 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Active Learning and Bayesian Optimization: a Unified Perspective to Learn with a Goal
Mar 08, 2023
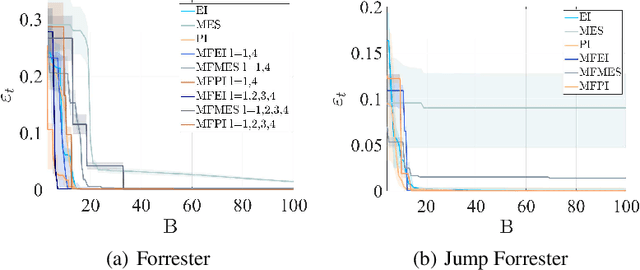
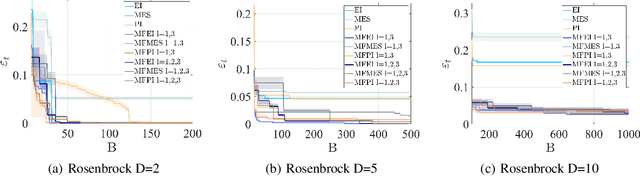
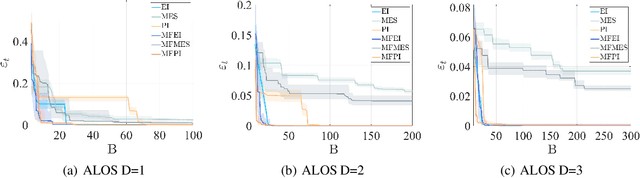
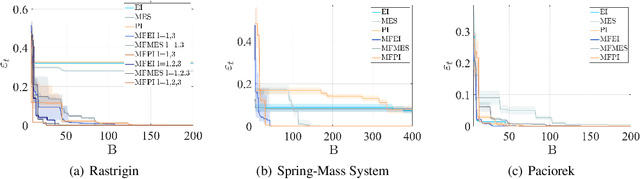
Both Bayesian optimization and active learning realize an adaptive sampling scheme to achieve a specific learning goal. However, while the two fields have seen an exponential growth in popularity in the past decade, their dualism has received relatively little attention. In this paper, we argue for an original unified perspective of Bayesian optimization and active learning based on the synergy between the principles driving the sampling policies. This symbiotic relationship is demonstrated through the substantial analogy between the infill criteria of Bayesian optimization and the learning criteria in active learning, and is formalized for the case of single information source and when multiple sources at different levels of fidelity are available. We further investigate the capabilities of each infill criteria both individually and in combination on a variety of analytical benchmark problems, to highlight benefits and limitations over mathematical properties that characterize real-world applications.
Convergence Rates for Localized Actor-Critic in Networked Markov Potential Games
Mar 08, 2023
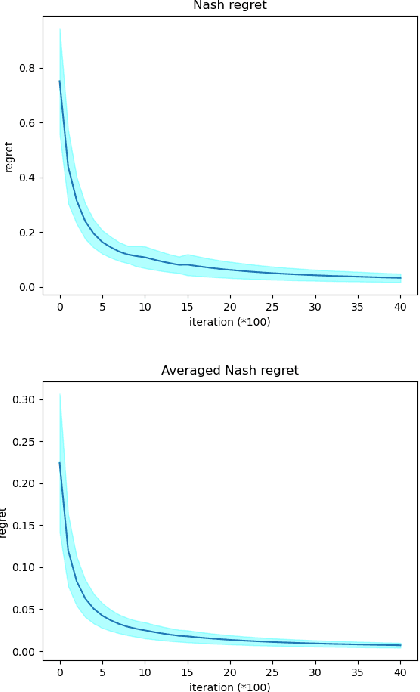
We introduce a class of networked Markov potential games where agents are associated with nodes in a network. Each agent has its own local potential function, and the reward of each agent depends only on the states and actions of agents within a $\kappa$-hop neighborhood. In this context, we propose a localized actor-critic algorithm. The algorithm is scalable since each agent uses only local information and does not need access to the global state. Further, the algorithm overcomes the curse of dimensionality through the use of function approximation. Our main results provide finite-sample guarantees up to a localization error and a function approximation error. Specifically, we achieve an $\tilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity measured by the averaged Nash regret. This is the first finite-sample bound for multi-agent competitive games that does not depend on the number of agents.
