 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sky-GVINS: a Sky-segmentation Aided GNSS-Visual-Inertial System for Robust Navigation in Urban Canyons
Apr 08, 2023
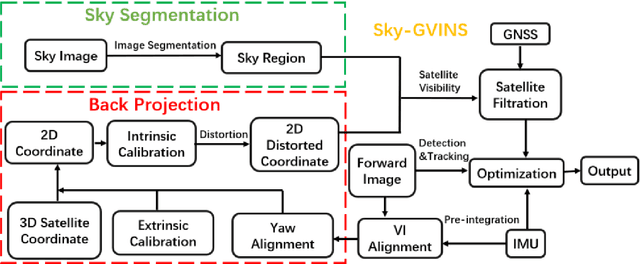

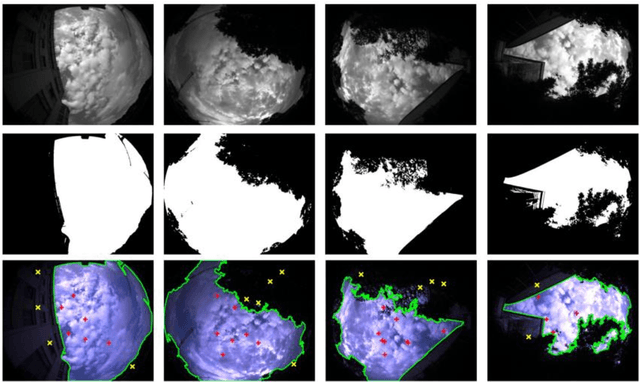

Integrating Global Navigation Satellite Systems (GNSS) in Simultaneous Localization and Mapping (SLAM) systems draws increasing attention to a global and continuous localization solution. Nonetheless, in dense urban environments, GNSS-based SLAM systems will suffer from the Non-Line-Of-Sight (NLOS) measurements, which might lead to a sharp deterioration in localization results. In this paper, we propose to detect the sky area from the up-looking camera to improve GNSS measurement reliability for more accurate position estimation. We present Sky-GVINS: a sky-aware GNSS-Visual-Inertial system based on a recent work called GVINS. Specifically, we adopt a global threshold method to segment the sky regions and non-sky regions in the fish-eye sky-pointing image and then project satellites to the image using the geometric relationship between satellites and the camera. After that, we reject satellites in non-sky regions to eliminate NLOS signals. We investigated various segmentation algorithms for sky detection and found that the Otsu algorithm reported the highest classification rate and computational efficiency, despite the algorithm's simplicity and ease of implementation. To evaluate the effectiveness of Sky-GVINS, we built a ground robot and conducted extensive real-world experiments on campus. Experimental results show that our method improves localization accuracy in both open areas and dense urban environments compared to the baseline method. Finally, we also conduct a detailed analysis and point out possible further directions for future research. For detailed information, visit our project website at https://github.com/SJTU-ViSYS/Sky-GVINS.
