 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022
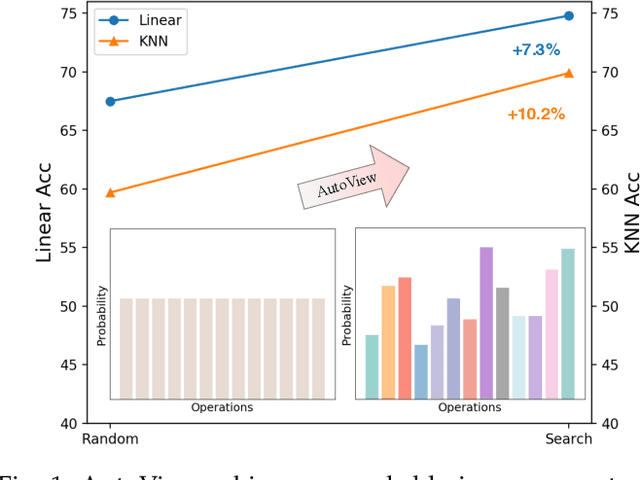
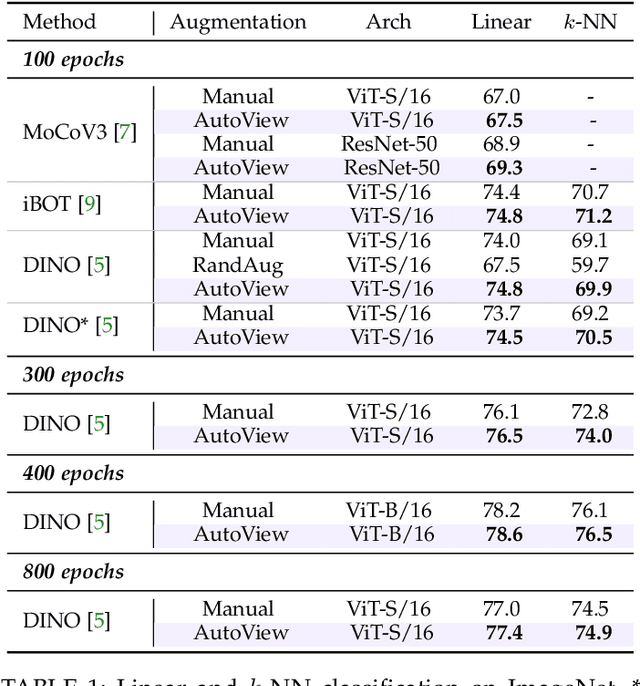
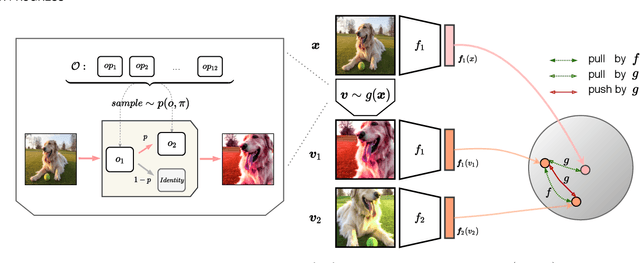

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
High-speed processing of X-ray wavefront marking data with the Unified Modulated Pattern Analysis (UMPA) model
Nov 02, 2022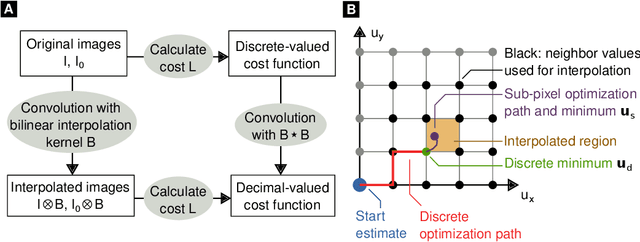

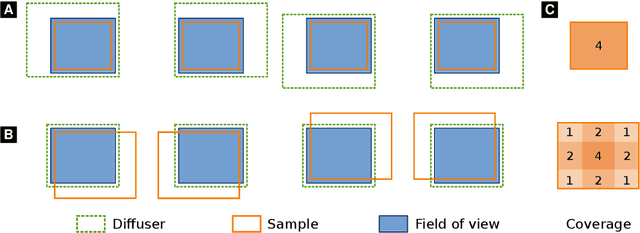

Wavefront-marking X-ray imaging techniques use e.g., sandpaper or a grating to generate intensity fluctuations, and analyze their distortion by the sample in order to retrieve attenuation, phase-contrast, and dark-field information. Phase contrast yields an improved visibility of soft-tissue specimens, while dark-field reveals small-angle scatter from sub-resolution structures. Both have found many biomedical and engineering applications. The previously developed Unified Modulated Pattern Analysis (UMPA) model extracts these modalities from wavefront-marking data. We here present a new UMPA implementation, capable of rapidly processing large datasets and featuring capabilities to greatly extend the field of view. We also discuss possible artifacts and additional new features.
