 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Refined Semantic Enhancement towards Frequency Diffusion for Video Captioning
Nov 28, 2022

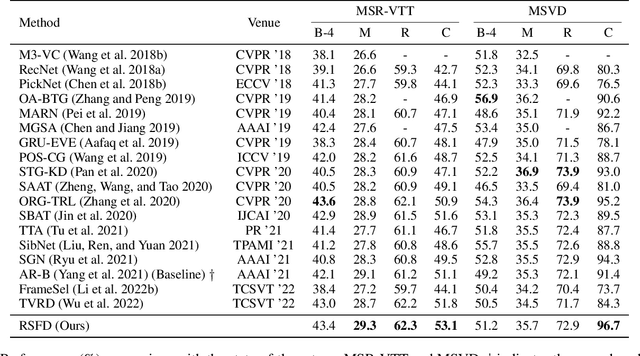
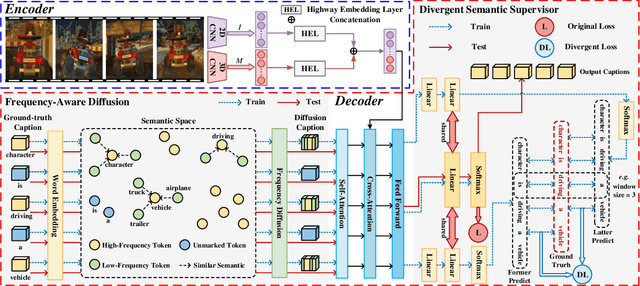
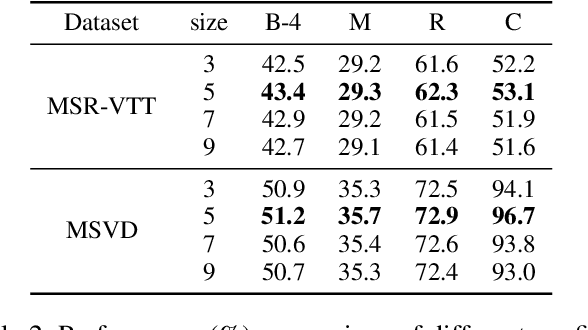
Video captioning aims to generate natural language sentences that describe the given video accurately. Existing methods obtain favorable generation by exploring richer visual representations in encode phase or improving the decoding ability. However, the long-tailed problem hinders these attempts at low-frequency tokens, which rarely occur but carry critical semantics, playing a vital role in the detailed generation. In this paper, we introduce a novel Refined Semantic enhancement method towards Frequency Diffusion (RSFD), a captioning model that constantly perceives the linguistic representation of the infrequent tokens. Concretely, a Frequency-Aware Diffusion (FAD) module is proposed to comprehend the semantics of low-frequency tokens to break through generation limitations. In this way, the caption is refined by promoting the absorption of tokens with insufficient occurrence. Based on FAD, we design a Divergent Semantic Supervisor (DSS) module to compensate for the information loss of high-frequency tokens brought by the diffusion process, where the semantics of low-frequency tokens is further emphasized to alleviate the long-tailed problem. Extensive experiments indicate that RSFD outperforms the state-of-the-art methods on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate that the enhancement of low-frequency tokens semantics can obtain a competitive generation effect. Code is available at https://github.com/lzp870/RSFD.
