 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
I Prefer not to Say: Operationalizing Fair and User-guided Data Minimization
Nov 01, 2022
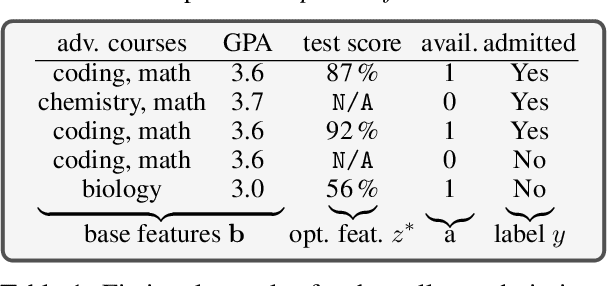
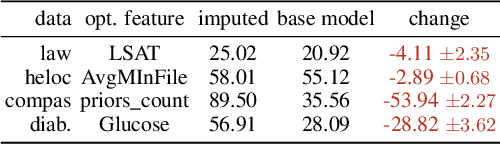
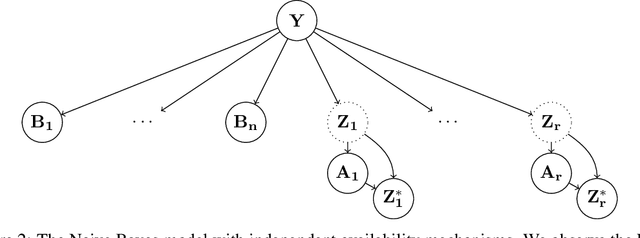
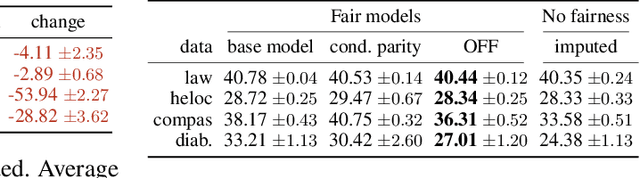
To grant users greater authority over their personal data, policymakers have suggested tighter data protection regulations (e.g., GDPR, CCPA). One key principle within these regulations is data minimization, which urges companies and institutions to only collect data that is relevant and adequate for the purpose of the data analysis. In this work, we take a user-centric perspective on this regulation, and let individual users decide which data they deem adequate and relevant to be processed by a machine-learned model. We require that users who decide to provide optional information should appropriately benefit from sharing their data, while users who rely on the mandate to leave their data undisclosed should not be penalized for doing so. This gives rise to the overlooked problem of fair treatment between individuals providing additional information and those choosing not to. While the classical fairness literature focuses on fair treatment between advantaged and disadvantaged groups, an initial look at this problem through the lens of classical fairness notions reveals that they are incompatible with these desiderata. We offer a solution to this problem by proposing the notion of Optional Feature Fairness (OFF) that follows from our requirements. To operationalize OFF, we derive a multi-model strategy and a tractable logistic regression model. We analyze the effect and the cost of applying OFF on several real-world data sets.