Rethinking Batch Sample Relationships for Data Representation: A Batch-Graph Transformer based Approach
Nov 19, 2022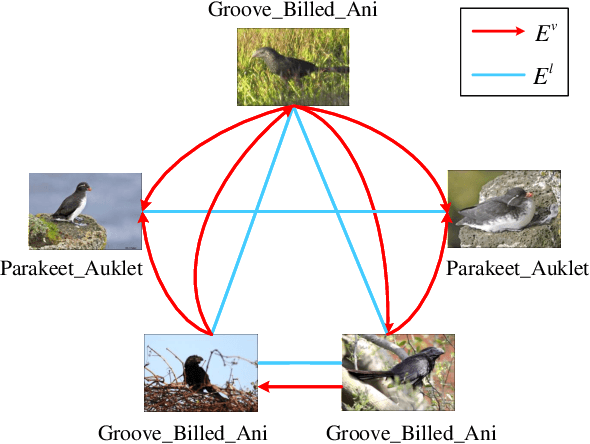
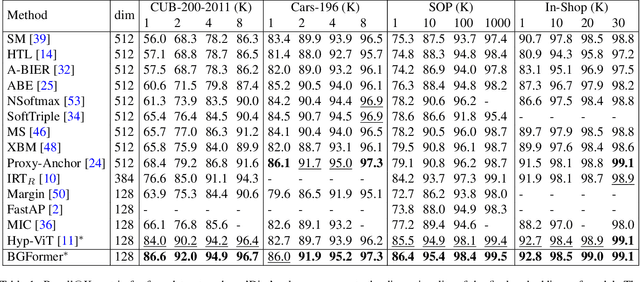
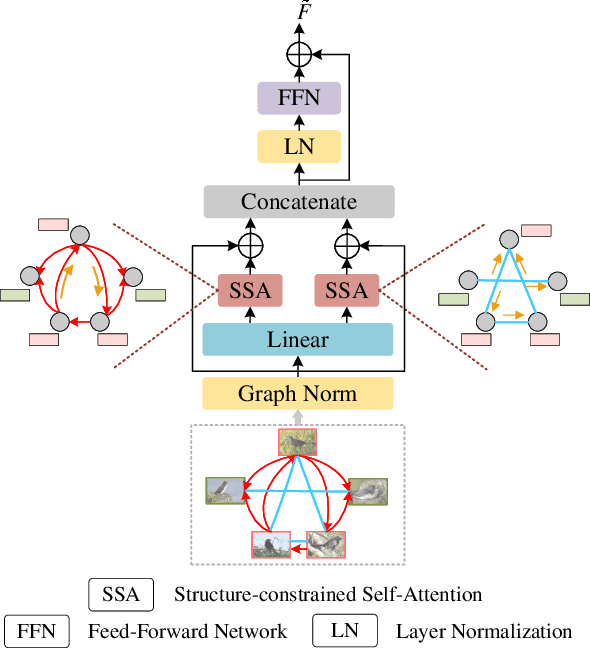
Exploring sample relationships within each mini-batch has shown great potential for learning image representations. Existing works generally adopt the regular Transformer to model the visual content relationships, ignoring the cues of semantic/label correlations between samples. Also, they generally adopt the "full" self-attention mechanism which are obviously redundant and also sensitive to the noisy samples. To overcome these issues, in this paper, we design a simple yet flexible Batch-Graph Transformer (BGFormer) for mini-batch sample representations by deeply capturing the relationships of image samples from both visual and semantic perspectives. BGFormer has three main aspects. (1) It employs a flexible graph model, termed Batch Graph to jointly encode the visual and semantic relationships of samples within each mini-batch. (2) It explores the neighborhood relationships of samples by borrowing the idea of sparse graph representation which thus performs robustly, w.r.t., noisy samples. (3) It devises a novel Transformer architecture that mainly adopts dual structure-constrained self-attention (SSA), together with graph normalization, FFN, etc, to carefully exploit the batch graph information for sample tokens (nodes) representations. As an application, we apply BGFormer to the metric learning tasks. Extensive experiments on four popular datasets demonstrate the effectiveness of the proposed model.
