 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Telemetry: Turn-Level Instrumentation for Autonomous Information Gathering
Jan 14, 2026Autonomous systems conducting schema-grounded information-gathering dialogues face an instrumentation gap, lacking turn-level observables for monitoring acquisition efficiency and detecting when questioning becomes unproductive. We introduce Dialogue Telemetry (DT), a measurement framework that produces two model-agnostic signals after each question-answer exchange: (i) a Progress Estimator (PE) quantifying residual information potential per category (with a bits-based variant), and (ii) a Stalling Index (SI) detecting an observable failure signature characterized by repeated category probing with semantically similar, low-marginal-gain responses. SI flags this pattern without requiring causal diagnosis, supporting monitoring in settings where attributing degradation to specific causes may be impractical. We validate DT in controlled search-and-rescue (SAR)-inspired interviews using large language model (LLM)-based simulations, distinguishing efficient from stalled dialogue traces and illustrating downstream utility by integrating DT signals into a reinforcement learning (RL) policy. Across these settings, DT provides interpretable turn-level instrumentation that improves policy performance when stalling carries operational costs.
LUCIFER: Language Understanding and Context-Infused Framework for Exploration and Behavior Refinement
Jun 09, 2025



In dynamic environments, the rapid obsolescence of pre-existing environmental knowledge creates a gap between an agent's internal model and the evolving reality of its operational context. This disparity between prior and updated environmental valuations fundamentally limits the effectiveness of autonomous decision-making. To bridge this gap, the contextual bias of human domain stakeholders, who naturally accumulate insights through direct, real-time observation, becomes indispensable. However, translating their nuanced, and context-rich input into actionable intelligence for autonomous systems remains an open challenge. To address this, we propose LUCIFER (Language Understanding and Context-Infused Framework for Exploration and Behavior Refinement), a domain-agnostic framework that integrates a hierarchical decision-making architecture with reinforcement learning (RL) and large language models (LLMs) into a unified system. This architecture mirrors how humans decompose complex tasks, enabling a high-level planner to coordinate specialised sub-agents, each focused on distinct objectives and temporally interdependent actions. Unlike traditional applications where LLMs are limited to single role, LUCIFER integrates them in two synergistic roles: as context extractors, structuring verbal stakeholder input into domain-aware representations that influence decision-making through an attention space mechanism aligning LLM-derived insights with the agent's learning process, and as zero-shot exploration facilitators guiding the agent's action selection process during exploration. We benchmark various LLMs in both roles and demonstrate that LUCIFER improves exploration efficiency and decision quality, outperforming flat, goal-conditioned policies. Our findings show the potential of context-driven decision-making, where autonomous systems leverage human contextual knowledge for operational success.
Learning What Matters Now: A Dual-Critic Context-Aware RL Framework for Priority-Driven Information Gain
Jun 07, 2025



Autonomous systems operating in high-stakes search-and-rescue (SAR) missions must continuously gather mission-critical information while flexibly adapting to shifting operational priorities. We propose CA-MIQ (Context-Aware Max-Information Q-learning), a lightweight dual-critic reinforcement learning (RL) framework that dynamically adjusts its exploration strategy whenever mission priorities change. CA-MIQ pairs a standard extrinsic critic for task reward with an intrinsic critic that fuses state-novelty, information-location awareness, and real-time priority alignment. A built-in shift detector triggers transient exploration boosts and selective critic resets, allowing the agent to re-focus after a priority revision. In a simulated SAR grid-world, where experiments specifically test adaptation to changes in the priority order of information types the agent is expected to focus on, CA-MIQ achieves nearly four times higher mission-success rates than baselines after a single priority shift and more than three times better performance in multiple-shift scenarios, achieving 100% recovery while baseline methods fail to adapt. These results highlight CA-MIQ's effectiveness in any discrete environment with piecewise-stationary information-value distributions.
A Supervised Machine Learning Approach to Operator Intent Recognition for Teleoperated Mobile Robot Navigation
Apr 27, 2023In applications that involve human-robot interaction (HRI), human-robot teaming (HRT), and cooperative human-machine systems, the inference of the human partner's intent is of critical importance. This paper presents a method for the inference of the human operator's navigational intent, in the context of mobile robots that provide full or partial (e.g., shared control) teleoperation. We propose the Machine Learning Operator Intent Inference (MLOII) method, which a) processes spatial data collected by the robot's sensors; b) utilizes a supervised machine learning algorithm to estimate the operator's most probable navigational goal online. The proposed method's ability to reliably and efficiently infer the intent of the human operator is experimentally evaluated in realistically simulated exploration and remote inspection scenarios. The results in terms of accuracy and uncertainty indicate that the proposed method is comparable to another state-of-the-art method found in the literature.
A Hierarchical Variable Autonomy Mixed-Initiative Framework for Human-Robot Teaming in Mobile Robotics
Nov 25, 2022