Hybrid Learning of Time-Series Inverse Dynamics Models for Locally Isotropic Robot Motion
Nov 28, 2022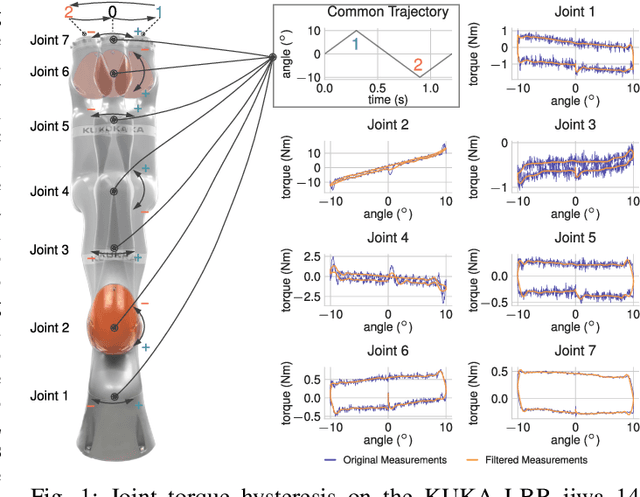
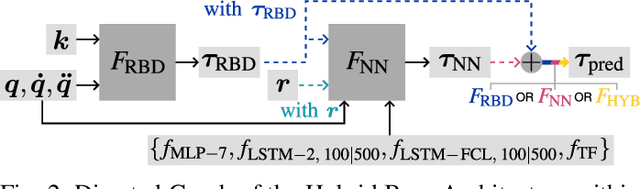
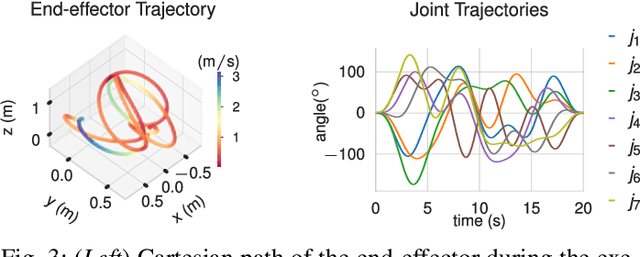
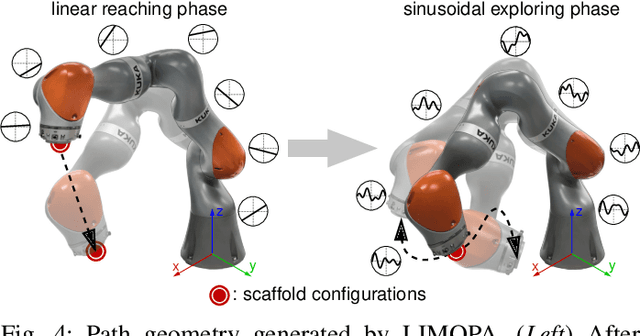
Applications of force control and motion planning often rely on an inverse dynamics model to represent the high-dimensional dynamic behavior of robots during motion. The widespread occurrence of low-velocity, small-scale, locally isotropic motion (LIMO) typically complicates the identification of appropriate models due to the exaggeration of dynamic effects and sensory perturbation caused by complex friction and phenomena of hysteresis, e.g., pertaining to joint elasticity. We propose a hybrid model learning base architecture combining a rigid body dynamics model identified by parametric regression and time-series neural network architectures based on multilayer-perceptron, LSTM, and Transformer topologies. Further, we introduce novel joint-wise rotational history encoding, reinforcing temporal information to effectively model dynamic hysteresis. The models are evaluated on a KUKA iiwa 14 during algorithmically generated locally isotropic movements. Together with the rotational encoding, the proposed architectures outperform state-of-the-art baselines by a magnitude of 10$^3$ yielding an RMSE of 0.14 Nm. Leveraging the hybrid structure and time-series encoding capabilities, our approach allows for accurate torque estimation, indicating its applicability in critically force-sensitive applications during motion sequences exceeding the capacity of conventional inverse dynamics models while retaining trainability in face of scarce data and explainability due to the employed physics model prior.
