 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IDEAL: Toward High-efficiency Device-Cloud Collaborative and Dynamic Recommendation System
Feb 14, 2023
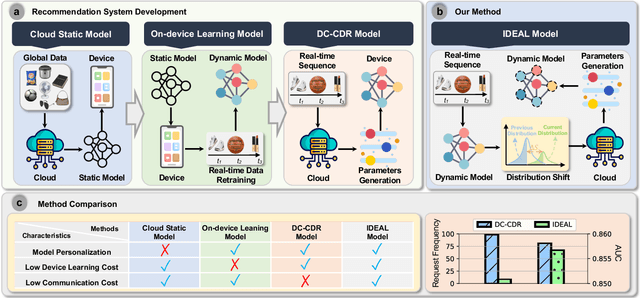
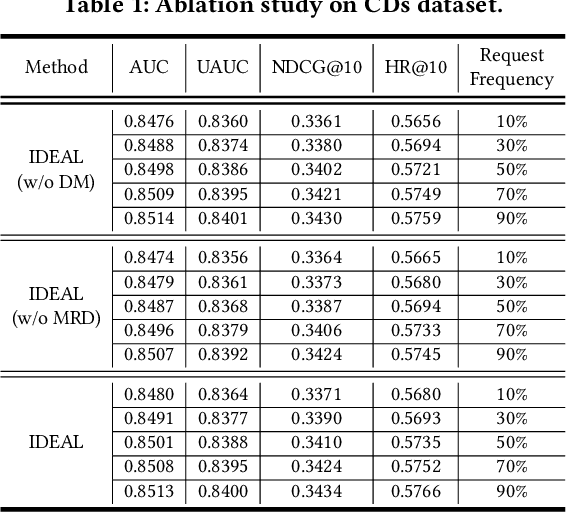
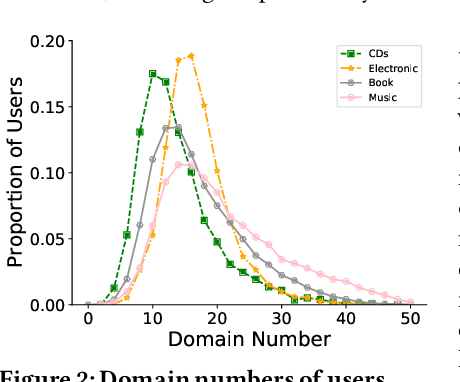
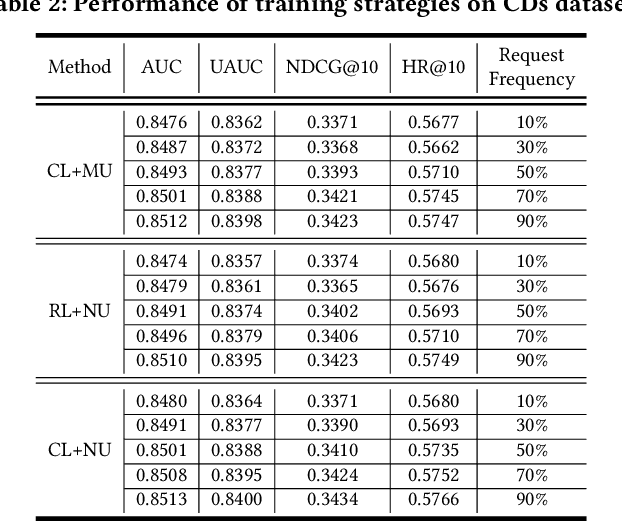
Recommendation systems have shown great potential to solve the information explosion problem and enhance user experience in various online applications, which recently present two emerging trends: (i) Collaboration: single-sided model trained on-cloud (separate learning) to the device-cloud collaborative recommendation (collaborative learning). (ii) Real-time Dynamic: the network parameters are the same across all the instances (static model) to adaptive network parameters generation conditioned on the real-time instances (dynamic model). The aforementioned two trends enable the device-cloud collaborative and dynamic recommendation, which deeply exploits the recommendation pattern among cloud-device data and efficiently characterizes different instances with different underlying distributions based on the cost of frequent device-cloud communication. Despite promising, we argue that most of the communications are unnecessary to request the new parameters of the recommendation system on the cloud since the on-device data distribution are not always changing. To alleviate this issue, we designed a Intelligent DEvice-Cloud PArameter Request ModeL (IDEAL) that can be deployed on the device to calculate the request revenue with low resource consumption, so as to ensure the adaptive device-cloud communication with high revenue. We envision a new device intelligence learning task to implement IDEAL by detecting the data out-of-domain. Moreover, we map the user's real-time behavior to a normal distribution, the