 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Hierarchical Variable Autonomy Mixed-Initiative Framework for Human-Robot Teaming in Mobile Robotics
Nov 25, 2022
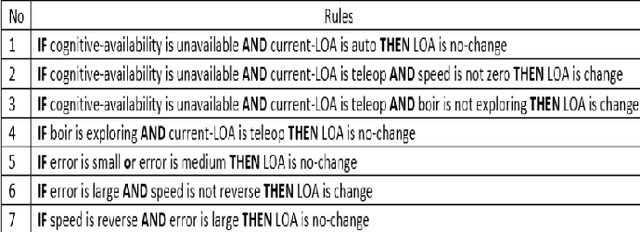
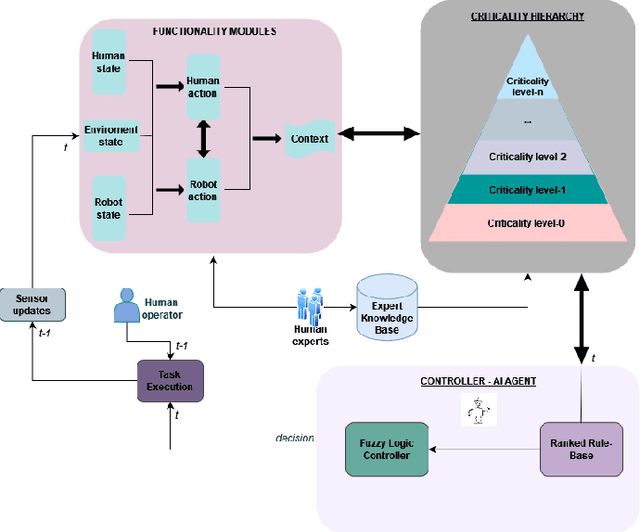
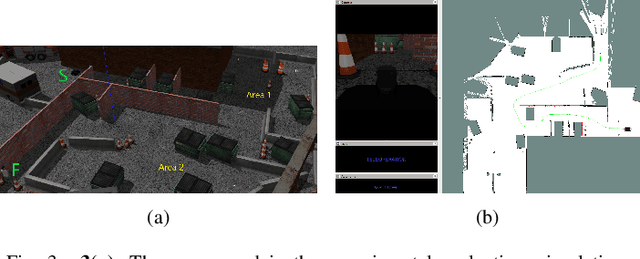
This paper presents a Mixed-Initiative (MI) framework for addressing the problem of control authority transfer between a remote human operator and an AI agent when cooperatively controlling a mobile robot. Our Hierarchical Expert-guided Mixed-Initiative Control Switcher (HierEMICS) leverages information on the human operator's state and intent. The control switching policies are based on a criticality hierarchy. An experimental evaluation was conducted in a high-fidelity simulated disaster response and remote inspection scenario, comparing HierEMICS with a state-of-the-art Expert-guided Mixed-Initiative Control Switcher (EMICS) in the context of mobile robot navigation. Results suggest that HierEMICS reduces conflicts for control between the human and the AI agent, which is a fundamental challenge in both the MI control paradigm and also in the related shared control paradigm. Additionally, we provide statistically significant evidence of improved, navigational safety (i.e., fewer collisions), LOA switching efficiency, and conflict for control reduction.
