 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Style Transfer for 2D Talking Head Animation
Mar 22, 2023
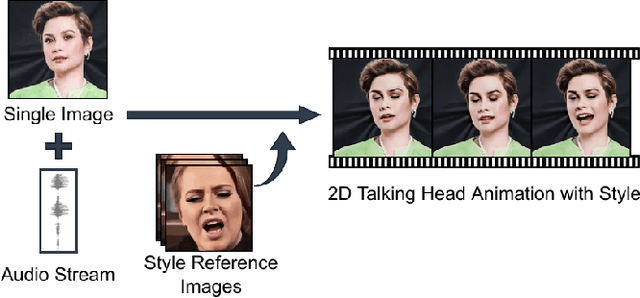
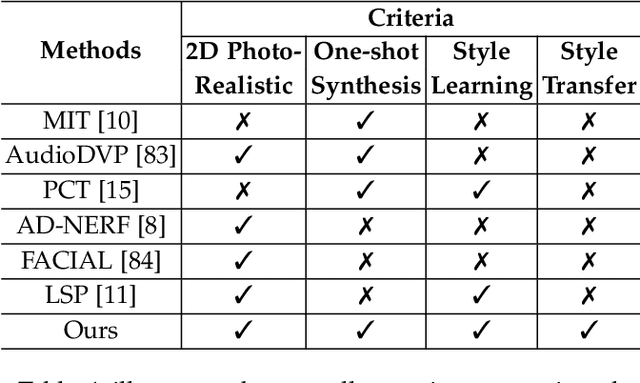
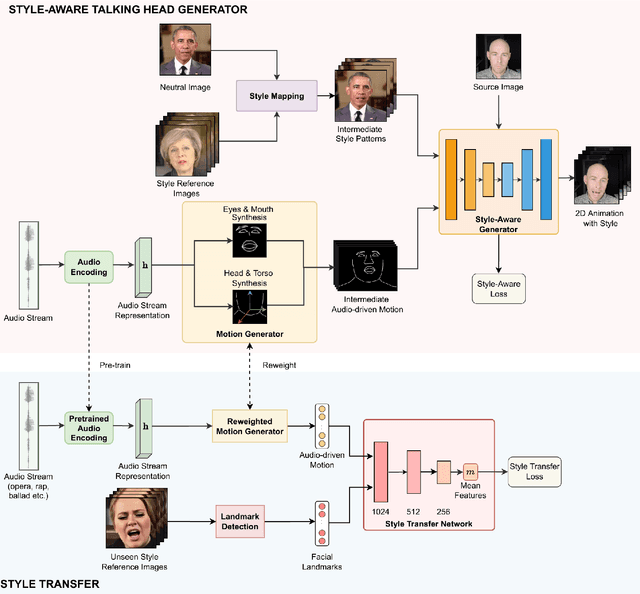
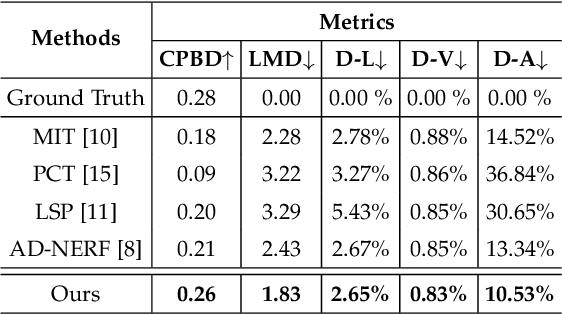
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
W2KPE: Keyphrase Extraction with Word-Word Relation
Mar 22, 2023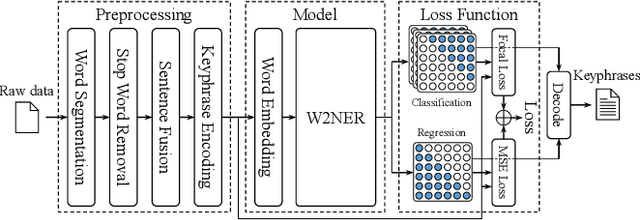
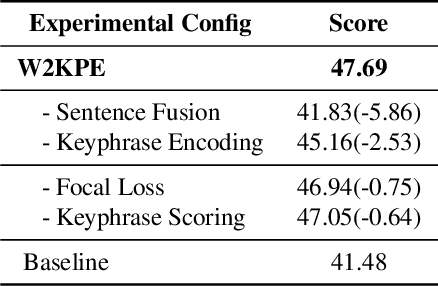
This paper describes our submission to ICASSP 2023 MUG Challenge Track 4, Keyphrase Extraction, which aims to extract keyphrases most relevant to the conference theme from conference materials. We model the challenge as a single-class Named Entity Recognition task and developed techniques for better performance on the challenge: For the data preprocessing, we encode the split keyphrases after word segmentation. In addition, we increase the amount of input information that the model can accept at one time by fusing multiple preprocessed sentences into one segment. We replace the loss function with the multi-class focal loss to address the sparseness of keyphrases. Besides, we score each appearance of keyphrases and add an extra output layer to fit the score to rank keyphrases. Exhaustive evaluations are performed to find the best combination of the word segmentation tool, the pre-trained embedding model, and the corresponding hyperparameters. With these proposals, we scored 45.04 on the final test set.
