 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Gathering in Latent Bandits
Paper and Code
Jul 08, 2022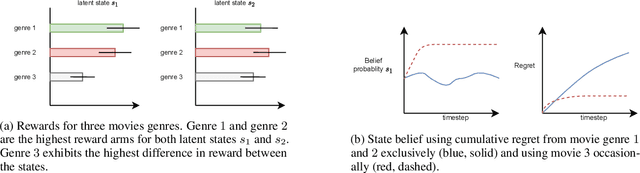
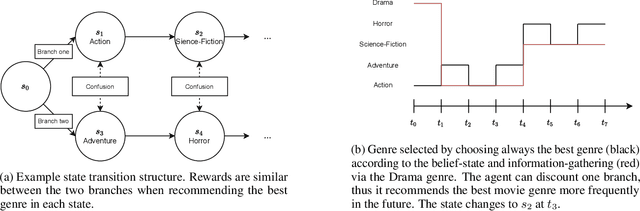
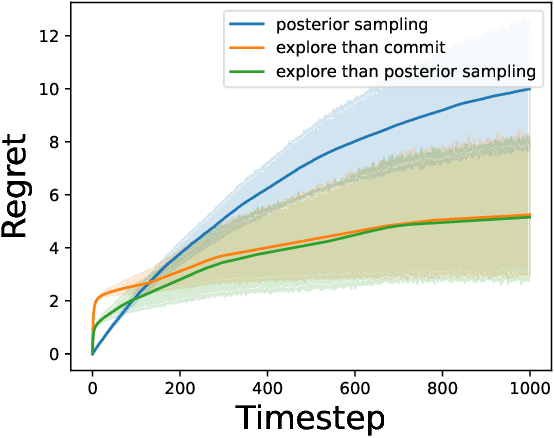
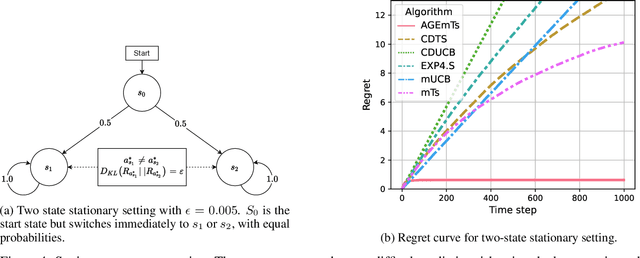
In the latent bandit problem, the learner has access to reward distributions and -- for the non-stationary variant -- transition models of the environment. The reward distributions are conditioned on the arm and unknown latent states. The goal is to use the reward history to identify the latent state, allowing for the optimal choice of arms in the future. The latent bandit setting lends itself to many practical applications, such as recommender and decision support systems, where rich data allows the offline estimation of environment models with online learning remaining a critical component. Previous solutions in this setting always choose the highest reward arm according to the agent's beliefs about the state, not explicitly considering the value of information-gathering arms. Such information-gathering arms do not necessarily provide the highest reward, thus may never be chosen by an agent that chooses the highest reward arms at all times. In this paper, we present a method for information-gathering in latent bandits. Given particular reward structures and transition matrices, we show that choosing the best arm given the agent's beliefs about the states incurs higher regret. Furthermore, we show that by choosing arms carefully, we obtain an improved estimation of the state distribution, and thus lower the cumulative regret through better arm choices in the future. We evaluate our method on both synthetic and real-world data sets, showing significant improvement in regret over state-of-the-art methods.