 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023
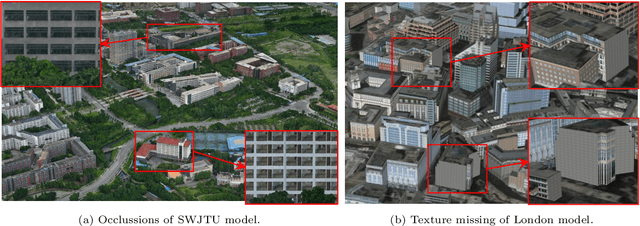
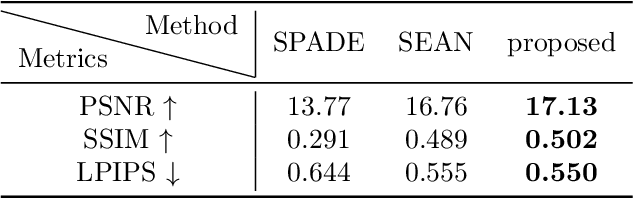
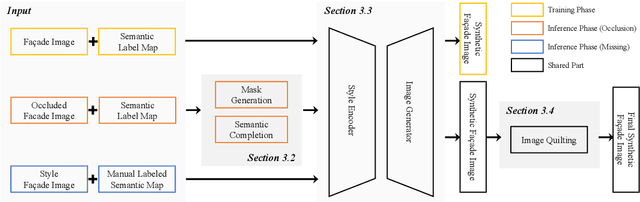

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Online Ensemble of Models for Optimal Predictive Performance with Applications to Sector Rotation Strategy
Mar 30, 2023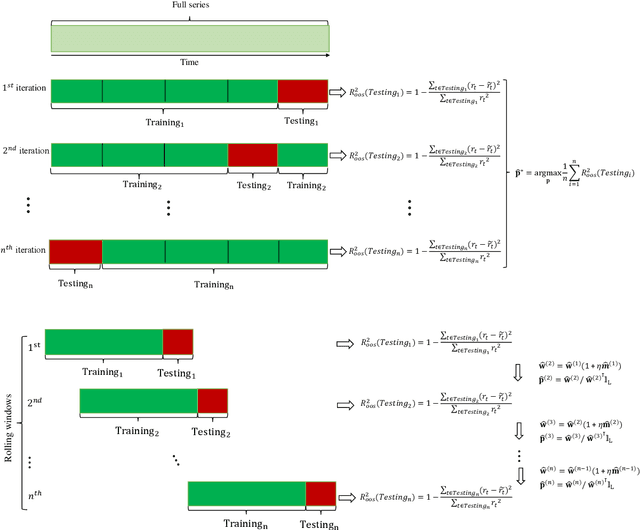

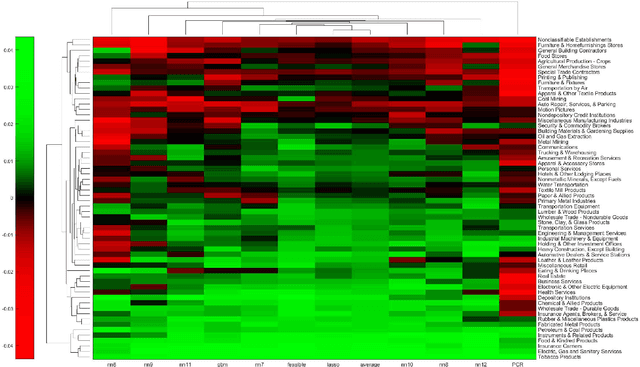
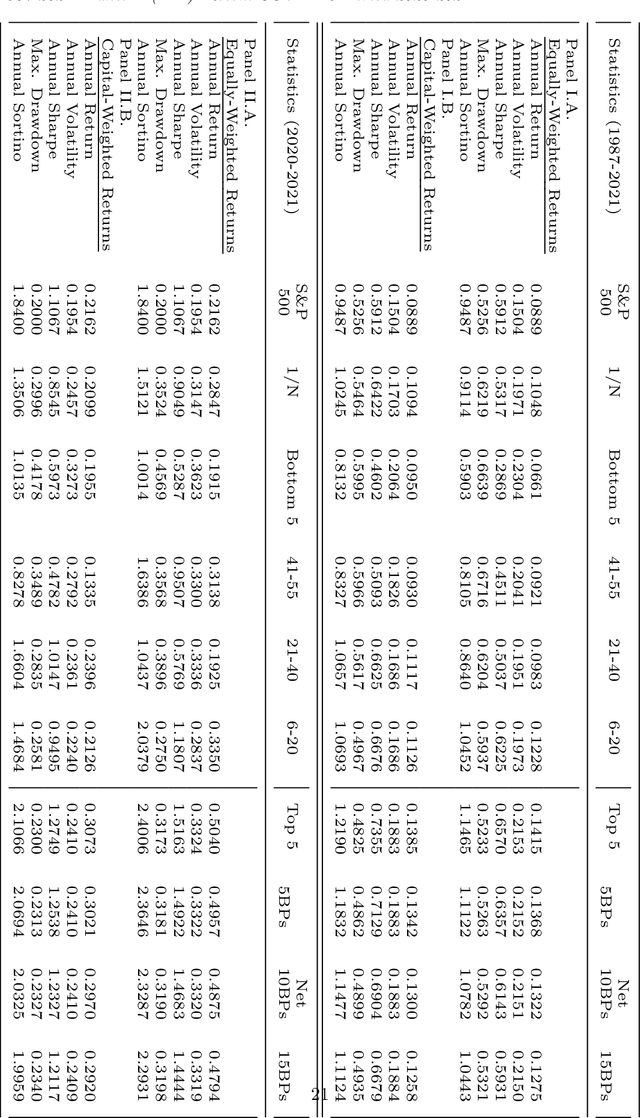
Asset-specific factors are commonly used to forecast financial returns and quantify asset-specific risk premia. Using various machine learning models, we demonstrate that the information contained in these factors leads to even larger economic gains in terms of forecasts of sector returns and the measurement of sector-specific risk premia. To capitalize on the strong predictive results of individual models for the performance of different sectors, we develop a novel online ensemble algorithm that learns to optimize predictive performance. The algorithm continuously adapts over time to determine the optimal combination of individual models by solely analyzing their most recent prediction performance. This makes it particularly suited for time series problems, rolling window backtesting procedures, and systems of potentially black-box models. We derive the optimal gain function, express the corresponding regret bounds in terms of the out-of-sample R-squared measure, and derive optimal learning rate for the algorithm. Empirically, the new ensemble outperforms both individual machine learning models and their simple averages in providing better measurements of sector risk premia. Moreover, it allows for performance attribution of different factors across various sectors, without conditioning on a specific model. Finally, by utilizing monthly predictions from our ensemble, we develop a sector rotation strategy that significantly outperforms the market. The strategy remains robust against various financial factors, periods of financial distress, and conservative transaction costs. Notably, the strategy's efficacy persists over time, exhibiting consistent improvement throughout an extended backtesting period and yielding substantial profits during the economic turbulence of the COVID-19 pandemic.
