 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic and Distributed Optimization for the Allocation of Aerial Swarm Vehicles
Nov 30, 2022
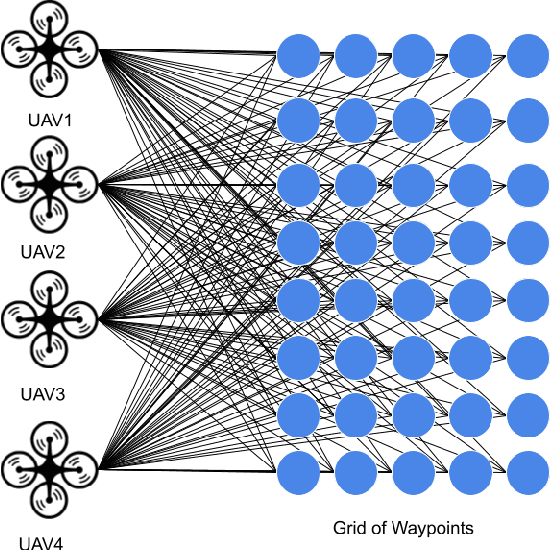
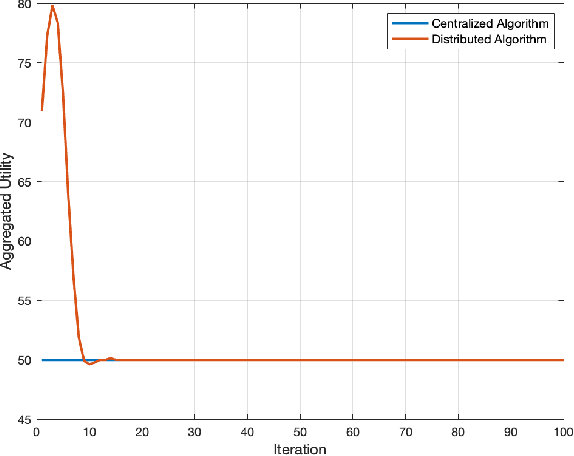
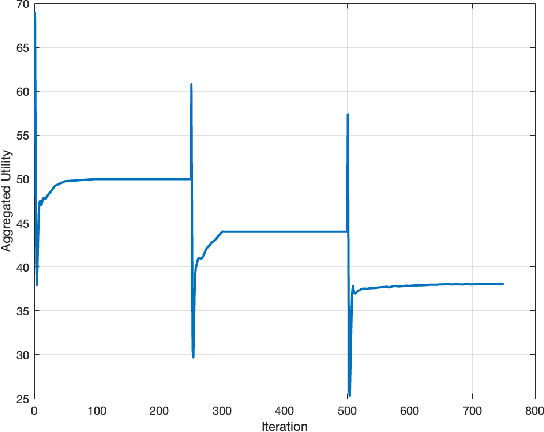
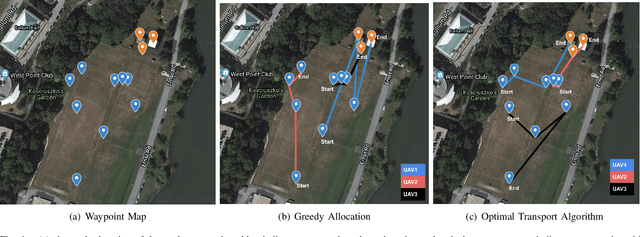
Optimal transport (OT) is a framework that can guide the design of efficient resource allocation strategies in a network of multiple sources and targets. This paper applies discrete OT to a swarm of UAVs in a novel way to achieve appropriate task allocation and execution. Drone swarm deployments already operate in multiple domains where sensors are used to gain knowledge of an environment [1]. Use cases such as, chemical and radiation detection, and thermal and RGB imaging create a specific need for an algorithm that considers parameters on both the UAV and waypoint side and allows for updating the matching scheme as the swarm gains information from the environment. Additionally, the need for a centralized planner can be removed by using a distributed algorithm that can dynamically update based on changes in the swarm network or parameters. To this end, we develop a dynamic and distributed OT algorithm that matches a UAV to the optimal waypoint based on one parameter at the UAV and another parameter at the waypoint. We show the convergence and allocation of the algorithm through a case study and test the algorithm's effectiveness against a greedy assignment algorithm in simulation.