Near-filed SAR Image Restoration with Deep Learning Inverse Technique: A Preliminary Study
Nov 28, 2022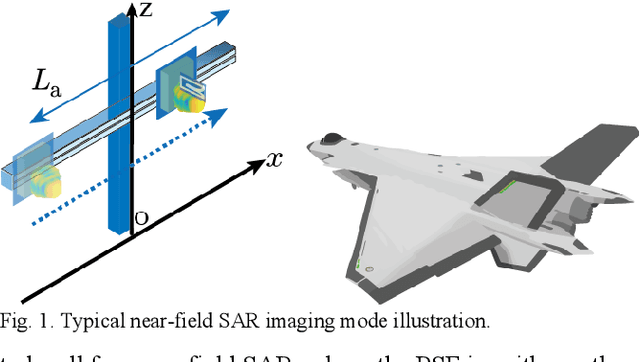
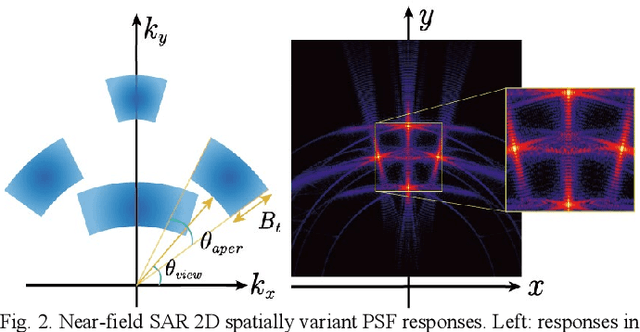

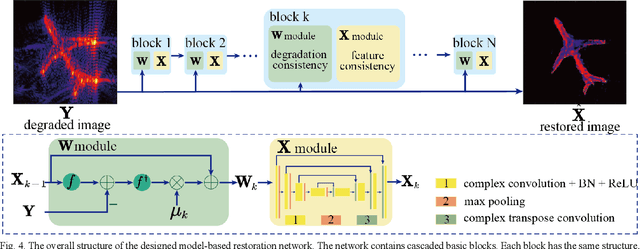
Benefiting from a relatively larger aperture's angle, and in combination with a wide transmitting bandwidth, near-field synthetic aperture radar (SAR) provides a high-resolution image of a target's scattering distribution-hot spots. Meanwhile, imaging result suffers inevitable degradation from sidelobes, clutters, and noises, hindering the information retrieval of the target. To restore the image, current methods make simplified assumptions; for example, the point spread function (PSF) is spatially consistent, the target consists of sparse point scatters, etc. Thus, they achieve limited restoration performance in terms of the target's shape, especially for complex targets. To address these issues, a preliminary study is conducted on restoration with the recent promising deep learning inverse technique in this work. We reformulate the degradation model into a spatially variable complex-convolution model, where the near-field SAR's system response is considered. Adhering to it, a model-based deep learning network is designed to restore the image. A simulated degraded image dataset from multiple complex target models is constructed to validate the network. All the images are formulated using the electromagnetic simulation tool. Experiments on the dataset reveal their effectiveness. Compared with current methods, superior performance is achieved regarding the target's shape and energy estimation.
Frustratingly Easy Label Projection for Cross-lingual Transfer
Nov 28, 2022
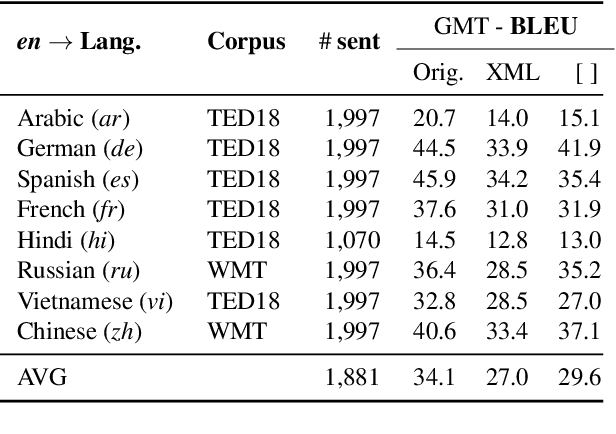
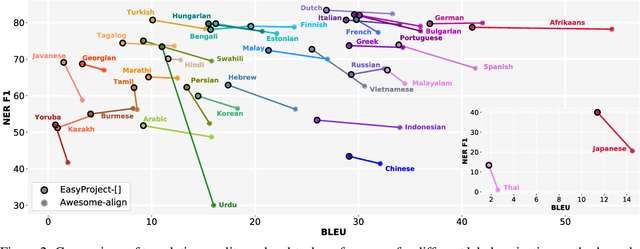
Translating training data into many languages has emerged as a practical solution for improving cross-lingual transfer. For tasks that involve span-level annotations, such as information extraction or question answering, an additional label projection step is required to map annotated spans onto the translated texts. Recently, a few efforts have utilized a simple mark-then-translate method to jointly perform translation and projection by inserting special markers around the labeled spans in the original sentence. However, as far as we are aware, no empirical analysis has been conducted on how this approach compares to traditional annotation projection based on word alignment. In this paper, we present an extensive empirical study across 42 languages and three tasks (QA, NER, and Event Extraction) to evaluate the effectiveness and limitations of both methods, filling an important gap in the literature. Experimental results show that our optimized version of mark-then-translate, which we call EasyProject, is easily applied to many languages and works surprisingly well, outperforming the more complex word alignment-based methods. We analyze several key factors that affect end-task performance, and show EasyProject works well because it can accurately preserve label span boundaries after translation. We will publicly release all our code and data.