Generalized Data Thinning Using Sufficient Statistics
Mar 22, 2023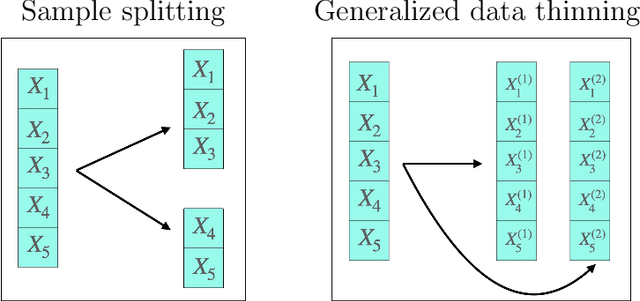
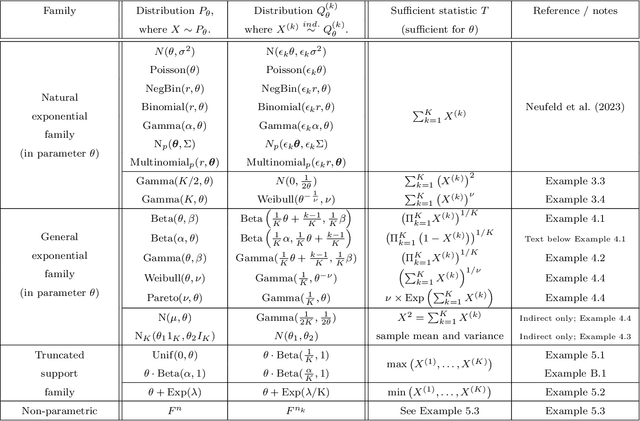
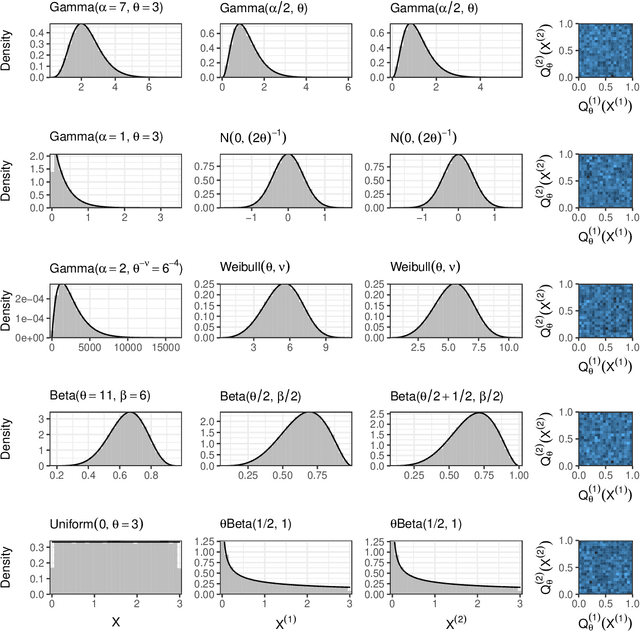
Our goal is to develop a general strategy to decompose a random variable $X$ into multiple independent random variables, without sacrificing any information about unknown parameters. A recent paper showed that for some well-known natural exponential families, $X$ can be "thinned" into independent random variables $X^{(1)}, \ldots, X^{(K)}$, such that $X = \sum_{k=1}^K X^{(k)}$. In this paper, we generalize their procedure by relaxing this summation requirement and simply asking that some known function of the independent random variables exactly reconstruct $X$. This generalization of the procedure serves two purposes. First, it greatly expands the families of distributions for which thinning can be performed. Second, it unifies sample splitting and data thinning, which on the surface seem to be very different, as applications of the same principle. This shared principle is sufficiency. We use this insight to perform generalized thinning operations for a diverse set of families.