MUS-CDB: Mixed Uncertainty Sampling with Class Distribution Balancing for Active Annotation in Aerial Object Detection
Dec 06, 2022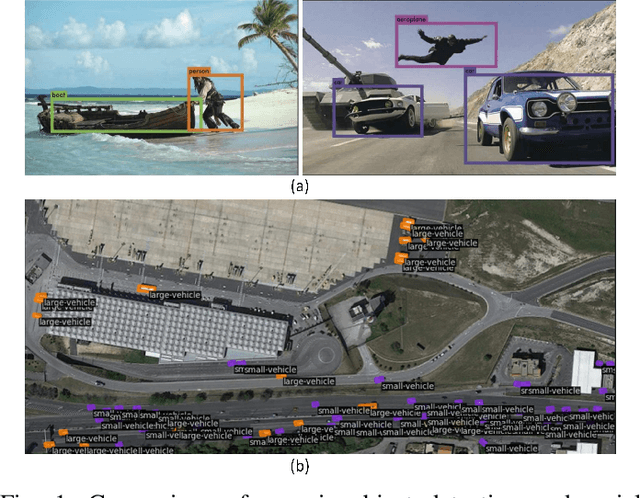

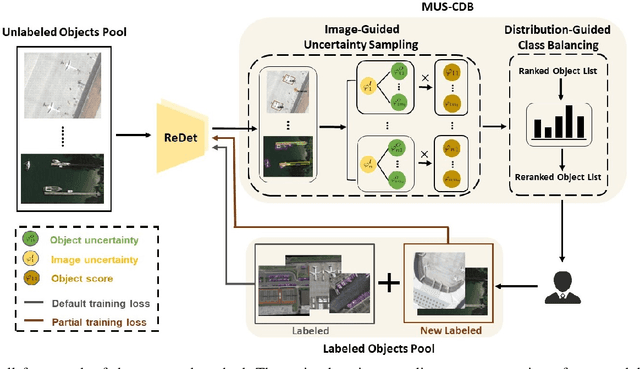
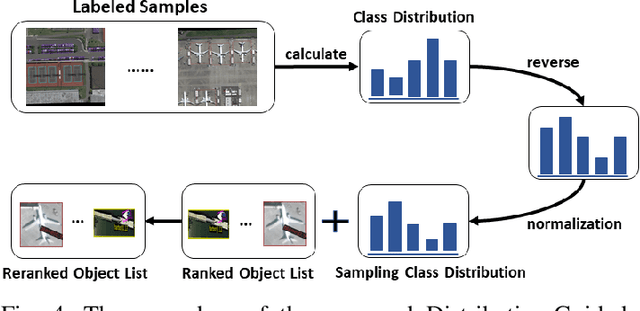
Recent aerial object detection models rely on a large amount of labeled training data, which requires unaffordable manual labeling costs in large aerial scenes with dense objects. Active learning is effective in reducing the data labeling cost by selectively querying the informative and representative unlabelled samples. However, existing active learning methods are mainly with class-balanced setting and image-based querying for generic object detection tasks, which are less applicable to aerial object detection scenario due to the long-tailed class distribution and dense small objects in aerial scenes. In this paper, we propose a novel active learning method for cost-effective aerial object detection. Specifically, both object-level and image-level informativeness are considered in the object selection to refrain from redundant and myopic querying. Besides, an easy-to-use class-balancing criterion is incorporated to favor the minority objects to alleviate the long-tailed class distribution problem in model training. To fully utilize the queried information, we further devise a training loss to mine the latent knowledge in the undiscovered image regions. Extensive experiments are conducted on the DOTA-v1.0 and DOTA-v2.0 benchmarks to validate the effectiveness of the proposed method. The results show that it can save more than 75% of the labeling cost to reach the same performance compared to the baselines and state-of-the-art active object detection methods. Code is available at https://github.com/ZJW700/MUS-CDB
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Dec 06, 2022
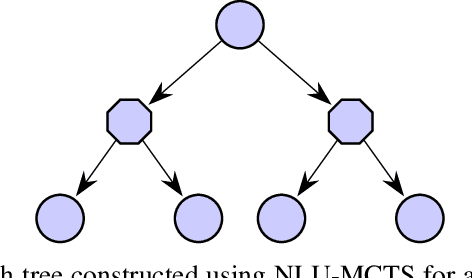
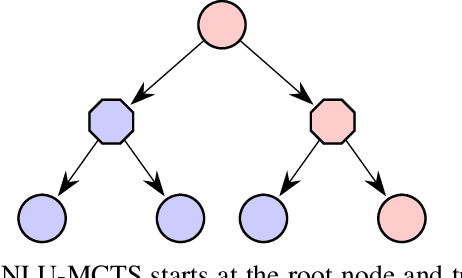
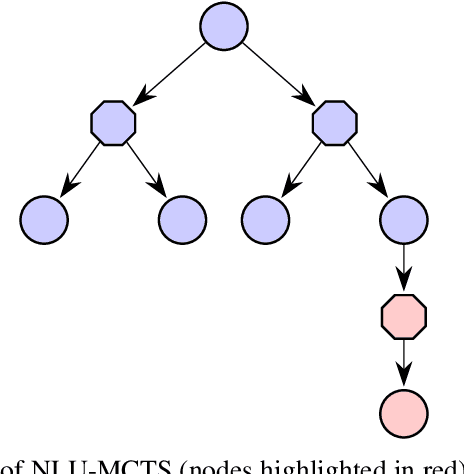
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Search in Imperfect Information Games
Nov 10, 2021

From the very dawn of the field, search with value functions was a fundamental concept of computer games research. Turing's chess algorithm from 1950 was able to think two moves ahead, and Shannon's work on chess from $1950$ includes an extensive section on evaluation functions to be used within a search. Samuel's checkers program from 1959 already combines search and value functions that are learned through self-play and bootstrapping. TD-Gammon improves upon those ideas and uses neural networks to learn those complex value functions -- only to be again used within search. The combination of decision-time search and value functions has been present in the remarkable milestones where computers bested their human counterparts in long standing challenging games -- DeepBlue for Chess and AlphaGo for Go. Until recently, this powerful framework of search aided with (learned) value functions has been limited to perfect information games. As many interesting problems do not provide the agent perfect information of the environment, this was an unfortunate limitation. This thesis introduces the reader to sound search for imperfect information games.
