 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Image captioning algorithm based on the Hybrid Deep Learning Technique (CNN+GRU)
Jan 06, 2023
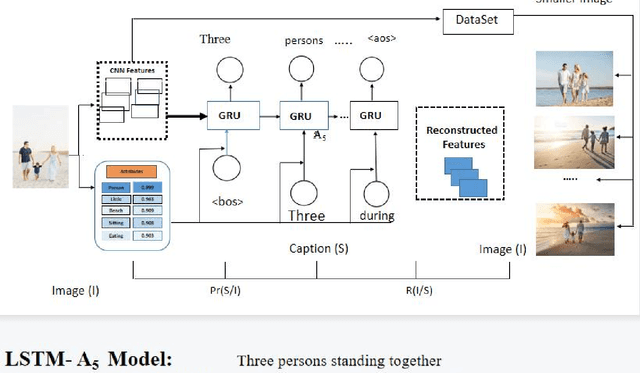
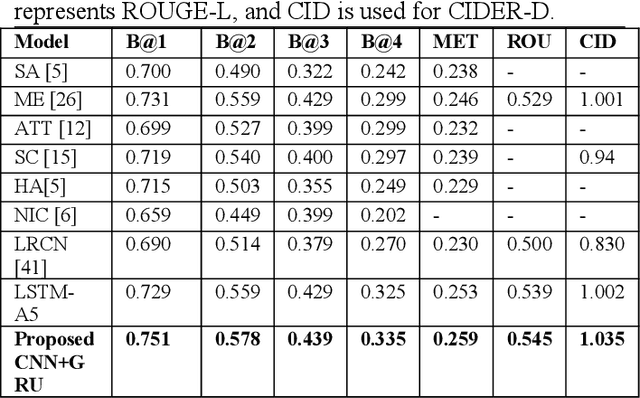
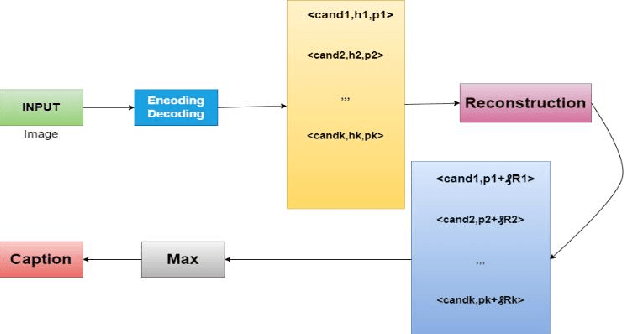
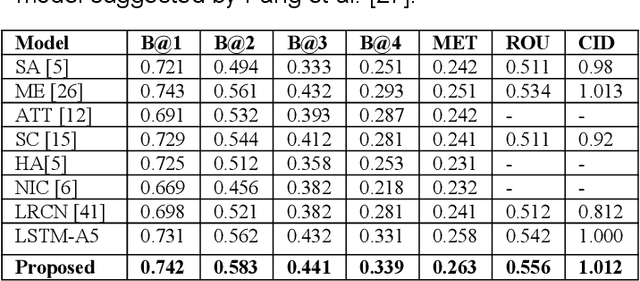
Image captioning by the encoder-decoder framework has shown tremendous advancement in the last decade where CNN is mainly used as encoder and LSTM is used as a decoder. Despite such an impressive achievement in terms of accuracy in simple images, it lacks in terms of time complexity and space complexity efficiency. In addition to this, in case of complex images with a lot of information and objects, the performance of this CNN-LSTM pair downgraded exponentially due to the lack of semantic understanding of the scenes presented in the images. Thus, to take these issues into consideration, we present CNN-GRU encoder decode framework for caption-to-image reconstructor to handle the semantic context into consideration as well as the time complexity. By taking the hidden states of the decoder into consideration, the input image and its similar semantic representations is reconstructed and reconstruction scores from a semantic reconstructor are used in conjunction with likelihood during model training to assess the quality of the generated caption. As a result, the decoder receives improved semantic information, enhancing the caption production process. During model testing, combining the reconstruction score and the log-likelihood is also feasible to choose the most appropriate caption. The suggested model outperforms the state-of-the-art LSTM-A5 model for picture captioning in terms of time complexity and accuracy.