Detecting Unknown DGAs without Context Information
May 30, 2022
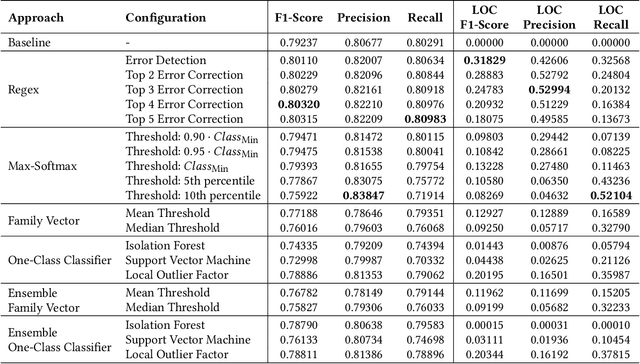
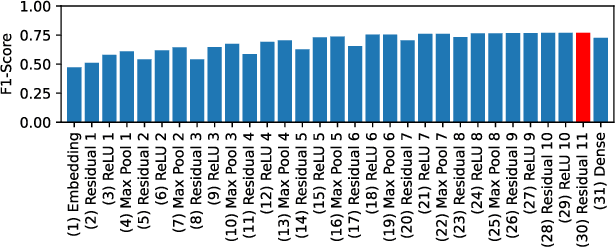
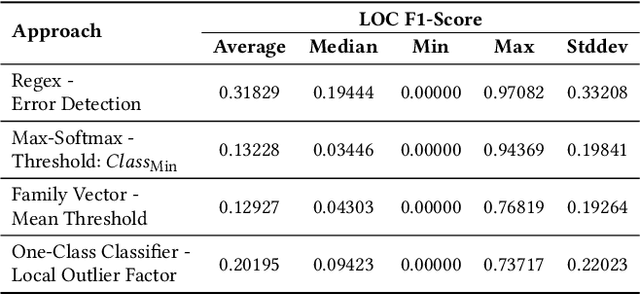
New malware emerges at a rapid pace and often incorporates Domain Generation Algorithms (DGAs) to avoid blocking the malware's connection to the command and control (C2) server. Current state-of-the-art classifiers are able to separate benign from malicious domains (binary classification) and attribute them with high probability to the DGAs that generated them (multiclass classification). While binary classifiers can label domains of yet unknown DGAs as malicious, multiclass classifiers can only assign domains to DGAs that are known at the time of training, limiting the ability to uncover new malware families. In this work, we perform a comprehensive study on the detection of new DGAs, which includes an evaluation of 59,690 classifiers. We examine four different approaches in 15 different configurations and propose a simple yet effective approach based on the combination of a softmax classifier and regular expressions (regexes) to detect multiple unknown DGAs with high probability. At the same time, our approach retains state-of-the-art classification performance for known DGAs. Our evaluation is based on a leave-one-group-out cross-validation with a total of 94 DGA families. By using the maximum number of known DGAs, our evaluation scenario is particularly difficult and close to the real world. All of the approaches examined are privacy-preserving, since they operate without context and exclusively on a single domain to be classified. We round up our study with a thorough discussion of class-incremental learning strategies that can adapt an existing classifier to newly discovered classes.
Adversarial Graph Contrastive Learning with Information Regularization
Feb 14, 2022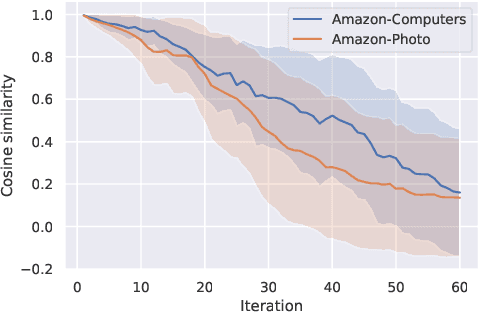
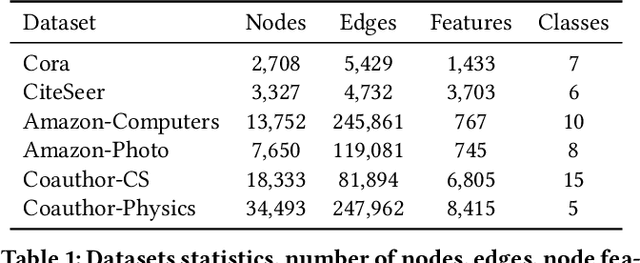
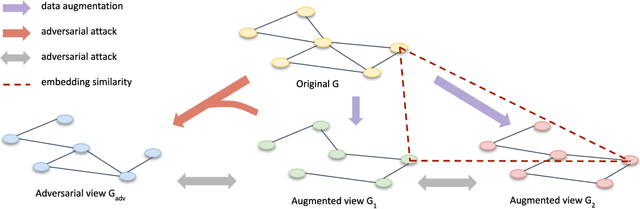
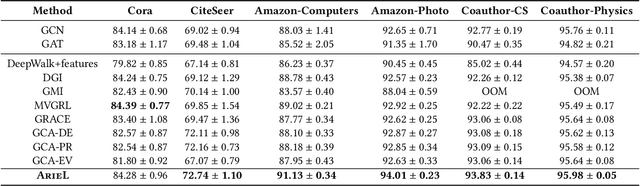
Contrastive learning is an effective unsupervised method in graph representation learning. Recently, the data augmentation based contrastive learning method has been extended from images to graphs. However, most prior works are directly adapted from the models designed for images. Unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which are the key to the performance of contrastive learning models. This leaves much space for improvement over the existing graph contrastive learning frameworks. In this work, by introducing an adversarial graph view and an information regularizer, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within a reasonable constraint. It consistently outperforms the current graph contrastive learning methods in the node classification task over various real-world datasets and further improves the robustness of graph contrastive learning.
