 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Auto Lead Extraction and Digitization of ECG Paper Records using cGAN
Nov 12, 2022
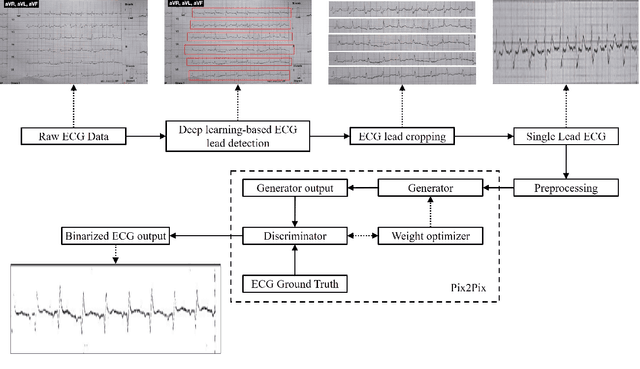
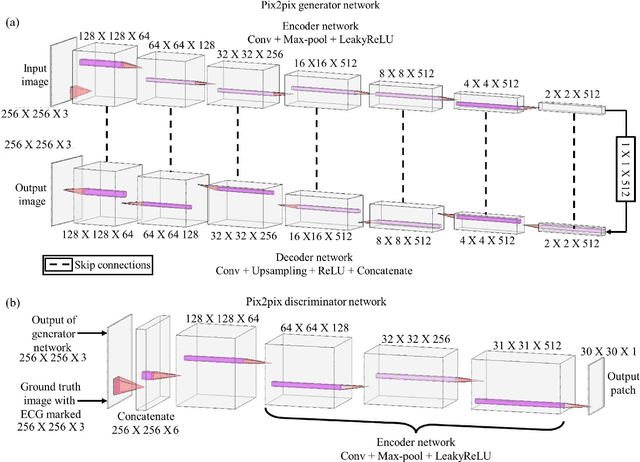
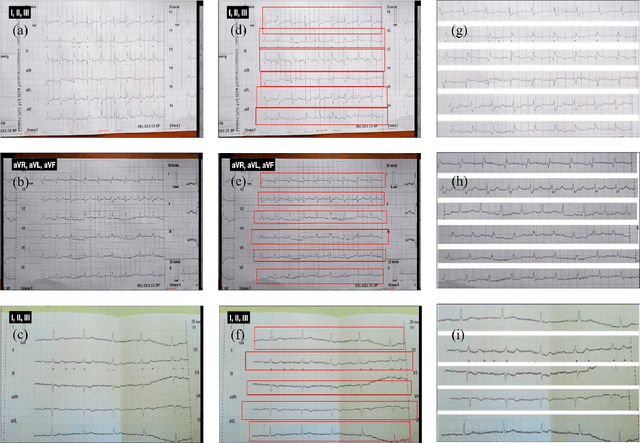
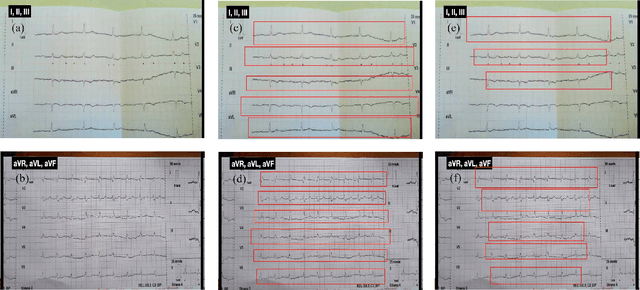
Purpose: An Electrocardiogram (ECG) is the simplest and fastest bio-medical test that is used to detect any heart-related disease. ECG signals are generally stored in paper form, which makes it difficult to store and analyze the data. While capturing ECG leads from paper ECG records, a lot of background information is also captured, which results in incorrect data interpretation. Methods: We propose a deep learning-based model for individually extracting all 12 leads from 12-lead ECG images captured using a camera. To simplify the analysis of the ECG and the calculation of complex parameters, we also propose a method to convert the paper ECG format into a storable digital format. The You Only Look Once, Version 3 (YOLOv3) algorithm has been used to extract the leads present in the image. These leads are then passed on to another deep learning model which separates the ECG signal and background from the single-lead image. After that, vertical scanning is performed on the ECG signal to convert it into a 1-Dimensional (1D) digital form. To perform the task of digitalization, we used the pix-2-pix deep learning model and binarized the ECG signals. Results: Our proposed method was able to achieve an accuracy of 97.4 %. Conclusion: The information on the paper ECG fades away over time. Hence, the digitized ECG signals make it possible to store the records and access them anytime. This proves highly beneficial for heart patients who require frequent ECG reports. The stored data can also be useful for research purposes, as this data can be used to develop computer algorithms that are capable of analyzing the data.