X-SepFormer: End-to-end Speaker Extraction Network with Explicit Optimization on Speaker Confusion
Mar 09, 2023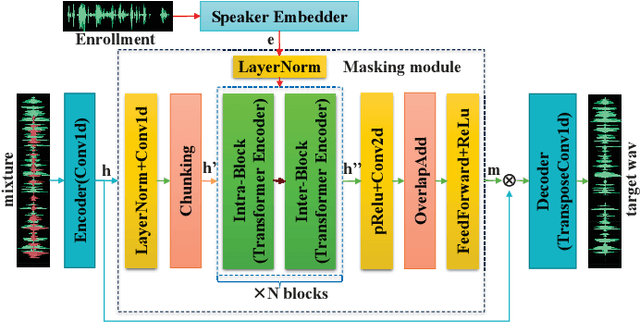
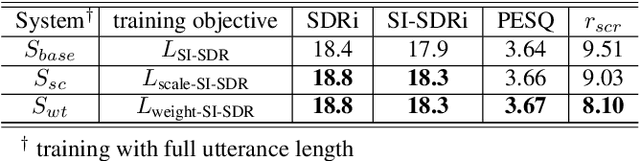
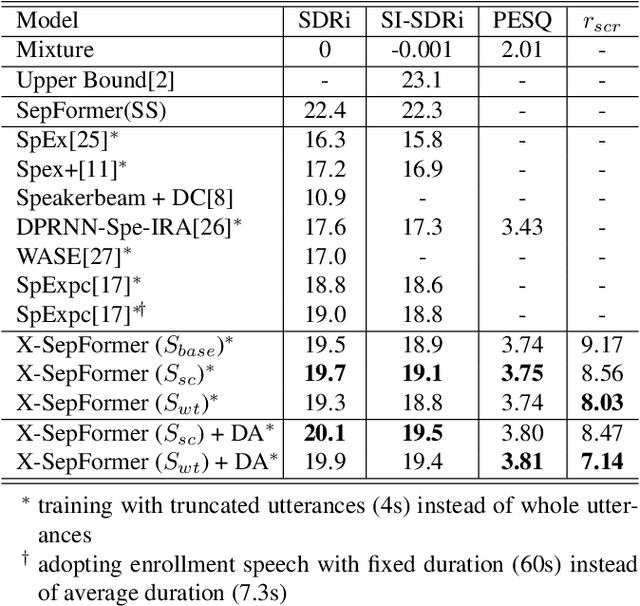
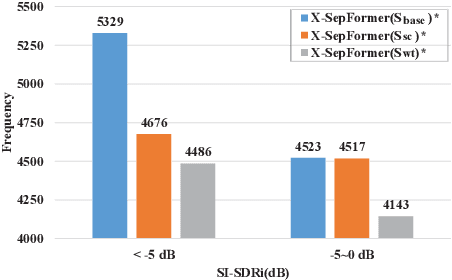
Target speech extraction (TSE) systems are designed to extract target speech from a multi-talker mixture. The popular training objective for most prior TSE networks is to enhance reconstruction performance of extracted speech waveform. However, it has been reported that a TSE system delivers high reconstruction performance may still suffer low-quality experience problems in practice. One such experience problem is wrong speaker extraction (called speaker confusion, SC), which leads to strong negative experience and hampers effective conversations. To mitigate the imperative SC issue, we reformulate the training objective and propose two novel loss schemes that explore the metric of reconstruction improvement performance defined at small chunk-level and leverage the metric associated distribution information. Both loss schemes aim to encourage a TSE network to pay attention to those SC chunks based on the said distribution information. On this basis, we present X-SepFormer, an end-to-end TSE model with proposed loss schemes and a backbone of SepFormer. Experimental results on the benchmark WSJ0-2mix dataset validate the effectiveness of our proposals, showing consistent improvements on SC errors (by 14.8% relative). Moreover, with SI-SDRi of 19.4 dB and PESQ of 3.81, our best system significantly outperforms the current SOTA systems and offers the top TSE results reported till date on the WSJ0-2mix.