An Approximate Algorithm for Maximum Inner Product Search over Streaming Sparse Vectors
Jan 25, 2023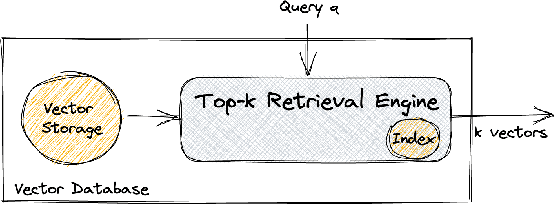
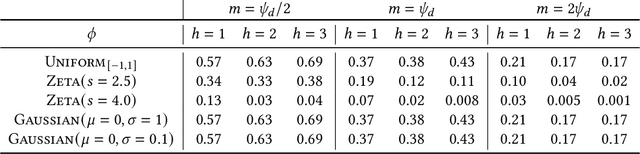
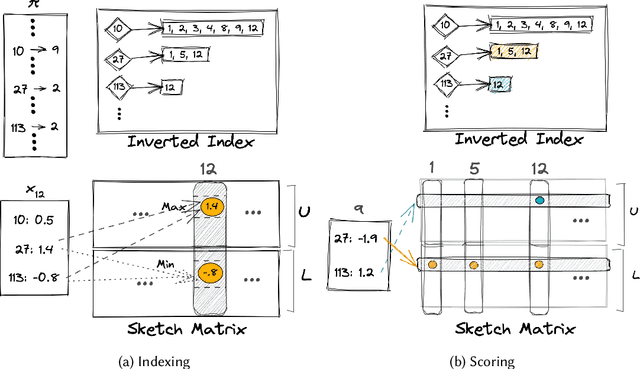
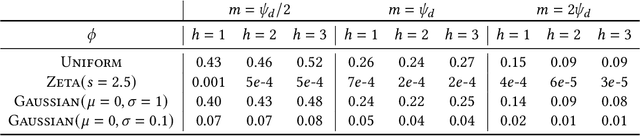
Maximum Inner Product Search or top-k retrieval on sparse vectors is well-understood in information retrieval, with a number of mature algorithms that solve it exactly. However, all existing algorithms are tailored to text and frequency-based similarity measures. To achieve optimal memory footprint and query latency, they rely on the near stationarity of documents and on laws governing natural languages. We consider, instead, a setup in which collections are streaming -- necessitating dynamic indexing -- and where indexing and retrieval must work with arbitrarily distributed real-valued vectors. As we show, existing algorithms are no longer competitive in this setup, even against naive solutions. We investigate this gap and present a novel approximate solution, called Sinnamon, that can efficiently retrieve the top-k results for sparse real valued vectors drawn from arbitrary distributions. Notably, Sinnamon offers levers to trade-off memory consumption, latency, and accuracy, making the algorithm suitable for constrained applications and systems. We give theoretical results on the error introduced by the approximate nature of the algorithm, and present an empirical evaluation of its performance on two hardware platforms and synthetic and real-valued datasets. We conclude by laying out concrete directions for future research on this general top-k retrieval problem over sparse vectors.