Dual Multi-scale Mean Teacher Network for Semi-supervised Infection Segmentation in Chest CT Volume for COVID-19
Nov 10, 2022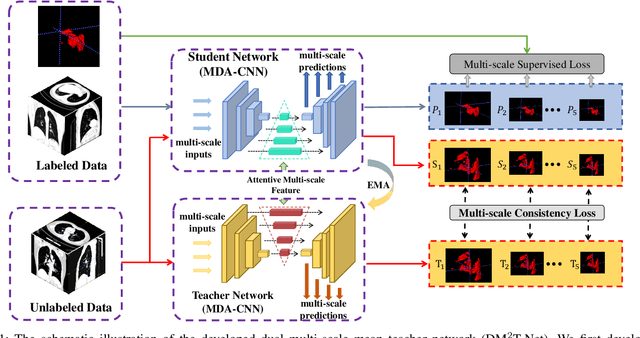
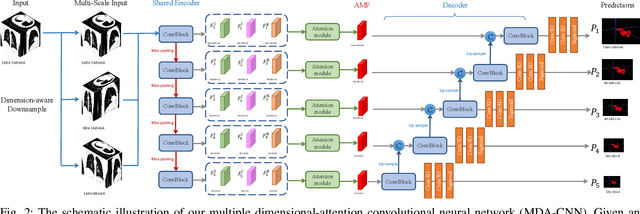
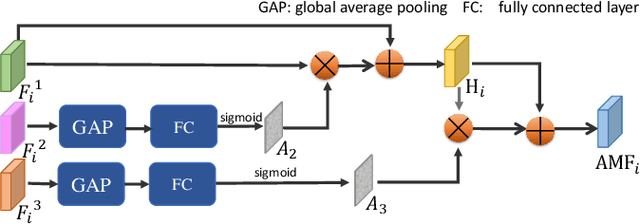

Automated detecting lung infections from computed tomography (CT) data plays an important role for combating COVID-19. However, there are still some challenges for developing AI system. 1) Most current COVID-19 infection segmentation methods mainly relied on 2D CT images, which lack 3D sequential constraint. 2) Existing 3D CT segmentation methods focus on single-scale representations, which do not achieve the multiple level receptive field sizes on 3D volume. 3) The emergent breaking out of COVID-19 makes it hard to annotate sufficient CT volumes for training deep model. To address these issues, we first build a multiple dimensional-attention convolutional neural network (MDA-CNN) to aggregate multi-scale information along different dimension of input feature maps and impose supervision on multiple predictions from different CNN layers. Second, we assign this MDA-CNN as a basic network into a novel dual multi-scale mean teacher network (DM${^2}$T-Net) for semi-supervised COVID-19 lung infection segmentation on CT volumes by leveraging unlabeled data and exploring the multi-scale information. Our DM${^2}$T-Net encourages multiple predictions at different CNN layers from the student and teacher networks to be consistent for computing a multi-scale consistency loss on unlabeled data, which is then added to the supervised loss on the labeled data from multiple predictions of MDA-CNN. Third, we collect two COVID-19 segmentation datasets to evaluate our method. The experimental results show that our network consistently outperforms the compared state-of-the-art methods.