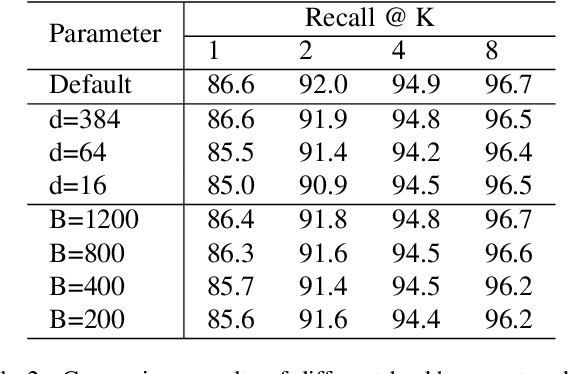
Simple and Effective Augmentation Methods for CSI Based Indoor Localization
Nov 19, 2022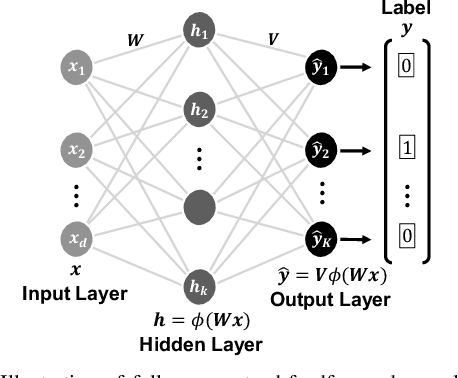
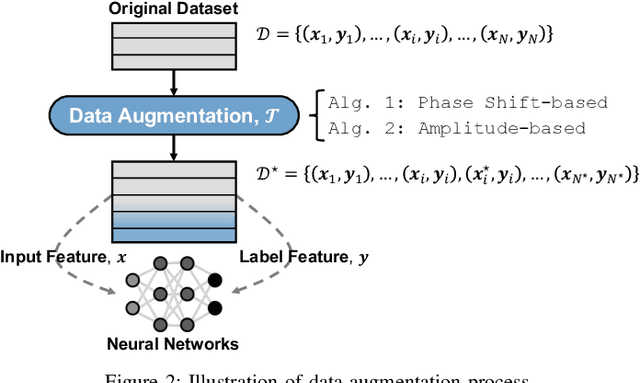
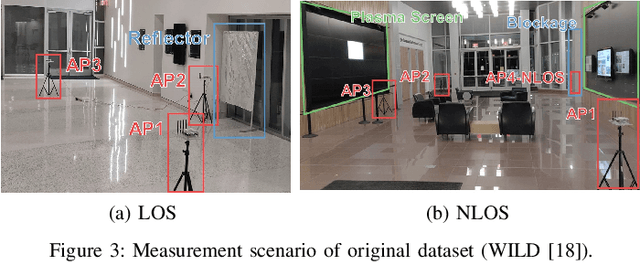

Indoor localization is a challenging task. There is no robust and almost-universal approach, in contrast to outdoor environments where GPS is dominant. Recently, machine learning (ML) has emerged as the most promising approach for achieving accurate indoor localization, yet its main challenge is the requirement for large datasets to train the neural networks. The data collection procedure is costly and laborious as the procedure requires extensive measurements and labeling processes for different indoor environments. The situation can be improved by Data Augmentation (DA), which is a general framework to enlarge the datasets for ML, making ML systems more robust and increases their generalization capabilities. In this paper, we propose two simple yet surprisingly effective DA algorithms for channel state information (CSI) based indoor localization motivated by physical considerations. We show that the required number of measurements for a given accuracy requirement may be decreased by an order of magnitude. Specifically, we demonstrate the algorithms' effectiveness by experiments conducted with a measured indoor WiFi measurement dataset: as little as 10% of the original dataset size is enough to get the same performance of the original dataset. We also showed that, if we further augment the dataset with proposed techniques we get better test accuracy more than three-fold.