Implications of Personality on Cognitive Workload, Affect, and Task Performance in Robot Remote Control
Mar 08, 2023
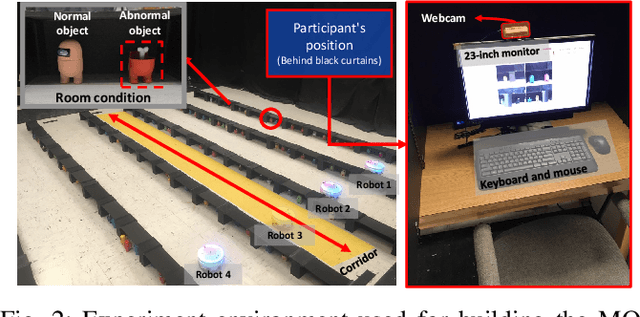
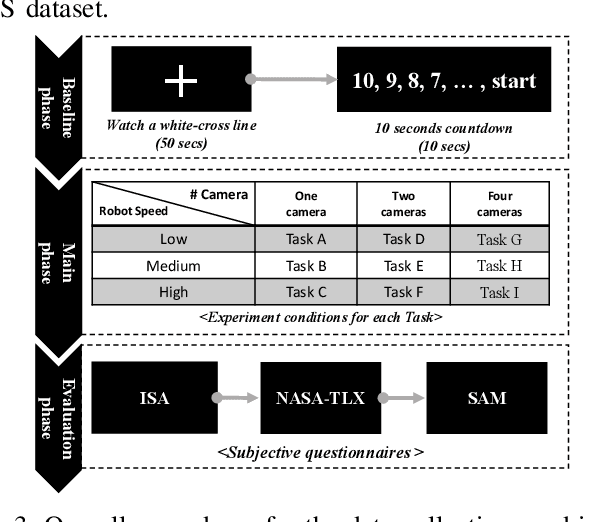
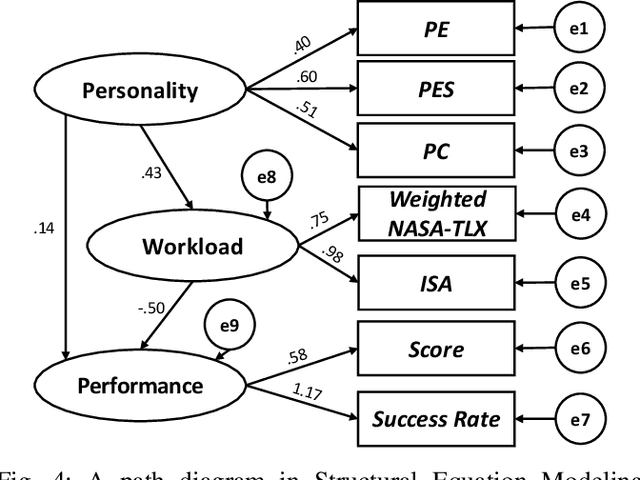
This paper explores how the personality traits of robot operators can impact their task performance during remote control of robots. The influence of personal dispositions on information processing, either directly or indirectly, needs to be examined when working with robots on specific tasks. To investigate this relationship, we utilize the open-access multi-modal dataset MOCAS to examine the operator's personality, affect, cognitive load, and task performance. Our objective is to confirm if personal traits have a total effect, including both direct and indirect effects, that could significantly impact operator performance level. We specifically examine the relationship between personality traits such as extroversion, conscientiousness, and agreeableness, and task performance. We analyze the correlation between cognitive load, self-ratings of workload and affect, and the quantified individual personality traits and their experimental scores. As a result, we confirm that personality traits have no total effect on task performance.