Random Copolymer inverse design system orienting on Accurate discovering of Antimicrobial peptide-mimetic copolymers
Nov 30, 2022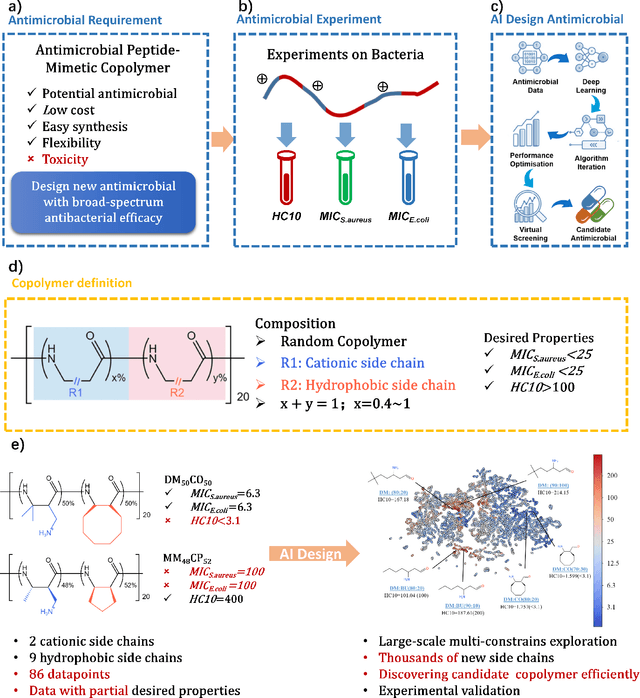
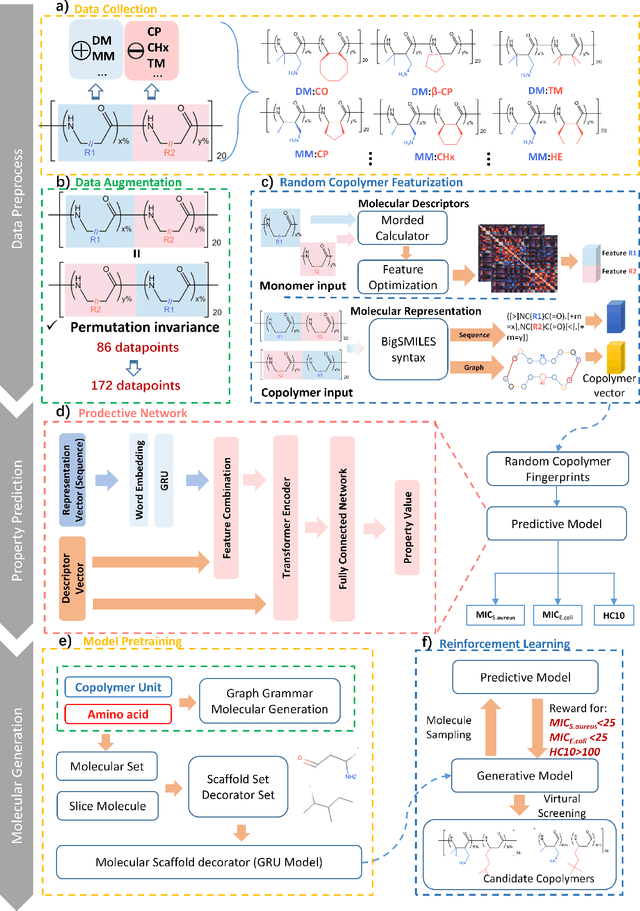
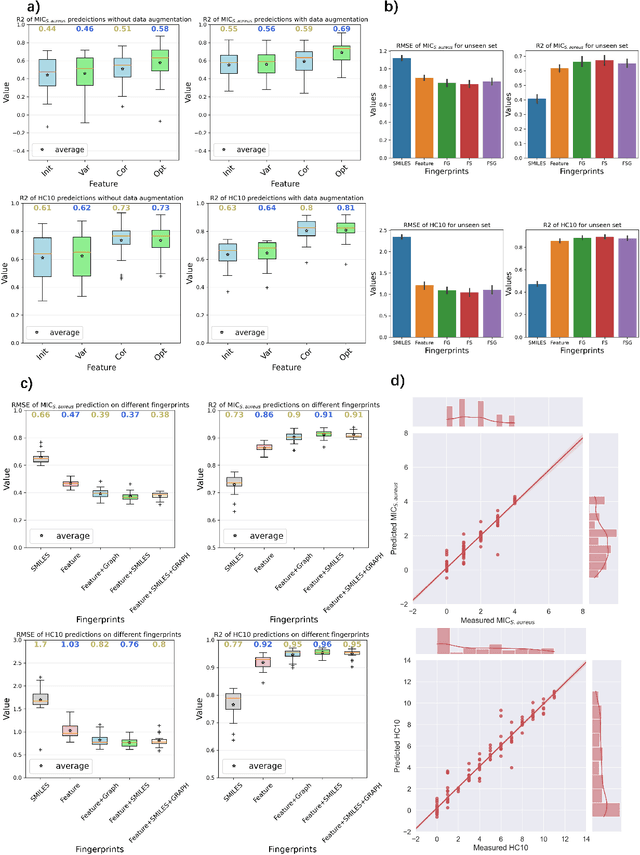
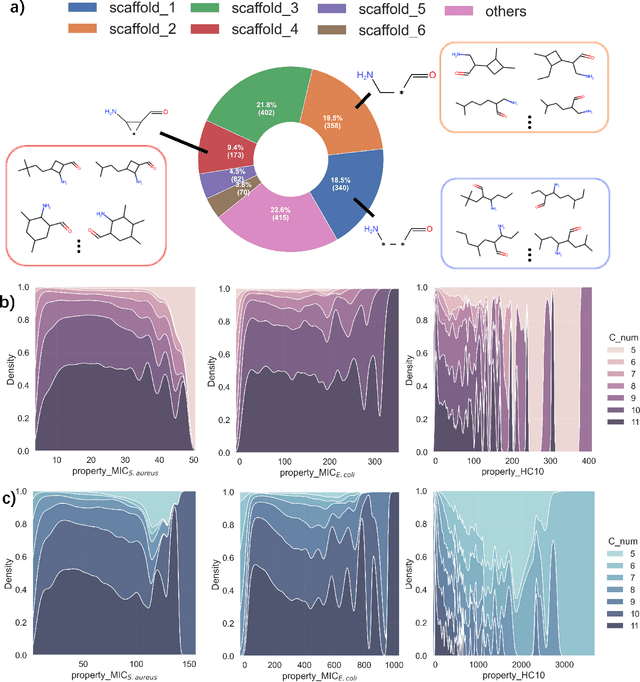
Antimicrobial resistance is one of the biggest health problem, especially in the current period of COVID-19 pandemic. Due to the unique membrane-destruction bactericidal mechanism, antimicrobial peptide-mimetic copolymers are paid more attention and it is urgent to find more potential candidates with broad-spectrum antibacterial efficacy and low toxicity. Artificial intelligence has shown significant performance on small molecule or biotech drugs, however, the higher-dimension of polymer space and the limited experimental data restrict the application of existing methods on copolymer design. Herein, we develop a universal random copolymer inverse design system via multi-model copolymer representation learning, knowledge distillation and reinforcement learning. Our system realize a high-precision antimicrobial activity prediction with few-shot data by extracting various chemical information from multi-modal copolymer representations. By pre-training a scaffold-decorator generative model via knowledge distillation, copolymer space are greatly contracted to the near space of existing data for exploration. Thus, our reinforcement learning algorithm can be adaptive for customized generation on specific scaffolds and requirements on property or structures. We apply our system on collected antimicrobial peptide-mimetic copolymers data, and we discover candidate copolymers with desired properties.