Privacy-Preserving Text Classification on BERT Embeddings with Homomorphic Encryption
Oct 05, 2022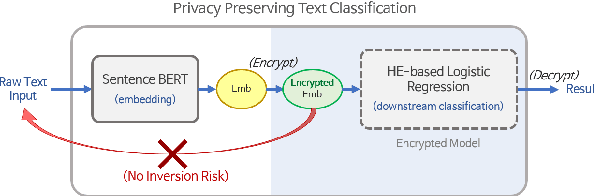

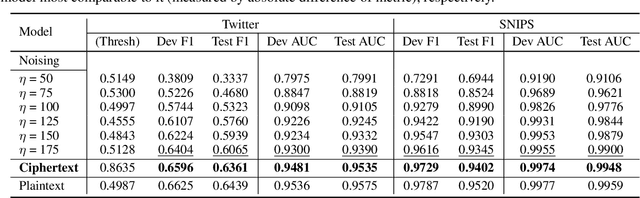
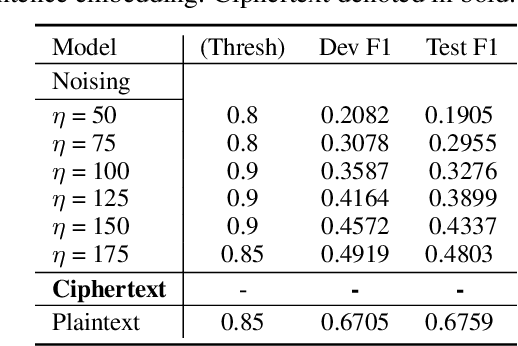
Embeddings, which compress information in raw text into semantics-preserving low-dimensional vectors, have been widely adopted for their efficacy. However, recent research has shown that embeddings can potentially leak private information about sensitive attributes of the text, and in some cases, can be inverted to recover the original input text. To address these growing privacy challenges, we propose a privatization mechanism for embeddings based on homomorphic encryption, to prevent potential leakage of any piece of information in the process of text classification. In particular, our method performs text classification on the encryption of embeddings from state-of-the-art models like BERT, supported by an efficient GPU implementation of CKKS encryption scheme. We show that our method offers encrypted protection of BERT embeddings, while largely preserving their utility on downstream text classification tasks.
Multilingual Representation Distillation with Contrastive Learning
Oct 10, 2022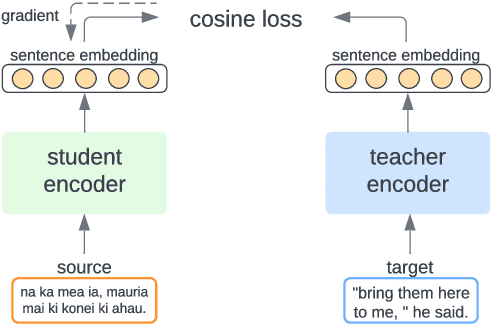

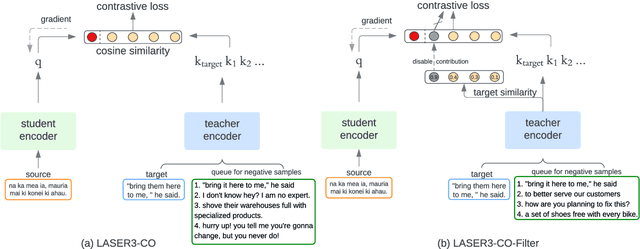
Multilingual sentence representations from large models can encode semantic information from two or more languages and can be used for different cross-lingual information retrieval tasks. In this paper, we integrate contrastive learning into multilingual representation distillation and use it for quality estimation of parallel sentences (find semantically similar sentences that can be used as translations of each other). We validate our approach with multilingual similarity search and corpus filtering tasks. Experiments across different low-resource languages show that our method significantly outperforms previous sentence encoders such as LASER, LASER3, and LaBSE.