On the Effective Usage of Priors in RSS-based Localization
Nov 28, 2022
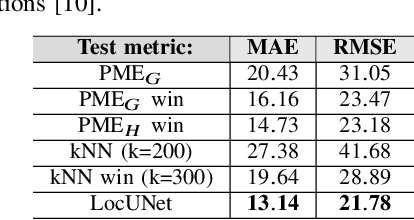
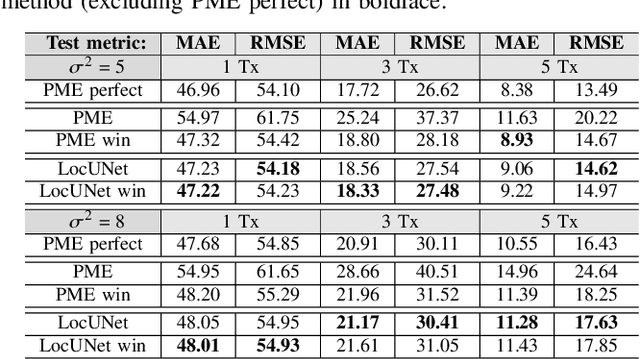
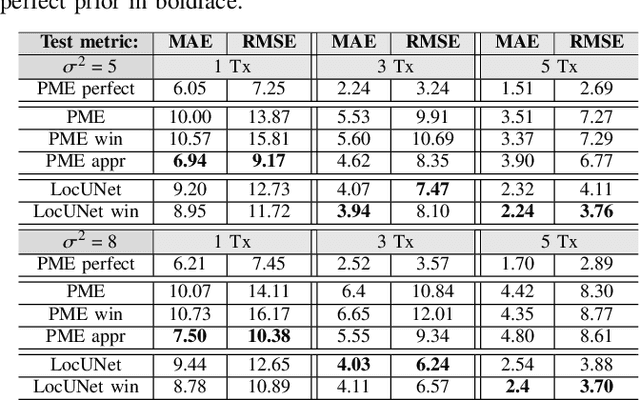
In this paper, we study the localization problem in dense urban settings. In such environments, Global Navigation Satellite Systems fail to provide good accuracy due to low likelihood of line-of-sight (LOS) links between the receiver (Rx) to be located and the satellites, due to the presence of obstacles like the buildings. Thus, one has to resort to other technologies, which can reliably operate under non-line-of-sight (NLOS) conditions. Recently, we proposed a Received Signal Strength (RSS) fingerprint and convolutional neural network-based algorithm, LocUNet, and demonstrated its state-of-the-art localization performance with respect to the widely adopted k-nearest neighbors (kNN) algorithm, and to state-of-the-art time of arrival (ToA) ranging-based methods. In the current work, we first recognize LocUNet's ability to learn the underlying prior distribution of the Rx position or Rx and transmitter (Tx) association preferences from the training data, and attribute its high performance to these. Conversely, we demonstrate that classical methods based on probabilistic approach, can greatly benefit from an appropriate incorporation of such prior information. Our studies also numerically prove LocUNet's close to optimal performance in many settings, by comparing it with the theoretically optimal formulations.