Simultaneous Acquisition of High Quality RGB Image and Polarization Information using a Sparse Polarization Sensor
Sep 27, 2022
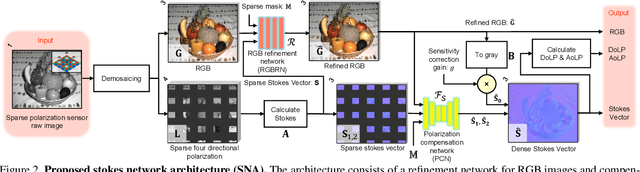
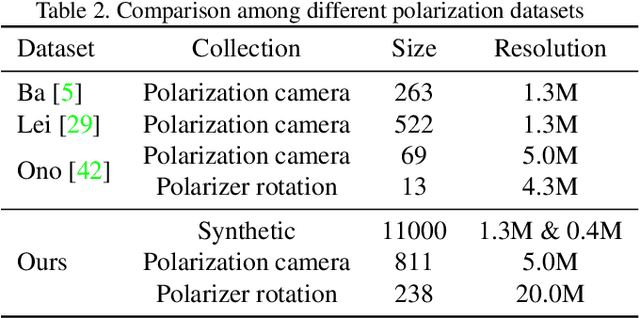
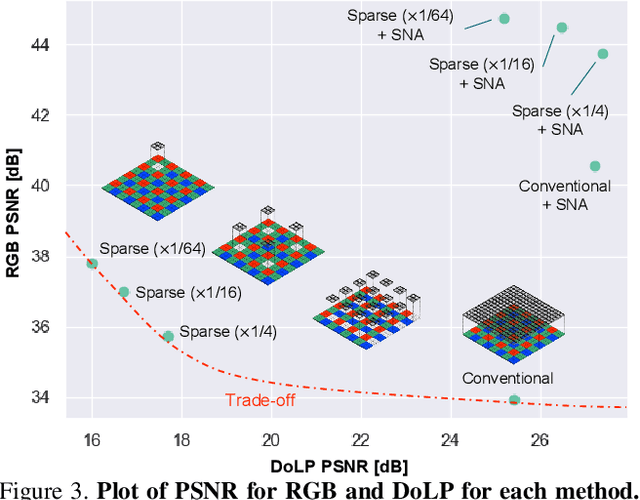
This paper proposes a novel polarization sensor structure and network architecture to obtain a high-quality RGB image and polarization information. Conventional polarization sensors can simultaneously acquire RGB images and polarization information, but the polarizers on the sensor degrade the quality of the RGB images. There is a trade-off between the quality of the RGB image and polarization information as fewer polarization pixels reduce the degradation of the RGB image but decrease the resolution of polarization information. Therefore, we propose an approach that resolves the trade-off by sparsely arranging polarization pixels on the sensor and compensating for low-resolution polarization information with higher resolution using the RGB image as a guide. Our proposed network architecture consists of an RGB image refinement network and a polarization information compensation network. We confirmed the superiority of our proposed network in compensating the differential component of polarization intensity by comparing its performance with state-of-the-art methods for similar tasks: depth completion. Furthermore, we confirmed that our approach could simultaneously acquire higher quality RGB images and polarization information than conventional polarization sensors, resolving the trade-off between the quality of RGB images and polarization information. The baseline code and newly generated real and synthetic large-scale polarization image datasets are available for further research and development.
Driver Profiling and Bayesian Workload Estimation Using Naturalistic Peripheral Detection Study Data
Mar 26, 2023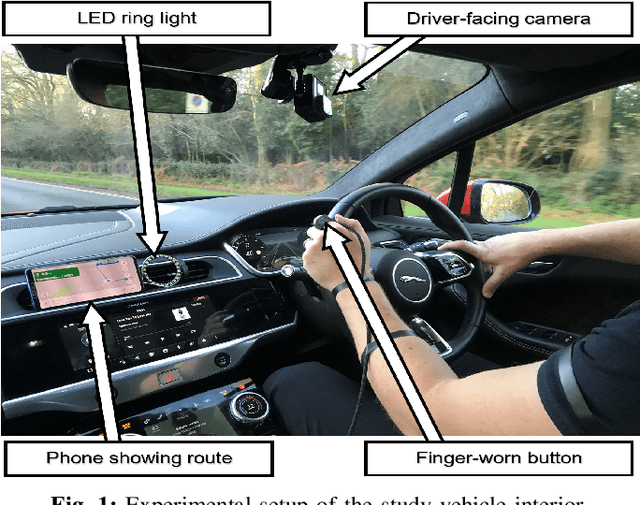
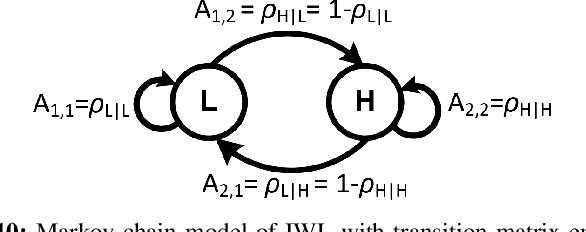
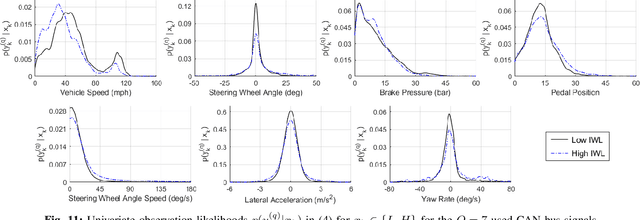
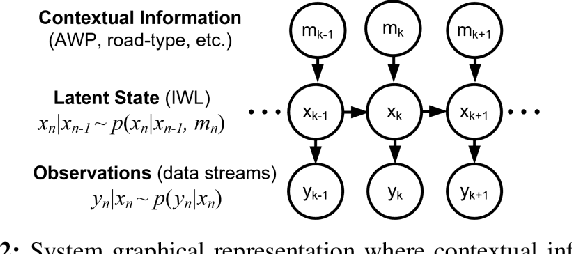
Monitoring drivers' mental workload facilitates initiating and maintaining safe interactions with in-vehicle information systems, and thus delivers adaptive human machine interaction with reduced impact on the primary task of driving. In this paper, we tackle the problem of workload estimation from driving performance data. First, we present a novel on-road study for