Encoding Binary Concepts in the Latent Space of Generative Models for Enhancing Data Representation
Mar 22, 2023
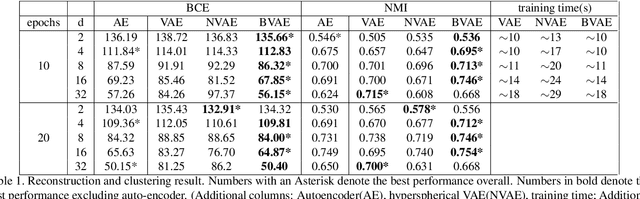
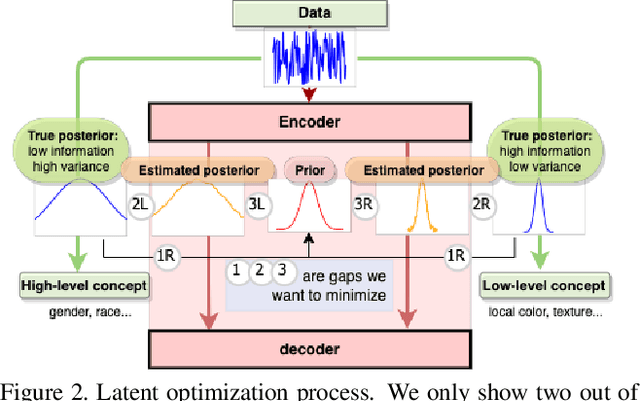
Binary concepts are empirically used by humans to generalize efficiently. And they are based on Bernoulli distribution which is the building block of information. These concepts span both low-level and high-level features such as "large vs small" and "a neuron is active or inactive". Binary concepts are ubiquitous features and can be used to transfer knowledge to improve model generalization. We propose a novel binarized regularization to facilitate learning of binary concepts to improve the quality of data generation in autoencoders. We introduce a binarizing hyperparameter $r$ in data generation process to disentangle the latent space symmetrically. We demonstrate that this method can be applied easily to existing variational autoencoder (VAE) variants to encourage symmetric disentanglement, improve reconstruction quality, and prevent posterior collapse without computation overhead. We also demonstrate that this method can boost existing models to learn more transferable representations and generate more representative samples for the input distribution which can alleviate catastrophic forgetting using generative replay under continual learning settings.