A Complete Criterion for Value of Information in Soluble Influence Diagrams
Feb 23, 2022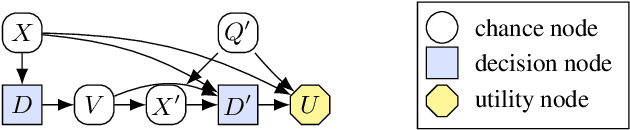
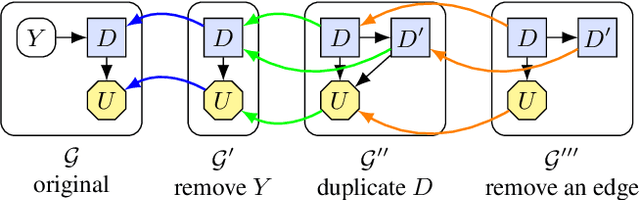
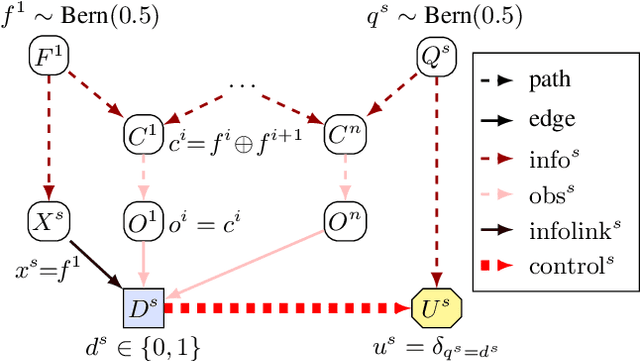
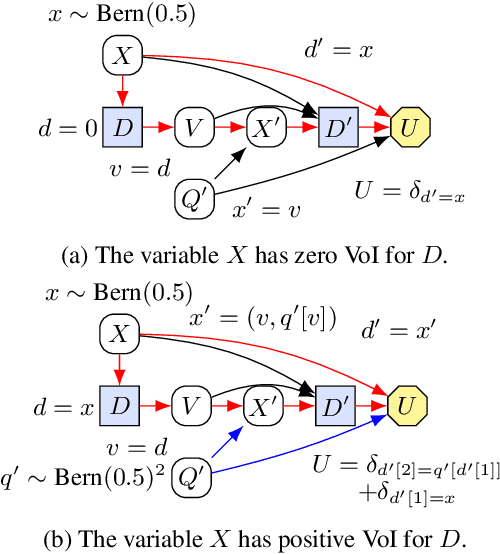
Influence diagrams have recently been used to analyse the safety and fairness properties of AI systems. A key building block for this analysis is a graphical criterion for value of information (VoI). This paper establishes the first complete graphical criterion for VoI in influence diagrams with multiple decisions. Along the way, we establish two important techniques for proving properties of multi-decision influence diagrams: ID homomorphisms are structure-preserving transformations of influence diagrams, while a Tree of Systems is collection of paths that captures how information and control can flow in an influence diagram.