collecting subjective workload data via a modified peripheral detection task in naturalistic settings. Key environmental factors that induce a high mental workload are identified via video analysis, e.g. junctions and behaviour of vehicle in front. Second, a supervised learning framework using state-of-the-art time series classifiers (e.g. convolutional neural network and transform techniques) is introduced to profile drivers based on the average workload they experience during a journey. A Bayesian filtering approach is then proposed for sequentially estimating, in (near) real-time, the driver's instantaneous workload. This computationally efficient and flexible method can be easily personalised to a driver (e.g. incorporate their inferred average workload profile), adapted to driving/environmental contexts (e.g. road type) and extended with data streams from new sources. The efficacy of the presented profiling and instantaneous workload estimation approaches are demonstrated using the on-road study data, showing $F_{1}$ scores of up to 92% and 81%, respectively.
CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation
Mar 21, 2023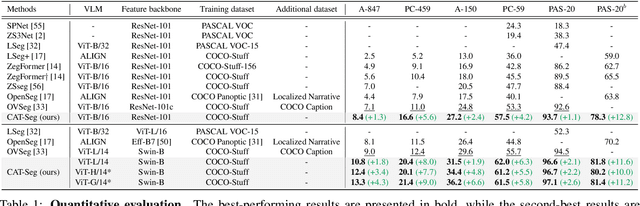
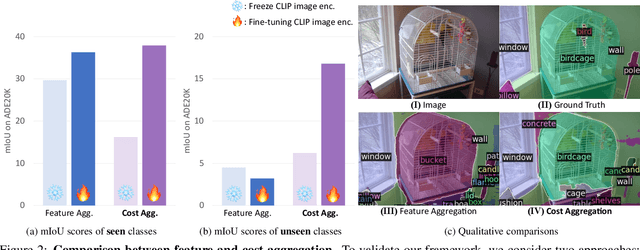
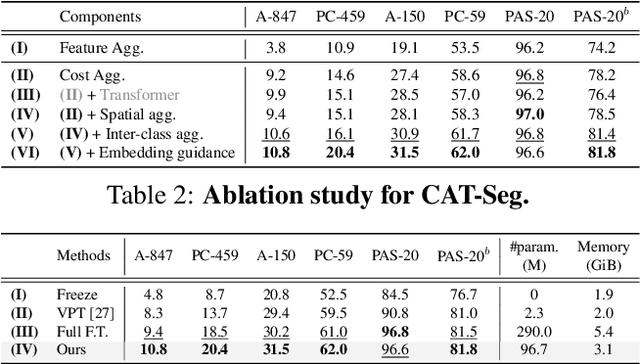

Existing works on open-vocabulary semantic segmentation have utilized large-scale vision-language models, such as CLIP, to leverage their exceptional open-vocabulary recognition capabilities. However, the problem of transferring these capabilities learned from image-level supervision to the pixel-level task of segmentation and addressing arbitrary unseen categories at inference makes this task challenging. To address these issues, we aim to attentively relate objects within an image to given categories by leveraging relational information among class categories and visual semantics through aggregation, while also adapting the CLIP representations to the pixel-level task. However, we observe that direct optimization of the CLIP embeddings can harm its open-vocabulary capabilities. In this regard, we propose an alternative approach to optimize the image-text similarity map, i.e. the cost map, using a novel cost aggregation-based method. Our framework, namely CAT-Seg, achieves state-of-the-art performance across all benchmarks. We provide extensive ablation studies to validate our choices. Project page: https://ku-cvlab.github.io/CAT-Seg/.