convoHER2: A Deep Neural Network for Multi-Stage Classification of HER2 Breast Cancer
Nov 19, 2022
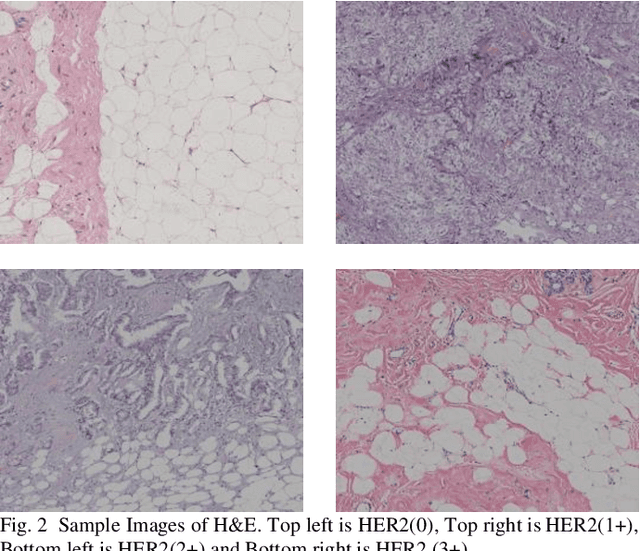
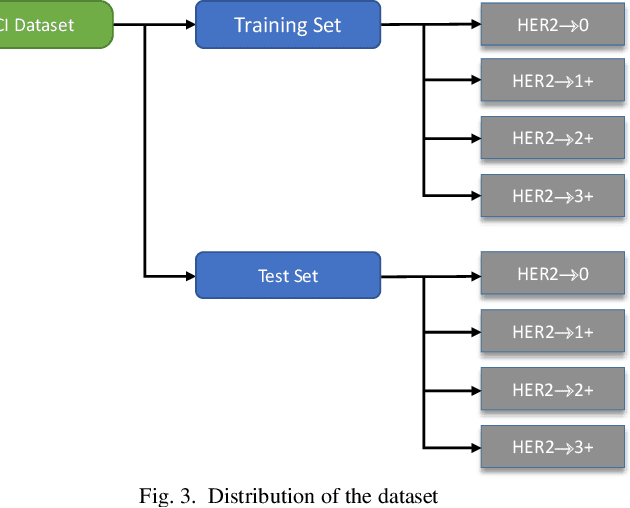
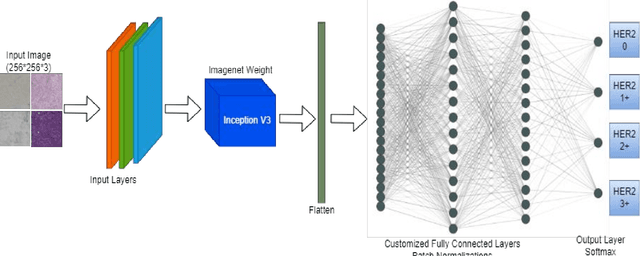
Generally, human epidermal growth factor 2 (HER2) breast cancer is more aggressive than other kinds of breast cancer. Currently, HER2 breast cancer is detected using expensive medical tests are most expensive. Therefore, the aim of this study was to develop a computational model named convoHER2 for detecting HER2 breast cancer with image data using convolution neural network (CNN). Hematoxylin and eosin (H&E) and immunohistochemical (IHC) stained images has been used as raw data from the Bayesian information criterion (BIC) benchmark dataset. This dataset consists of 4873 images of H&E and IHC. Among all images of the dataset, 3896 and 977 images are applied to train and test the convoHER2 model, respectively. As all the images are in high resolution, we resize them so that we can feed them in our convoHER2 model. The cancerous samples images are classified into four classes based on the stage of the cancer (0+, 1+, 2+, 3+). The convoHER2 model is able to detect HER2 cancer and its grade with accuracy 85% and 88% using H&E images and IHC images, respectively. The outcomes of this study determined that the HER2 cancer detecting rates of the convoHER2 model are much enough to provide better diagnosis to the patient for recovering their HER2 breast cancer in future.