Local Contrastive Feature learning for Tabular Data
Nov 19, 2022
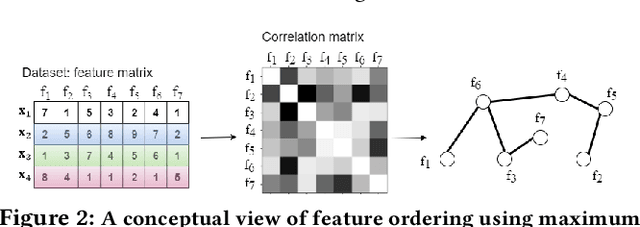
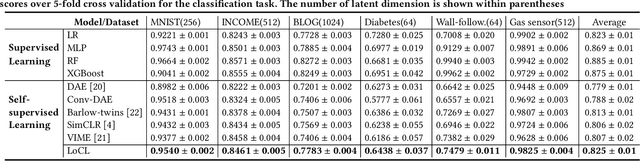
Contrastive self-supervised learning has been successfully used in many domains, such as images, texts, graphs, etc., to learn features without requiring label information. In this paper, we propose a new local contrastive feature learning (LoCL) framework, and our theme is to learn local patterns/features from tabular data. In order to create a niche for local learning, we use feature correlations to create a maximum-spanning tree, and break the tree into feature subsets, with strongly correlated features being assigned next to each other. Convolutional learning of the features is used to learn latent feature space, regulated by contrastive and reconstruction losses. Experiments on public tabular datasets show the effectiveness of the proposed method versus state-of-the-art baseline methods.
Topic Modeling on Clinical Social Work Notes for Exploring Social Determinants of Health Factors
Dec 02, 2022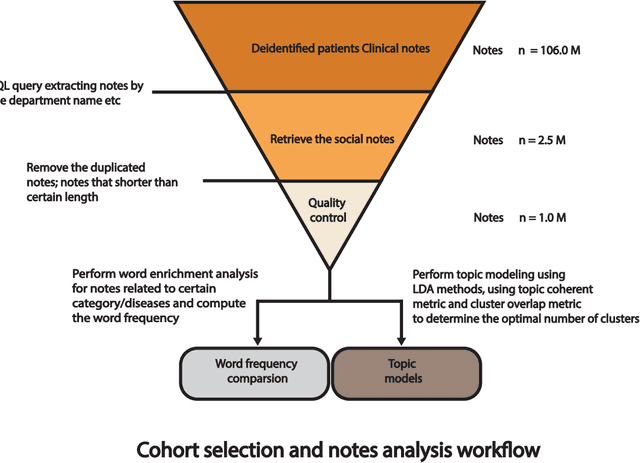
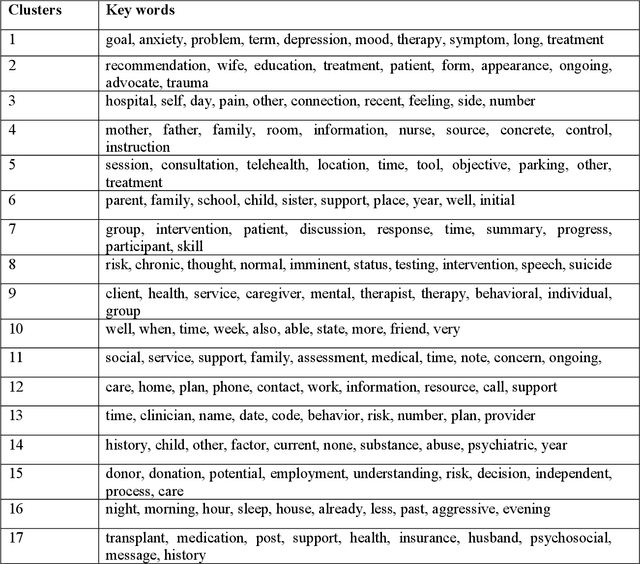
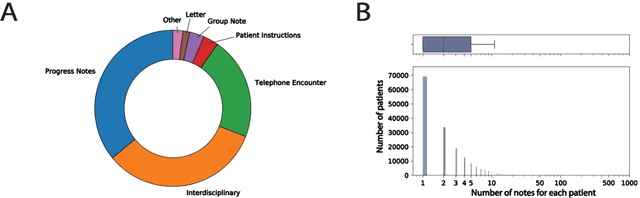
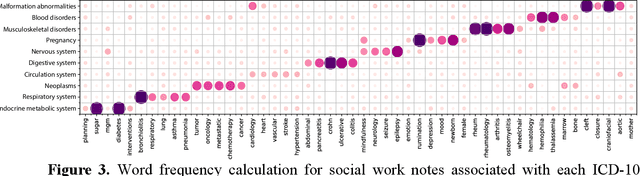
Most research studying social determinants of health (SDoH) has focused on physician notes or structured elements of the electronic medical record (EMR). We hypothesize that clinical notes from social workers, whose role is to ameliorate social and economic factors, might provide a richer source of data on SDoH. We sought to perform topic modeling to identify robust topics of discussion within a large cohort of social work notes. We retrieved a diverse, deidentified corpus of 0.95 million clinical social work notes from 181,644 patients at the University of California, San Francisco. We used word frequency analysis and Latent Dirichlet Allocation (LDA) topic modeling analysis to characterize this corpus and identify potential topics of discussion. Word frequency analysis identified both medical and non-medical terms associated with specific ICD10 chapters. The LDA topic modeling analysis extracted 11 topics related to social determinants of health risk factors including financial status, abuse history, social support, risk of death, and mental health. In addition, the topic modeling approach captured the variation between different types of social work notes and across patients with different types of diseases or conditions. We demonstrated that social work notes contain rich, unique, and otherwise unobtainable information on an individual's SDoH.