Data Augmentation Vision Transformer for Fine-grained Image Classification
Nov 24, 2022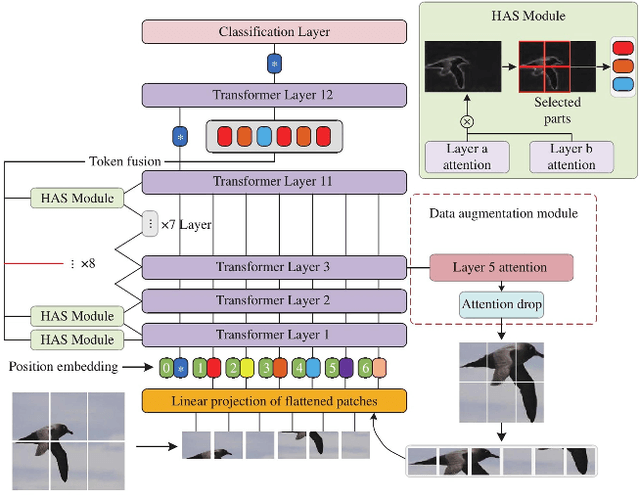
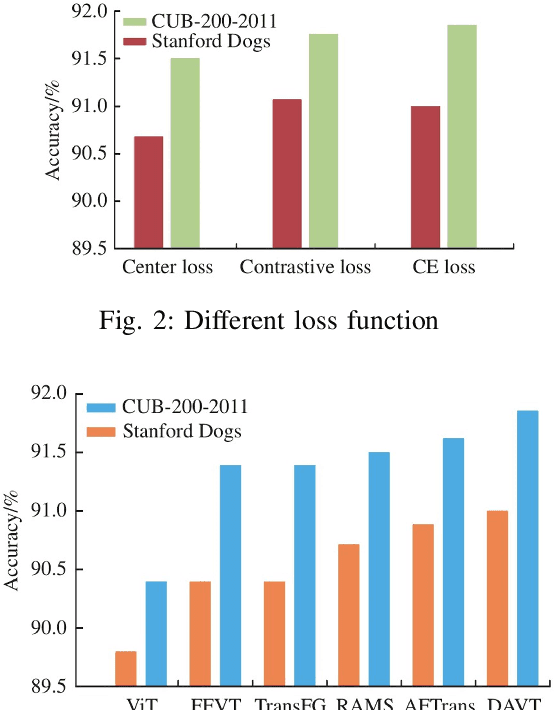


Recently, the vision transformer (ViT) has made breakthroughs in image recognition. Its self-attention mechanism (MSA) can extract discriminative labeling information of different pixel blocks to improve image classification accuracy. However, the classification marks in their deep layers tend to ignore local features between layers. In addition, the embedding layer will be fixed-size pixel blocks. Input network Inevitably introduces additional image noise. To this end, we study a data augmentation vision transformer (DAVT) based on data augmentation and proposes a data augmentation method for attention cropping, which uses attention weights as the guide to crop images and improve the ability of the network to learn critical features. Secondly, we also propose a hierarchical attention selection (HAS) method, which improves the ability of discriminative markers between levels of learning by filtering and fusing labels between levels. Experimental results show that the accuracy of this method on the two general datasets, CUB-200-2011, and Stanford Dogs, is better than the existing mainstream methods, and its accuracy is 1.4\% and 1.6\% higher than the original ViT, respectively
* IEEE Signal Processing Letters