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models
Nov 30, 2022

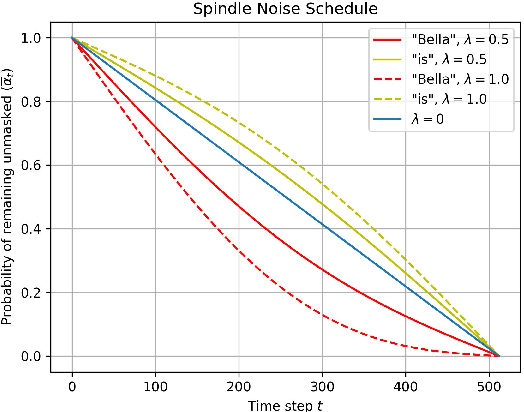
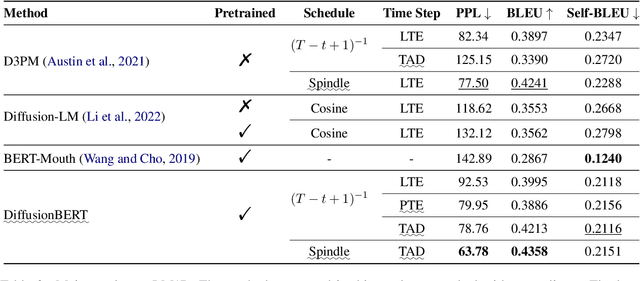
We present DiffusionBERT, a new generative masked language model based on discrete diffusion models. Diffusion models and many pre-trained language models have a shared training objective, i.e., denoising, making it possible to combine the two powerful models and enjoy the best of both worlds. On the one hand, diffusion models offer a promising training strategy that helps improve the generation quality. On the other hand, pre-trained denoising language models (e.g., BERT) can be used as a good initialization that accelerates convergence. We explore training BERT to learn the reverse process of a discrete diffusion process with an absorbing state and elucidate several designs to improve it. First, we propose a new noise schedule for the forward diffusion process that controls the degree of noise added at each step based on the information of each token. Second, we investigate several designs of incorporating the time step into BERT. Experiments on unconditional text generation demonstrate that DiffusionBERT achieves significant improvement over existing diffusion models for text (e.g., D3PM and Diffusion-LM) and previous generative masked language models in terms of perplexity and BLEU score.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022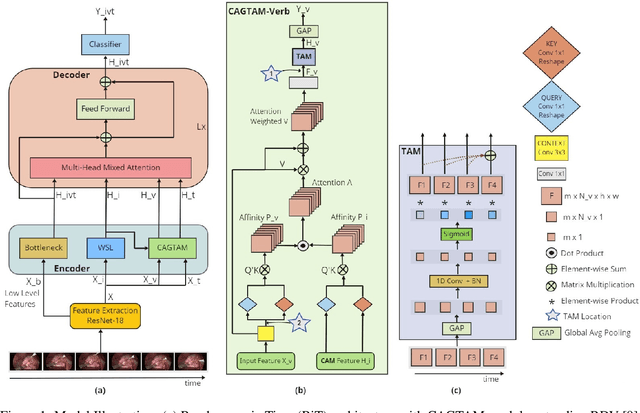