Joint Open Knowledge Base Canonicalization and Linking
Dec 02, 2022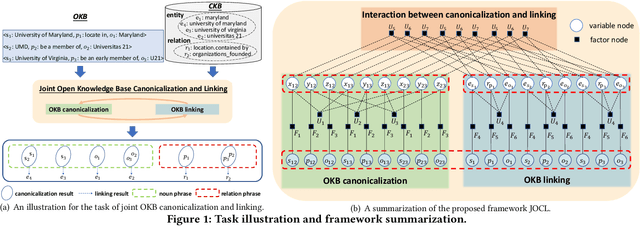
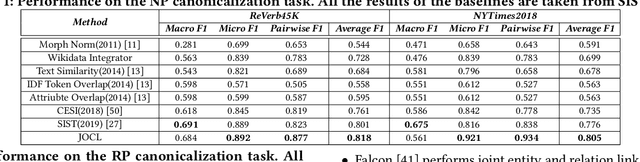
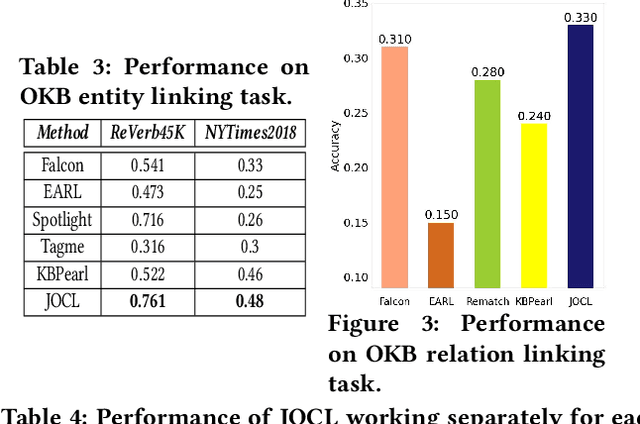
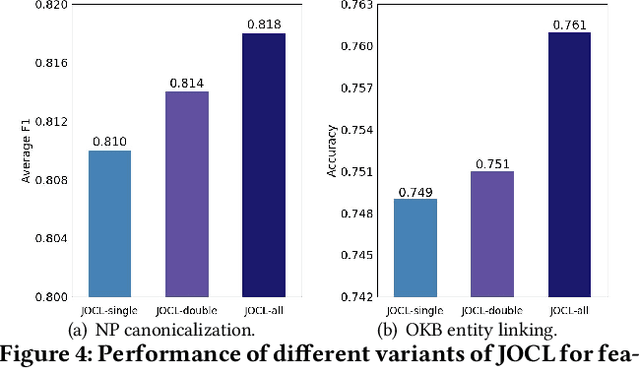
Open Information Extraction (OIE) methods extract a large number of OIE triples (noun phrase, relation phrase, noun phrase) from text, which compose large Open Knowledge Bases (OKBs). However, noun phrases (NPs) and relation phrases (RPs) in OKBs are not canonicalized and often appear in different paraphrased textual variants, which leads to redundant and ambiguous facts. To address this problem, there are two related tasks: OKB canonicalization (i.e., convert NPs and RPs to canonicalized form) and OKB linking (i.e., link NPs and RPs with their corresponding entities and relations in a curated Knowledge Base (e.g., DBPedia). These two tasks are tightly coupled, and one task can benefit significantly from the other. However, they have been studied in isolation so far. In this paper, we explore the task of joint OKB canonicalization and linking for the first time, and propose a novel framework JOCL based on factor graph model to make them reinforce each other. JOCL is flexible enough to combine different signals from both tasks, and able to extend to fit any new signals. A thorough experimental study over two large scale OIE triple data sets shows that our framework outperforms all the baseline methods for the task of OKB canonicalization (OKB linking) in terms of average F1 (accuracy).
