 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Benchmarking Adversarial Patch Against Aerial Detection
Oct 30, 2022
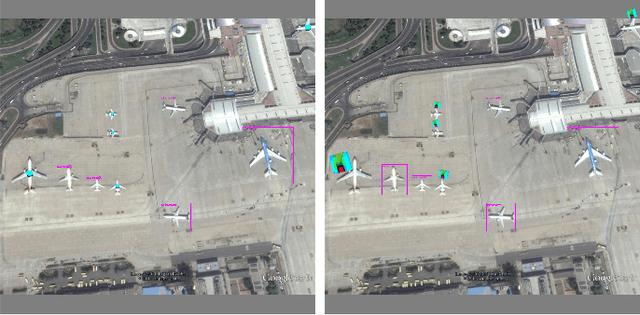
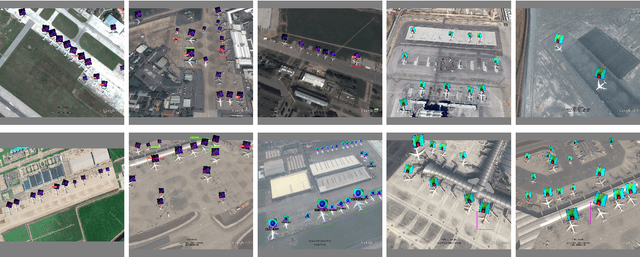


DNNs are vulnerable to adversarial examples, which poses great security concerns for security-critical systems. In this paper, a novel adaptive-patch-based physical attack (AP-PA) framework is proposed, which aims to generate adversarial patches that are adaptive in both physical dynamics and varying scales, and by which the particular targets can be hidden from being detected. Furthermore, the adversarial patch is also gifted with attack effectiveness against all targets of the same class with a patch outside the target (No need to smear targeted objects) and robust enough in the physical world. In addition, a new loss is devised to consider more available information of detected objects to optimize the adversarial patch, which can significantly improve the patch's attack efficacy (Average precision drop up to 87.86% and 85.48% in white-box and black-box settings, respectively) and optimizing efficiency. We also establish one of the first comprehensive, coherent, and rigorous benchmarks to evaluate the attack efficacy of adversarial patches on aerial detection tasks. Finally, several proportionally scaled experiments are performed physically to demonstrate that the elaborated adversarial patches can successfully deceive aerial detection algorithms in dynamic physical circumstances. The code is available at https://github.com/JiaweiLian/AP-PA.
token2vec: A Joint Self-Supervised Pre-training Framework Using Unpaired Speech and Text
Oct 30, 2022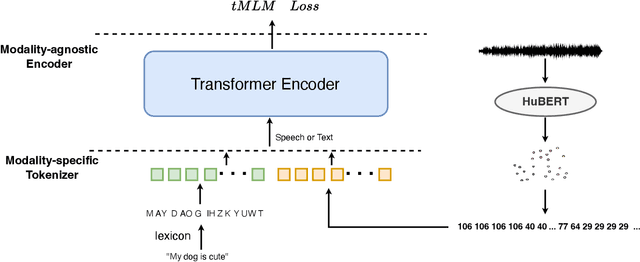
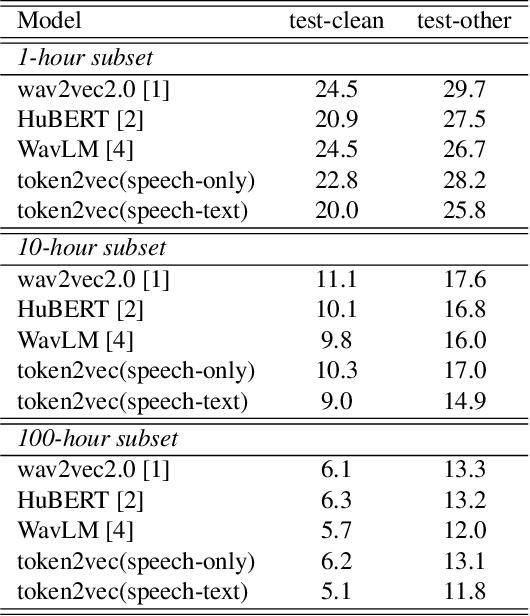
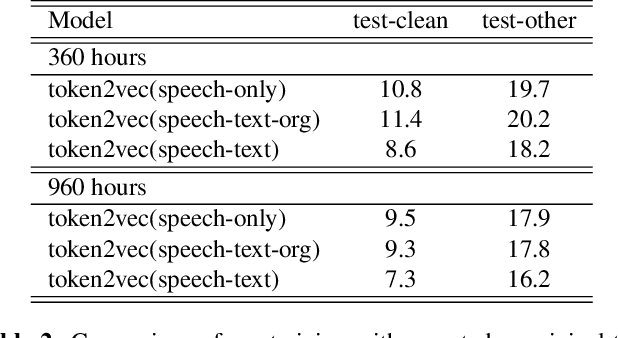
Self-supervised pre-training has been successful in both text and speech processing. Speech and text offer different but complementary information. The question is whether we are able to perform a speech-text joint pre-training on unpaired speech and text. In this paper, we take the idea of self-supervised pre-training one step further and propose token2vec, a novel joint pre-training framework for unpaired speech and text based on discrete representations of speech. Firstly, due to