3D Dual-Fusion: Dual-Domain Dual-Query Camera-LiDAR Fusion for 3D Object Detection
Nov 24, 2022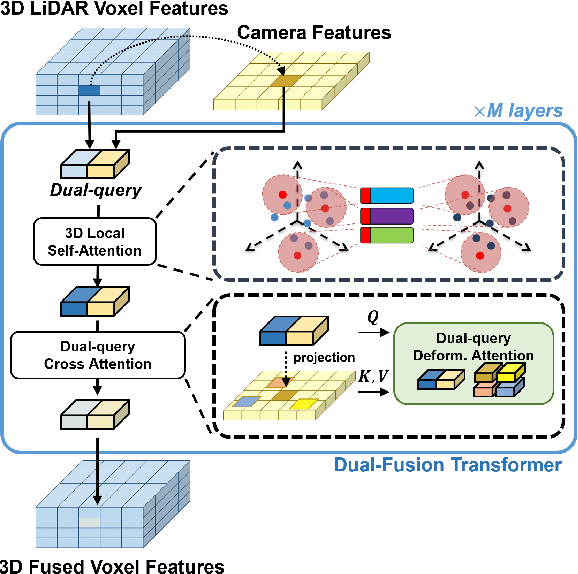
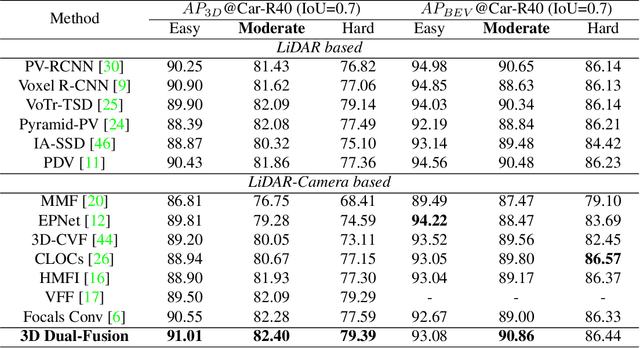
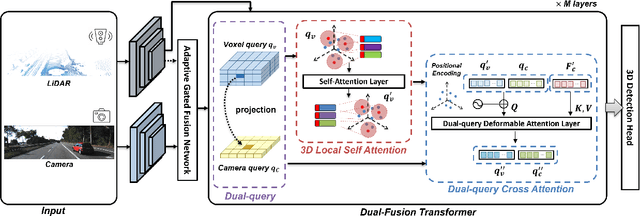
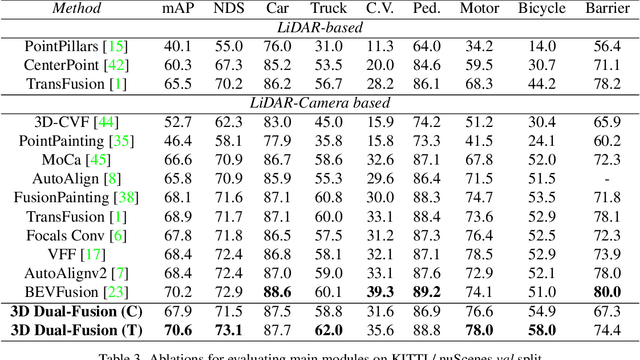
Fusing data from cameras and LiDAR sensors is an essential technique to achieve robust 3D object detection. One key challenge in camera-LiDAR fusion involves mitigating the large domain gap between the two sensors in terms of coordinates and data distribution when fusing their features. In this paper, we propose a novel camera-LiDAR fusion architecture called, 3D Dual-Fusion, which is designed to mitigate the gap between the feature representations of camera and LiDAR data. The proposed method fuses the features of the camera-view and 3D voxel-view domain and models their interactions through deformable attention. We redesign the transformer fusion encoder to aggregate the information from the two domains. Two major changes include 1) dual query-based deformable attention to fuse the dual-domain features interactively and 2) 3D local self-attention to encode the voxel-domain queries prior to dual-query decoding. The results of an experimental evaluation show that the proposed camera-LiDAR fusion architecture achieved competitive performance on the KITTI and nuScenes datasets, with state-of-the-art performances in some 3D object detection benchmarks categories.