Metric Learning as a Service with Covariance Embedding
Nov 28, 2022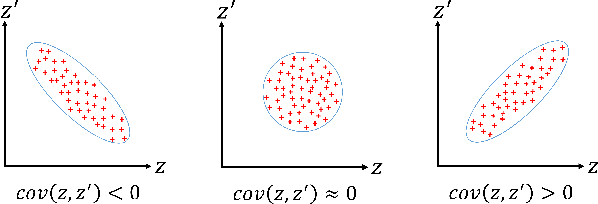

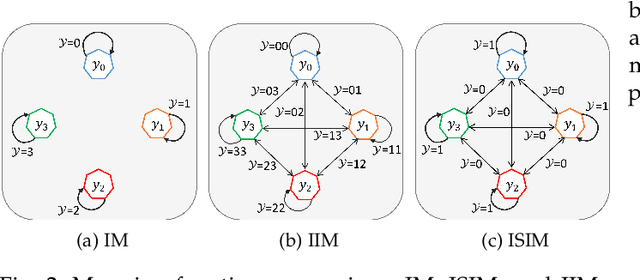
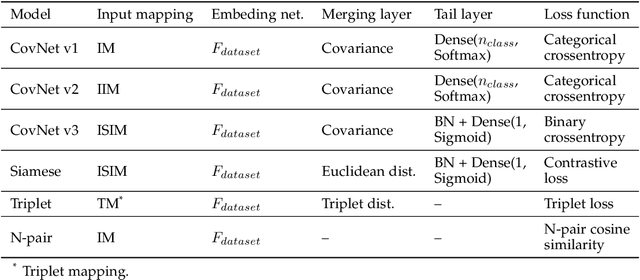
With the emergence of deep learning, metric learning has gained significant popularity in numerous machine learning tasks dealing with complex and large-scale datasets, such as information retrieval, object recognition and recommendation systems. Metric learning aims to maximize and minimize inter- and intra-class similarities. However, existing models mainly rely on distance measures to obtain a separable embedding space and implicitly maximize the intra-class similarity while neglecting the inter-class relationship. We argue that to enable metric learning as a service for high-performance deep learning applications, we should also wisely deal with inter-class relationships to obtain a more advanced and meaningful embedding space representation. In this paper, a novel metric learning is presented as a service methodology that incorporates covariance to signify the direction of the linear relationship between data points in an embedding space. Unlike conventional metric learning, our covariance-embedding-enhanced approach enables metric learning as a service to be more expressive for computing similar or dissimilar measures and can capture positive, negative, or neutral relationships. Extensive experiments conducted using various benchmark datasets, including natural, biomedical, and facial images, demonstrate that the proposed model as a service with covariance-embedding optimizations can obtain higher-quality, more separable, and more expressive embedding representations than existing models.
Superpoint Transformer for 3D Scene Instance Segmentation
Nov 28, 2022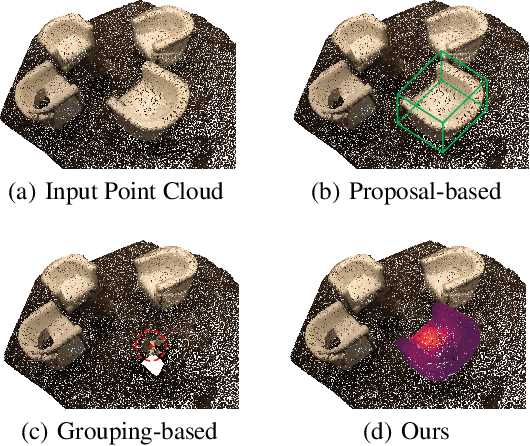
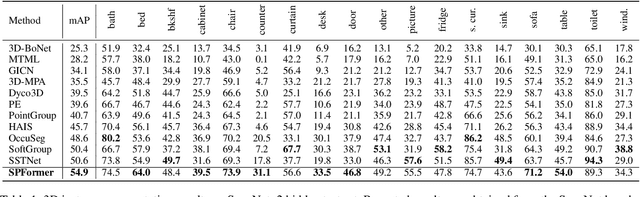
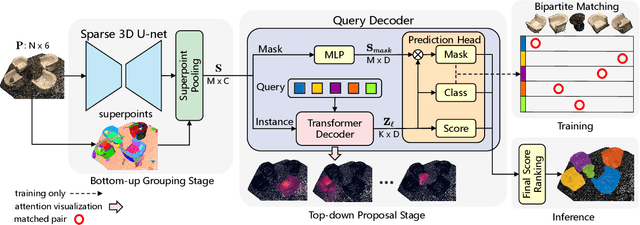
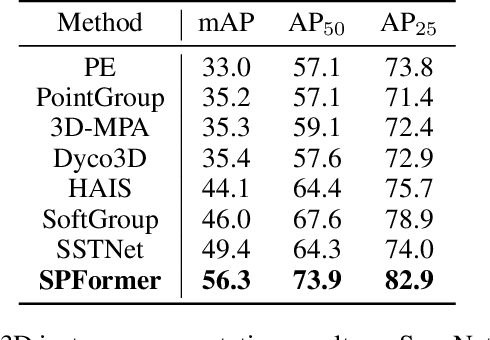
Most existing methods realize 3D instance segmentation by extending those models used for 3D object detection or 3D semantic segmentation. However, these non-straightforward methods suffer from two drawbacks: 1) Imprecise bounding boxes or unsatisfactory semantic predictions limit the performance of the overall 3D instance segmentation framework. 2) Existing method requires a time-consuming intermediate step of aggregation. To address these issues, this paper proposes a novel end-to-end 3D instance segmentation method based on Superpoint Transformer, named as SPFormer. It groups potential features from point clouds into superpoints, and directly predicts instances through query vectors without relying on the results of object detection or semantic segmentation. The key step in this framework is a novel query decoder with transformers that can capture the instance information through the superpoint cross-attention mechanism and generate the superpoint masks of the instances. Through bipartite matching based on superpoint masks, SPFormer can implement the network training without the intermediate aggregation step, which accelerates the network. Extensive experiments on ScanNetv2 and S3DIS benchmarks verify that our method is concise yet efficient. Notably, SPFormer exceeds compared state-of-the-art methods by 4.3% on ScanNetv2 hidden test set in terms of mAP and keeps fast inference speed (247ms per frame) simultaneously. Code is available at https://github.com/sunjiahao1999/SPFormer.