FreGAN: Exploiting Frequency Components for Training GANs under Limited Data
Oct 11, 2022
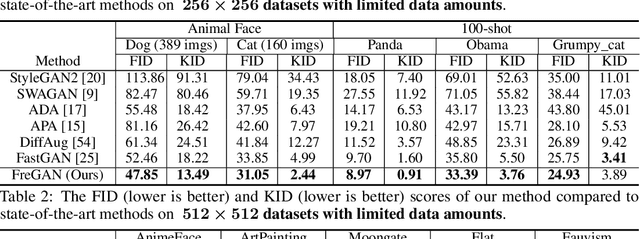
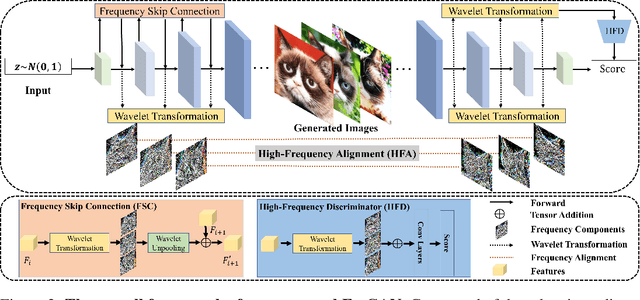
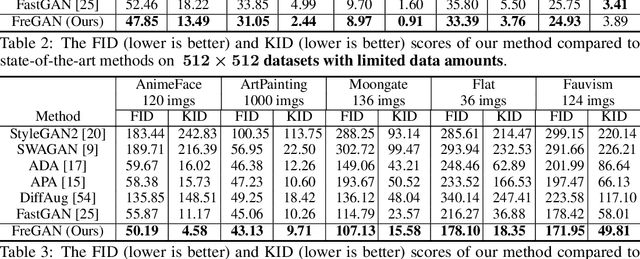
Training GANs under limited data often leads to discriminator overfitting and memorization issues, causing divergent training. Existing approaches mitigate the overfitting by employing data augmentations, model regularization, or attention mechanisms. However, they ignore the frequency bias of GANs and take poor consideration towards frequency information, especially high-frequency signals that contain rich details. To fully utilize the frequency information of limited data, this paper proposes FreGAN, which raises the model's frequency awareness and draws more attention to producing high-frequency signals, facilitating high-quality generation. In addition to exploiting both real and generated images' frequency information, we also involve the frequency signals of real images as a self-supervised constraint, which alleviates the GAN disequilibrium and encourages the generator to synthesize adequate rather than arbitrary frequency signals. Extensive results demonstrate the superiority and effectiveness of our FreGAN in ameliorating generation quality in the low-data regime (especially when training data is less than 100). Besides, FreGAN can be seamlessly applied to existing regularization and attention mechanism models to further boost the performance.