Physics-guided deep learning for data scarcity
Nov 24, 2022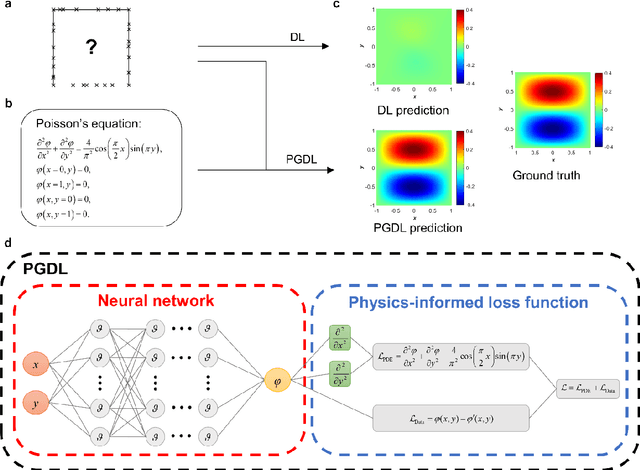
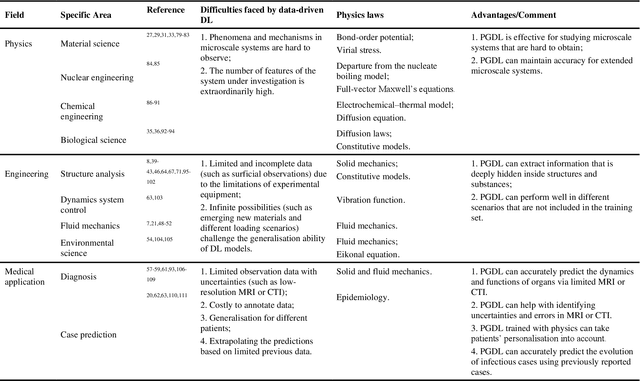
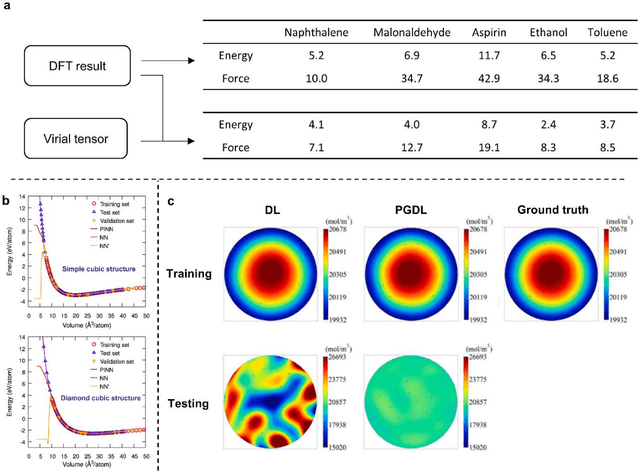
Data are the core of deep learning (DL), and the quality of data significantly affects the performance of DL models. However, high-quality and well-annotated databases are hard or even impossible to acquire for use in many applications, such as structural risk estimation and medical diagnosis, which is an essential barrier that blocks the applications of DL in real life. Physics-guided deep learning (PGDL) is a novel type of DL that can integrate physics laws to train neural networks. It can be used for any systems that are controlled or governed by physics laws, such as mechanics, finance and medical applications. It has been shown that, with the additional information provided by physics laws, PGDL achieves great accuracy and generalisation when facing data scarcity. In this review, the details of PGDL are elucidated, and a structured overview of PGDL with respect to data scarcity in various applications is presented, including physics, engineering and medical applications. Moreover, the limitations and opportunities for current PGDL in terms of data scarcity are identified, and the future outlook for PGDL is discussed in depth.