the distinct characteristics between speech and text modalities, where speech is continuous while text is discrete, we first discretize speech into a sequence of discrete speech tokens to solve the modality mismatch problem. Secondly, to solve the length mismatch problem, where the speech sequence is usually much longer than text sequence, we convert the words of text into phoneme sequences and randomly repeat each phoneme in the sequences. Finally, we feed the discrete speech and text tokens into a modality-agnostic Transformer encoder and pre-train with token-level masking language modeling (tMLM). Experiments show that token2vec is significantly superior to various speech-only pre-training baselines, with up to 17.7% relative WER reduction. Token2vec model is also validated on a non-ASR task, i.e., spoken intent classification, and shows good transferability.
Online Convex Optimization with Long Term Constraints for Predictable Sequences
Oct 30, 2022In this paper, we investigate the framework of Online Convex Optimization (OCO) for online learning. OCO offers a very powerful online learning framework for many applications. In this context, we study a specific framework of OCO called {\it OCO with long term constraints}. Long term constraints are introduced typically as an alternative to reduce the complexity of the projection at every update step in online optimization. While many algorithmic advances have been made towards online optimization with long term constraints, these algorithms typically assume that the sequence of cost functions over a certain $T$ finite steps that determine the cost to the online learner are adversarially generated. In many circumstances, the sequence of cost functions may not be unrelated, and thus predictable from those observed till a point of time. In this paper, we study the setting where the sequences are predictable. We present a novel online optimization algorithm for online optimization with long term constraints that can leverage such predictability. We show that, with a predictor that can supply the gradient information of the next function in the sequence, our algorithm can achieve an overall regret and constraint violation rate that is strictly less than the rate that is achievable without prediction.