Next-Generation URLLC with Massive Devices: A Unified Semi-Blind Detection Framework for Sourced and Unsourced Random Access
Mar 20, 2023
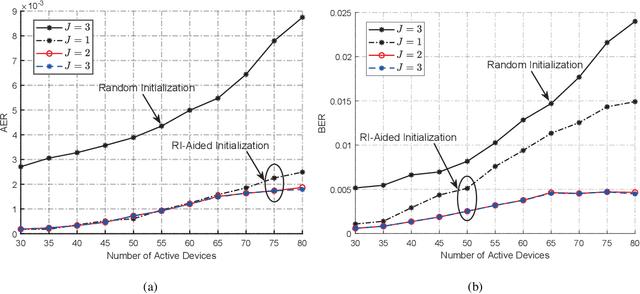
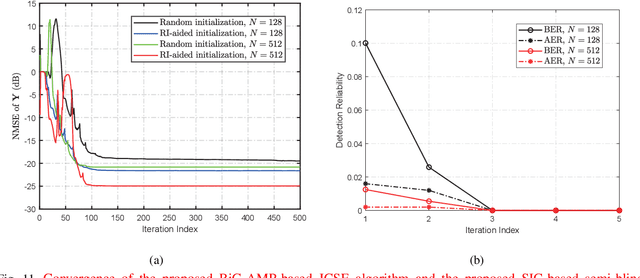
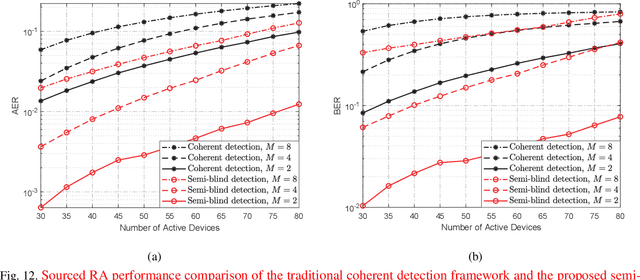
This paper proposes a unified semi-blind detection framework for sourced and unsourced random access (RA), which enables next-generation ultra-reliable low-latency communications (URLLC) with massive devices. Specifically, the active devices transmit their uplink access signals in a grant-free manner to realize ultra-low access latency. Meanwhile, the base station aims to achieve ultra-reliable data detection under severe inter-device interference without exploiting explicit channel state information (CSI). We first propose an efficient transmitter design, where a small amount of reference information (RI) is embedded in the access signal to resolve the inherent ambiguities incurred by the unknown CSI. At the receiver, we further develop a successive interference cancellation-based semi-blind detection scheme, where a bilinear generalized approximate message passing algorithm is utilized for joint channel and signal estimation (JCSE), while the embedded RI is exploited for ambiguity elimination. Particularly, a rank selection approach and a RI-aided initialization strategy are incorporated to reduce the algorithmic computational complexity and to enhance the JCSE reliability, respectively. Besides, four enabling techniques are integrated to satisfy the stringent latency and reliability requirements of massive URLLC. Numerical results demonstrate that the proposed semi-blind detection framework offers a better scalability-latency-reliability tradeoff than the state-of-the-art detection schemes dedicated to sourced or unsourced RA.
Targeted Analysis of High-Risk States Using an Oriented Variational Autoencoder
Mar 20, 2023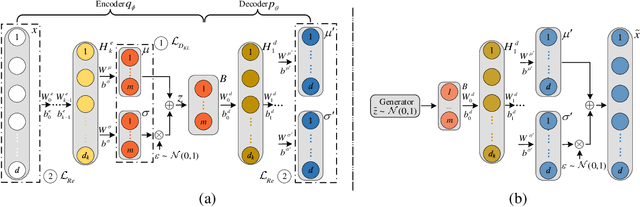
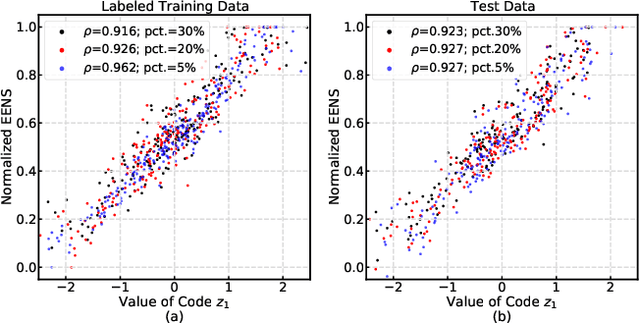
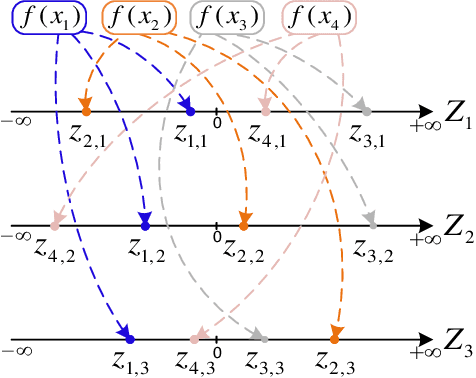
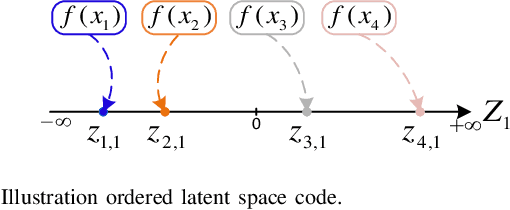
Variational autoencoder (VAE) neural networks can be trained to generate power system states that capture both marginal distribution and multivariate dependencies of historical data. The coordinates of the latent space codes of VAEs have been shown to correlate with conceptual features of the data, which can be leveraged to synthesize targeted data with desired features. However, the locations of the VAEs' latent space codes that correspond to specific properties are not constrained. Additionally, the generation of data with specific characteristics may require data with corresponding hard-to-get labels fed into the generative model for training. In this paper, to make data generation more controllable and efficient, an oriented variation autoencoder (OVAE) is proposed to constrain the link between latent space code and generated data in the form of a Spearman correlation, which provides increased control over the data synthesis process. On this basis, an importance sampling process is used to sample data in the latent space. Two cases are considered for testing the performance of the OVAE model: the data set is fully labeled with approximate information and the data set is incompletely labeled but with more accurate information. The experimental results show that, in both cases, the OVAE model correlates latent space codes with the generated data, and the efficiency of generating targeted samples is significantly improved.