Rethinking Estimation Rate for Wireless Sensing: A Rate-Distortion Perspective
Mar 21, 2023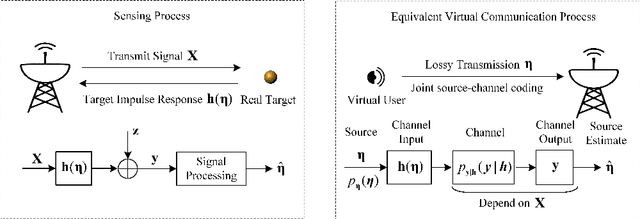
Wireless sensing has been recognized as a key enabling technology for numerous emerging applications. For decades, the sensing performance was mostly evaluated from a reliability perspective, with the efficiency aspect widely unexplored. Motivated from both backgrounds of rate-distortion theory and optimal sensing waveform design, a novel efficiency metric, namely, the sensing estimation rate (SER), is defined to unify the information- and estimation- theoretic perspectives of wireless sensing. Specifically, the active sensing process is characterized as a virtual lossy data transmission through non-cooperative joint source-channel coding. The bounds of SER are analyzed based on the data processing inequality, followed by a detailed derivation of achievable bounds under the special cases of the Gaussian linear model (GLM) and semi-controllable GLM. As for the intractable non-linear model, a computable upper bound is also given in terms of the Bayesian Cram\'er-Rao bound (BCRB). Finally, we show the rationality and effectiveness of the SER defined by comparing to the related works.
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Mar 18, 2023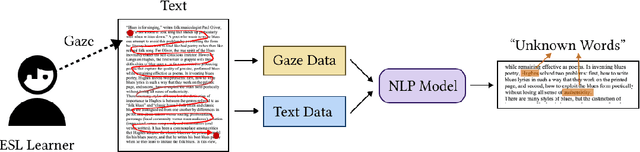
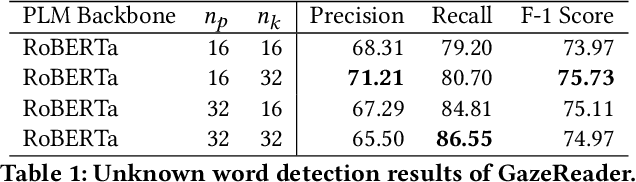
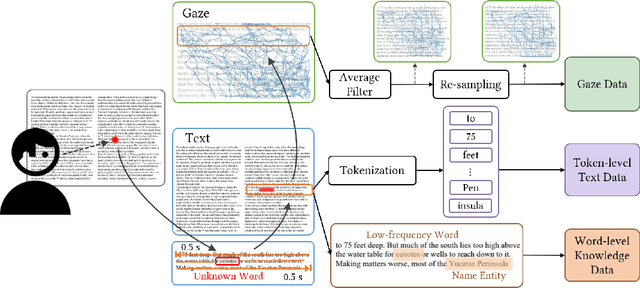

Automatic unknown word detection techniques can enable new applications for assisting English as a Second Language (ESL) learners, thus improving their reading experiences. However, most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learning model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term frequency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%, respectively. Lastly, we explored the design scope for ESL reading and discussed the findings.