Fingerprint Image-Quality Estimation and its Application to Multialgorithm Verification
Nov 24, 2022
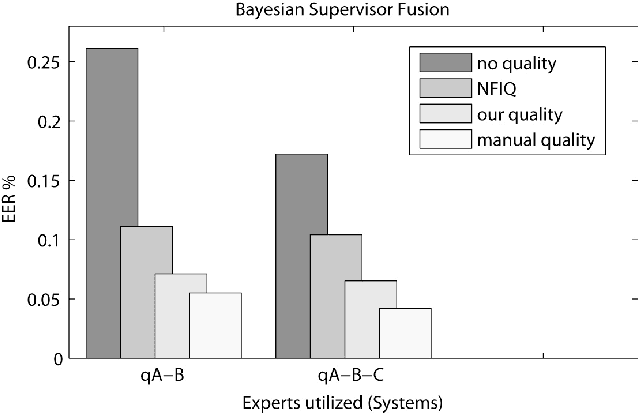
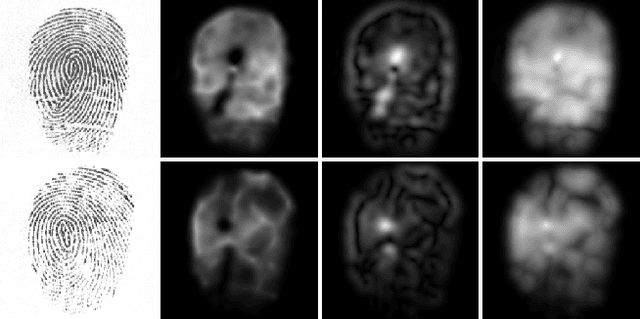

Signal-quality awareness has been found to increase recognition rates and to support decisions in multisensor environments significantly. Nevertheless, automatic quality assessment is still an open issue. Here, we study the orientation tensor of fingerprint images to quantify signal impairments, such as noise, lack of structure, blur, with the help of symmetry descriptors. A strongly reduced reference is especially favorable in biometrics, but less information is not sufficient for the approach. This is also supported by numerous experiments involving a simpler quality estimator, a trained method (NFIQ), as well as the human perception of fingerprint quality on several public databases. Furthermore, quality measurements are extensively reused to adapt fusion parameters in a monomodal multialgorithm fingerprint recognition environment. In this study, several trained and nontrained score-level fusion schemes are investigated. A Bayes-based strategy for incorporating experts past performances and current quality conditions, a novel cascaded scheme for computational efficiency, besides simple fusion rules, is presented. The quantitative results favor quality awareness under all aspects, boosting recognition rates and fusing differently skilled experts efficiently as well as effectively (by training).
R2-MLP: Round-Roll MLP for Multi-View 3D Object Recognition
Nov 20, 2022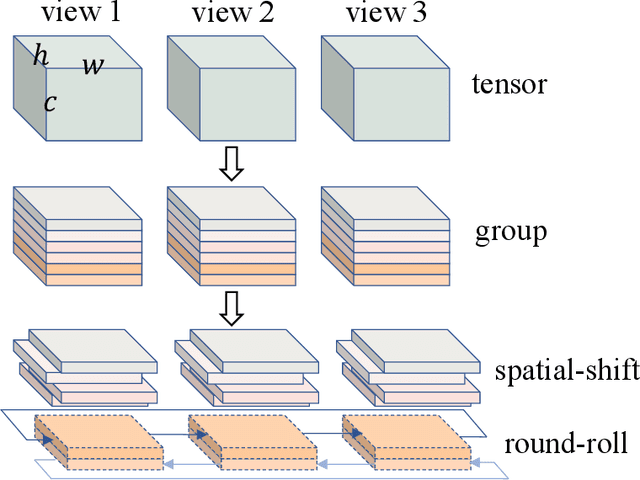
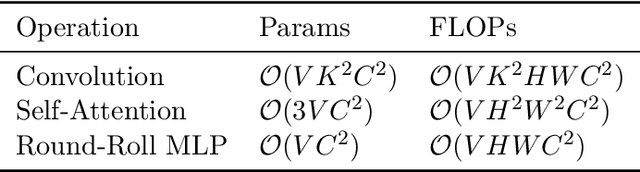
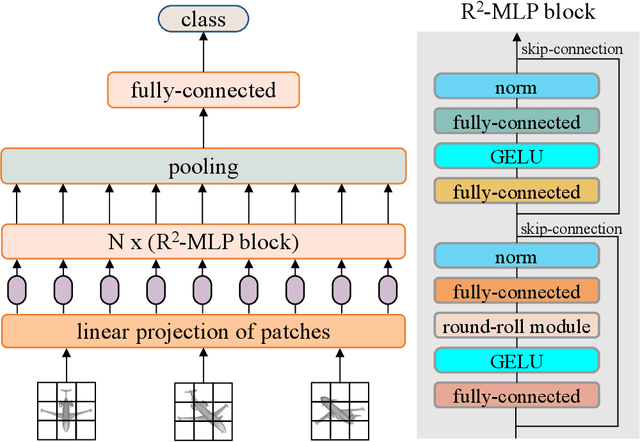

Recently, vision architectures based exclusively on multi-layer perceptrons (MLPs) have gained much attention in the computer vision community. MLP-like models achieve competitive performance on a single 2D image classification with less inductive bias without hand-crafted convolution layers. In this work, we explore the effectiveness of MLP-based architecture for the view-based 3D object recognition task. We present an MLP-based architecture termed as Round-Roll MLP (R$^2$-MLP). It extends the spatial-shift MLP backbone by considering the communications between patches from different views. R$^2$-MLP rolls part of the channels along the view dimension and promotes information exchange between neighboring views. We benchmark MLP results on ModelNet10 and ModelNet40 datasets with ablations in various aspects. The experimental results show that, with a conceptually simple structure, our R$^2$-MLP achieves competitive performance compared with existing state-of-the-art methods.