Min-Max Latency Optimization Based on Sensed Position State Information in Internet of Vehicles
Mar 19, 2022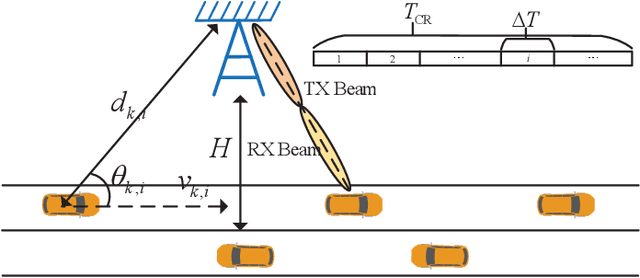
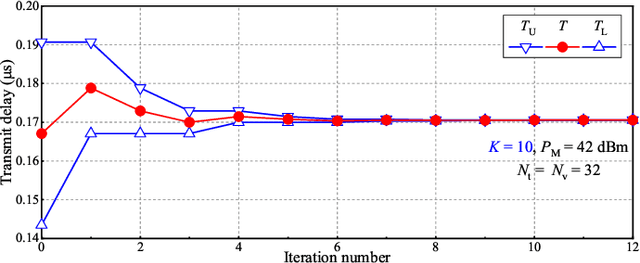
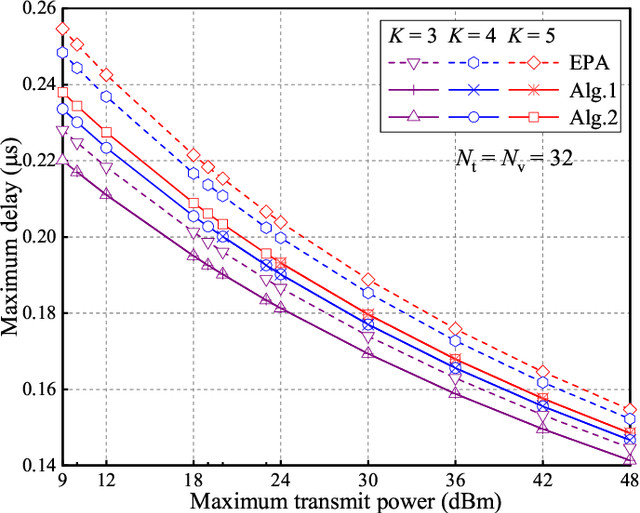
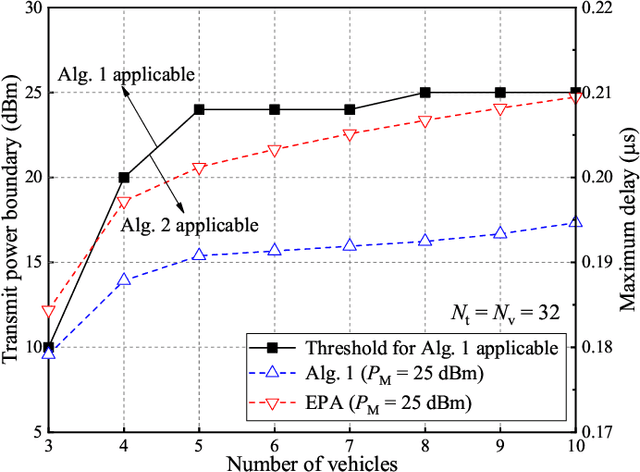
The dual-function radar communication (DFRC) is an essential technology in Internet of Vehicles (IoV). Consider that the road-side unit (RSU) employs the DFRC signals to sense the vehicles' position state information (PSI), and communicates with the vehicles based on PSI. The objective of this paper is to minimize the maximum communication delay among all vehicles by considering the estimation accuracy constraint of the vehicles' PSI and the transmit power constraint of RSU. By leveraging convex optimization theory, two iterative power allocation algorithms are proposed with different complexities and applicable scenarios. Simulation results indicate that the proposed power allocation algorithm converges and can significantly reduce the maximum transmit delay among vehicles compared with other schemes.