Error Performance of Rectangular Pulse-shaped OTFS with Practical Receivers
Nov 07, 2022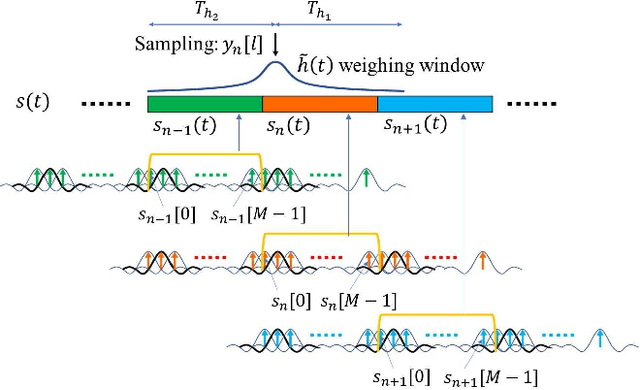
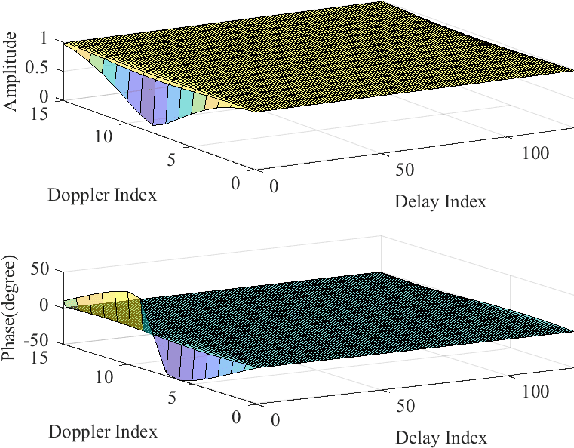
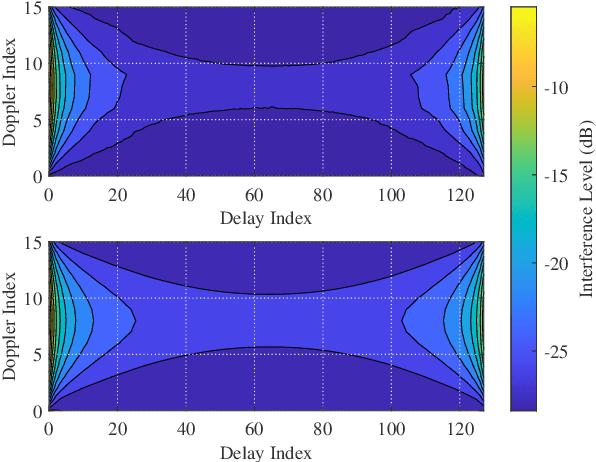
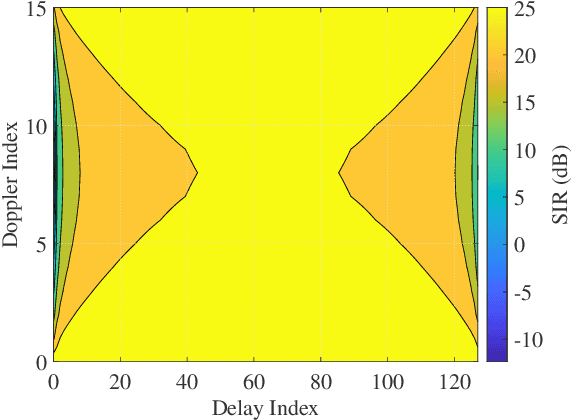
In this letter, we investigate error performance of rectangular pulse-shaped orthogonal time frequency space (OTFS) modulation with a practical receiver. Specifically, we consider an essential bandpass filter at receiver RF front-end, which has been ignored in existing works. We analyse the effect of rectangular pulses on practical OTFS receiver performance, and derive the exact forms of interference in delay-Doppler (DD) domain. We demonstrate that the transmitted information symbols in certain regions of the DD domain are severely contaminated. As a result, there is an error floor in the receiver error performance, which needs to be addressed for such OTFS waveform in practical systems.
MM-Locate-News: Multimodal Focus Location Estimation in News
Nov 15, 2022

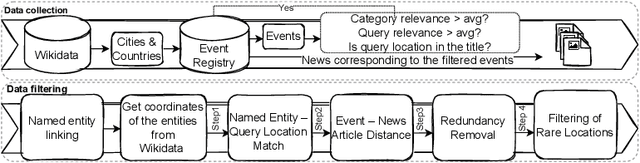
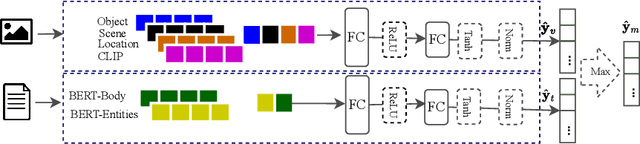
The consumption of news has changed significantly as the Web has become the most influential medium for information. To analyze and contextualize the large amount of news published every day, the geographic focus of an article is an important aspect in order to enable content-based news retrieval. There are methods and datasets for geolocation estimation from text or photos, but they are typically considered as separate tasks. However, the photo might lack geographical cues and text can include multiple locations, making it challenging to recognize the focus location using a single modality. In this paper, a novel dataset called Multimodal Focus Location of News (MM-Locate-News) is introduced. We evaluate state-of-the-art methods on the new benchmark dataset and suggest novel models to predict the focus location of news using both textual and image content. The experimental results show that the multimodal model outperforms unimodal models.