uncertainty is calculated by the multi-sampling outputs to measure the generalization ability of the device model to the current user behavior. Our experimental study demonstrates IDEAL's effectiveness and generalizability on four public benchmarks, which yield a higher efficient device-cloud collaborative and dynamic recommendation paradigm.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023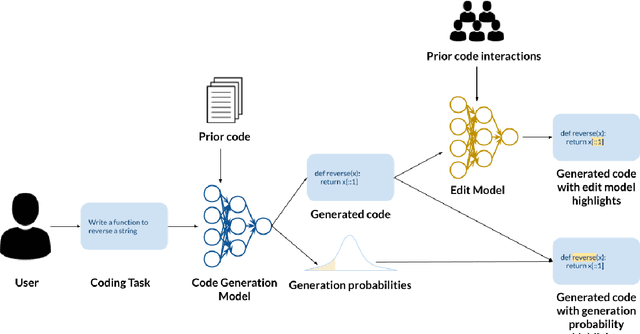
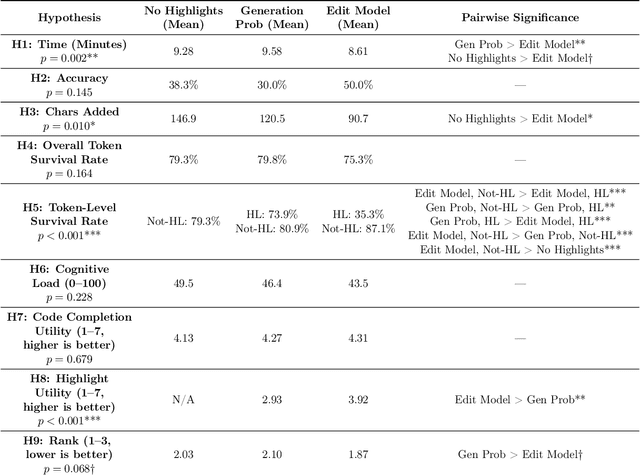


Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.
ContrasInver: Voxel-wise Contrastive Semi-supervised Learning for Seismic Inversion
Feb 14, 2023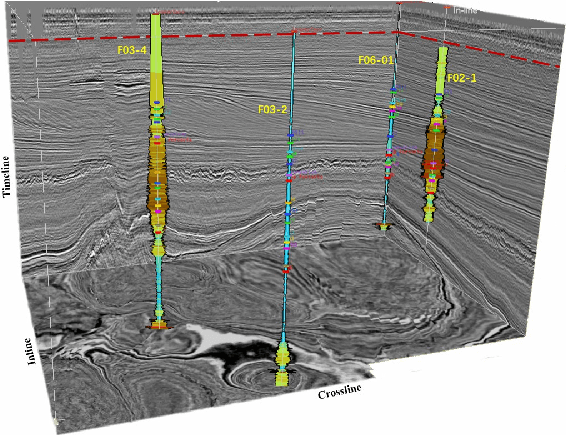
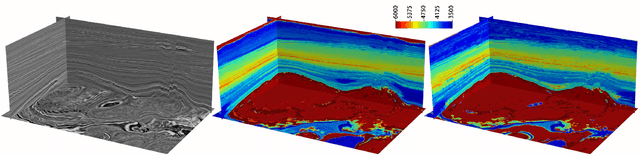
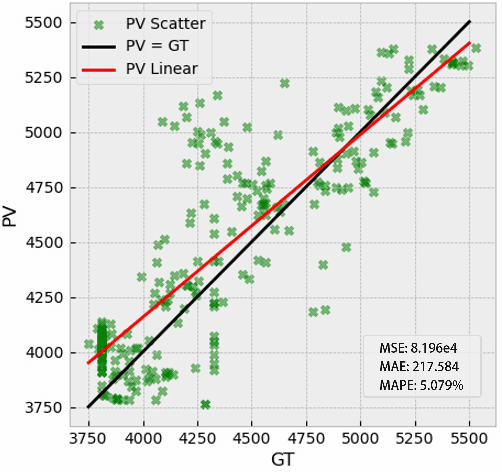
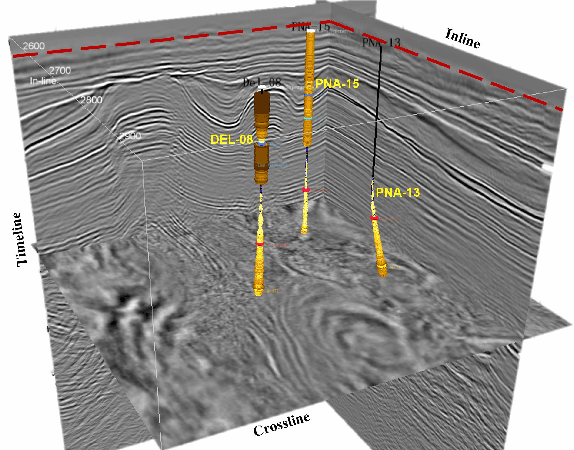
Recent studies have shown that learning theories have been very successful in hydrocarbon exploration. Inversion of seismic into various attributes through the relationship of 1D well-logs and 3D seismic is an essential step in reservoir description, among which, acoustic impedance is one of the most critical attributes, and although current deep learningbased impedance inversion obtains promising results, it relies on a large number of logs (1D labels, typically more than 30 well-logs are required per inversion), which is unacceptable in many practical explorations. In this work, we define acoustic impedance inversion as a regression task for learning sparse 1D labels from 3D volume data and propose a voxel-wise semisupervised contrastive learning framework, ContrasInver, for regression tasks under sparse labels. ConstraInver consists of several key components, including a novel pre-training method for 3D seismic data inversion, a contrastive semi-supervised strategy for diffusing well-log information to the global, and a continuous-value