A two-stage approach for table extraction in invoices
Oct 10, 2022
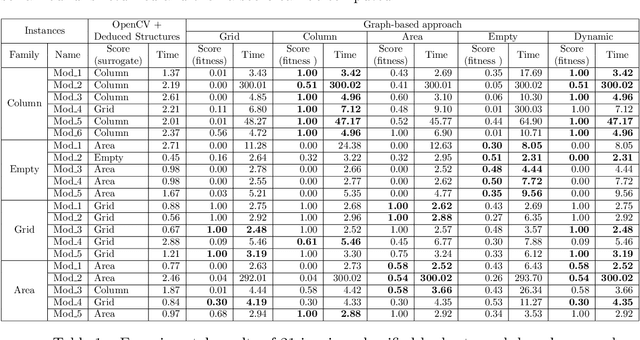
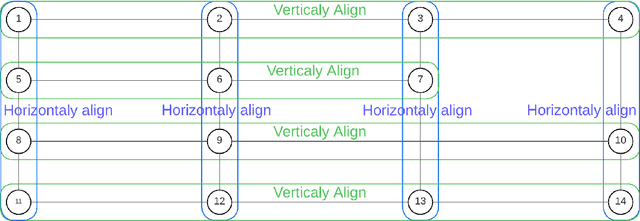
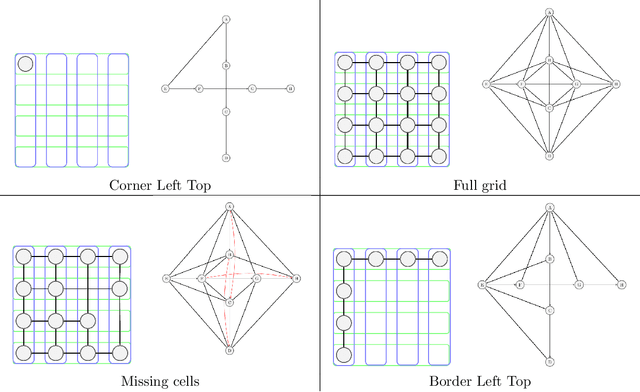
The automated analysis of administrative documents is an important field in document recognition that is studied for decades. Invoices are key documents among these huge amounts of documents available in companies and public services. Invoices contain most of the time data that are presented in tables that should be clearly identified to extract suitable information. In this paper, we propose an approach that combines an image processing based estimation of the shape of the tables with a graph-based representation of the document, which is used to identify complex tables precisely. We propose an experimental evaluation using a real case application.
Focusing on Context is NICE: Improving Overshadowed Entity Disambiguation
Oct 12, 2022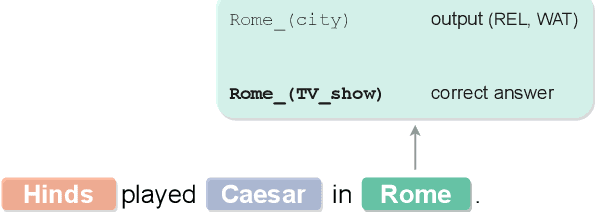
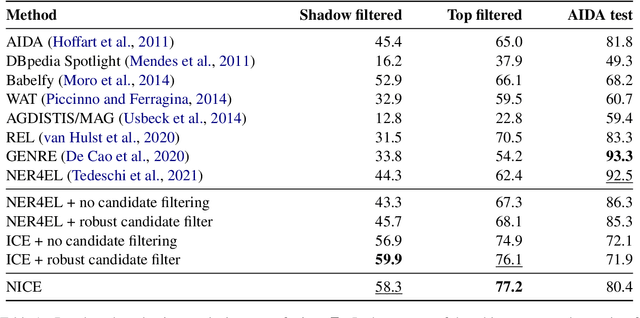
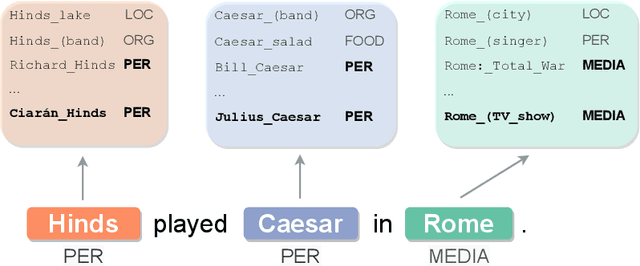
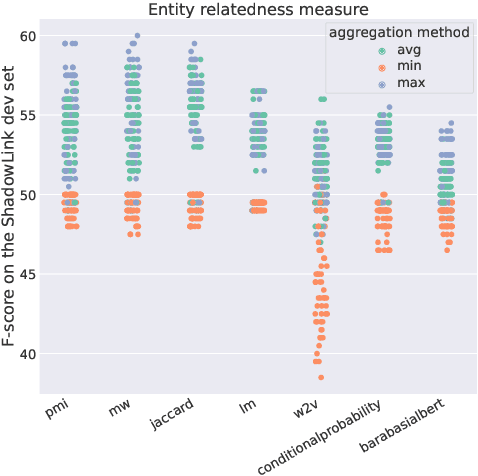
Entity disambiguation (ED) is the task of mapping an ambiguous entity mention to the corresponding entry in a structured knowledge base. Previous research showed that entity overshadowing is a significant challenge for existing ED models: when presented with an ambiguous entity mention, the models are much more likely to rank a more frequent yet less contextually relevant entity at the top. Here, we present NICE, an iterative approach that uses entity type information to leverage context and avoid over-relying on the frequency-based prior. Our experiments show that NICE achieves the best performance results on the overshadowed entities while still performing competitively on the frequent entities.