Low-Cost Beamforming and DOA Estimation Based on One-Bit Reconfigurable Intelligent Surface
Nov 15, 2022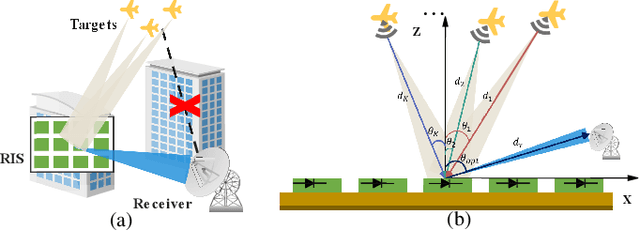
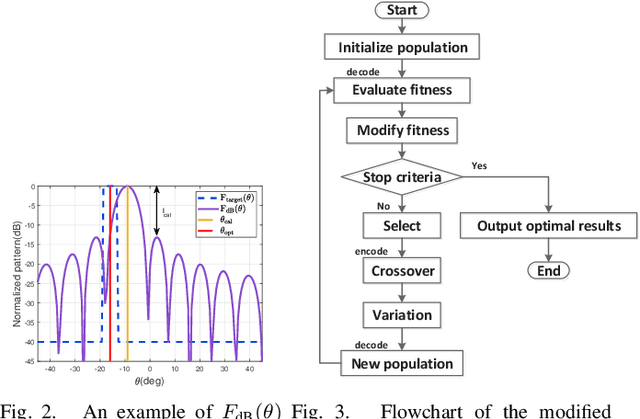
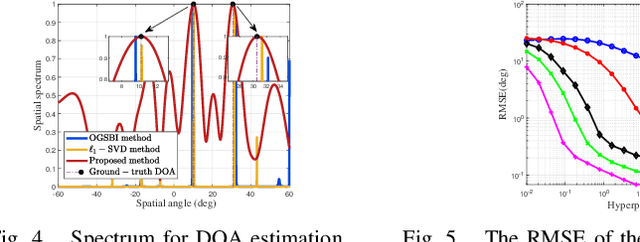
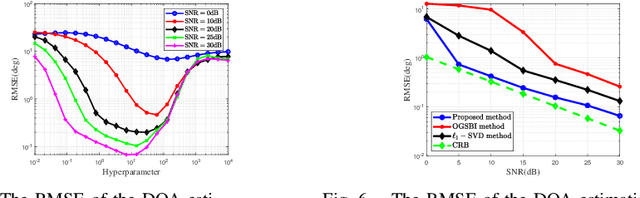
In this work, we consider the Direction-of-Arrival (DOA) estimation problem in a low-cost architecture where only one antenna as the receiver is aided by a reconfigurable intelligent surface (RIS). We introduce the one-bit RIS as a signal reflector to enhance signal transmission in non-line-of-sight (NLOS) situations and substantially simplify the physical hardware for DOA estimation. We optimize the beamforming scheme called measurement matrix to focus the echo power on the receiver with the coarse localization information of the targets as the prior. A beamforming scheme based on the modified genetic algorithm is proposed to optimize the measurement matrix, guaranteeing restricted isometry property (RIP) and meeting single beamforming requirements. The DOA results are finely estimated by solving an atomic-norm based sparse reconstruction problem. Simulation results show that the proposed method outperforms the existing methods in the DOA estimation performance.