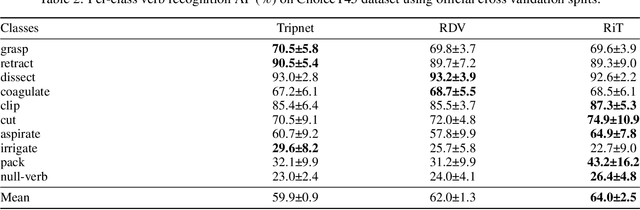
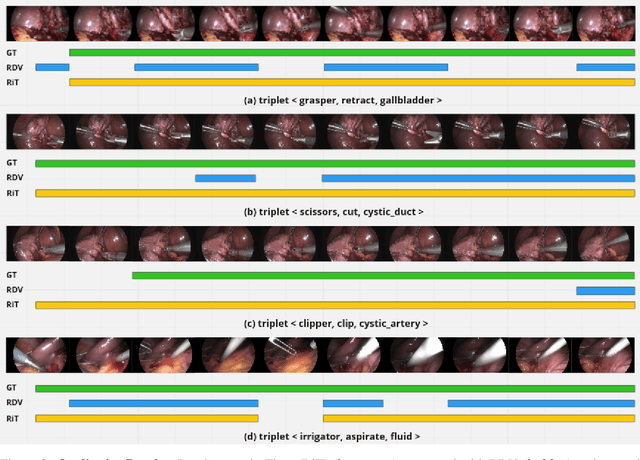
One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
A data set providing synthetic and real-world fisheye video sequences
Nov 30, 2022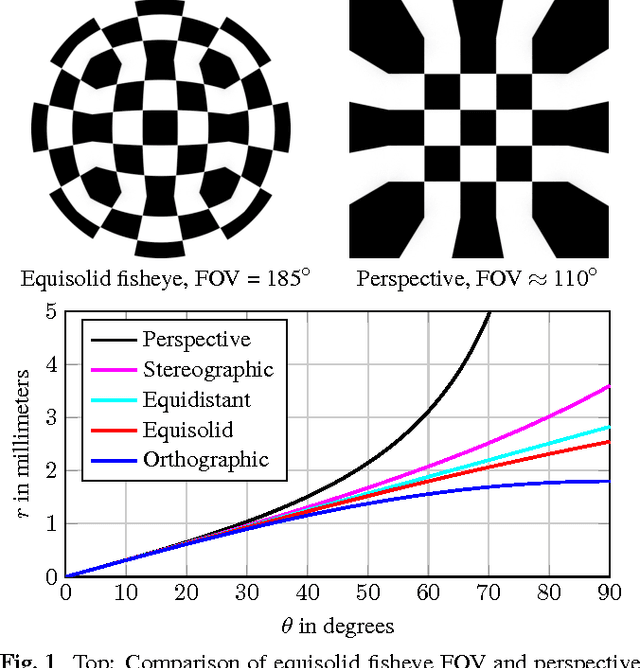
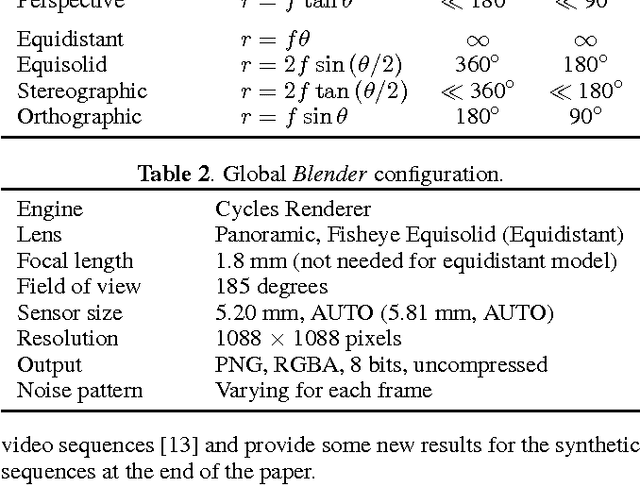

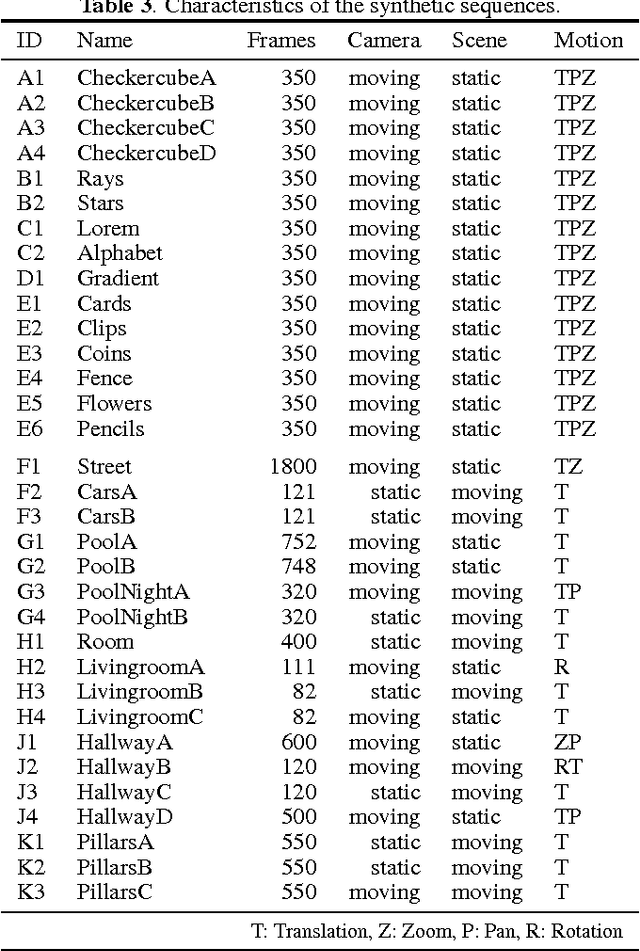
In video surveillance as well as automotive applications, so-called fisheye cameras are often employed to capture a very wide angle of view. As such cameras depend on projections quite different from the classical perspective projection, the resulting fisheye image and video data correspondingly exhibits non-rectilinear image characteristics. Typical image and video processing algorithms, however, are not designed for these fisheye characteristics. To be able to develop and evaluate algorithms specifically adapted to fisheye images and videos, a corresponding test data set is therefore introduced in this paper. The first of those sequences were generated during the authors' own work on motion estimation for fish-eye videos and further sequences have gradually been added to create a more extensive collection. The data set now comprises synthetically generated fisheye sequences, ranging from simple patterns to more complex scenes, as well as fisheye video sequences captured with an actual fisheye camera. For the synthetic sequences, exact information on the lens employed is available, thus facilitating both verification and evaluation of any adapted algorithms. For the real-world sequences, we provide calibration data as well as the settings used during acquisition. The sequences are freely available via www.lms.lnt.de/fisheyedataset/.