vectorized characterization method for a contrastive learning-based regression task, and also designed the distance TopK sampling method for improving the training efficiency. We performed a complete ablation study on SEAM Phase I synthetic data to verify the effectiveness of each component and compared our approach with the current mainstream methods on this data, and our approach demonstrated very significant advantages. In this data we achieved an SSIM of 0.92 and an MSE of 0.079 with only four well-logs. ConstraInver is the first purely data-driven approach to invert two classic field data, F3 Netherlands (only four well-logs) and Delft (only three well-logs) and achieves very reasonable and reliable results.
Transformers Meet Directed Graphs
Jan 31, 2023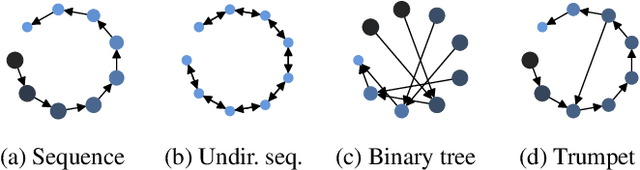
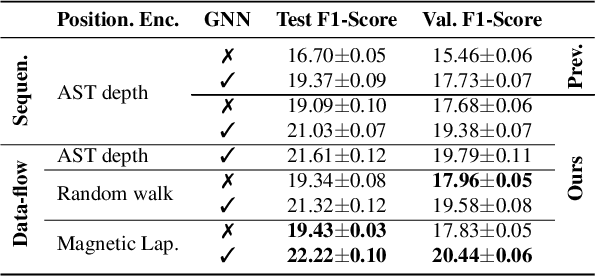

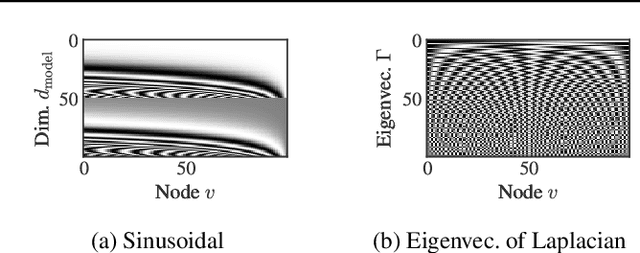
Transformers were originally proposed as a sequence-to-sequence model for text but have become vital for a wide range of modalities, including images, audio, video, and undirected graphs. However, transformers for directed graphs are a surprisingly underexplored topic, despite their applicability to ubiquitous domains including source code and logic circuits. In this work, we propose two direction- and structure-aware positional encodings for directed graphs: (1) the eigenvectors of the Magnetic Laplacian - a direction-aware generalization of the combinatorial Laplacian; (2) directional random walk encodings. Empirically, we show that the extra directionality information is useful in various downstream tasks, including correctness testing of sorting networks and source code understanding. Together with a data-flow-centric graph construction, our model outperforms the prior state of the art on the Open Graph Benchmark Code2 relatively by 14.7%.