Brain subtle anomaly detection based on auto-encoders latent space analysis : application to de novo parkinson patients
Feb 27, 2023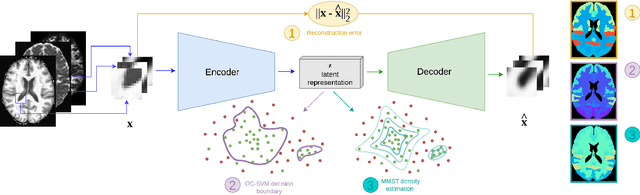
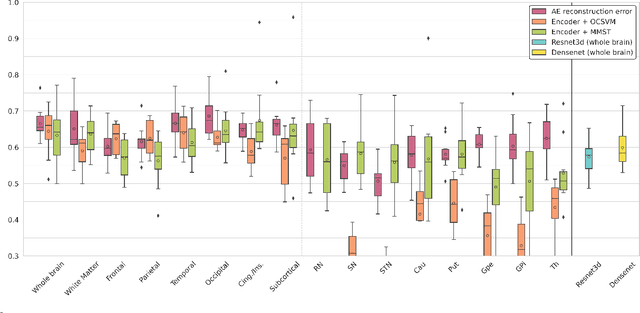
Neural network-based anomaly detection remains challenging in clinical applications with little or no supervised information and subtle anomalies such as hardly visible brain lesions. Among unsupervised methods, patch-based auto-encoders with their efficient representation power provided by their latent space, have shown good results for visible lesion detection. However, the commonly used reconstruction error criterion may limit their performance when facing less obvious lesions. In this work, we design two alternative detection criteria. They are derived from multivariate analysis and can more directly capture information from latent space representations. Their performance compares favorably with two additional supervised learning methods, on a difficult de novo Parkinson Disease (PD) classification task.
Renderable Neural Radiance Map for Visual Navigation
Mar 03, 2023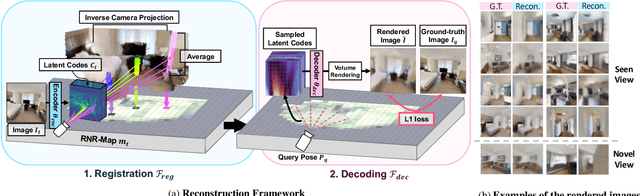
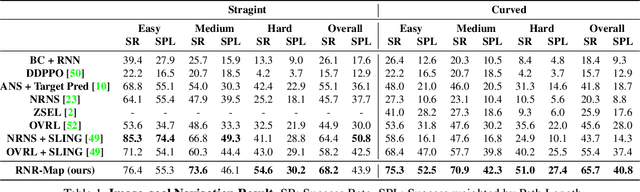
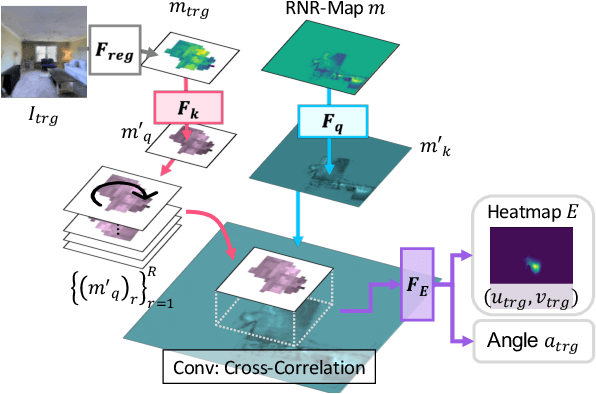
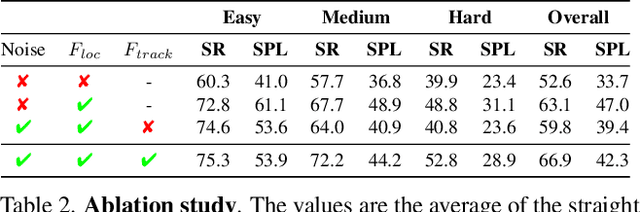
We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art.