Self-Supervised Feature Learning for Long-Term Metric Visual Localization
Nov 30, 2022
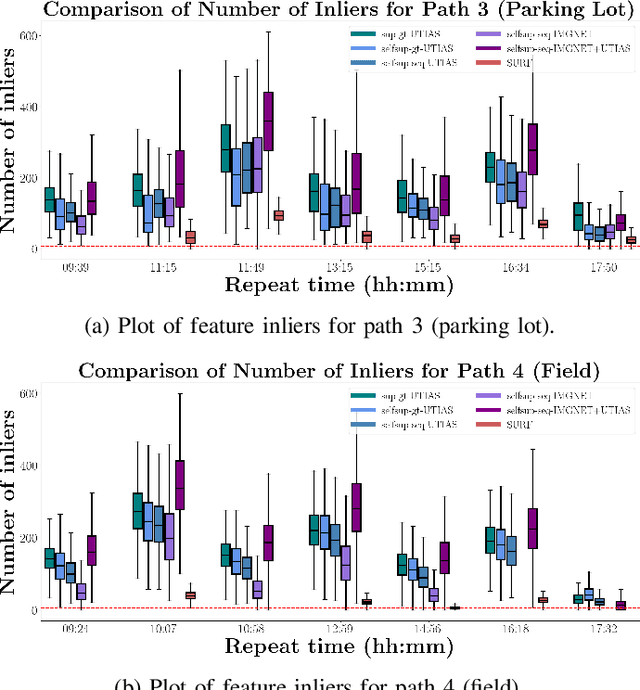
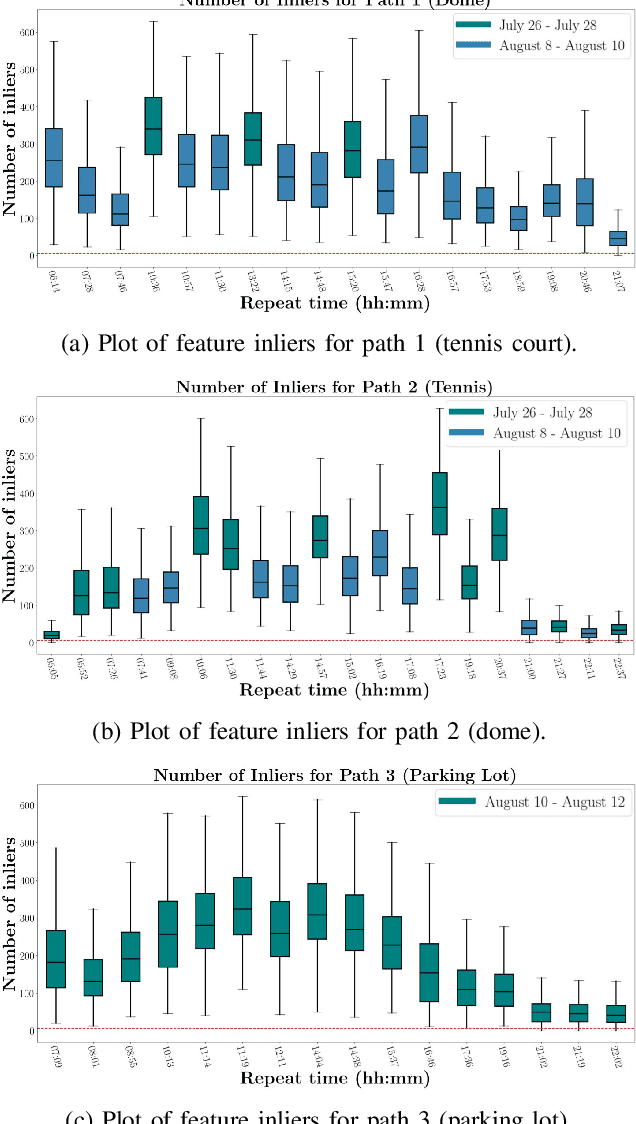
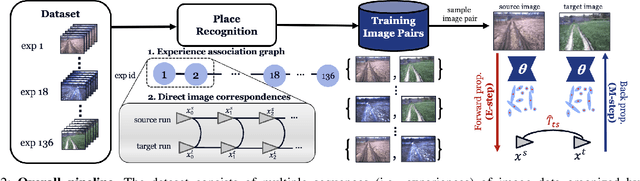
Visual localization is the task of estimating camera pose in a known scene, which is an essential problem in robotics and computer vision. However, long-term visual localization is still a challenge due to the environmental appearance changes caused by lighting and seasons. While techniques exist to address appearance changes using neural networks, these methods typically require ground-truth pose information to generate accurate image correspondences or act as a supervisory signal during training. In this paper, we present a novel self-supervised feature learning framework for metric visual localization. We use a sequence-based image matching algorithm across different sequences of images (i.e., experiences) to generate image correspondences without ground-truth labels. We can then sample image pairs to train a deep neural network that learns sparse features with associated descriptors and scores without ground-truth pose supervision. The learned features can be used together with a classical pose estimator for visual stereo localization. We validate the learned features by integrating with an existing Visual Teach & Repeat pipeline to perform closed-loop localization experiments under different lighting conditions for a total of 22.4 km.