Multimodal Continuous Emotion Recognition: A Technical Report for ABAW5
Mar 18, 2023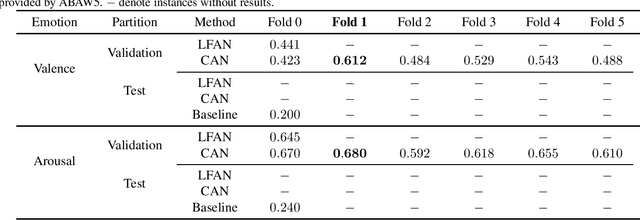
We used two multimodal models for continuous valence-arousal recognition using visual, audio, and linguistic information. The first model is the same as we used in ABAW2 and ABAW3, which employs the leader-follower attention. The second model has the same architecture for spatial and temporal encoding. As for the fusion block, it employs a compact and straightforward channel attention, borrowed from the End2You toolkit. Unlike our previous attempts that use Vggish feature directly as the audio feature, this time we feed the pre-trained VGG model using logmel-spectrogram and finetune it during the training. To make full use of the data and alleviate over-fitting, cross-validation is carried out. The fold with the highest concordance correlation coefficient is selected for submission. The code is to be available at https://github.com/sucv/ABAW5.
SottoVoce: An Ultrasound Imaging-Based Silent Speech Interaction Using Deep Neural Networks
Mar 03, 2023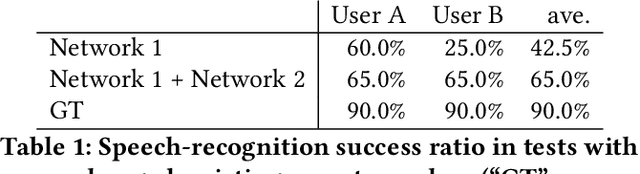
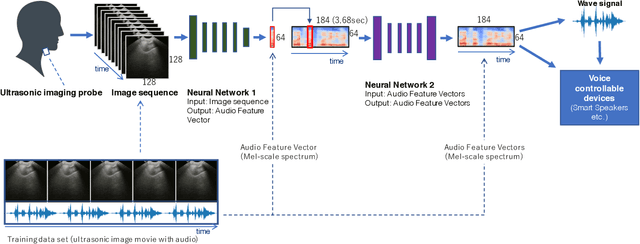
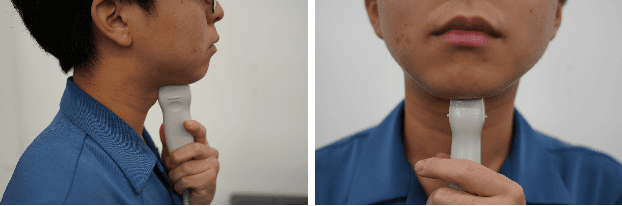
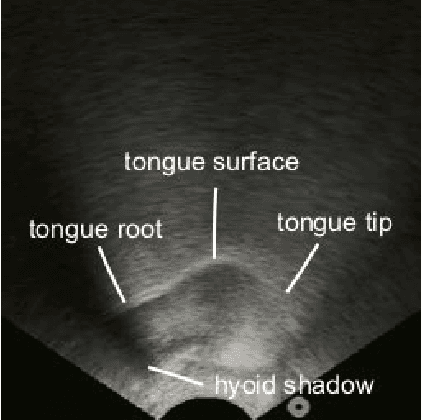
The availability of digital devices operated by voice is expanding rapidly. However, the applications of voice interfaces are still restricted. For example, speaking in public places becomes an annoyance to the surrounding people, and secret information should not be uttered. Environmental noise may reduce the accuracy of speech recognition. To address these limitations, a system to detect a user's unvoiced utterance is proposed. From internal information observed by an ultrasonic imaging sensor attached to the underside of the jaw, our proposed system recognizes the utterance contents without the user's uttering voice. Our proposed deep neural network model is used to obtain acoustic features from a sequence of ultrasound images. We confirmed that audio signals generated by our system can control the existing smart speakers. We also observed that a user can adjust their oral movement to learn and improve the accuracy of their voice recognition.
* ACM CHI 2019 paper