Learning to Search for Job Shop Scheduling via Deep Reinforcement Learning
Nov 20, 2022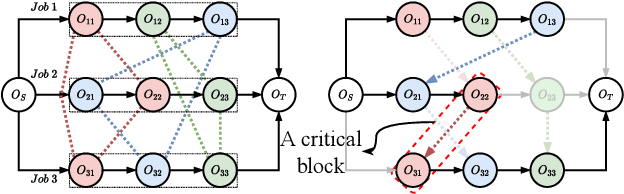
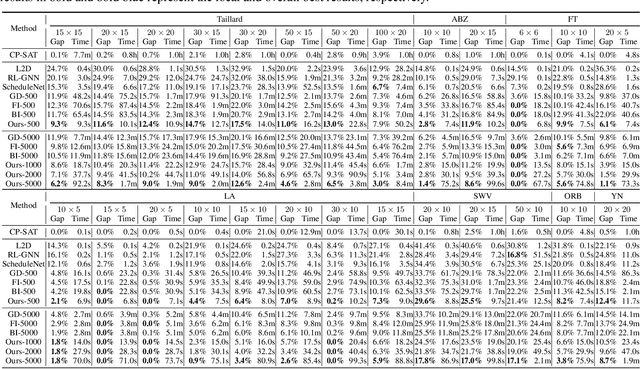
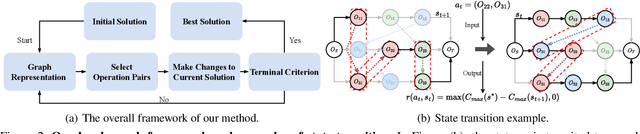

Recent studies in using deep reinforcement learning (DRL) to solve Job-shop scheduling problems (JSSP) focus on construction heuristics. However, their performance is still far from optimality, mainly because the underlying graph representation scheme is unsuitable for modeling partial solutions at each construction step. This paper proposes a novel DRL-based method to learn improvement heuristics for JSSP, where graph representation is employed to encode complete solutions. We design a Graph Neural Network based representation scheme, consisting of two modules to effectively capture the information of dynamic topology and different types of nodes in graphs encountered during the improvement process. To speed up solution evaluation during improvement, we design a novel message-passing mechanism that can evaluate multiple solutions simultaneously. Extensive experiments on classic benchmarks show that the improvement policy learned by our method outperforms state-of-the-art DRL-based methods by a large margin.
