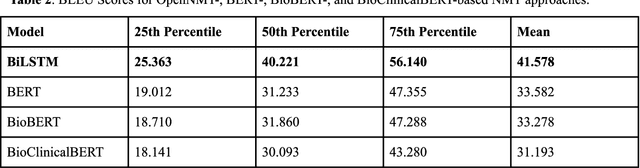
Health literacy is the central focus of Healthy People 2030, the fifth iteration of the U.S. national goals and objectives. People with low health literacy usually have trouble understanding health information, following post-visit instructions, and using prescriptions, which results in worse health outcomes and serious health disparities. In this study, we propose to leverage natural language processing techniques to improve health literacy in patient education materials by automatically translating illiterate languages in a given sentence. We scraped patient education materials from four online health information websites: MedlinePlus.gov, Drugs.com, Mayoclinic.org and Reddit.com. We trained and tested the state-of-the-art neural machine translation (NMT) models on a silver standard training dataset and a gold standard testing dataset, respectively. The experimental results showed that the Bidirectional Long Short-Term Memory (BiLSTM) NMT model outperformed Bidirectional Encoder Representations from Transformers (BERT)-based NMT models. We also verified the effectiveness of NMT models in translating health illiterate languages by comparing the ratio of health illiterate language in the sentence. The proposed NMT models were able to identify the correct complicated words and simplify into layman language while at the same time the models suffer from sentence completeness, fluency, readability, and have difficulty in translating certain medical terms.
On the Average Mutual Information of MIMO Keyhole Channels with Finite Inputs
Dec 08, 2021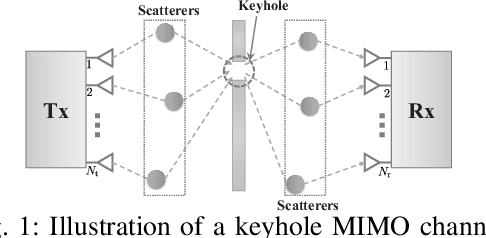
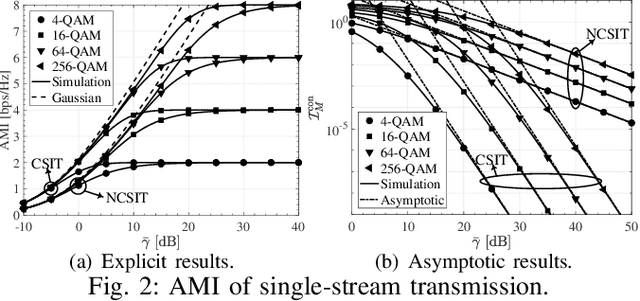
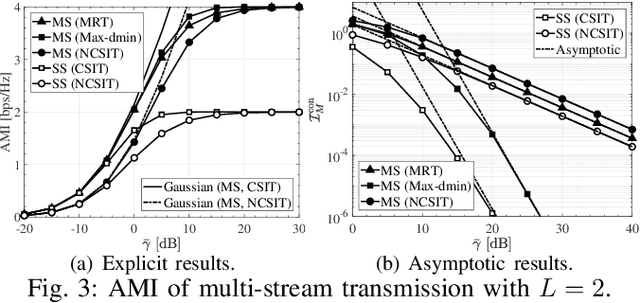
This letter studies the average mutual information (AMI) of keyhole multiple-input multiple-output (MIMO) systems having finite input signals. At first, the AMI of single-stream transmission is investigated under two cases where the state information at the transmitter (CSIT) is available or not. Then, the derived results are further extended to the case of multi-stream transmission. For the sake of providing more system insights, asymptotic analyses are performed in the regime of high signal-to-noise ratio (SNR), which suggests that the high-SNR AMI converges to some constant with its rate of convergence determined by the diversity order. All the results are validated by numerical simulations and are in excellent agreement.