Towards Mechatronics Approach of System Design, Verification and Validation for Autonomous Vehicles
Jan 31, 2023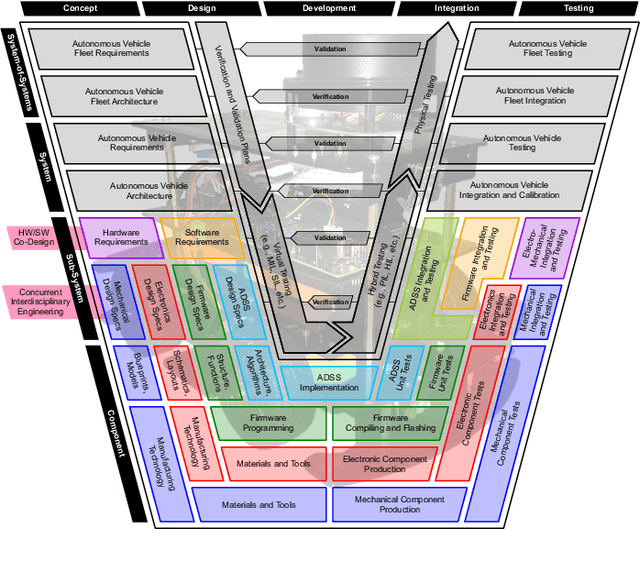
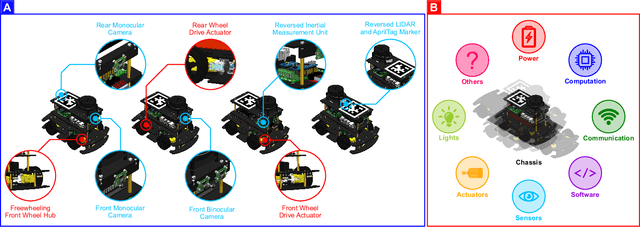
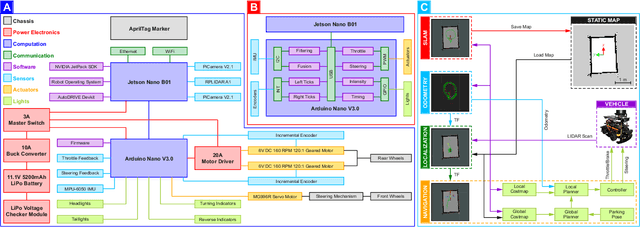
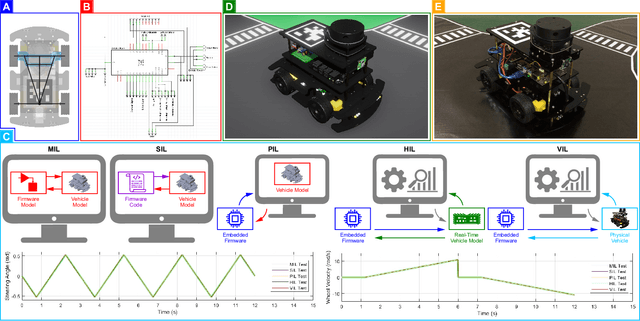
Modern-day autonomous vehicles are increasingly becoming complex multidisciplinary systems composed of mechanical, electrical, electronic, computing and information sub-systems. Furthermore, the individual constituent technologies employed for developing autonomous vehicles have started maturing up to a point, where it seems beneficial to start looking at the synergistic integration of these components into sub-systems, systems, and potentially, system-of-systems. Hence, this work applies the principles of mechatronics approach of system design, verification and validation for the development of autonomous vehicles. Particularly, we discuss leveraging multidisciplinary co-design practices along with virtual, hybrid and physical prototyping and testing within a concurrent engineering framework to develop and validate a scaled autonomous vehicle using the AutoDRIVE ecosystem. We also describe a case-study of autonomous parking application using a modular probabilistic framework to illustrate the benefits of the proposed approach.