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023
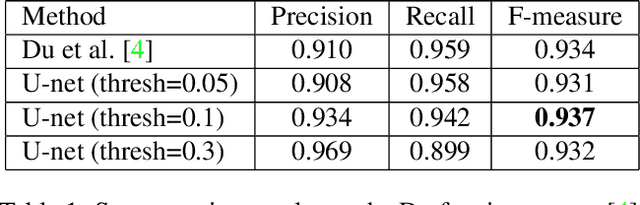

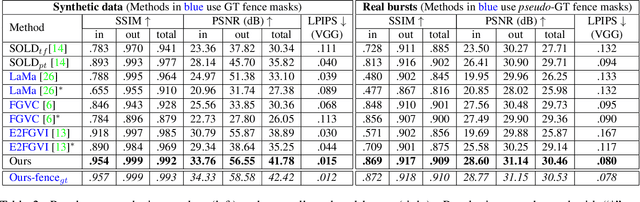
Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
From Baseline to Top Performer: A Reproducibility Study of Approaches at the TREC 2021 Conversational Assistance Track
Jan 25, 2023

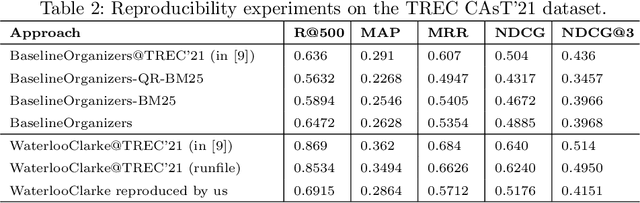
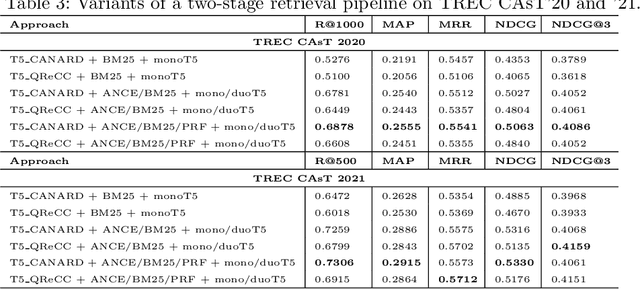
This paper reports on an effort of reproducing the organizers' baseline as well as the top performing participant submission at the 2021 edition of the TREC Conversational Assistance track. TREC systems are commonly regarded as reference points for effectiveness comparison. Yet, the papers accompanying them have less strict requirements than peer-reviewed publications, which can make reproducibility challenging. Our results indicate that key practical information is indeed missing. While the results can be reproduced within a 19% relative margin with respect to the main evaluation measure, the relative difference between the baseline and the top performing approach shrinks from the reported 18% to 5%. Additionally, we report on a new set of experiments aimed at understanding the impact of various pipeline components. We show that end-to-end system performance can indeed benefit from advanced retrieval techniques in either stage of a two-stage retrieval pipeline. We also measure the impact of the dataset used for fine-tuning the query rewriter and find that employing different query rewriting methods in different stages of the retrieval pipeline might be beneficial. Moreover, these results are shown to generalize across the 2020 and 2021 editions of the track. We conclude our study with a list of lessons learned and practical suggestions.
A deep scalable neural architecture for soil properties estimation from spectral information
Oct 26, 2022
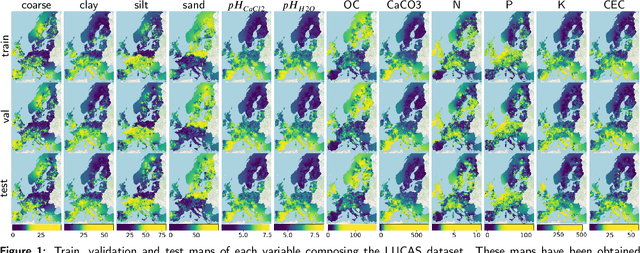
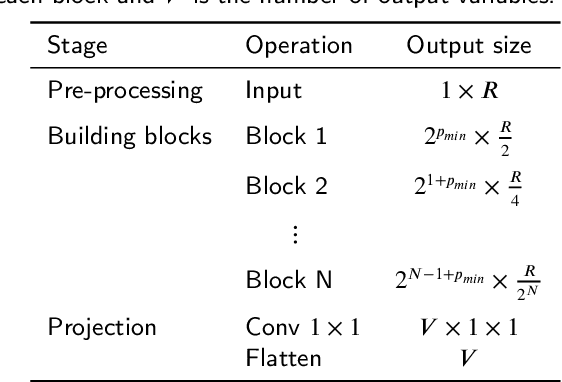
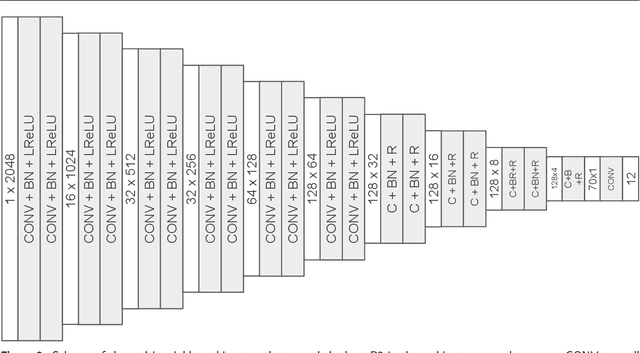
In this paper we propose an adaptive deep neural architecture for the prediction of multiple soil characteristics from the analysis of hyperspectral signatures. The proposed method overcomes the limitations of previous methods in the state of art: (i) it allows to predict multiple soil variables at once; (ii) it permits to backtrace the spectral bands that most contribute to the estimation of a given variable; (iii) it is based on a flexible neural architecture capable of automatically adapting to the spectral library under analysis. The proposed architecture is experimented on LUCAS, a large laboratory dataset and on a dataset achieved by simulating PRISMA hyperspectral sensor. 'Results, compared with other state-of-the-art methods confirm the effectiveness of the proposed solution.