DrDisco: Deep Registration for Distortion Correction of Diffusion MRI with single phase-encoding
Apr 01, 2023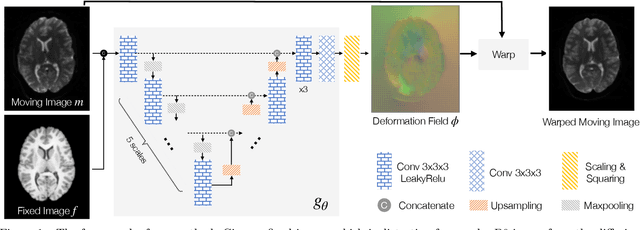
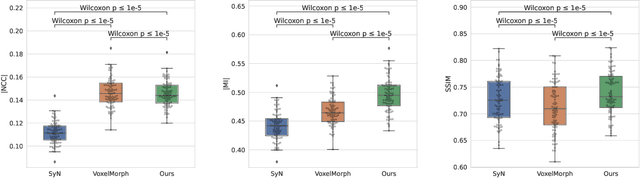
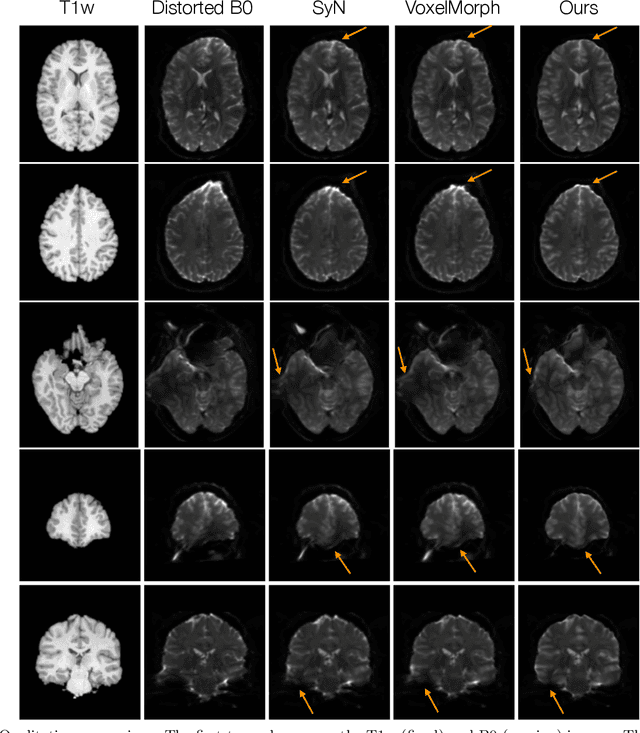
Diffusion-weighted magnetic resonance imaging (DW-MRI) is a non-invasive way of imaging white matter tracts in the human brain. DW-MRIs are usually acquired using echo-planar imaging (EPI) with high gradient fields, which could introduce severe geometric distortions that interfere with further analyses. Most tools for correcting distortion require two minimally weighted DW-MRI images (B0) acquired with different phase-encoding directions, and they can take hours to process per subject. Since a great amount of diffusion data are only acquired with a single phase-encoding direction, the application of existing approaches is limited. We propose a deep learning-based registration approach to correct distortion using only the B0 acquired from a single phase-encoding direction. Specifically, we register undistorted T1-weighted images and distorted B0 to remove the distortion through a deep learning model. We apply a differentiable mutual information loss during training to improve inter-modality alignment. Experiments on the Human Connectome Project dataset show the proposed method outperforms SyN and VoxelMorph on several metrics, and only takes a few seconds to process one subject.