Coarse-to-fine Task-driven Inpainting for Geoscience Images
Nov 30, 2022

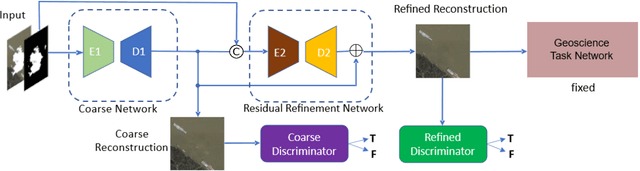
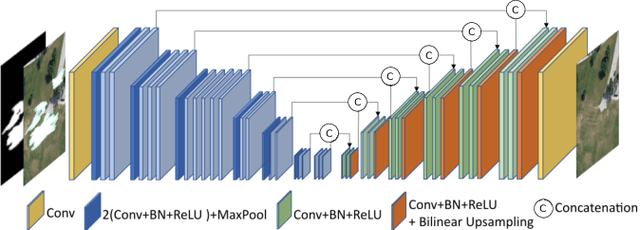
The processing and recognition of geoscience images have wide applications. Most of existing researches focus on understanding the high-quality geoscience images by assuming that all the images are clear. However, in many real-world cases, the geoscience images might contain occlusions during the image acquisition. This problem actually implies the image inpainting problem in computer vision and multimedia. To the best of our knowledge, all the existing image inpainting algorithms learn to repair the occluded regions for a better visualization quality, they are excellent for natural images but not good enough for geoscience images by ignoring the geoscience related tasks. This paper aims to repair the occluded regions for a better geoscience task performance with the advanced visualization quality simultaneously, without changing the current deployed deep learning based geoscience models. Because of the complex context of geoscience images, we propose a coarse-to-fine encoder-decoder network with coarse-to-fine adversarial context discriminators to reconstruct the occluded image regions. Due to the limited data of geoscience images, we use a MaskMix based data augmentation method to exploit more information from limited geoscience image data. The experimental results on three public geoscience datasets for remote sensing scene recognition, cross-view geolocation and semantic segmentation tasks respectively show the effectiveness and accuracy of the proposed method.