Mutual Balancing in State-Object Components for Compositional Zero-Shot Learning
Nov 19, 2022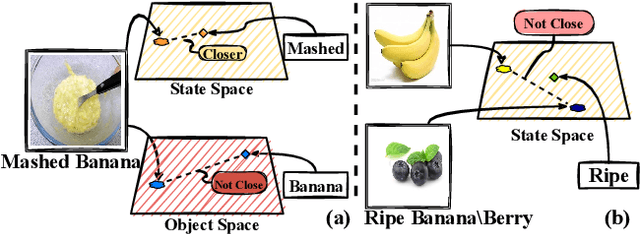
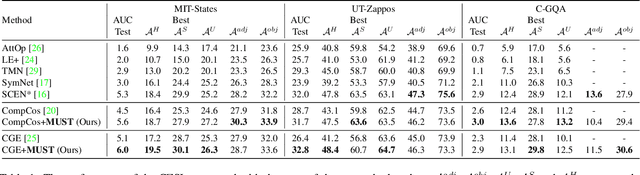
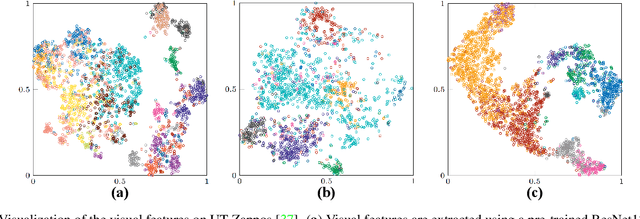
Compositional Zero-Shot Learning (CZSL) aims to recognize unseen compositions from seen states and objects. The disparity between the manually labeled semantic information and its actual visual features causes a significant imbalance of visual deviation in the distribution of various object classes and state classes, which is ignored by existing methods. To ameliorate these issues, we consider the CZSL task as an unbalanced multi-label classification task and propose a novel method called MUtual balancing in STate-object components (MUST) for CZSL, which provides a balancing inductive bias for the model. In particular, we split the classification of the composition classes into two consecutive processes to analyze the entanglement of the two components to get additional knowledge in advance, which reflects the degree of visual deviation between the two components. We use the knowledge gained to modify the model's training process in order to generate more distinct class borders for classes with significant visual deviations. Extensive experiments demonstrate that our approach significantly outperforms the state-of-the-art on MIT-States, UT-Zappos, and C-GQA when combined with the basic CZSL frameworks, and it can improve various CZSL frameworks. Our codes are available on https://anonymous.4open.science/r/MUST_CGE/.
