 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbeSDF: Light Field Probes for Neural Surface Reconstruction
Dec 13, 2024



SDF-based differential rendering frameworks have achieved state-of-the-art multiview 3D shape reconstruction. In this work, we re-examine this family of approaches by minimally reformulating its core appearance model in a way that simultaneously yields faster computation and increased performance. To this goal, we exhibit a physically-inspired minimal radiance parametrization decoupling angular and spatial contributions, by encoding them with a small number of features stored in two respective volumetric grids of different resolutions. Requiring as little as four parameters per voxel, and a tiny MLP call inside a single fully fused kernel, our approach allows to enhance performance with both surface and image (PSNR) metrics, while providing a significant training speedup and real-time rendering. We show this performance to be consistently achieved on real data over two widely different and popular application fields, generic object and human subject shape reconstruction, using four representative and challenging datasets.
Neural Active Structure-from-Motion in Dark and Textureless Environment
Oct 20, 2024



Active 3D measurement, especially structured light (SL) has been widely used in various fields for its robustness against textureless or equivalent surfaces by low light illumination. In addition, reconstruction of large scenes by moving the SL system has become popular, however, there have been few practical techniques to obtain the system's precise pose information only from images, since most conventional techniques are based on image features, which cannot be retrieved under textureless environments. In this paper, we propose a simultaneous shape reconstruction and pose estimation technique for SL systems from an image set where sparsely projected patterns onto the scene are observed (i.e. no scene texture information), which we call Active SfM. To achieve this, we propose a full optimization framework of the volumetric shape that employs neural signed distance fields (Neural-SDF) for SL with the goal of not only reconstructing the scene shape but also estimating the poses for each motion of the system. Experimental results show that the proposed method is able to achieve accurate shape reconstruction as well as pose estimation from images where only projected patterns are observed.
ActiveNeuS: Neural Signed Distance Fields for Active Stereo
Oct 20, 2024



3D-shape reconstruction in extreme environments, such as low illumination or scattering condition, has been an open problem and intensively researched. Active stereo is one of potential solution for such environments for its robustness and high accuracy. However, active stereo systems usually consist of specialized system configurations with complicated algorithms, which narrow their application. In this paper, we propose Neural Signed Distance Field for active stereo systems to enable implicit correspondence search and triangulation in generalized Structured Light. With our technique, textureless or equivalent surfaces by low light condition are successfully reconstructed even with a small number of captured images. Experiments were conducted to confirm that the proposed method could achieve state-of-the-art reconstruction quality under such severe condition. We also demonstrated that the proposed method worked in an underwater scenario.
VortSDF: 3D Modeling with Centroidal Voronoi Tesselation on Signed Distance Field
Jul 29, 2024Volumetric shape representations have become ubiquitous in multi-view reconstruction tasks. They often build on regular voxel grids as discrete representations of 3D shape functions, such as SDF or radiance fields, either as the full shape model or as sampled instantiations of continuous representations, as with neural networks. Despite their proven efficiency, voxel representations come with the precision versus complexity trade-off. This inherent limitation can significantly impact performance when moving away from simple and uncluttered scenes. In this paper we investigate an alternative discretization strategy with the Centroidal Voronoi Tesselation (CVT). CVTs allow to better partition the observation space with respect to shape occupancy and to focus the discretization around shape surfaces. To leverage this discretization strategy for multi-view reconstruction, we introduce a volumetric optimization framework that combines explicit SDF fields with a shallow color network, in order to estimate 3D shape properties over tetrahedral grids. Experimental results with Chamfer statistics validate this approach with unprecedented reconstruction quality on various scenarios such as objects, open scenes or human.
Weakly-Supervised 3D Reconstruction of Clothed Humans via Normal Maps
Nov 27, 2023