Robust, fast and accurate mapping of diffusional mean kurtosis
Nov 30, 2022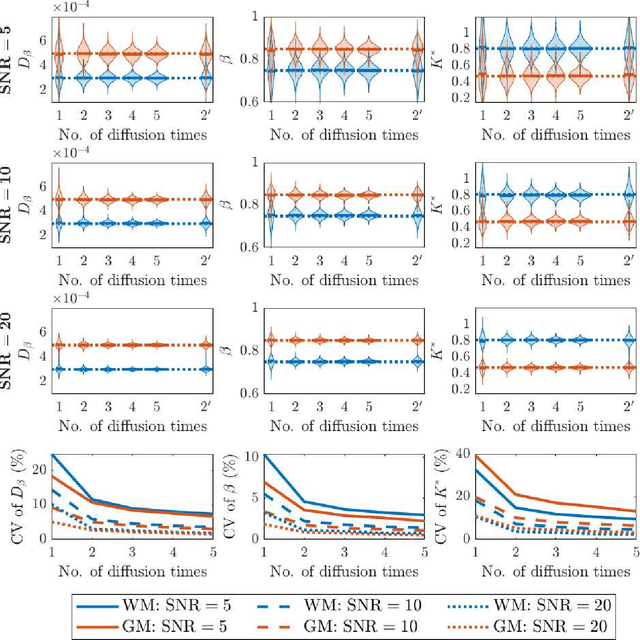
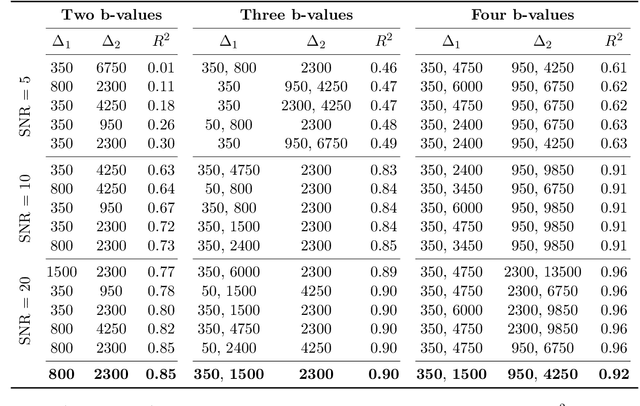
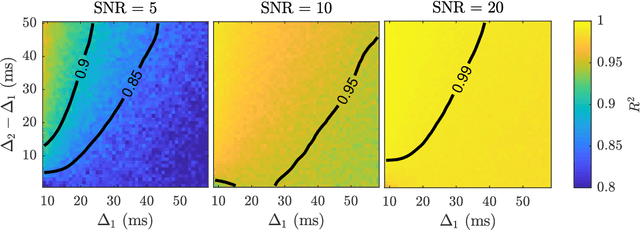
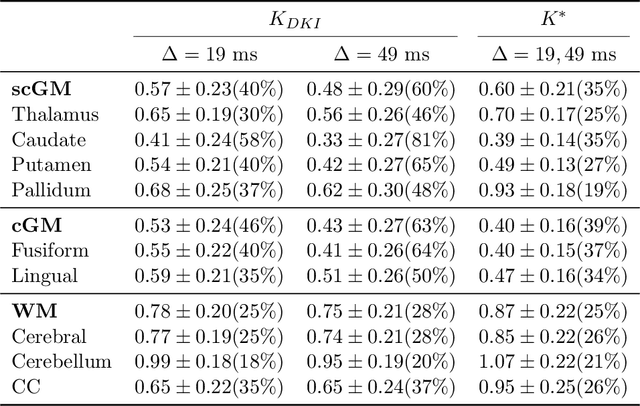
Diffusion weighted magnetic resonance imaging produces data encoded with the random motion of water molecules in biological tissues. The collection and extraction of information from such data have become critical to modern imaging studies, and particularly those focusing on neuroimaging. A range of mathematical models are routinely applied to infer tissue microstructure properties. Diffusional kurtosis imaging entails a model for measuring the extent of non-Gaussian diffusion in biological tissues. The method has seen wide assimilation across a range of clinical applications, and promises to be an increasingly important tool for clinical diagnosis, treatment planning and monitoring. However, accurate and robust estimation of kurtosis from clinically feasible data acquisitions remains a challenge. We outline a fast and robust way of estimating mean kurtosis via the sub-diffusion mathematical framework. Our kurtosis mapping method is evaluated using simulations and the Connectome 1.0 human brain data. Results show that fitting the sub-diffusion model to multiple diffusion time data and then directly calculating the mean kurtosis greatly improves the quality of the estimation. Suggestions for diffusion encoding sampling, the number of diffusion times to be acquired and the separation between them are provided. Exquisite tissue contrast is achieved even when the diffusion encoded data is collected in only minutes. Our findings suggest robust estimation of mean kurtosis can be realised within a clinically feasible diffusion weighted magnetic resonance imaging data acquisition time.