Useful Confidence Measures: Beyond the Max Score
Oct 25, 2022


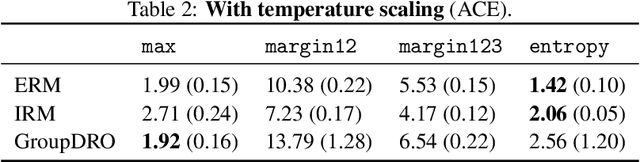
An important component in deploying machine learning (ML) in safety-critic applications is having a reliable measure of confidence in the ML model's predictions. For a classifier $f$ producing a probability vector $f(x)$ over the candidate classes, the confidence is typically taken to be $\max_i f(x)_i$. This approach is potentially limited, as it disregards the rest of the probability vector. In this work, we derive several confidence measures that depend on information beyond the maximum score, such as margin-based and entropy-based measures, and empirically evaluate their usefulness, focusing on NLP tasks with distribution shifts and Transformer-based models. We show that when models are evaluated on the out-of-distribution data ``out of the box'', using only the maximum score to inform the confidence measure is highly suboptimal. In the post-processing regime (where the scores of $f$ can be improved using additional in-distribution held-out data), this remains true, albeit less significant. Overall, our results suggest that entropy-based confidence is a surprisingly useful measure.
Topical Segmentation of Spoken Narratives: A Test Case on Holocaust Survivor Testimonies
Oct 25, 2022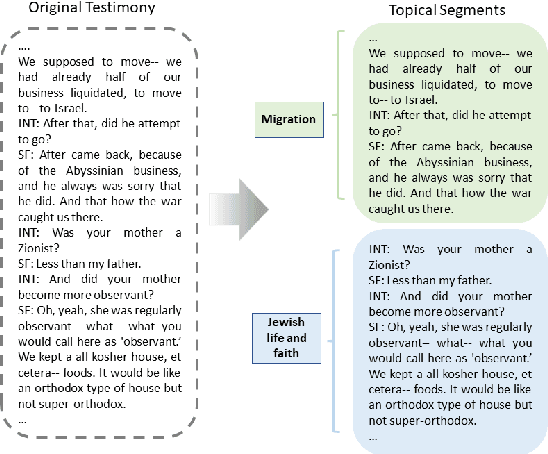
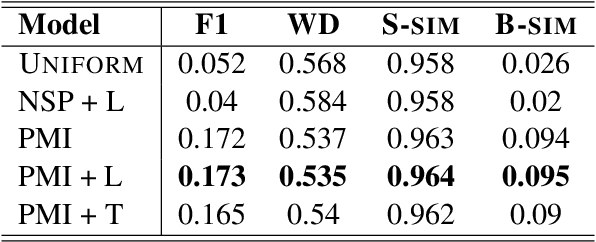
The task of topical segmentation is well studied, but previous work has mostly addressed it in the context of structured, well-defined segments, such as segmentation into paragraphs, chapters, or segmenting text that originated from multiple sources. We tackle the task of segmenting running (spoken) narratives, which poses hitherto unaddressed challenges. As a test case, we address Holocaust survivor testimonies, given in English. Other than the importance of studying these testimonies for Holocaust research, we argue that they provide an interesting test case for topical segmentation, due to their unstructured surface level, relative abundance (tens of thousands of such testimonies were collected), and the relatively confined domain that they cover. We hypothesize that boundary points between segments correspond to low mutual information between the sentences proceeding and following the boundary. Based on this hypothesis, we explore a range of algorithmic approaches to the task, building on previous work on segmentation that uses generative Bayesian modeling and state-of-the-art neural machinery. Compared to manually annotated references, we find that the developed approaches show considerable improvements over previous work.