Robust Information Criterion for Model Selection in Sparse High-Dimensional Linear Regression Models
Jun 17, 2022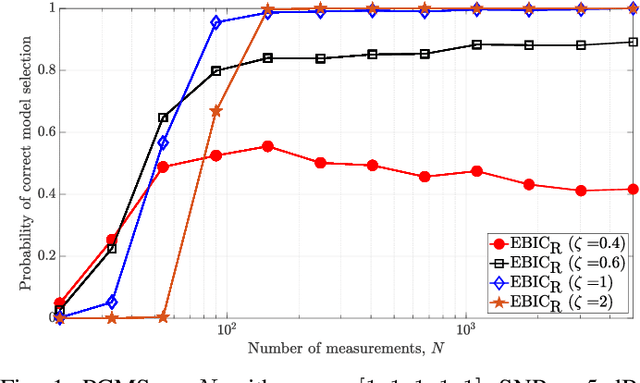
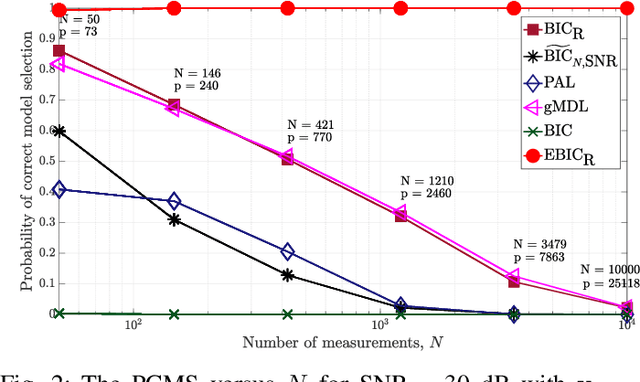
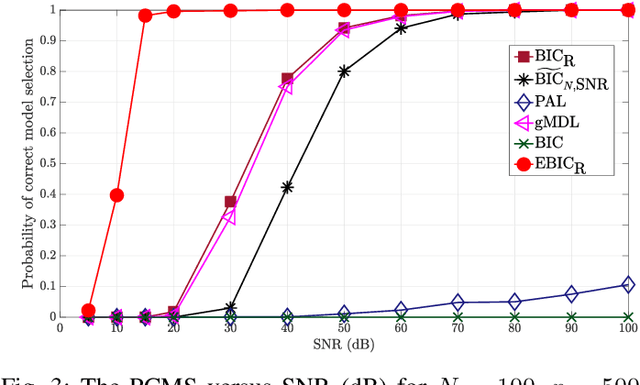
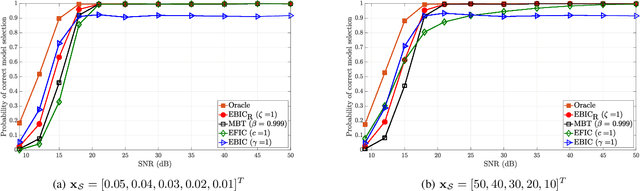
Model selection in linear regression models is a major challenge when dealing with high-dimensional data where the number of available measurements (sample size) is much smaller than the dimension of the parameter space. Traditional methods for model selection such as Akaike information criterion, Bayesian information criterion (BIC) and minimum description length are heavily prone to overfitting in the high-dimensional setting. In this regard, extended BIC (EBIC), which is an extended version of the original BIC and extended Fisher information criterion (EFIC), which is a combination of EBIC and Fisher information criterion, are consistent estimators of the true model as the number of measurements grows very large. However, EBIC is not consistent in high signal-to-noise-ratio (SNR) scenarios where the sample size is fixed and EFIC is not invariant to data scaling resulting in unstable behaviour. In this paper, we propose a new form of the EBIC criterion called EBIC-Robust, which is invariant to data scaling and consistent in both large sample size and high-SNR scenarios. Analytical proofs are presented to guarantee its consistency. Simulation results indicate that the performance of EBIC-Robust is quite superior to that of both EBIC and EFIC.