BioSequence2Vec: Efficient Embedding Generation For Biological Sequences
Apr 01, 2023
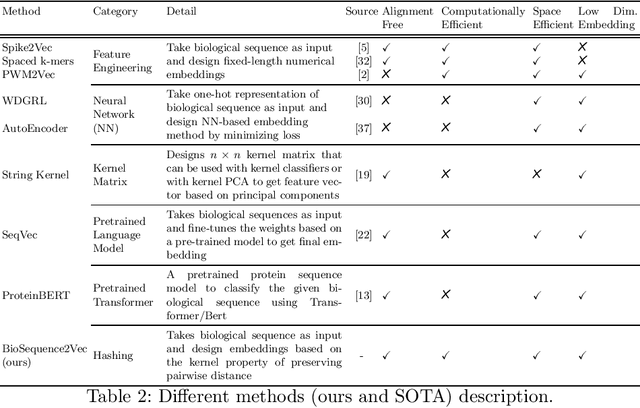
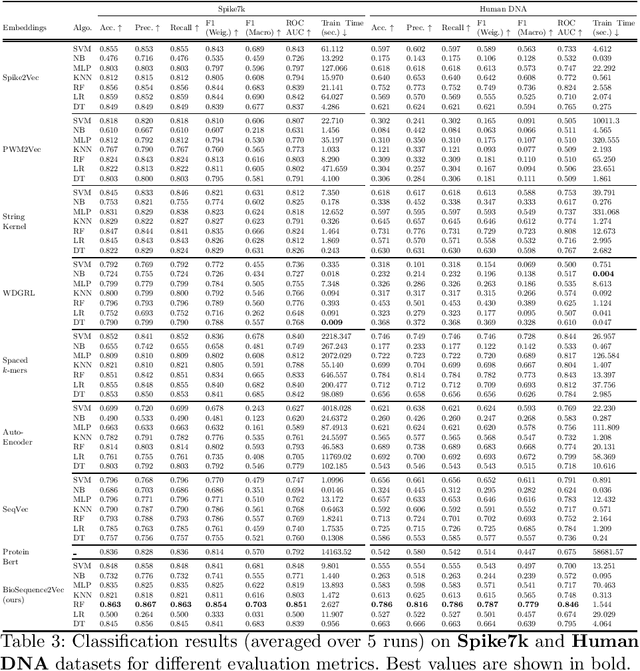
Representation learning is an important step in the machine learning pipeline. Given the current biological sequencing data volume, learning an explicit representation is prohibitive due to the dimensionality of the resulting feature vectors. Kernel-based methods, e.g., SVM, are a proven efficient and useful alternative for several machine learning (ML) tasks such as sequence classification. Three challenges with kernel methods are (i) the computation time, (ii) the memory usage (storing an $n\times n$ matrix), and (iii) the usage of kernel matrices limited to kernel-based ML methods (difficult to generalize on non-kernel classifiers). While (i) can be solved using approximate methods, challenge (ii) remains for typical kernel methods. Similarly, although non-kernel-based ML methods can be applied to kernel matrices by extracting principal components (kernel PCA), it may result in information loss, while being computationally expensive. In this paper, we propose a general-purpose representation learning approach that embodies kernel methods' qualities while avoiding computation, memory, and generalizability challenges. This involves computing a low-dimensional embedding of each sequence, using random projections of its $k$-mer frequency vectors, significantly reducing the computation needed to compute the dot product and the memory needed to store the resulting representation. Our proposed fast and alignment-free embedding method can be used as input to any distance (e.g., $k$ nearest neighbors) and non-distance (e.g., decision tree) based ML method for classification and clustering tasks. Using different forms of biological sequences as input, we perform a variety of real-world classification tasks, such as SARS-CoV-2 lineage and gene family classification, outperforming several state-of-the-art embedding and kernel methods in predictive performance.