Memory-augmented Online Video Anomaly Detection
Feb 21, 2023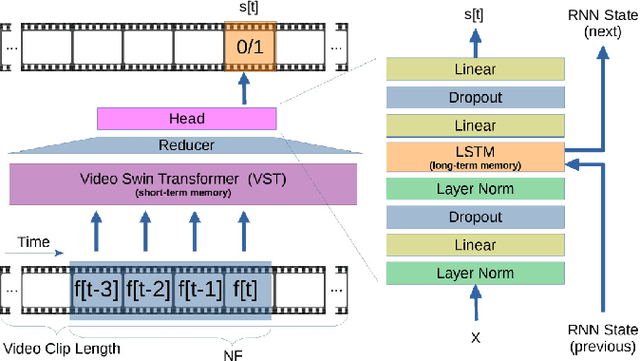


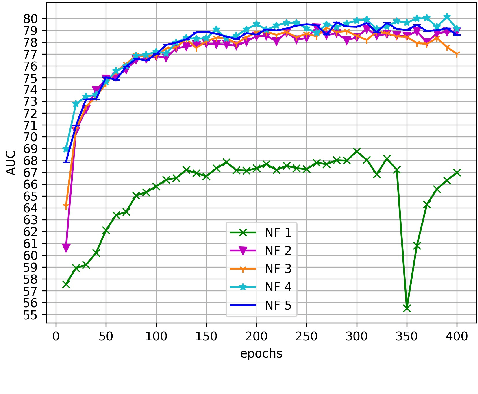
The ability to understand the surrounding scene is of paramount importance for Autonomous Vehicles (AVs). This paper presents a system capable to work in a real time guaranteed response times and online fashion, giving an immediate response to the arise of anomalies surrounding the AV, exploiting only the videos captured by a dash-mounted camera. Our architecture, called MOVAD, relies on two main modules: a short-term memory to extract information related to the ongoing action, implemented by a Video Swin Transformer adapted to work in an online scenario, and a long-term memory module that considers also remote past information thanks to the use of a Long-Short Term Memory (LSTM) network. We evaluated the performance of our method on Detection of Traffic Anomaly (DoTA) dataset, a challenging collection of dash-mounted camera videos of accidents. After an extensive ablation study, MOVAD is able to reach an AUC score of 82.11%, surpassing the current state-of-the-art by +2.81 AUC. Our code will be available on https://github.com/IMPLabUniPr/movad/tree/icip
MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
Feb 21, 2023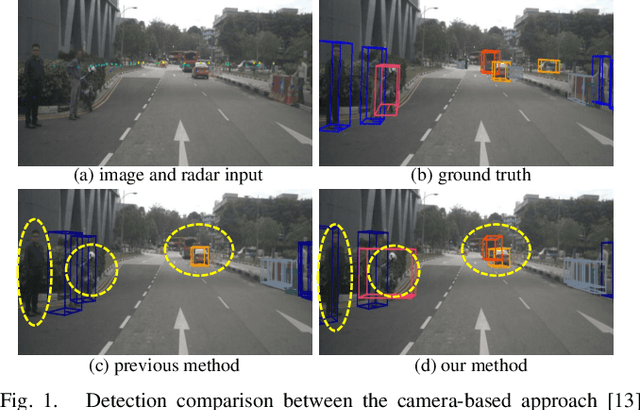
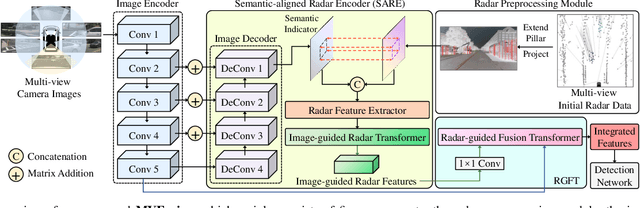

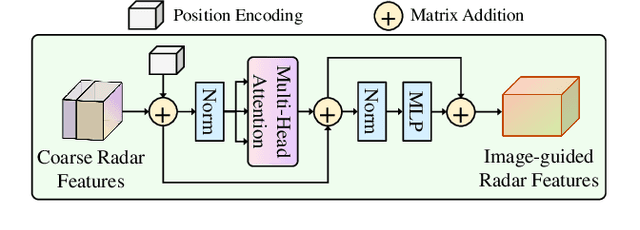
Multi-view radar-camera fused 3D object detection provides a farther detection range and more helpful features for autonomous driving, especially under adverse weather. The current radar-camera fusion methods deliver kinds of designs to fuse radar information with camera data. However, these fusion approaches usually adopt the straightforward concatenation operation between multi-modal features, which ignores the semantic alignment with radar features and sufficient correlations across modals. In this paper, we present MVFusion, a novel Multi-View radar-camera Fusion method to achieve semantic-aligned radar features and enhance the cross-modal information interaction. To achieve so, we inject the semantic alignment into the radar features via the semantic-aligned radar encoder (SARE) to produce image-guided radar features. Then, we propose the radar-guided fusion transformer (RGFT) to fuse our radar and image features to strengthen the two modals' correlation from the global scope via the cross-attention mechanism. Extensive experiments show that MVFusion achieves state-of-the-art performance (51.7% NDS and 45.3% mAP) on the nuScenes dataset. We shall release our code and trained networks upon publication.