LGDN: Language-Guided Denoising Network for Video-Language Modeling
Oct 03, 2022
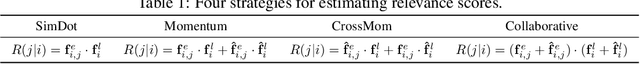
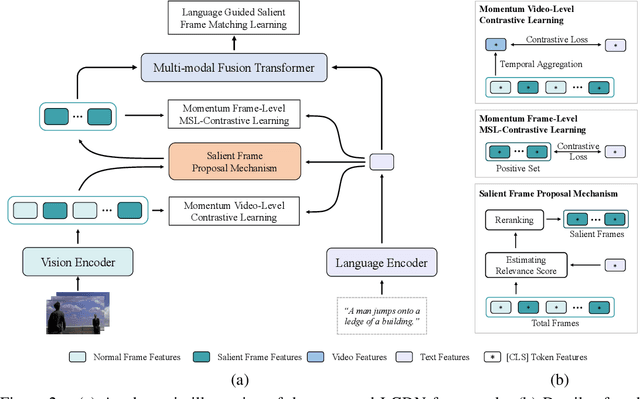
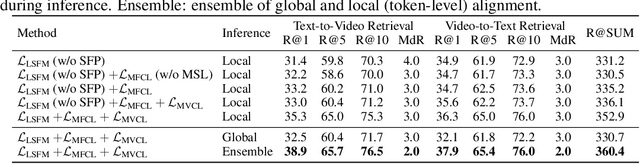
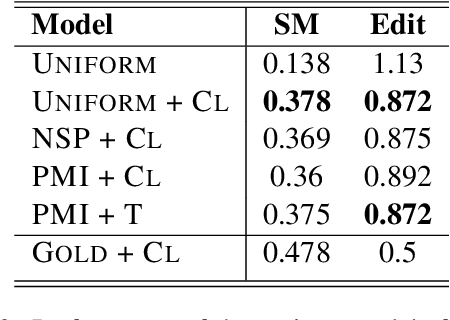
Video-language modeling has attracted much attention with the rapid growth of web videos. Most existing methods assume that the video frames and text description are semantically correlated, and focus on video-language modeling at video level. However, this hypothesis often fails for two reasons: (1) With the rich semantics of video contents, it is difficult to cover all frames with a single video-level description; (2) A raw video typically has noisy/meaningless information (e.g., scenery shot, transition or teaser). Although a number of recent works deploy attention mechanism to alleviate this problem, the irrelevant/noisy information still makes it very difficult to address. To overcome such challenge, we thus propose an efficient and effective model, termed Language-Guided Denoising Network (LGDN), for video-language modeling. Different from most existing methods that utilize all extracted video frames, LGDN dynamically filters out the misaligned or redundant frames under the language supervision and obtains only 2--4 salient frames per video for cross-modal token-level alignment. Extensive experiments on five public datasets show that our LGDN outperforms the state-of-the-arts by large margins. We also provide detailed ablation study to reveal the critical importance of solving the noise issue, in hope of inspiring future video-language work.