CKG: Dynamic Representation Based on Context and Knowledge Graph
Dec 09, 2022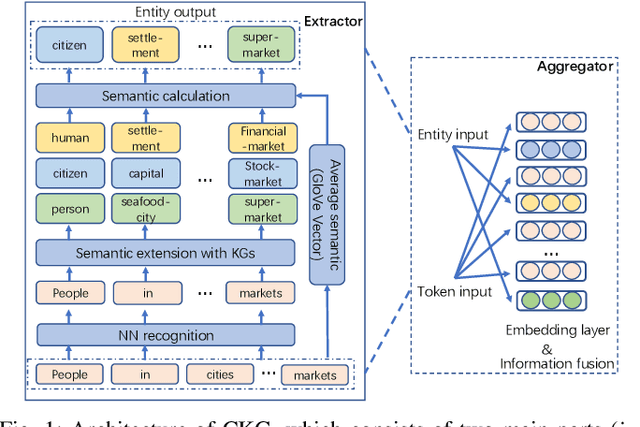
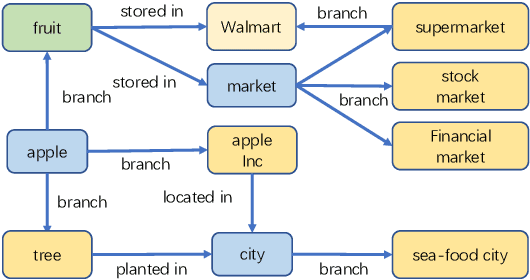
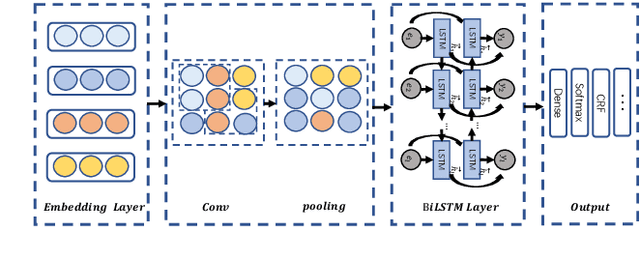
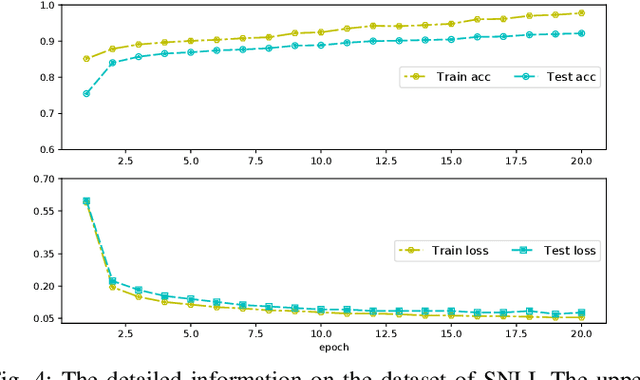
Recently, neural language representation models pre-trained on large corpus can capture rich co-occurrence information and be fine-tuned in downstream tasks to improve the performance. As a result, they have achieved state-of-the-art results in a large range of language tasks. However, there exists other valuable semantic information such as similar, opposite, or other possible meanings in external knowledge graphs (KGs). We argue that entities in KGs could be used to enhance the correct semantic meaning of language sentences. In this paper, we propose a new method CKG: Dynamic Representation Based on \textbf{C}ontext and \textbf{K}nowledge \textbf{G}raph. On the one side, CKG can extract rich semantic information of large corpus. On the other side, it can make full use of inside information such as co-occurrence in large corpus and outside information such as similar entities in KGs. We conduct extensive experiments on a wide range of tasks, including QQP, MRPC, SST-5, SQuAD, CoNLL 2003, and SNLI. The experiment results show that CKG achieves SOTA 89.2 on SQuAD compared with SAN (84.4), ELMo (85.8), and BERT$_{Base}$ (88.5).