Incremental Fourier Neural Operator
Nov 30, 2022
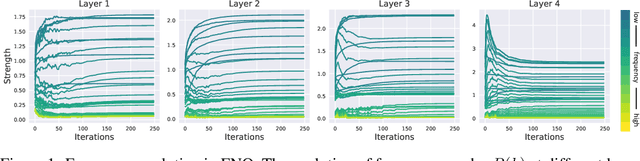

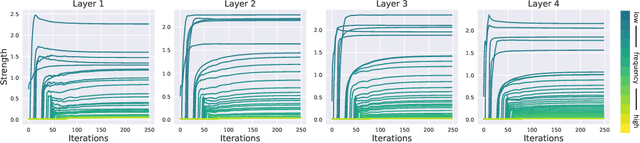
Recently, neural networks have proven their impressive ability to solve partial differential equations (PDEs). Among them, Fourier neural operator (FNO) has shown success in learning solution operators for highly non-linear problems such as turbulence flow. FNO is discretization-invariant, where it can be trained on low-resolution data and generalizes to problems with high-resolution. This property is related to the low-pass filters in FNO, where only a limited number of frequency modes are selected to propagate information. However, it is still a challenge to select an appropriate number of frequency modes and training resolution for different PDEs. Too few frequency modes and low-resolution data hurt generalization, while too many frequency modes and high-resolution data are computationally expensive and lead to over-fitting. To this end, we propose Incremental Fourier Neural Operator (IFNO), which augments both the frequency modes and data resolution incrementally during training. We show that IFNO achieves better generalization (around 15% reduction on testing L2 loss) while reducing the computational cost by 35%, compared to the standard FNO. In addition, we observe that IFNO follows the behavior of implicit regularization in FNO, which explains its excellent generalization ability.