Information-Gathering in Latent Bandits
Jul 08, 2022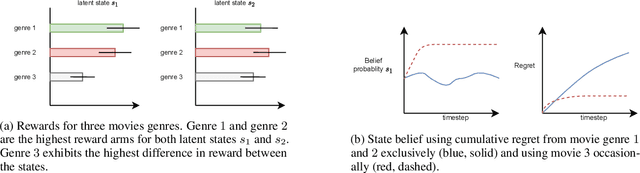
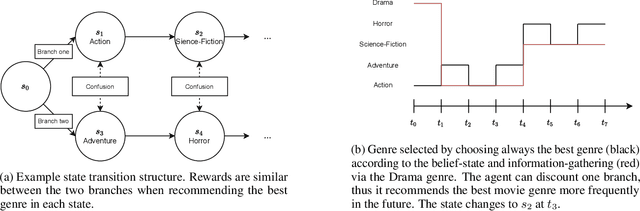
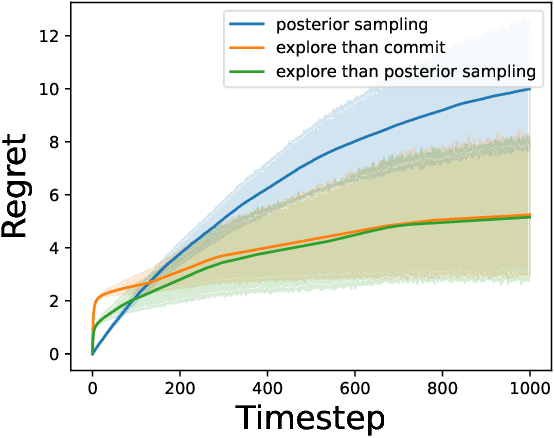
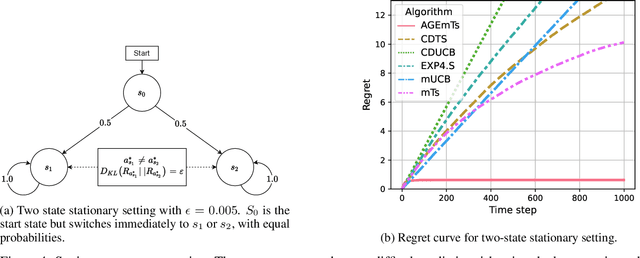
In the latent bandit problem, the learner has access to reward distributions and -- for the non-stationary variant -- transition models of the environment. The reward distributions are conditioned on the arm and unknown latent states. The goal is to use the reward history to identify the latent state, allowing for the optimal choice of arms in the future. The latent bandit setting lends itself to many practical applications, such as recommender and decision support systems, where rich data allows the offline estimation of environment models with online learning remaining a critical component. Previous solutions in this setting always choose the highest reward arm according to the agent's beliefs about the state, not explicitly considering the value of information-gathering arms. Such information-gathering arms do not necessarily provide the highest reward, thus may never be chosen by an agent that chooses the highest reward arms at all times. In this paper, we present a method for information-gathering in latent bandits. Given particular reward structures and transition matrices, we show that choosing the best arm given the agent's beliefs about the states incurs higher regret. Furthermore, we show that by choosing arms carefully, we obtain an improved estimation of the state distribution, and thus lower the cumulative regret through better arm choices in the future. We evaluate our method on both synthetic and real-world data sets, showing significant improvement in regret over state-of-the-art methods.