We present a novel deep learning-based approach to the 3D reconstruction of clothed humans using weak supervision via 2D normal maps. Given a single RGB image or multiview images, our network infers a signed distance function (SDF) discretized on a tetrahedral mesh surrounding the body in a rest pose. Subsequently, inferred pose and camera parameters are used to generate a normal map from the SDF. A key aspect of our approach is the use of Marching Tetrahedra to (uniquely) compute a triangulated surface from the SDF on the tetrahedral mesh, facilitating straightforward differentiation (and thus backpropagation). Thus, given only ground truth normal maps (with no volumetric information ground truth information), we can train the network to produce SDF values from corresponding RGB images. Optionally, an additional multiview loss leads to improved results. We demonstrate the efficacy of our approach for both network inference and 3D reconstruction.
Toward unlabeled multi-view 3D pedestrian detection by generalizable AI: techniques and performance analysis
Aug 08, 2023



We unveil how generalizable AI can be used to improve multi-view 3D pedestrian detection in unlabeled target scenes. One way to increase generalization to new scenes is to automatically label target data, which can then be used for training a detector model. In this context, we investigate two approaches for automatically labeling target data: pseudo-labeling using a supervised detector and automatic labeling using an untrained detector (that can be applied out of the box without any training). We adopt a training framework for optimizing detector models using automatic labeling procedures. This framework encompasses different training sets/modes and multi-round automatic labeling strategies. We conduct our analyses on the publicly-available WILDTRACK and MultiviewX datasets. We show that, by using the automatic labeling approach based on an untrained detector, we can obtain superior results than directly using the untrained detector or a detector trained with an existing labeled source dataset. It achieved a MODA about 4% and 1% better than the best existing unlabeled method when using WILDTRACK and MultiviewX as target datasets, respectively.