PointResNet: Residual Network for 3D Point Cloud Segmentation and Classification
Nov 20, 2022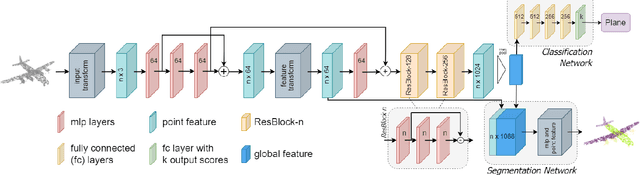
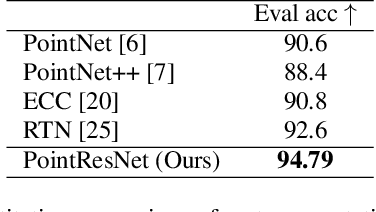

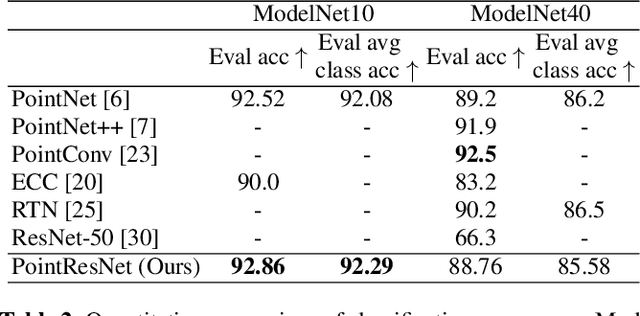
Point cloud segmentation and classification are some of the primary tasks in 3D computer vision with applications ranging from augmented reality to robotics. However, processing point clouds using deep learning-based algorithms is quite challenging due to the irregular point formats. Voxelization or 3D grid-based representation are different ways of applying deep neural networks to this problem. In this paper, we propose PointResNet, a residual block-based approach. Our model directly processes the 3D points, using a deep neural network for the segmentation and classification tasks. The main components of the architecture are: 1) residual blocks and 2) multi-layered perceptron (MLP). We show that it preserves profound features and structural information, which are useful for segmentation and classification tasks. The experimental evaluations demonstrate that the proposed model produces the best results for segmentation and comparable results for classification in comparison to the conventional baselines.
Chronic pain patient narratives allow for the estimation of current pain intensity
Nov 08, 2022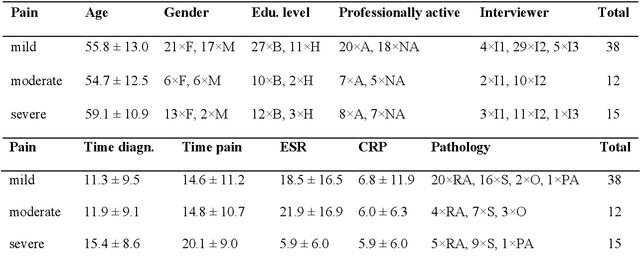
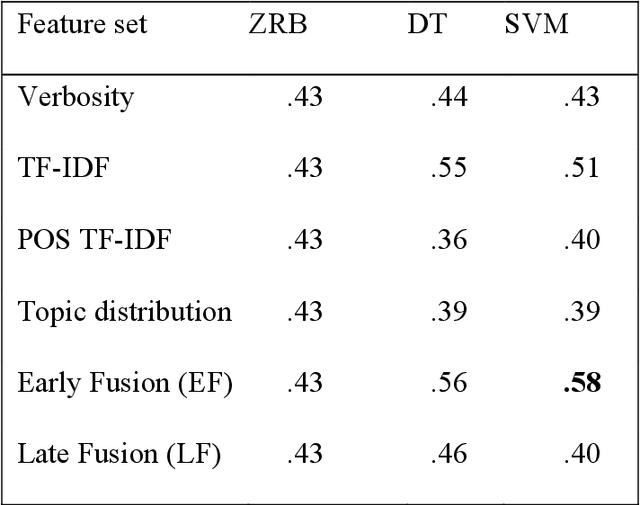

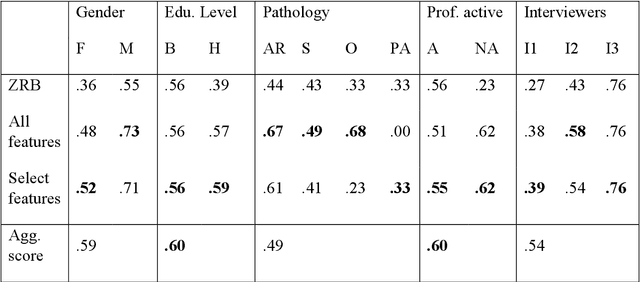
Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture this burden. Moreover, this type of tools is susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use it, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.