Explainable Artificial Intelligence: Precepts, Methods, and Opportunities for Research in Construction
Nov 12, 2022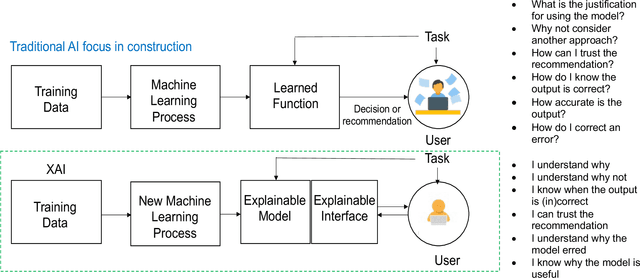
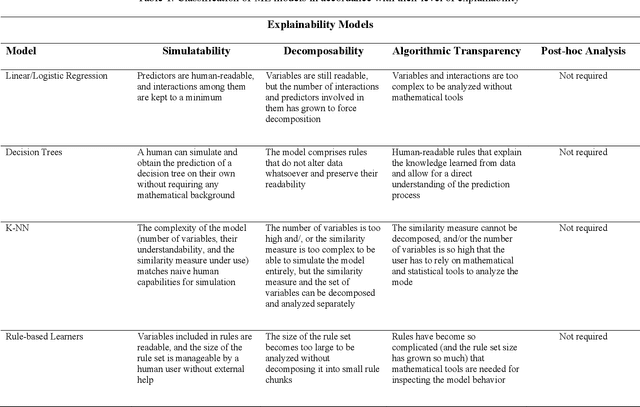
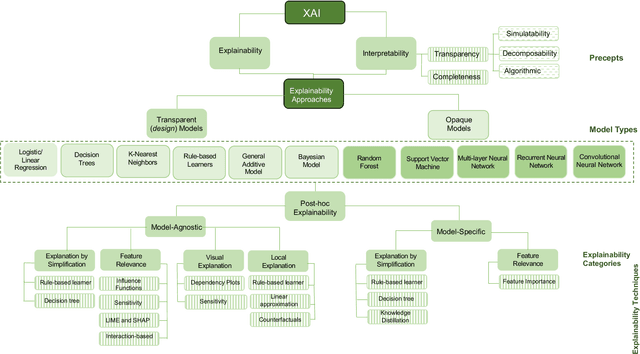

Explainable artificial intelligence has received limited attention in construction despite its growing importance in various other industrial sectors. In this paper, we provide a narrative review of XAI to raise awareness about its potential in construction. Our review develops a taxonomy of the XAI literature comprising its precepts and approaches. Opportunities for future XAI research focusing on stakeholder desiderata and data and information fusion are identified and discussed. We hope the opportunities we suggest stimulate new lines of inquiry to help alleviate the scepticism and hesitancy toward AI adoption and integration in construction.