Seq2Seq-SC: End-to-End Semantic Communication Systems with Pre-trained Language Model
Oct 27, 2022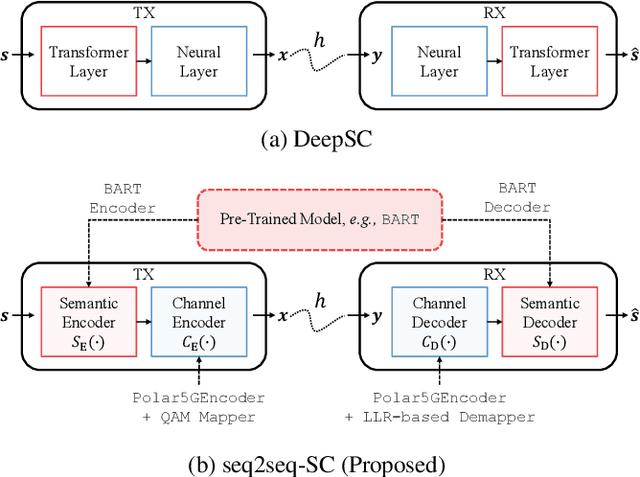
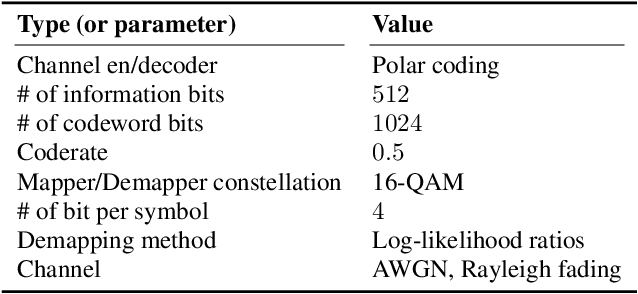
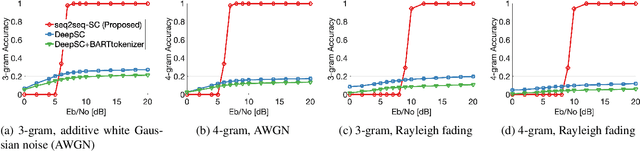

While semantic communication is expected to bring unprecedented communication efficiency in comparison to classical communication, many challenges must be resolved to realize its potential. In this work, we provide a realistic semantic network dubbed seq2seq-SC, which is compatible to 5G NR and can work with generalized text dataset utilizing pre-trained language model. We also utilize a performance metric (SBERT) which can accurately measure semantic similarity and show that seq2seq-SC achieves superior performance while extracting semantically meaningful information.
SMiLE: Schema-augmented Multi-level Contrastive Learning for Knowledge Graph Link Prediction
Oct 10, 2022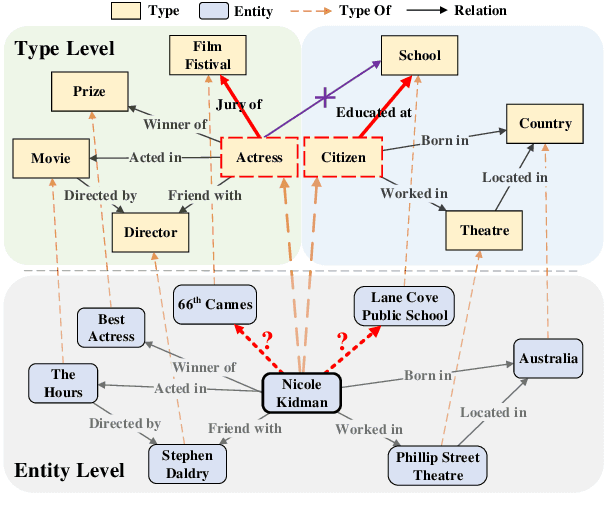
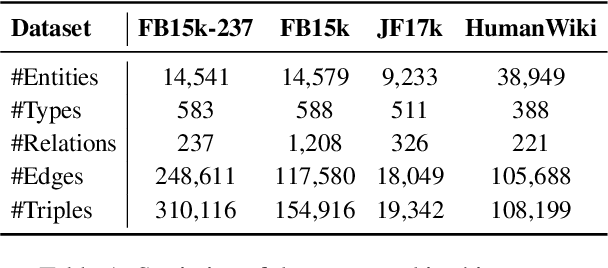
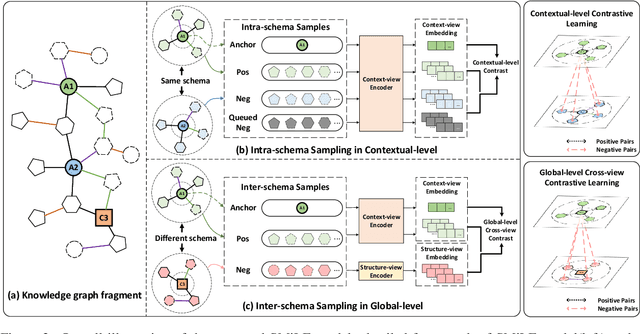
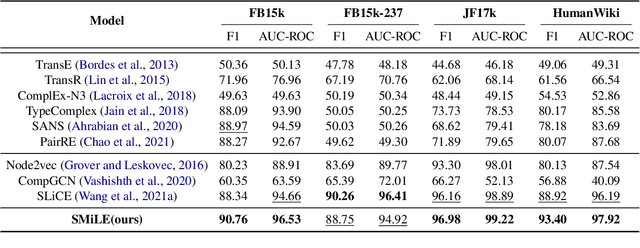
Link prediction is the task of inferring missing links between entities in knowledge graphs. Embedding-based methods have shown effectiveness in addressing this problem by modeling relational patterns in triples. However, the link prediction task often requires contextual information in entity neighborhoods, while most existing embedding-based methods fail to capture it. Additionally, little attention is paid to the diversity of entity representations in different contexts, which often leads to false prediction results. In this situation, we consider that the schema of knowledge graph contains the specific contextual information, and it is beneficial for preserving the consistency of entities across contexts. In this paper, we propose a novel schema-augmented multi-level contrastive learning framework (SMiLE) to conduct knowledge