Adaptive Federated Learning via New Entropy Approach
Apr 01, 2023
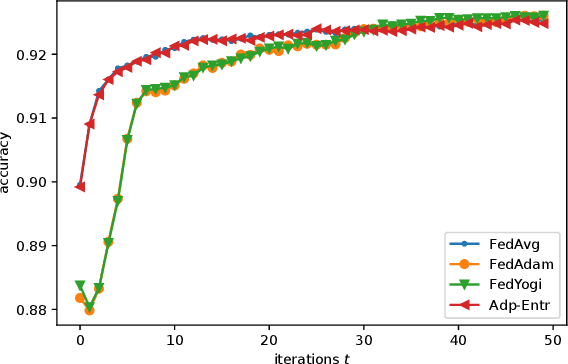
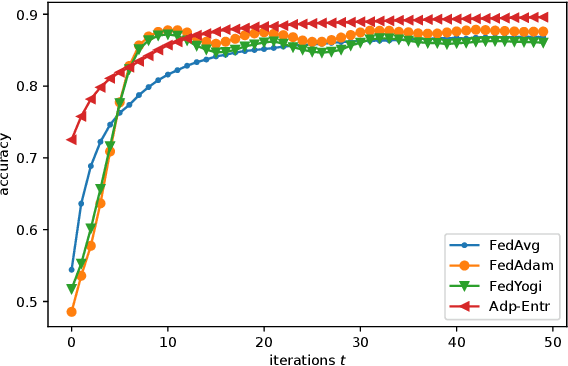
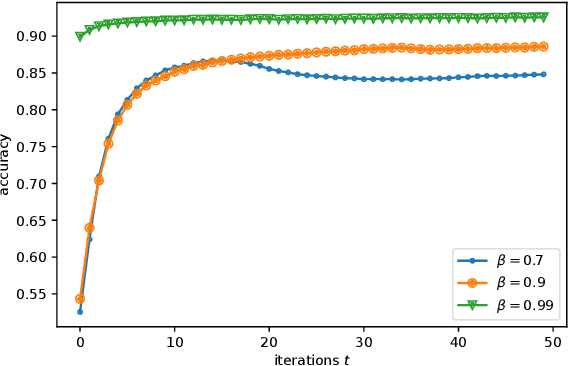
Federated Learning (FL) has recently emerged as a popular framework, which allows resource-constrained discrete clients to cooperatively learn the global model under the orchestration of a central server while storing privacy-sensitive data locally. However, due to the difference in equipment and data divergence of heterogeneous clients, there will be parameter deviation between local models, resulting in a slow convergence rate and a reduction of the accuracy of the global model. The current FL algorithms use the static client learning strategy pervasively and can not adapt to the dynamic training parameters of different clients. In this paper, by considering the deviation between different local model parameters, we propose an adaptive learning rate scheme for each client based on entropy theory to alleviate the deviation between heterogeneous clients and achieve fast convergence of the global model. It's difficult to design the optimal dynamic learning rate for each client as the local information of other clients is unknown, especially during the local training epochs without communications between local clients and the central server. To enable a decentralized learning rate design for each client, we first introduce mean-field schemes to estimate the terms related to other clients' local model parameters. Then the decentralized adaptive learning rate for each client is obtained in closed form by constructing the Hamilton equation. Moreover, we prove that there exist fixed point solutions for the mean-field estimators, and an algorithm is proposed to obtain them. Finally, extensive experimental results on real datasets show that our algorithm can effectively eliminate the deviation between local model parameters compared to other recent FL algorithms.