Monitoring of the heart movements using a FMCW radar and correlation with an ECG
Jan 21, 2023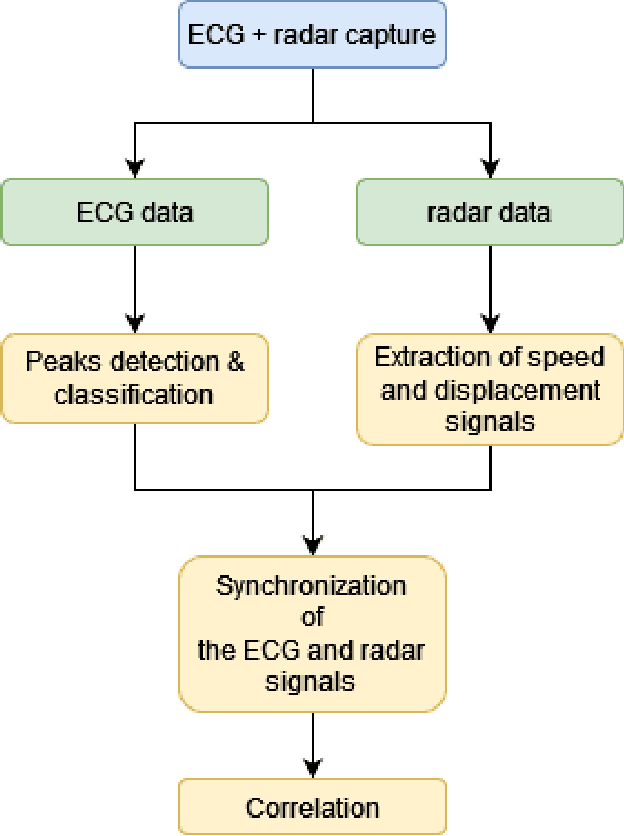


Monitoring the heart activity is an important task to prevent and diagnose cardiovascular diseases. An electrocardio-gram (ECG) is the gold standard for such task. It monitors the heart electrical activity, and while the later is highly correlated to the cardiac mechanical activity, it does not provide all the information. Other sensors such as echo-cardiograph allow to monitor the heart movements, but such tools are hard to operate and expensive. Therefore, contact-less monitoring of the heart using RF sensing has gained interest over the past years. In this paper, we provide a process to extract the movement of the heart with a high accuracy from a millimeter wave radar, i.e. we describe a non invasive and affordable way to monitor cardiac movements. We then demonstrate the correlation between the observed movements and the ECG. Furthermore, we propose an algorithm to synchronize the ECG signal and the processed signal from the radar sensor. The results we obtained provide insights on the mechanical activity of the heart, which could assist cardiologists in their diagnosis
Learning to View: Decision Transformers for Active Object Detection
Jan 23, 2023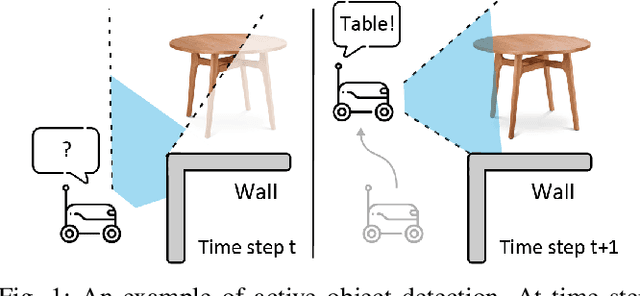
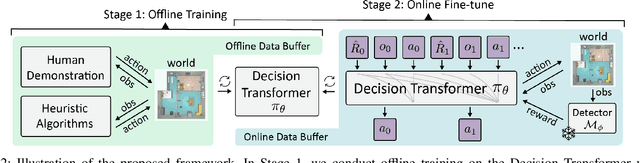
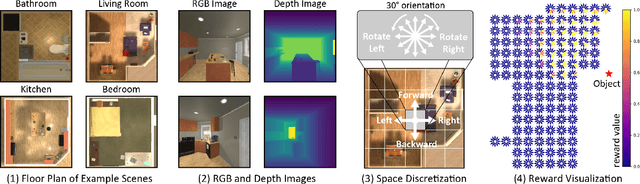
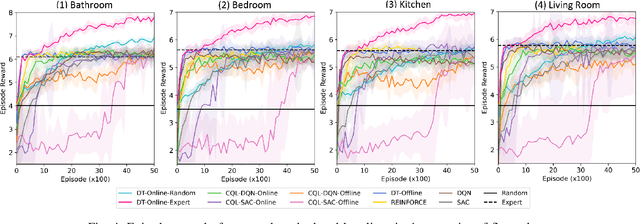
Active perception describes a broad class of techniques that couple planning and perception systems to move the robot in a way to give the robot more information about the environment. In most robotic systems, perception is typically independent of motion planning. For example, traditional object detection is passive: it operates only on the images it receives. However, we have a chance to improve the results if we allow planning to consume detection signals and move the robot to collect views that maximize the quality of the results. In this paper, we use reinforcement learning (RL) methods to control the robot in order to obtain images that maximize the detection quality. Specifically, we propose using a Decision Transformer with online fine-tuning, which first optimizes the policy with a pre-collected expert dataset and then improves the learned policy by exploring better solutions in the environment. We evaluate the performance of proposed method on an interactive dataset collected from an indoor scenario simulator. Experimental results demonstrate that our method outperforms all baselines, including expert policy and pure offline RL methods. We also provide exhaustive analyses of the reward distribution and observation space.