Towards Diverse, Relevant and Coherent Open-Domain Dialogue Generation via Hybrid Latent Variables
Dec 02, 2022

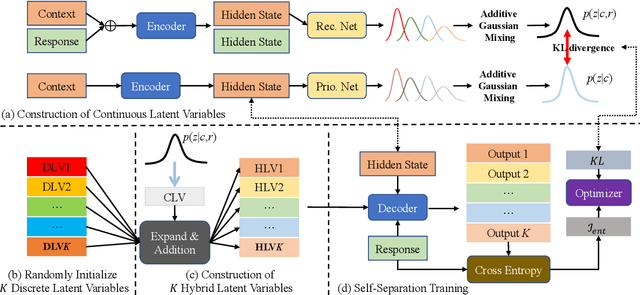
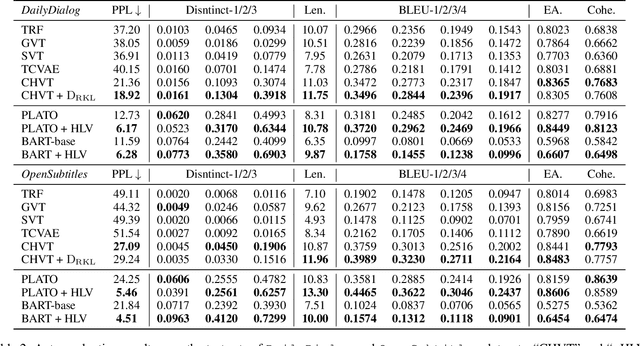
Conditional variational models, using either continuous or discrete latent variables, are powerful for open-domain dialogue response generation. However, previous works show that continuous latent variables tend to reduce the coherence of generated responses. In this paper, we also found that discrete latent variables have difficulty capturing more diverse expressions. To tackle these problems, we combine the merits of both continuous and discrete latent variables and propose a Hybrid Latent Variable (HLV) method. Specifically, HLV constrains the global semantics of responses through discrete latent variables and enriches responses with continuous latent variables. Thus, we diversify the generated responses while maintaining relevance and coherence. In addition, we propose Conditional Hybrid Variational Transformer (CHVT) to construct and to utilize HLV with transformers for dialogue generation. Through fine-grained symbolic-level semantic information and additive Gaussian mixing, we construct the distribution of continuous variables, prompting the generation of diverse expressions. Meanwhile, to maintain the relevance and coherence, the discrete latent variable is optimized by self-separation training. Experimental results on two dialogue generation datasets (DailyDialog and Opensubtitles) show that CHVT is superior to traditional transformer-based variational mechanism w.r.t. diversity, relevance and coherence metrics. Moreover, we also demonstrate the benefit of applying HLV to fine-tuning two pre-trained dialogue models (PLATO and BART-base).