graph link prediction. Specifically, we first exploit network schema as the prior constraint to sample negatives and pre-train our model by employing a multi-level contrastive learning method to yield both prior schema and contextual information. Then we fine-tune our model under the supervision of individual triples to learn subtler representations for link prediction. Extensive experimental results on four knowledge graph datasets with thorough analysis of each component demonstrate the effectiveness of our proposed framework against state-of-the-art baselines.
Social Media Personal Event Notifier Using NLP and Machine Learning
Oct 10, 2022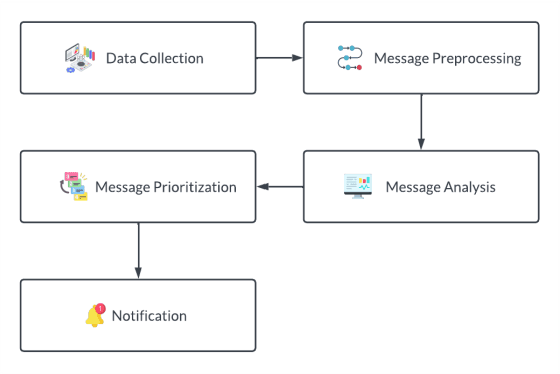
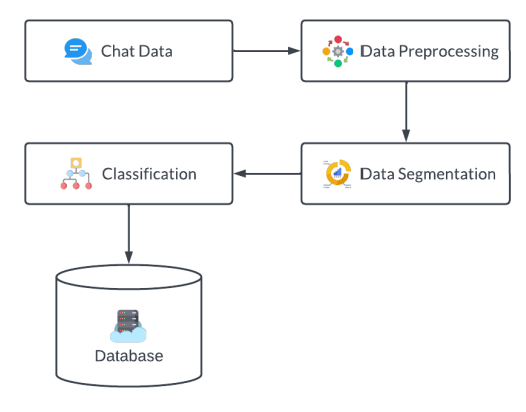
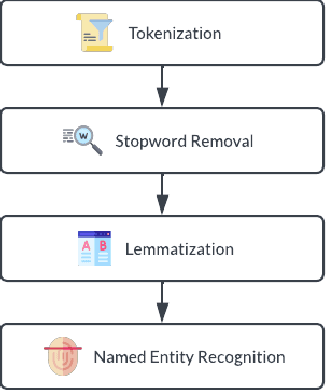
Social media apps have become very promising and omnipresent in daily life. Most social media apps are used to deliver vital information to those nearby and far away. As our lives become more hectic, many of us strive to limit our usage of social media apps because they are too addictive, and the majority of us have gotten preoccupied with our daily lives. Because of this, we frequently overlook crucial information, such as invitations to weddings, interviews, birthday parties, etc., or find ourselves unable to attend the event. In most cases, this happens because users are more likely to discover the invitation or information only before the event, giving them little time to prepare. To solve this issue, in this study, we created a system that will collect social media chat and filter it using Natural Language Processing (NLP) methods like Tokenization, Stop Words Removal, Lemmatization, Segmentation, and Named Entity Recognition (NER). Also, Machine Learning Algorithms such as K-Nearest Neighbor (KNN) Algorithm are implemented to prioritize the received invitation and to sort the level of priority. Finally, a customized notification will be delivered to the users where they acknowledge the upcoming event. So, the chances of missing the event are less or can be planned.