Nonstationary data stream classification with online active learning and siamese neural networks
Oct 03, 2022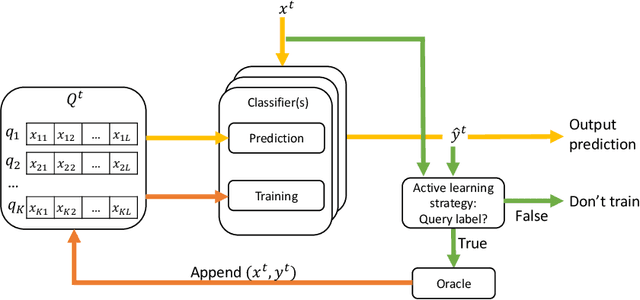
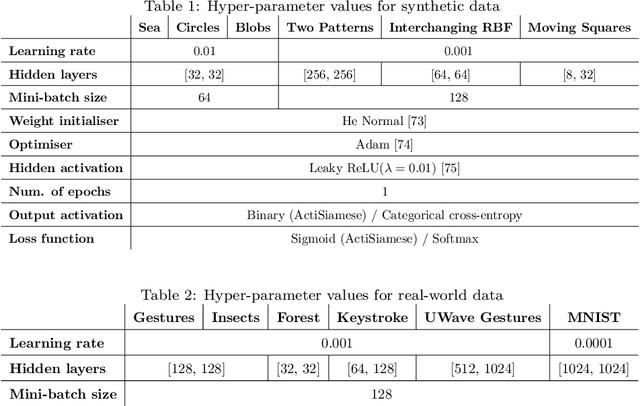
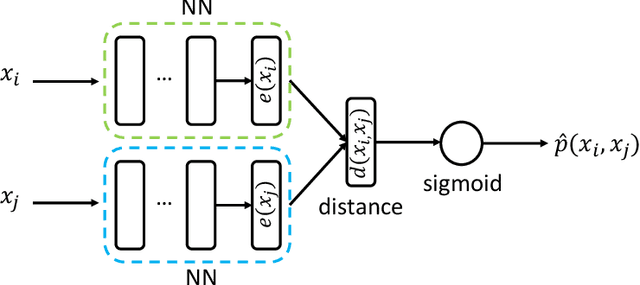
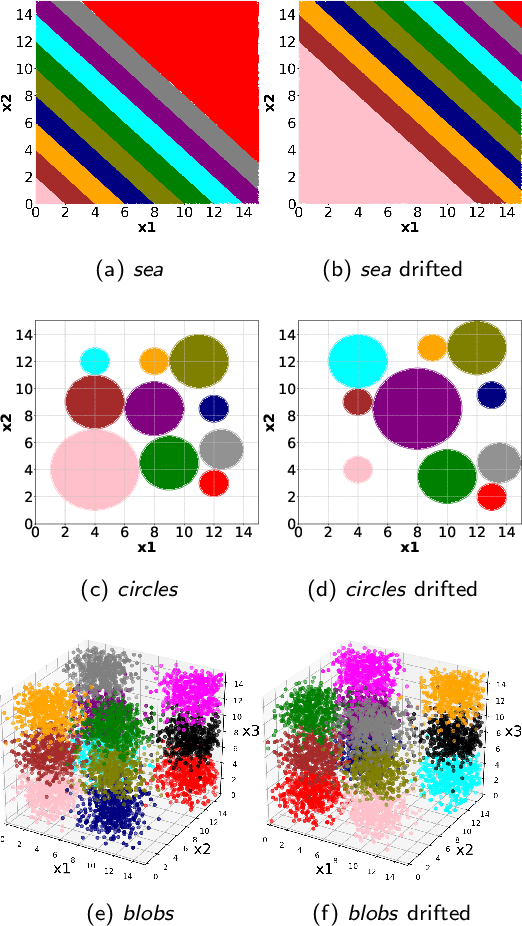
We have witnessed in recent years an ever-growing volume of information becoming available in a streaming manner in various application areas. As a result, there is an emerging need for online learning methods that train predictive models on-the-fly. A series of open challenges, however, hinder their deployment in practice. These are, learning as data arrive in real-time one-by-one, learning from data with limited ground truth information, learning from nonstationary data, and learning from severely imbalanced data, while occupying a limited amount of memory for data storage. We propose the ActiSiamese algorithm, which addresses these challenges by combining online active learning, siamese networks, and a multi-queue memory. It develops a new density-based active learning strategy which considers similarity in the latent (rather than the input) space. We conduct an extensive study that compares the role of different active learning budgets and strategies, the performance with/without memory, the performance with/without ensembling, in both synthetic and real-world datasets, under different data nonstationarity characteristics and class imbalance levels. ActiSiamese outperforms baseline and state-of-the-art algorithms, and is effective under severe imbalance, even only when a fraction of the arriving instances' labels is available. We publicly release our code to the community.
* Keywords: Incremental learning, Active learning, Data streams, Concept drift, Class imbalance