EMS-Net: Efficient Multi-Temporal Self-Attention For Hyperspectral Change Detection
Mar 24, 2023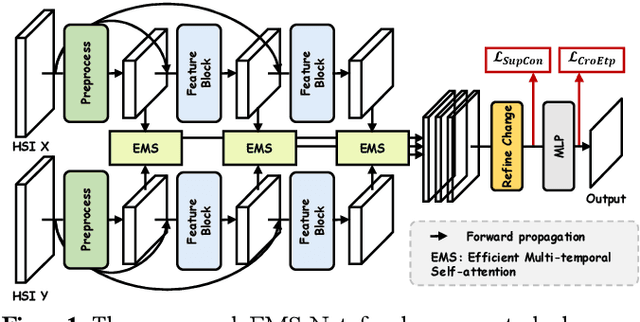
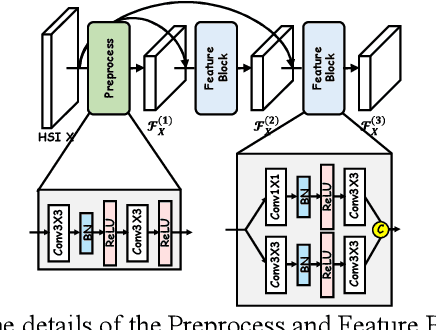
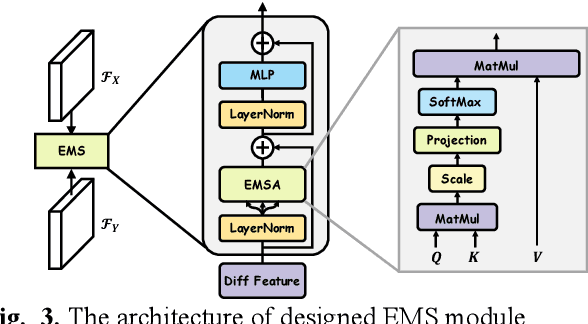
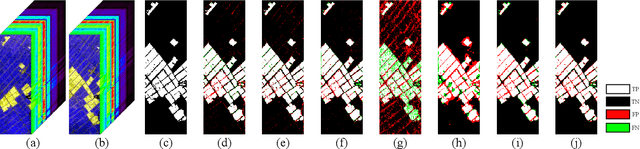
Hyperspectral change detection plays an essential role of monitoring the dynamic urban development and detecting precise fine object evolution and alteration. In this paper, we have proposed an original Efficient Multi-temporal Self-attention Network (EMS-Net) for hyperspectral change detection. The designed EMS module cuts redundancy of those similar and containing-no-changes feature maps, computing efficient multi-temporal change information for precise binary change map. Besides, to explore the clustering characteristics of the change detection, a novel supervised contrastive loss is provided to enhance the compactness of the unchanged. Experiments implemented on two hyperspectral change detection datasets manifests the out-standing performance and validity of proposed method.
Learning to Manipulate a Commitment Optimizer
Feb 23, 2023
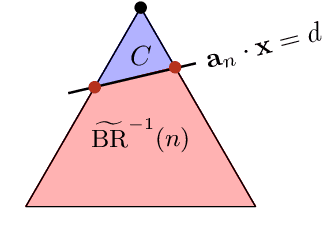


It is shown in recent studies that in a Stackelberg game the follower can manipulate the leader by deviating from their true best-response behavior. Such manipulations are computationally tractable and can be highly beneficial for the follower. Meanwhile, they may result in significant payoff losses for the leader, sometimes completely defeating their first-mover advantage. A warning to commitment optimizers, the risk these findings indicate appears to be alleviated to some extent by a strict information advantage the manipulations rely on. That is, the follower knows the full information about both players' payoffs whereas the leader only knows their own payoffs. In this paper, we study the manipulation problem with this information advantage relaxed. We consider the scenario where the follower is not given any information about the leader's payoffs to begin with but has to learn to manipulate by interacting with the leader. The follower can gather necessary information by querying the leader's optimal commitments against contrived best-response behaviors. Our results indicate that the information advantage is not entirely indispensable to the follower's manipulations: the follower can learn the optimal way to manipulate in polynomial time with polynomially many queries of the leader's optimal commitment.