Goal Alignment: A Human-Aware Account of Value Alignment Problem
Feb 08, 2023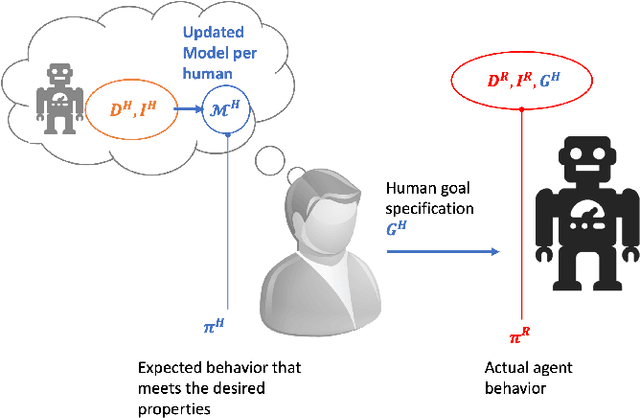
Value alignment problems arise in scenarios where the specified objectives of an AI agent don't match the true underlying objective of its users. The problem has been widely argued to be one of the central safety problems in AI. Unfortunately, most existing works in value alignment tend to focus on issues that are primarily related to the fact that reward functions are an unintuitive mechanism to specify objectives. However, the complexity of the objective specification mechanism is just one of many reasons why the user may have misspecified their objective. A foundational cause for misalignment that is being overlooked by these works is the inherent asymmetry in human expectations about the agent's behavior and the behavior generated by the agent for the specified objective. To address this lacuna, we propose a novel formulation for the value alignment problem, named goal alignment that focuses on a few central challenges related to value alignment. In doing so, we bridge the currently disparate research areas of value alignment and human-aware planning. Additionally, we propose a first-of-its-kind interactive algorithm that is capable of using information generated under incorrect beliefs about the agent, to determine the true underlying goal of the user.
Neural Congealing: Aligning Images to a Joint Semantic Atlas
Feb 08, 2023
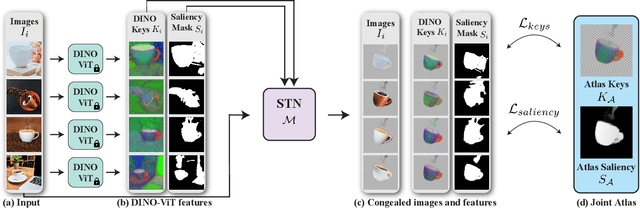
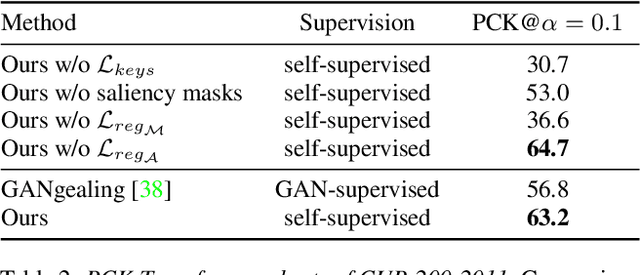
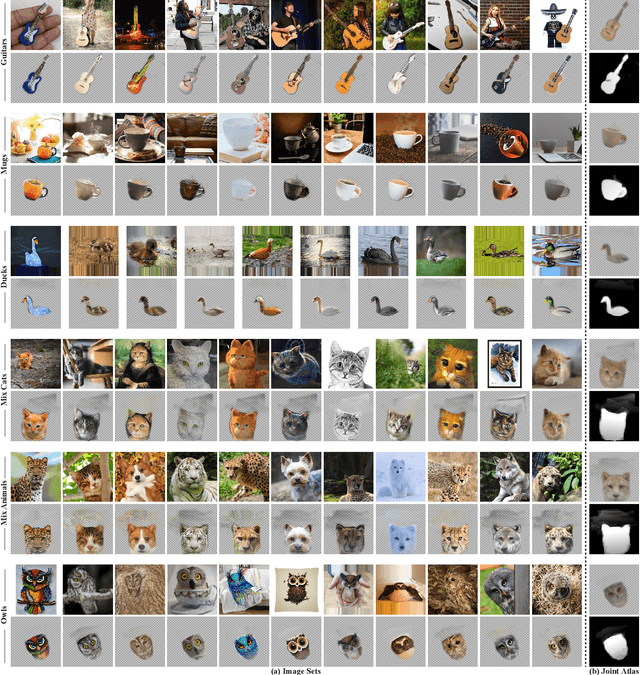
We present Neural Congealing -- a zero-shot self-supervised framework for detecting and jointly aligning semantically-common content across a given set of images. Our approach harnesses the power of pre-trained DINO-ViT features to learn: (i) a joint semantic atlas -- a 2D grid that captures the mode of DINO-ViT features in the input set, and (ii) dense mappings from the unified atlas to each of the input images. We derive a new robust self-supervised framework that optimizes the atlas representation and mappings per image set, requiring only a few real-world images as input without any additional input information (e.g., segmentation masks). Notably, we design our losses and training paradigm to account only for the shared content under severe variations in appearance, pose, background clutter or other distracting objects. We demonstrate results on a plethora of challenging image sets including sets of mixed domains (e.g., aligning images depicting sculpture and artwork of cats), sets depicting related yet different object categories (e.g., dogs and tigers), or domains for which large-scale training data is scarce (e.g., coffee mugs). We thoroughly evaluate our method and show that our test-time optimization approach performs favorably compared to a state-of-the-art method that requires extensive training on large-scale datasets.
EVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023
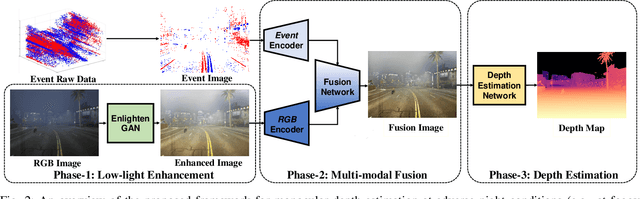
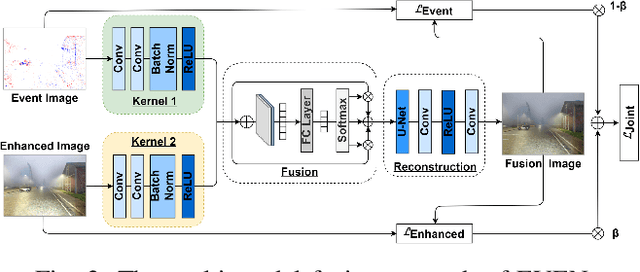
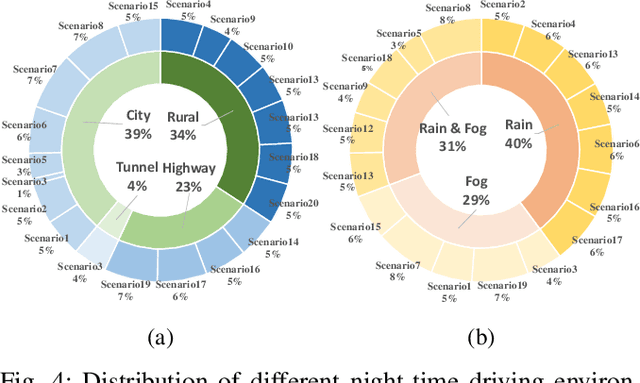
Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 08, 2023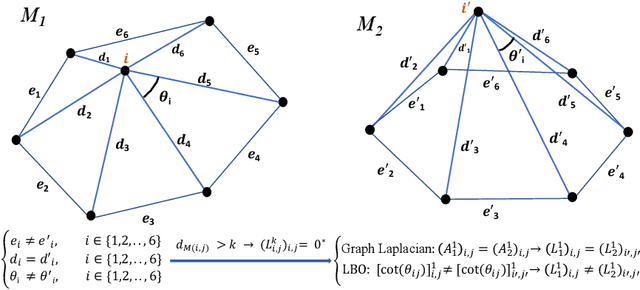
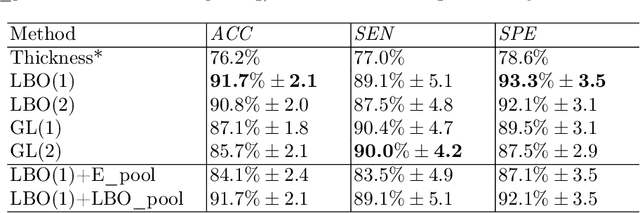
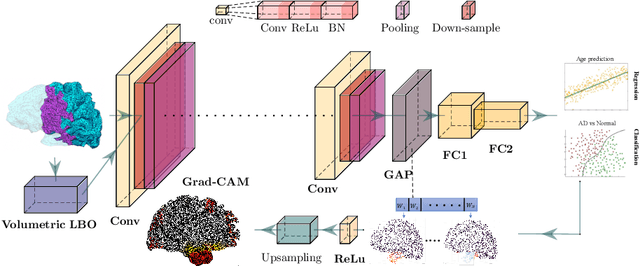
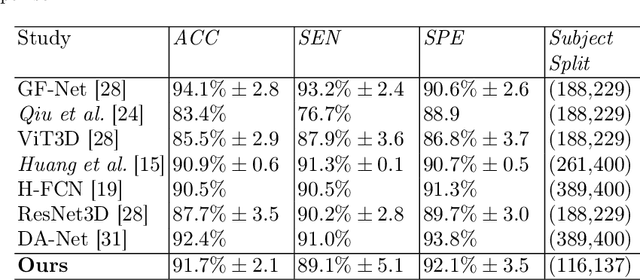
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
A Unified Multi-view Multi-person Tracking Framework
Feb 08, 2023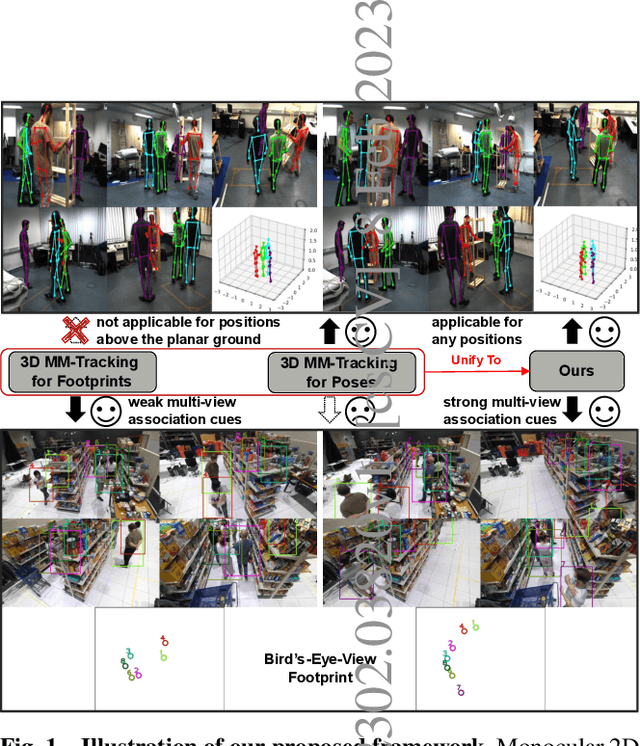

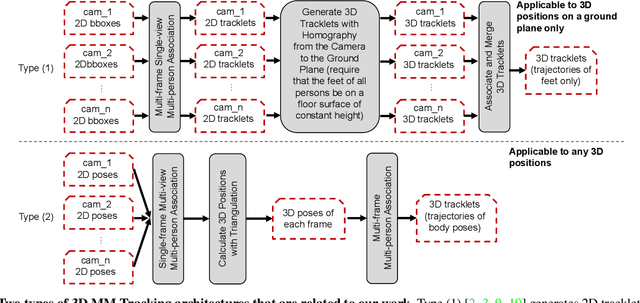

Although there is a significant development in 3D Multi-view Multi-person Tracking (3D MM-Tracking), current 3D MM-Tracking frameworks are designed separately for footprint and pose tracking. Specifically, frameworks designed for footprint tracking cannot be utilized in 3D pose tracking, because they directly obtain 3D positions on the ground plane with a homography projection, which is inapplicable to 3D poses above the ground. In contrast, frameworks designed for pose tracking generally isolate multi-view and multi-frame associations and may not be robust to footprint tracking, since footprint tracking utilizes fewer key points than pose tracking, which weakens multi-view association cues in a single frame. This study presents a Unified Multi-view Multi-person Tracking framework to bridge the gap between footprint tracking and pose tracking. Without additional modifications, the framework can adopt monocular 2D bounding boxes and 2D poses as the input to produce robust 3D trajectories for multiple persons. Importantly, multi-frame and multi-view information are jointly employed to improve the performance of association and triangulation. The effectiveness of our framework is verified by accomplishing state-of-the-art performance on the Campus and Shelf datasets for 3D pose tracking, and by comparable results on the WILDTRACK and MMPTRACK datasets for 3D footprint tracking.
* Accepted to Computational Visual Media