Data Fusion for Multipath-Based SLAM: Combing Information from Multiple Propagation Paths
Nov 24, 2022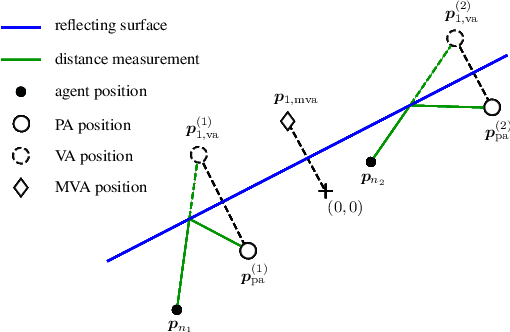
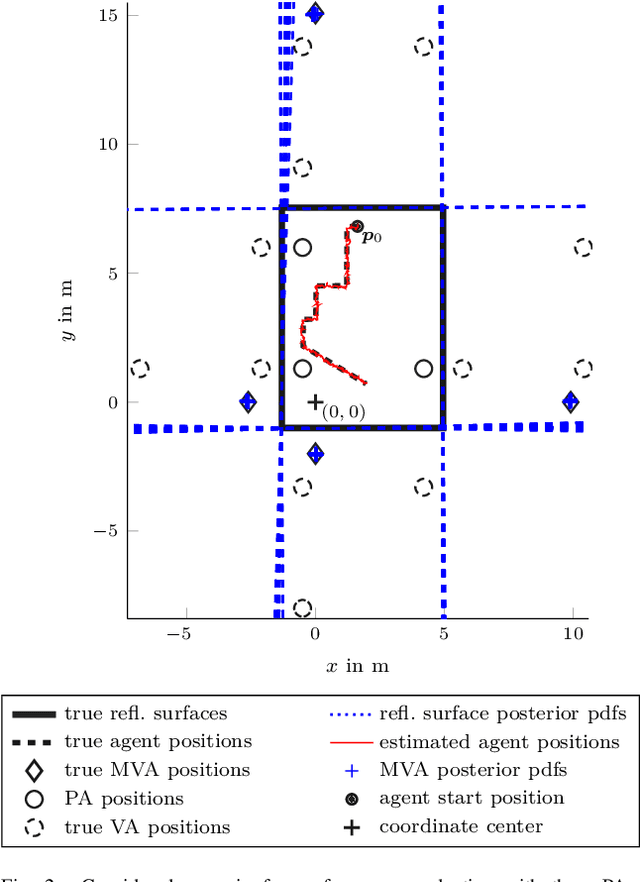
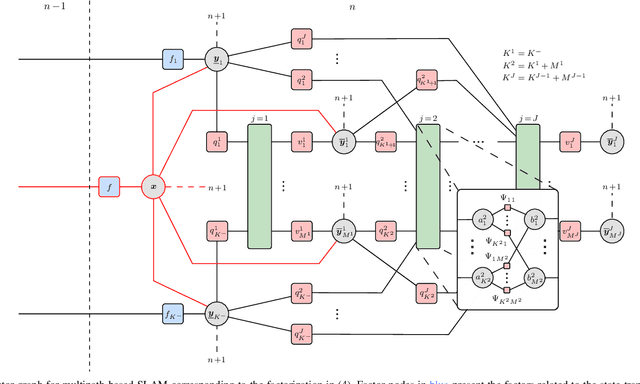
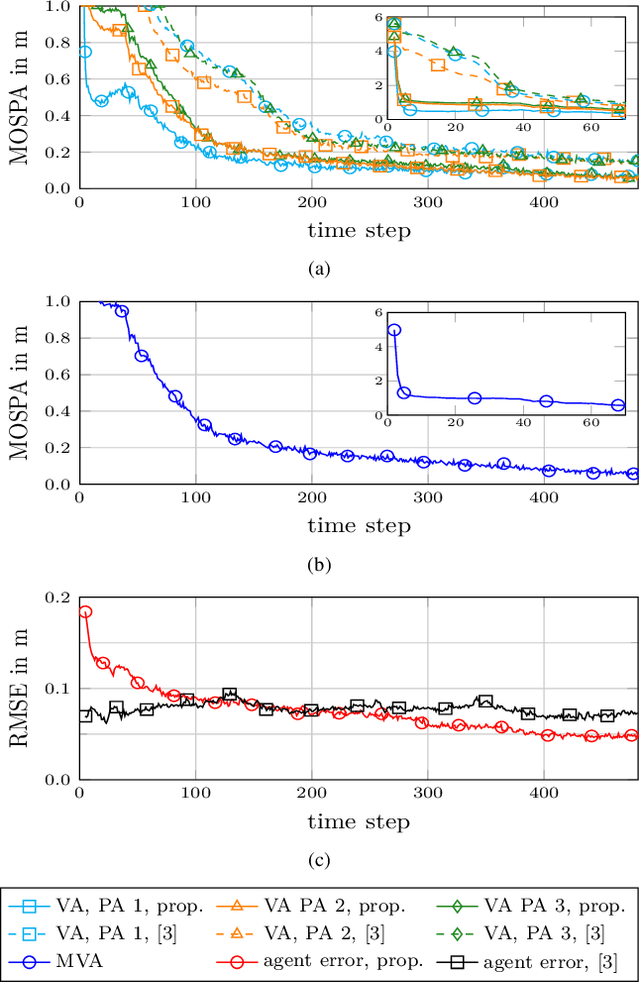
Multipath-based simultaneous localization and mapping (SLAM) is an emerging paradigm for accurate indoor localization with limited resources. The goal of multipath-based SLAM is to detect and localize radio reflective surfaces to support the estimation of time-varying positions of mobile agents. Radio reflective surfaces are typically represented by so-called virtual anchors (VAs), which are mirror images of base stations at the surfaces. In existing multipath-based SLAM methods, a VA is introduced for each propagation path, even if the goal is to map the reflective surfaces. The fact that not every reflective surface but every propagation path is modeled by a VA, complicates a consistent combination "fusion" of statistical information across multiple paths and base stations and thus limits the accuracy and mapping speed of existing multipath-based SLAM methods. In this paper, we introduce an improved statistical model and estimation method that enables data fusion for multipath-based SLAM by representing each surface by a single master virtual anchor (MVA). We further develop a particle-based sum-product algorithm (SPA) that performs probabilistic data association to compute marginal posterior distributions of MVA and agent positions efficiently. A key aspect of the proposed estimation method based on MVAs is to check the availability of single-bounce and double-bounce