Spatial Latent Representations in Generative Adversarial Networks for Image Generation
Mar 25, 2023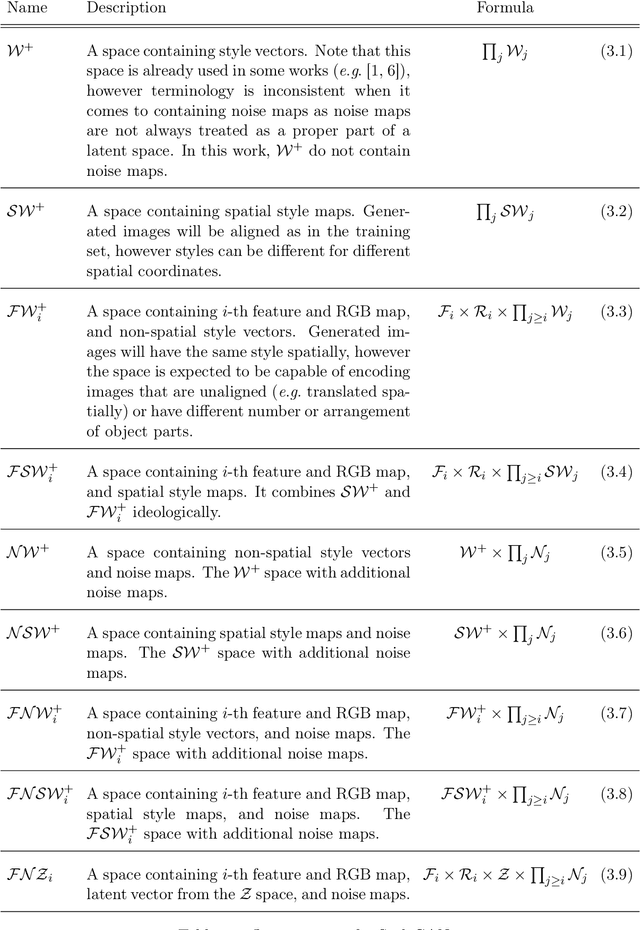
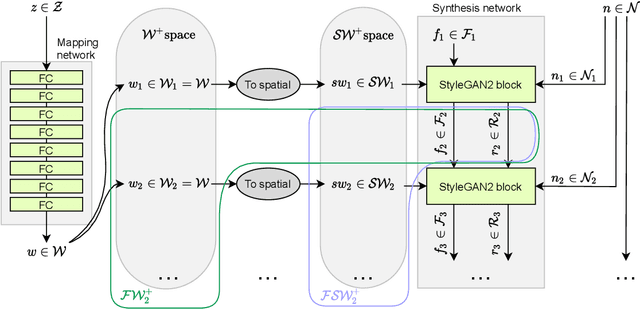
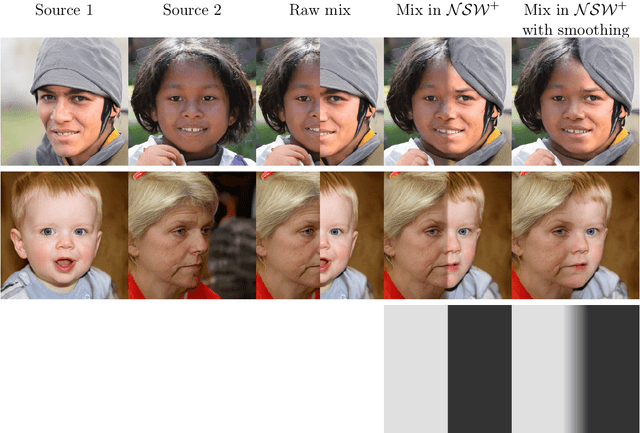

In the majority of GAN architectures, the latent space is defined as a set of vectors of given dimensionality. Such representations are not easily interpretable and do not capture spatial information of image content directly. In this work, we define a family of spatial latent spaces for StyleGAN2, capable of capturing more details and representing images that are out-of-sample in terms of the number and arrangement of object parts, such as an image of multiple faces or a face with more than two eyes. We propose a method for encoding images into our spaces, together with an attribute model capable of performing attribute editing in these spaces. We show that our spaces are effective for image manipulation and encode semantic information well. Our approach can be used on pre-trained generator models, and attribute edition can be done using pre-generated direction vectors making the barrier to entry for experimentation and use extremely low. We propose a regularization method for optimizing latent representations, which equalizes distributions of parts of latent spaces, making representations much closer to generated ones. We use it for encoding images into spatial spaces to obtain significant improvement in quality while keeping semantics and ability to use our attribute model for edition purposes. In total, using our methods gives encoding quality boost even as high as 30% in terms of LPIPS score comparing to standard methods, while keeping semantics. Additionally, we propose a StyleGAN2 training procedure on our spatial latent spaces, together with a custom spatial latent representation distribution to make spatially closer elements in the representation more dependent on each other than farther elements. Such approach improves the FID score by 29% on SpaceNet, and is able to generate consistent images of arbitrary sizes on spatially homogeneous datasets, like satellite imagery.