On Instance-Dependent Bounds for Offline Reinforcement Learning with Linear Function Approximation
Nov 23, 2022
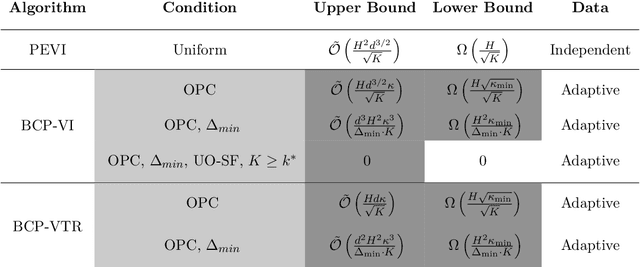

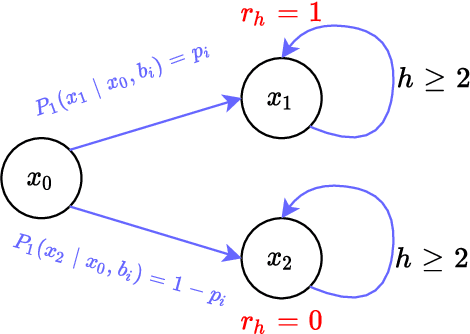
Sample-efficient offline reinforcement learning (RL) with linear function approximation has recently been studied extensively. Much of prior work has yielded the minimax-optimal bound of $\tilde{\mathcal{O}}(\frac{1}{\sqrt{K}})$, with $K$ being the number of episodes in the offline data. In this work, we seek to understand instance-dependent bounds for offline RL with function approximation. We present an algorithm called Bootstrapped and Constrained Pessimistic Value Iteration (BCP-VI), which leverages data bootstrapping and constrained optimization on top of pessimism. We show that under a partial data coverage assumption, that of \emph{concentrability} with respect to an optimal policy, the proposed algorithm yields a fast rate of $\tilde{\mathcal{O}}(\frac{1}{K})$ for offline RL when there is a positive gap in the optimal Q-value functions, even when the offline data were adaptively collected. Moreover, when the linear features of the optimal actions in the states reachable by an optimal policy span those reachable by the behavior policy and the optimal actions are unique, offline RL achieves absolute zero sub-optimality error when $K$ exceeds a (finite) instance-dependent threshold. To the best of our knowledge, these are the first $\tilde{\mathcal{O}}(\frac{1}{K})$ bound and absolute zero sub-optimality bound respectively for offline RL with linear function approximation from adaptive data with partial coverage. We also provide instance-agnostic and instance-dependent information-theoretical lower bounds to complement our upper bounds.