This paper presents a Mixed-Initiative (MI) framework for addressing the problem of control authority transfer between a remote human operator and an AI agent when cooperatively controlling a mobile robot. Our Hierarchical Expert-guided Mixed-Initiative Control Switcher (HierEMICS) leverages information on the human operator's state and intent. The control switching policies are based on a criticality hierarchy. An experimental evaluation was conducted in a high-fidelity simulated disaster response and remote inspection scenario, comparing HierEMICS with a state-of-the-art Expert-guided Mixed-Initiative Control Switcher (EMICS) in the context of mobile robot navigation. Results suggest that HierEMICS reduces conflicts for control between the human and the AI agent, which is a fundamental challenge in both the MI control paradigm and also in the related shared control paradigm. Additionally, we provide statistically significant evidence of improved, navigational safety (i.e., fewer collisions), LOA switching efficiency, and conflict for control reduction.
A Bayesian-Based Approach to Human Operator Intent Recognition in Remote Mobile Robot Navigation
Sep 24, 2021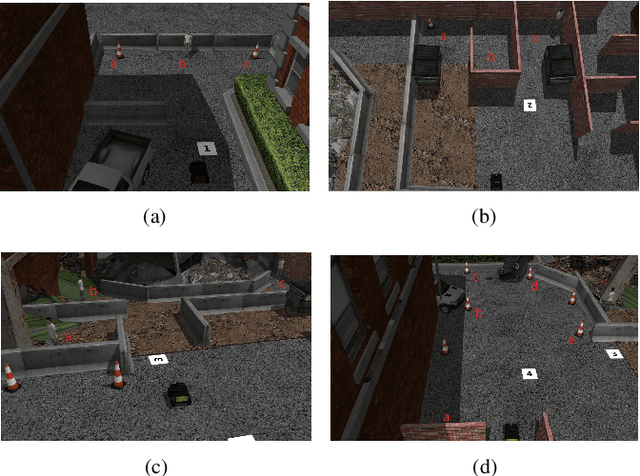
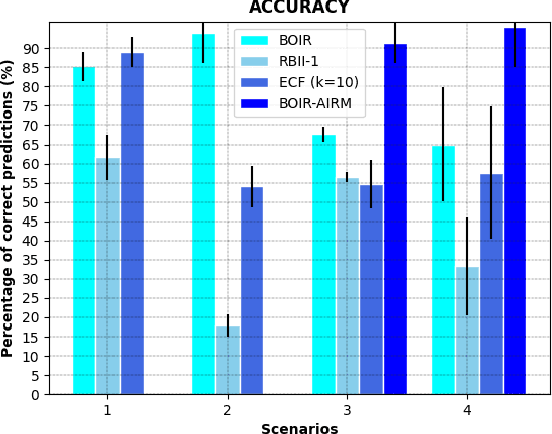
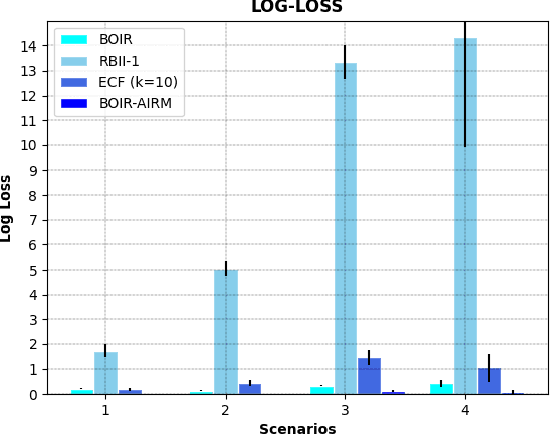
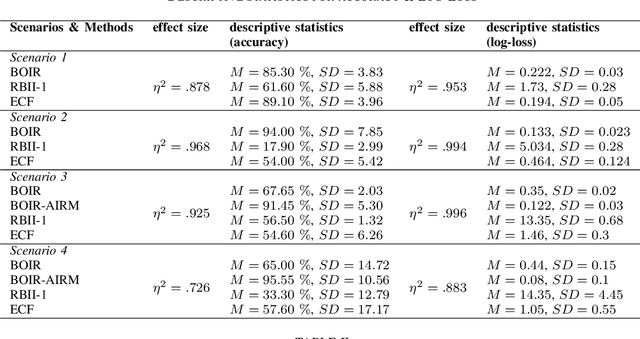
This paper addresses the problem of human operator intent recognition during teleoperated robot navigation. In this context, recognition of the operator's intended navigational goal, could enable an artificial intelligence (AI) agent to assist the operator in an advanced human-robot interaction framework. We propose a Bayesian Operator Intent Recognition (BOIR) probabilistic method that utilizes: (i) an observation model that fuses information as a weighting combination of multiple observation sources providing geometric information; (ii) a transition model that indicates the evolution of the state; and (iii) an action model, the Active Intent Recognition Model (AIRM), that enables the operator to communicate their explicit intent asynchronously. The proposed method is evaluated in an experiment where operators controlling a remote mobile robot are tasked with navigation and exploration under various scenarios with different map and obstacle layouts. Results demonstrate that BOIR outperforms two related methods from literature in terms of accuracy and uncertainty of the intent recognition.