Incomplete Multi-View Multi-Label Learning via Label-Guided Masked View- and Category-Aware Transformers
Mar 13, 2023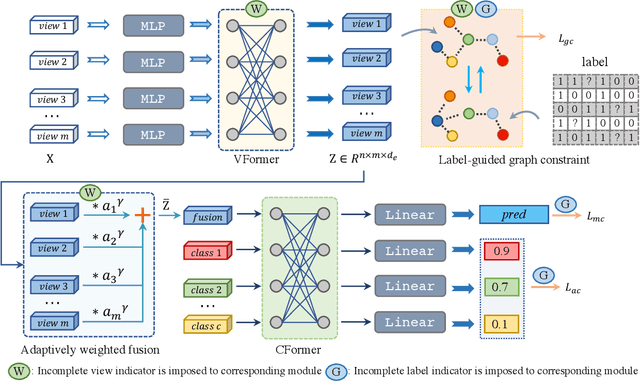

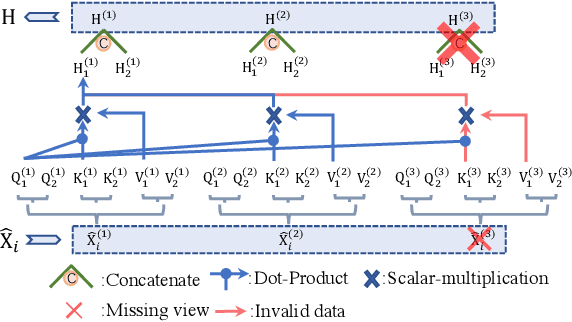

As we all know, multi-view data is more expressive than single-view data and multi-label annotation enjoys richer supervision information than single-label, which makes multi-view multi-label learning widely applicable for various pattern recognition tasks. In this complex representation learning problem, three main challenges can be characterized as follows: i) How to learn consistent representations of samples across all views? ii) How to exploit and utilize category correlations of multi-label to guide inference? iii) How to avoid the negative impact resulting from the incompleteness of views or labels? To cope with these problems, we propose a general multi-view multi-label learning framework named label-guided masked view- and category-aware transformers in this paper. First, we design two transformer-style based modules for cross-view features aggregation and multi-label classification, respectively. The former aggregates information from different views in the process of extracting view-specific features, and the latter learns subcategory embedding to improve classification performance. Second, considering the imbalance of expressive power among views, an adaptively weighted view fusion module is proposed to obtain view-consistent embedding features. Third, we impose a label manifold constraint in sample-level representation learning to maximize the utilization of supervised information. Last but not least, all the modules are designed under the premise of incomplete views and labels, which makes our method adaptable to arbitrary multi-view and multi-label data. Extensive experiments on five datasets confirm that our method has clear advantages over other state-of-the-art methods.