Optical multi-task learning using multi-wavelength diffractive deep neural networks
Nov 30, 2022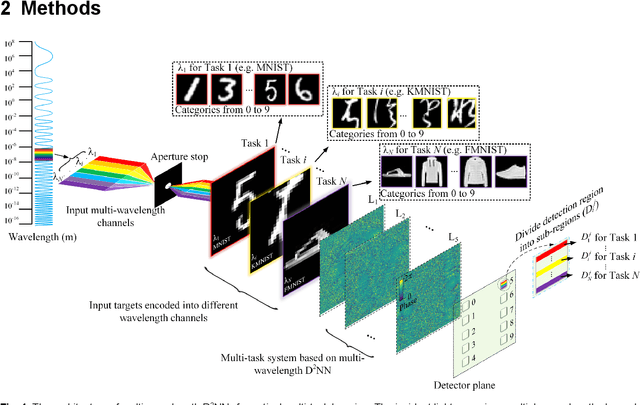
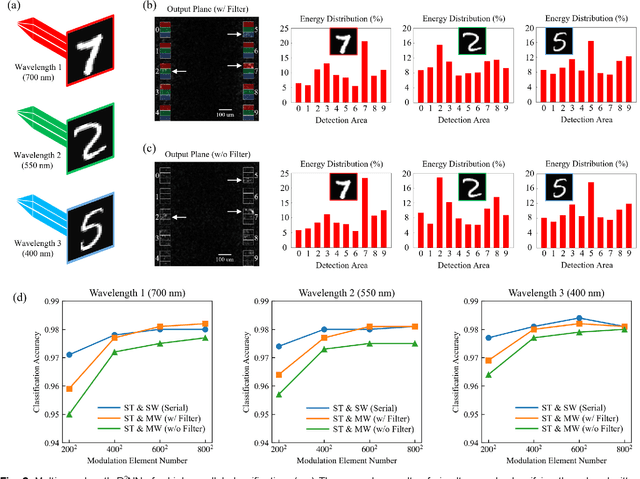
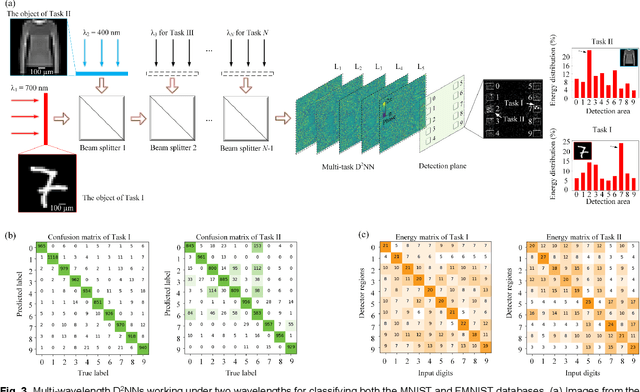
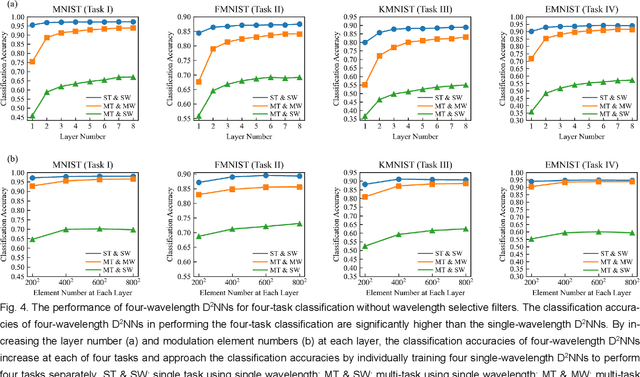
Photonic neural networks are brain-inspired information processing technology using photons instead of electrons to perform artificial intelligence (AI) tasks. However, existing architectures are designed for a single task but fail to multiplex different tasks in parallel within a single monolithic system due to the task competition that deteriorates the model performance. This paper proposes a novel optical multi-task learning system by designing multi-wavelength diffractive deep neural networks (D2NNs) with the joint optimization method. By encoding multi-task inputs into multi-wavelength channels, the system can increase the computing throughput and significantly alle-viate the competition to perform multiple tasks in parallel with high accuracy. We design the two-task and four-task D2NNs with two and four spectral channels, respectively, for classifying different inputs from MNIST, FMNIST, KMNIST, and EMNIST databases. The numerical evaluations demonstrate that, under the same network size, mul-ti-wavelength D2NNs achieve significantly higher classification accuracies for multi-task learning than single-wavelength D2NNs. Furthermore, by increasing the network size, the multi-wavelength D2NNs for simultaneously performing multiple tasks achieve comparable classification accuracies with respect to the individual training of multiple single-wavelength D2NNs to perform tasks separately. Our work paves the way for developing the wave-length-division multiplexing technology to achieve high-throughput neuromorphic photonic computing and more general AI systems to perform multiple tasks in parallel.