* 5 pages, 8 figures
Combining State-of-the-Art Models with Maximal Marginal Relevance for Few-Shot and Zero-Shot Multi-Document Summarization
Nov 19, 2022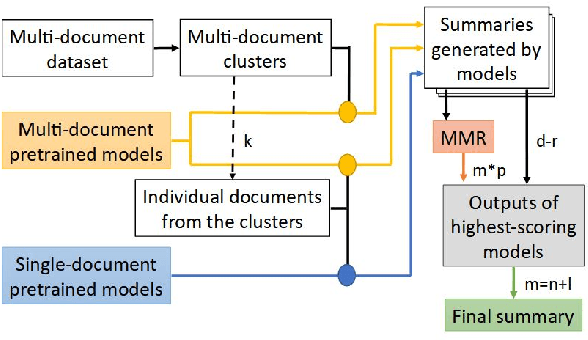
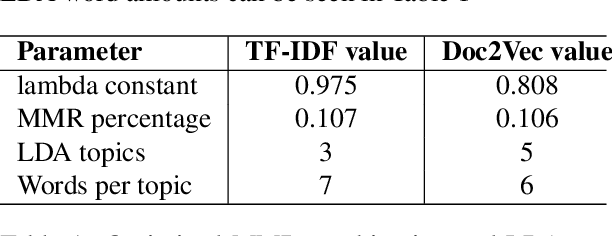
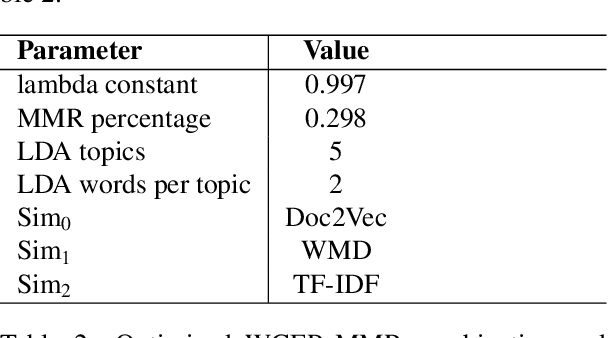
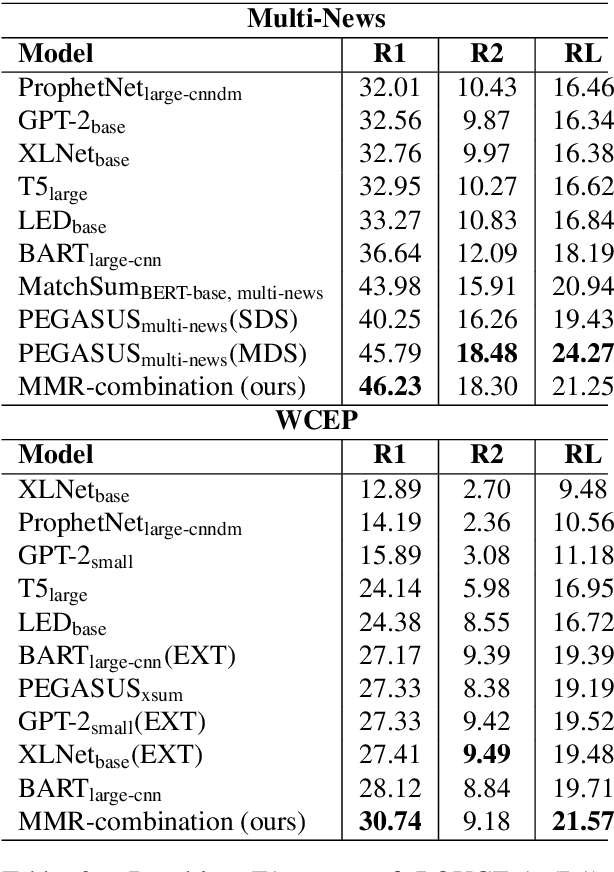
In Natural Language Processing, multi-document summarization (MDS) poses many challenges to researchers above those posed by single-document summarization (SDS). These challenges include the increased search space and greater potential for the inclusion of redundant information. While advancements in deep learning approaches have led to the development of several advanced language models capable of summarization, the variety of training data specific to the problem of MDS remains relatively limited. Therefore, MDS approaches which require little to no pretraining, known as few-shot or zero-shot applications, respectively, could be beneficial additions to the current set of tools available in summarization. To explore one possible approach, we devise a strategy for combining state-of-the-art models' outputs using maximal marginal relevance (MMR) with a focus on query relevance rather than document diversity. Our MMR-based approach shows improvement over some aspects of the current state-of-the-art results in both few-shot and zero-shot MDS applications while maintaining a state-of-the-art standard of output by all available metrics.