Deep Gesture Generation for Social Robots Using Type-Specific Libraries
Oct 13, 2022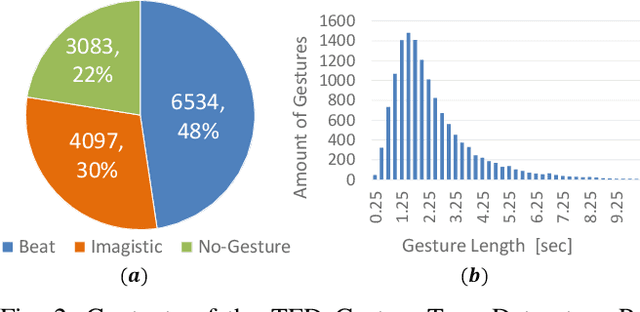
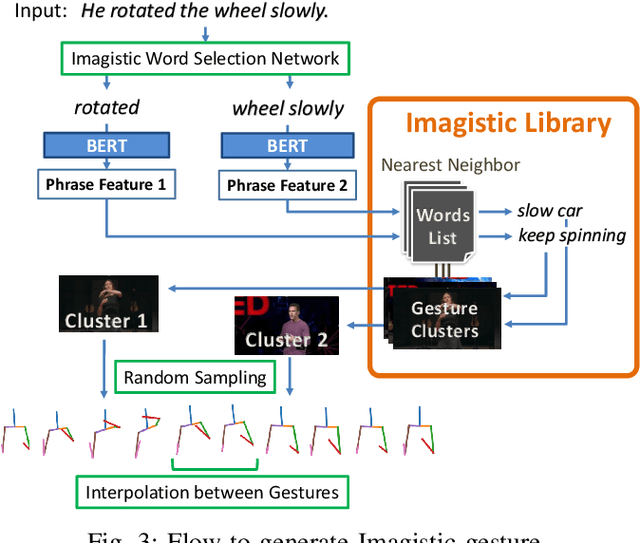
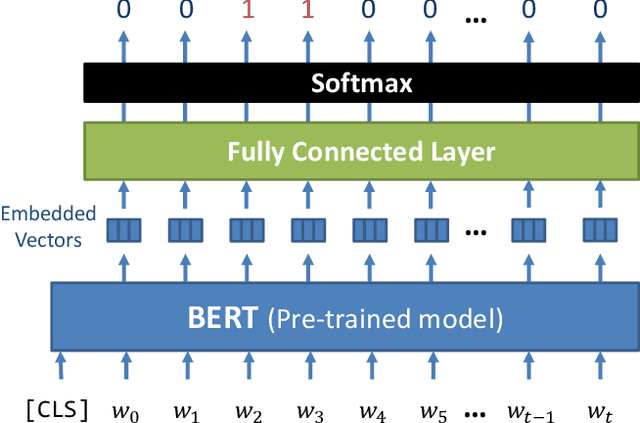
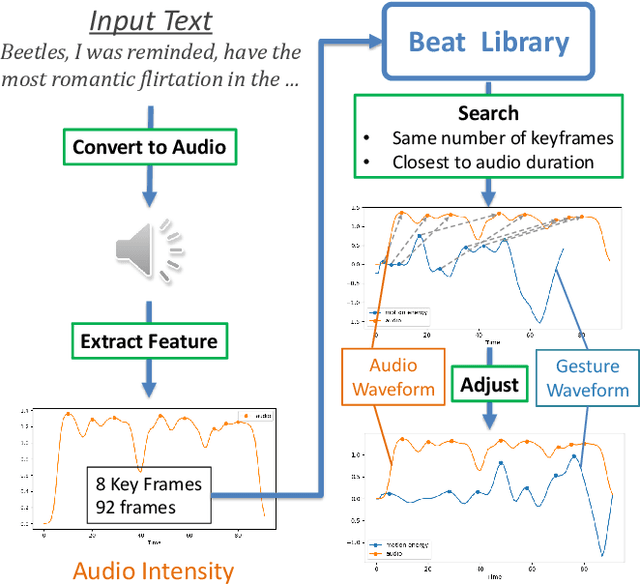
Body language such as conversational gesture is a powerful way to ease communication. Conversational gestures do not only make a speech more lively but also contain semantic meaning that helps to stress important information in the discussion. In the field of robotics, giving conversational agents (humanoid robots or virtual avatars) the ability to properly use gestures is critical, yet remain a task of extraordinary difficulty. This is because given only a text as input, there are many possibilities and ambiguities to generate an appropriate gesture. Different to previous works we propose a new method that explicitly takes into account the gesture types to reduce these ambiguities and generate human-like conversational gestures. Key to our proposed system is a new gesture database built on the TED dataset that allows us to map a word to one of three types of gestures: "Imagistic" gestures, which express the content of the speech, "Beat" gestures, which emphasize words, and "No gestures." We propose a system that first maps the words in the input text to their corresponding gesture type, generate type-specific gestures and combine the generated gestures into one final smooth gesture. In our comparative experiments, the effectiveness of the proposed method was confirmed in user studies for both avatar and humanoid robot.
PoseRN: A 2D pose refinement network for bias-free multi-view 3D human pose estimation
Jul 07, 2021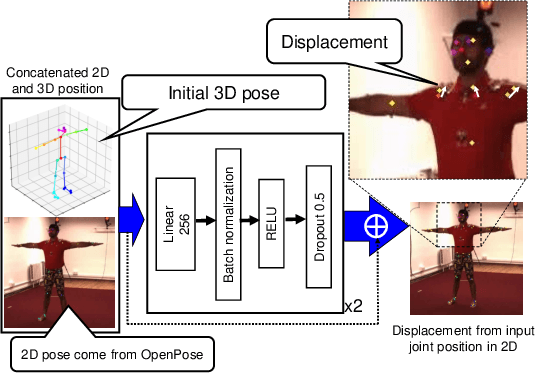
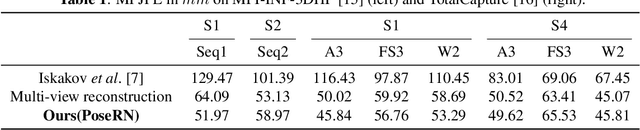
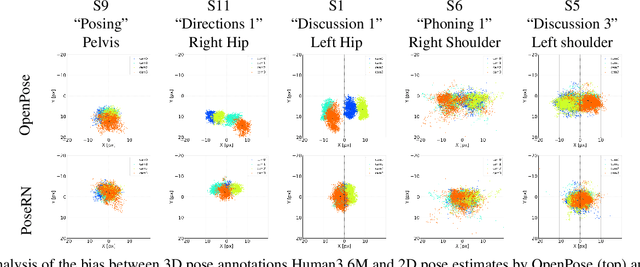