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023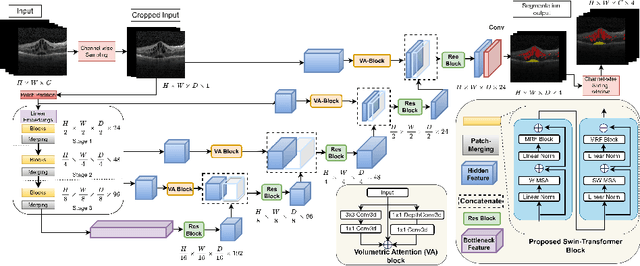
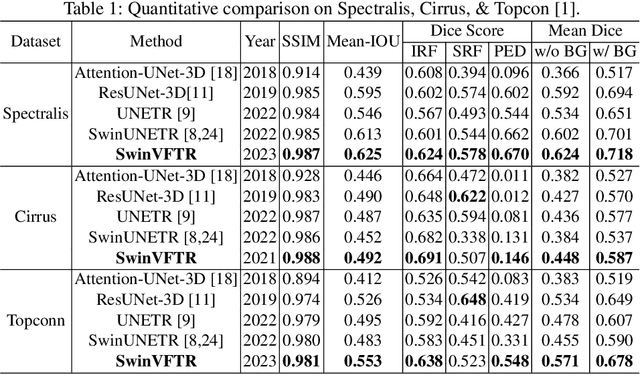
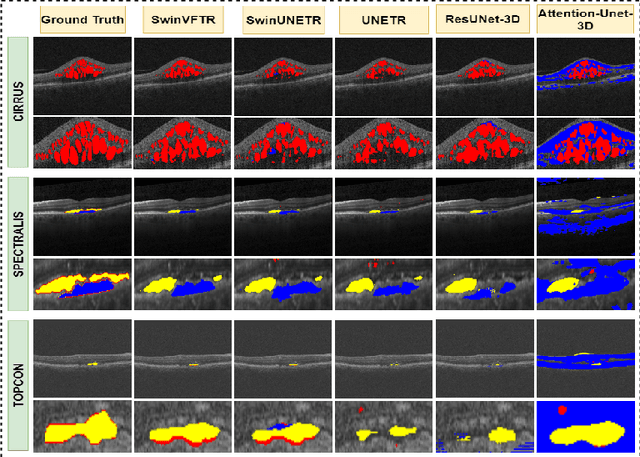
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
Efficient fair PCA for fair representation learning
Feb 26, 2023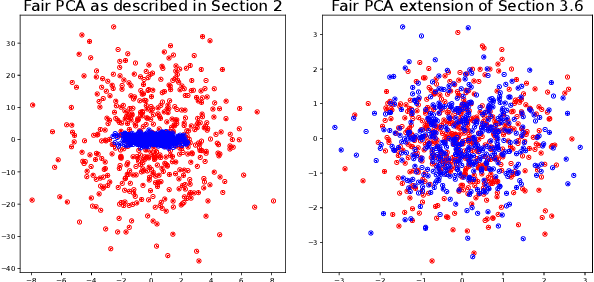
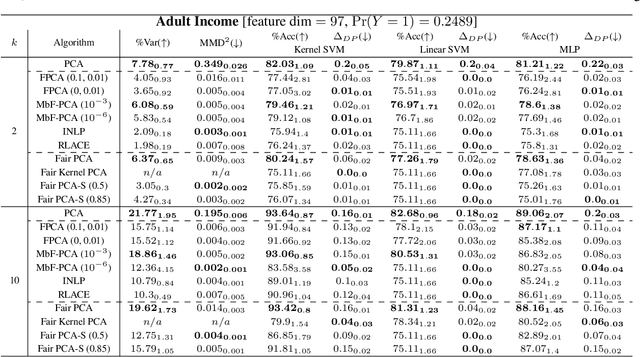
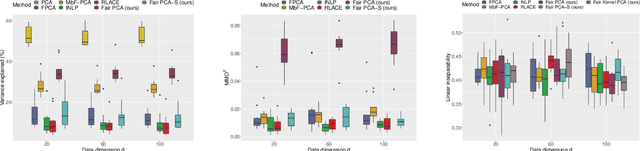

We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
Unsupervised Entity Alignment for Temporal Knowledge Graphs
Feb 01, 2023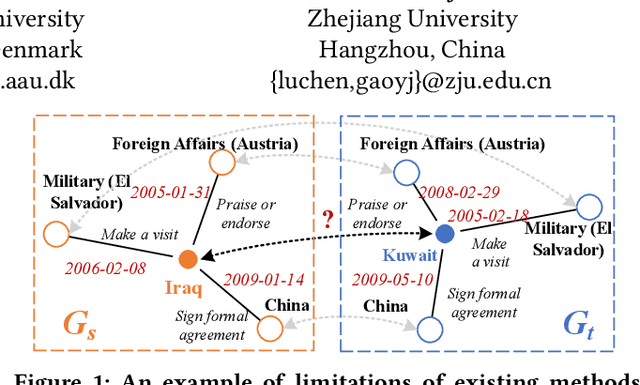
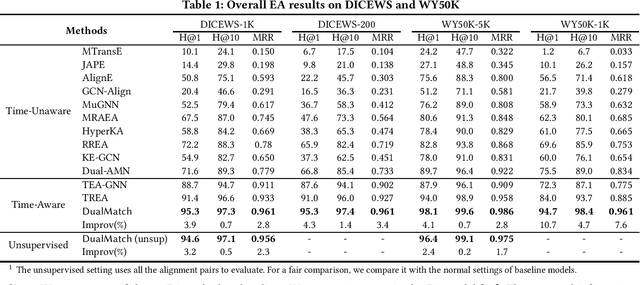
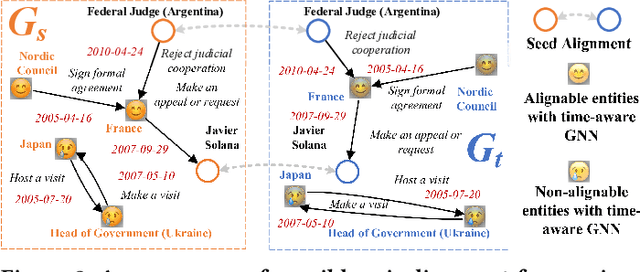
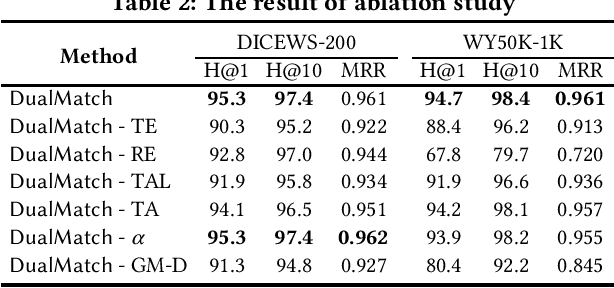
Entity alignment (EA) is a fundamental data integration task that identifies equivalent entities between different knowledge graphs (KGs). Temporal Knowledge graphs (TKGs) extend traditional knowledge graphs by introducing timestamps, which have received increasing attention. State-of-the-art time-aware EA studies have suggested that the temporal information of TKGs facilitates the performance of EA. However, existing studies have not thoroughly exploited the advantages of temporal information in TKGs. Also, they perform EA by pre-aligning entity pairs, which can be labor-intensive and thus inefficient. In this paper, we present DualMatch which effectively fuses the relational and temporal information for EA. DualMatch transfers EA on TKGs into a weighted graph matching problem. More specifically, DualMatch is equipped with an unsupervised method, which achieves EA without necessitating seed alignment. DualMatch has two steps: (i) encoding temporal and relational information into embeddings separately using a novel label-free encoder, Dual-Encoder; and (ii) fusing both information and transforming it into alignment using a novel graph-matching-based decoder, GM-Decoder. DualMatch is able to perform EA on TKGs with or without supervision, due to its capability of effectively capturing temporal information. Extensive experiments on three real-world TKG datasets offer the insight that DualMatch outperforms the state-of-the-art methods in terms of H@1 by 2.4% - 10.7% and MRR by 1.7% - 7.6%, respectively.