Mining User-aware Multi-relations for Fake News Detection in Large Scale Online Social Networks
Jan 04, 2023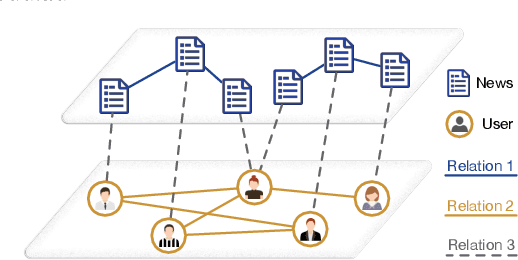
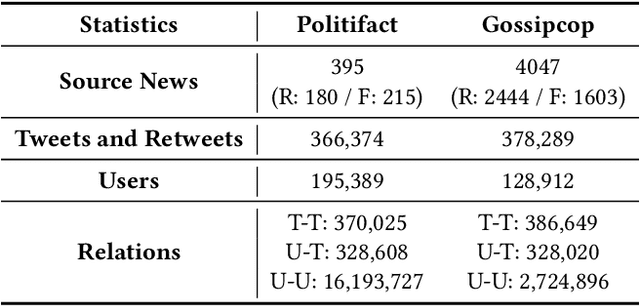
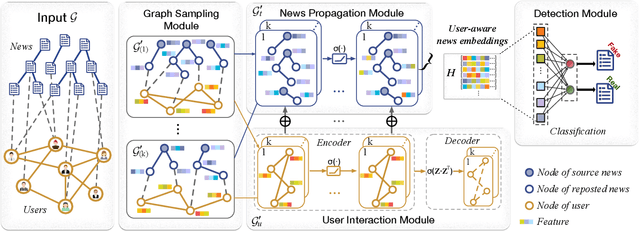
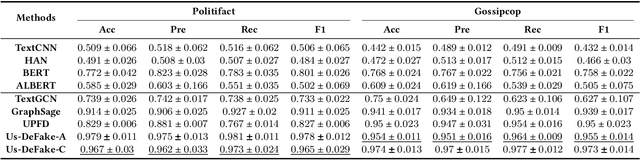
Users' involvement in creating and propagating news is a vital aspect of fake news detection in online social networks. Intuitively, credible users are more likely to share trustworthy news, while untrusted users have a higher probability of spreading untrustworthy news. In this paper, we construct a dual-layer graph (i.e., the news layer and the user layer) to extract multiple relations of news and users in social networks to derive rich information for detecting fake news. Based on the dual-layer graph, we propose a fake news detection model named Us-DeFake. It learns the propagation features of news in the news layer and the interaction features of users in the user layer. Through the inter-layer in the graph, Us-DeFake fuses the user signals that contain credibility information into the news features, to provide distinctive user-aware embeddings of news for fake news detection. The training process conducts on multiple dual-layer subgraphs obtained by a graph sampler to scale Us-DeFake in large scale social networks. Extensive experiments on real-world datasets illustrate the superiority of Us-DeFake which outperforms all baselines, and the users' credibility signals learned by interaction relation can notably improve the performance of our model.