We propose a new 2D pose refinement network that learns to predict the human bias in the estimated 2D pose. There are biases in 2D pose estimations that are due to differences between annotations of 2D joint locations based on annotators' perception and those defined by motion capture (MoCap) systems. These biases are crafted into publicly available 2D pose datasets and cannot be removed with existing error reduction approaches. Our proposed pose refinement network allows us to efficiently remove the human bias in the estimated 2D poses and achieve highly accurate multi-view 3D human pose estimation.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
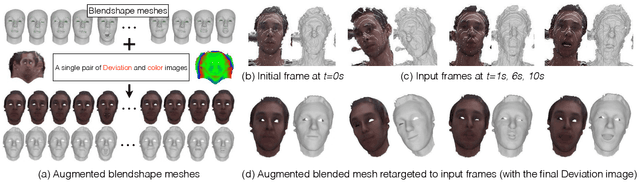

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.
TetraTSDF: 3D human reconstruction from a single image with a tetrahedral outer shell
Apr 22, 2020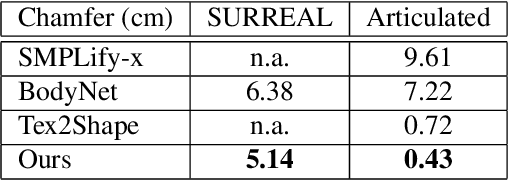
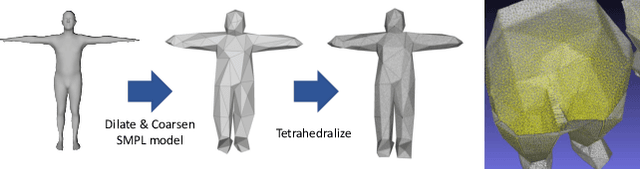

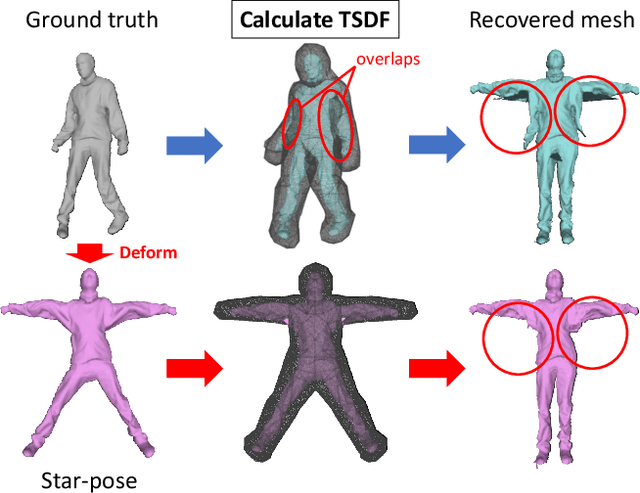
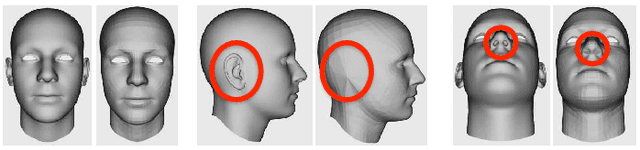
Recovering the 3D shape of a person from its 2D appearance is ill-posed due to ambiguities. Nevertheless, with the help of convolutional neural networks (CNN) and prior knowledge on the 3D human body, it is possible to overcome such ambiguities to recover detailed 3D shapes of human bodies from single images. Current solutions, however, fail to reconstruct all the details of a person wearing loose clothes. This is because of either (a) huge memory requirement that cannot be maintained even on modern GPUs or (b) the compact 3D representation that cannot encode all the details. In this paper, we propose the tetrahedral outer shell volumetric truncated signed distance function (TetraTSDF) model for the human body, and its corresponding part connection network (PCN) for 3D human body shape regression. Our proposed model is compact, dense, accurate, and yet well suited for CNN-based regression task. Our proposed PCN allows us to learn the distribution of the TSDF in the tetrahedral volume from a single image in an end-to-end manner. Results show that our proposed method allows to reconstruct detailed shapes of humans wearing loose clothes from single RGB images.