Variational Bayes for Joint Channel Estimation and Data Detection in Few-Bit Massive MIMO Systems
Dec 04, 2022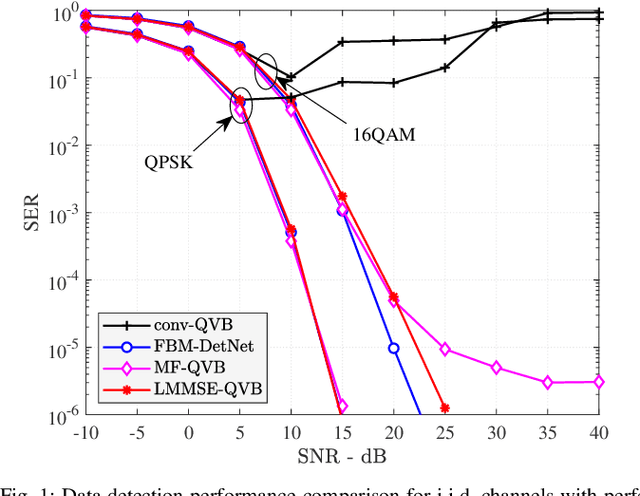
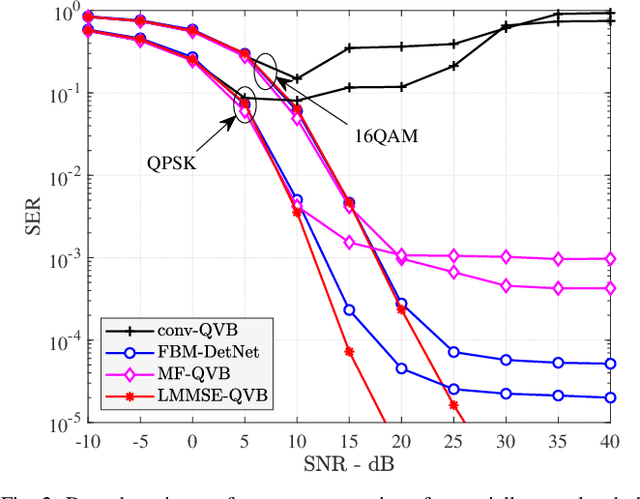
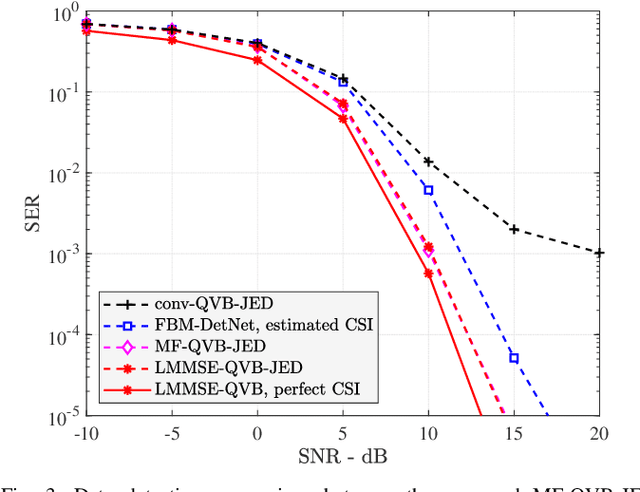
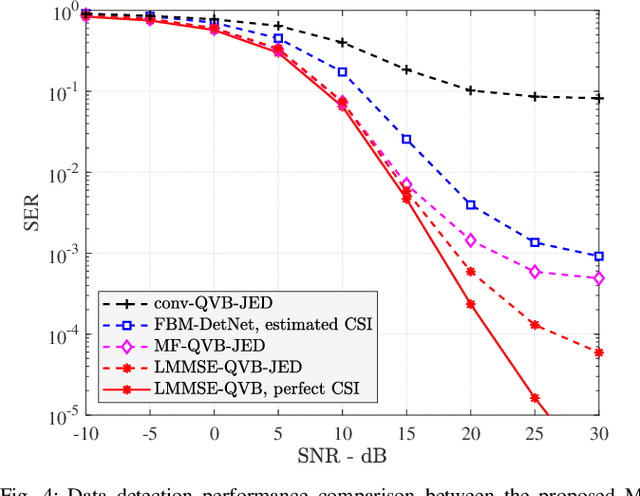
Massive multiple-input multiple-output (MIMO) communications using low-resolution analog-to-digital converters (ADCs) is a promising technology for providing high spectral and energy efficiency with affordable hardware cost and power consumption. However, the use of low-resolution ADCs requires special signal processing methods for channel estimation and data detection since the resulting system is severely non-linear. This paper proposes joint channel estimation and data detection methods for massive MIMO systems with low-resolution ADCs based on the variational Bayes (VB) inference framework. We first derive matched-filter quantized VB (MF-QVB) and linear minimum mean-squared error quantized VB (LMMSE-QVB) detection methods assuming the channel state information (CSI) is available. Then we extend these methods to the joint channel estimation and data detection (JED) problem and propose two methods we refer to as MF-QVB-JED and LMMSE-QVB-JED. Unlike conventional VB-based detection methods that assume knowledge of the second-order statistics of the additive noise, we propose to float the noise variance/covariance matrix as an unknown random variable that is used to account for both the noise and the residual inter-user interference. We also present practical aspects of the QVB framework to improve its implementation stability. Finally, we show via numerical results that the proposed VB-based methods provide robust performance and also significantly outperform existing methods.