Automated Ensemble Search Framework for Semantic Segmentation Using Medical Imaging Labels
Mar 14, 2023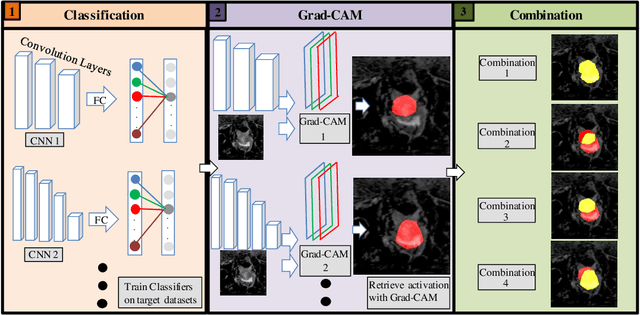
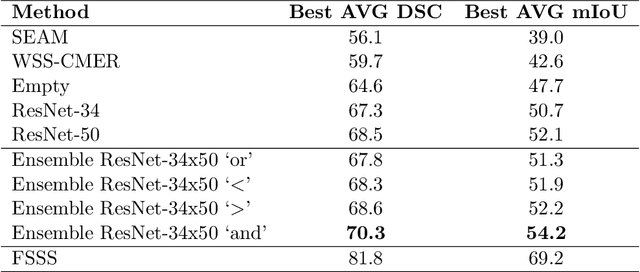
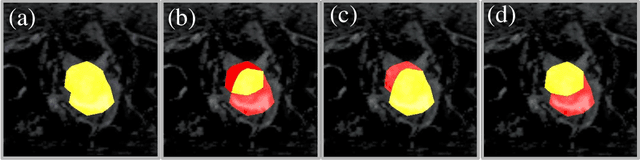
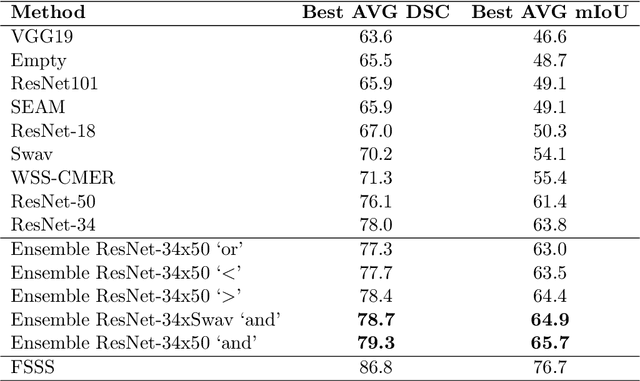
Reliable classification and detection of certain medical conditions, in images, with state-of-the-art semantic segmentation networks, require vast amounts of pixel-wise annotation. However, the public availability of such datasets is minimal. Therefore, semantic segmentation with image-level labels presents a promising alternative to this problem. Nevertheless, very few works have focused on evaluating this technique and its applicability to the medical sector. Due to their complexity and the small number of training examples in medical datasets, classifier-based weakly supervised networks like class activation maps (CAMs) struggle to extract useful information from them. However, most state-of-the-art approaches rely on them to achieve their improvements. Therefore, we propose a framework that can still utilize the low-quality CAM predictions of complicated datasets to improve the accuracy of our results. Our framework achieves that by first utilizing lower threshold CAMs to cover the target object with high certainty; second, by combining multiple low-threshold CAMs that even out their errors while highlighting the target object. We performed exhaustive experiments on the popular multi-modal BRATS and prostate DECATHLON segmentation challenge datasets. Using the proposed framework, we have demonstrated an improved dice score of up to 8% on BRATS and 6% on DECATHLON datasets compared to the previous state-of-the-art.