propagation paths at a specific agent position by means of ray-launching. The availability check is directly integrated into the statistical model by providing detection probabilities for probabilistic data association. Our numerical simulation results demonstrate significant improvements in estimation accuracy and mapping speed compared to state-of-the-art multipath-based SLAM methods.
Penalty-Based Imitation Learning With Cross Semantics Generation Sensor Fusion for Autonomous Driving
Mar 21, 2023
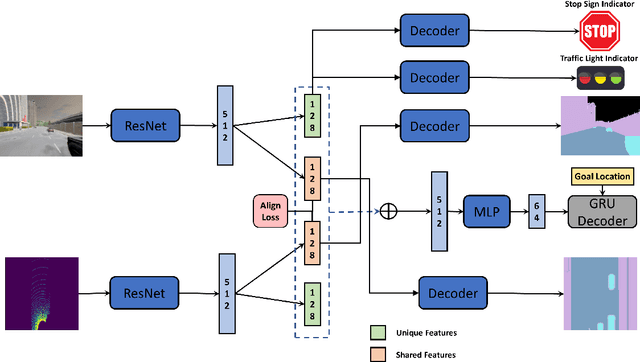
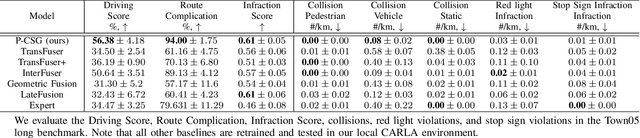
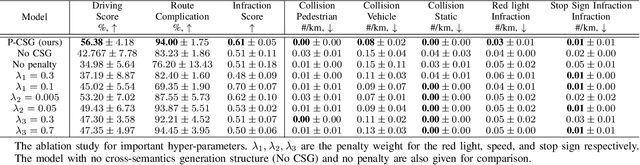
With the rapid development of Pattern Recognition and Computer Vision technologies, tasks like object detection or semantic segmentation have achieved even better accuracy than human beings. Based on these solid foundations, autonomous driving is becoming an important research direction, aiming to revolute the future of transportation and mobility. Sensors are critical to autonomous driving's security and feasibility to perceive the surrounding environment. Multi-Sensor fusion has become a current research hot spot because of its potential for multidimensional perception and integration ability. In this paper, we propose a novel feature-level multi-sensor fusion technology for end-to-end autonomous driving navigation with imitation learning. Our paper mainly focuses on fusion technologies for Lidar and RGB information. We also provide a brand-new penalty-based imitation learning method to reinforce the model's compliance with traffic rules and unify the objective of imitation learning and the metric of autonomous driving.