Interaction Visual Transformer for Egocentric Action Anticipation
Nov 25, 2022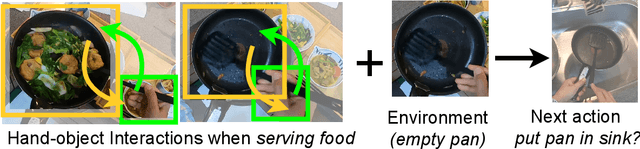
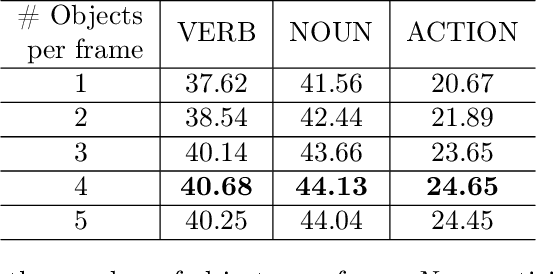
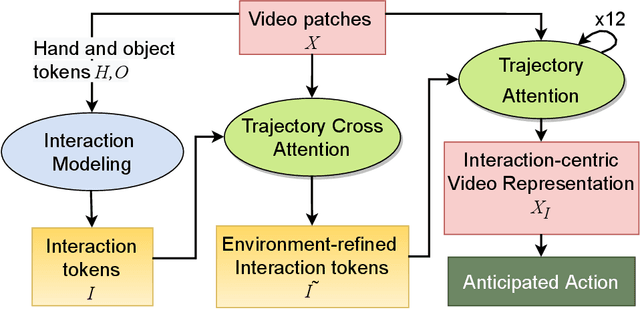
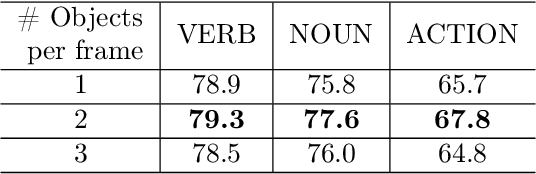
Human-object interaction is one of the most important visual cues that has not been explored for egocentric action anticipation. We propose a novel Transformer variant to model interactions by computing the change in the appearance of objects and human hands due to the execution of the actions and use those changes to refine the video representation. Specifically, we model interactions between hands and objects using Spatial Cross-Attention (SCA) and further infuse contextual information using Trajectory Cross-Attention to obtain environment-refined interaction tokens. Using these tokens, we construct an interaction-centric video representation for action anticipation. We term our model InAViT which achieves state-of-the-art action anticipation performance on large-scale egocentric datasets EPICKTICHENS100 (EK100) and EGTEA Gaze+. InAViT outperforms other visual transformer-based methods including object-centric video representation. On the EK100 evaluation server, InAViT is the top-performing method on the public leaderboard (at the time of submission) where it outperforms the second-best model by 3.3% on mean-top5 recall.
A Hierarchical Variable Autonomy Mixed-Initiative Framework for Human-Robot Teaming in Mobile Robotics
Nov 25, 2022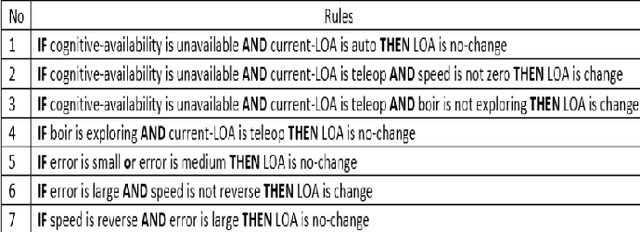
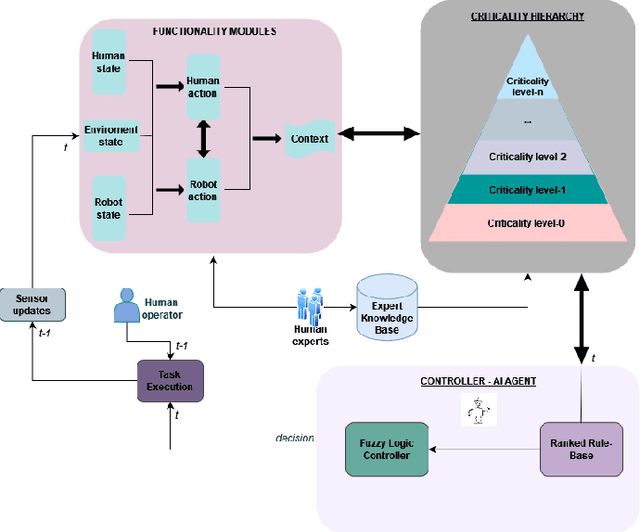
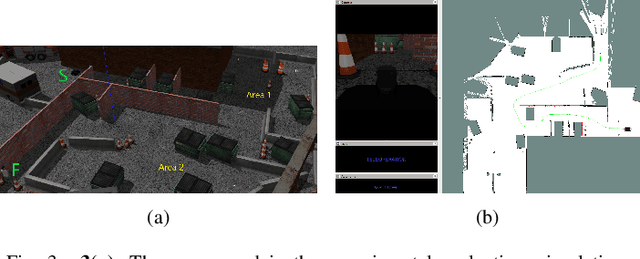
This paper presents a Mixed-Initiative (MI) framework for addressing the problem of control authority transfer between a remote human operator and an AI agent when cooperatively controlling a mobile robot. Our Hierarchical Expert-guided Mixed-Initiative Control Switcher (HierEMICS) leverages information on the human operator's state and intent. The control switching policies are based on a criticality hierarchy. An experimental evaluation was conducted in a high-fidelity simulated disaster response and remote inspection scenario, comparing HierEMICS with a state-of-the-art Expert-guided Mixed-Initiative Control Switcher (EMICS) in the context of mobile robot navigation. Results suggest that HierEMICS reduces conflicts for control between the human and the AI agent, which is a fundamental challenge in both the MI control paradigm and also in the related shared control paradigm. Additionally, we provide statistically significant evidence of improved, navigational safety (i.e., fewer collisions), LOA switching efficiency, and conflict for control reduction.