Isolated Sign Language Recognition based on Tree Structure Skeleton Images
Apr 10, 2023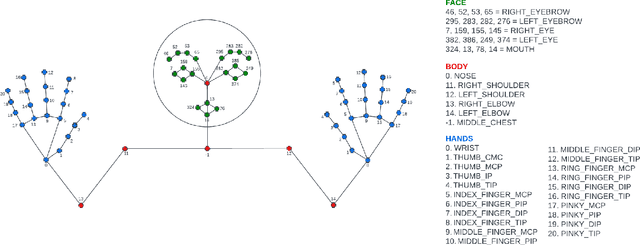
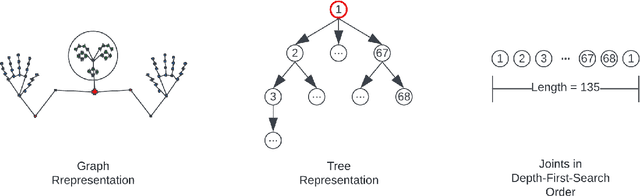

Sign Language Recognition (SLR) systems aim to be embedded in video stream platforms to recognize the sign performed in front of a camera. SLR research has taken advantage of recent advances in pose estimation models to use skeleton sequences estimated from videos instead of RGB information to predict signs. This approach can make HAR-related tasks less complex and more robust to diverse backgrounds, lightning conditions, and physical appearances. In this work, we explore the use of a spatio-temporal skeleton representation such as Tree Structure Skeleton Image (TSSI) as an alternative input to improve the accuracy of skeleton-based models for SLR. TSSI converts a skeleton sequence into an RGB image where the columns represent the joints of the skeleton in a depth-first tree traversal order, the rows represent the temporal evolution of the joints, and the three channels represent the (x, y, z) coordinates of the joints. We trained a DenseNet-121 using this type of input and compared it with other skeleton-based deep learning methods using a large-scale American Sign Language (ASL) dataset, WLASL. Our model (SL-TSSI-DenseNet) overcomes the state-of-the-art of other skeleton-based models. Moreover, when including data augmentation our proposal achieves better results than both skeleton-based and RGB-based models. We evaluated the effectiveness of our model on the Ankara University Turkish Sign Language (TSL) dataset, AUTSL, and a Mexican Sign Language (LSM) dataset. On the AUTSL dataset, the model achieves similar results to the state-of-the-art of other skeleton-based models. On the LSM dataset, the model achieves higher results than the baseline. Code has been made available at: https://github.com/davidlainesv/SL-TSSI-DenseNet.
LADER: Log-Augmented DEnse Retrieval for Biomedical Literature Search
Apr 10, 2023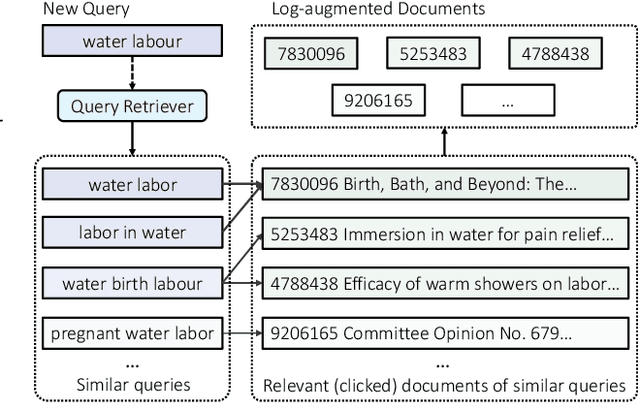
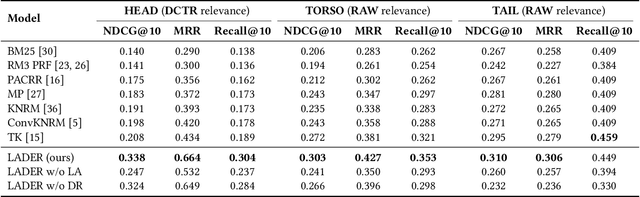
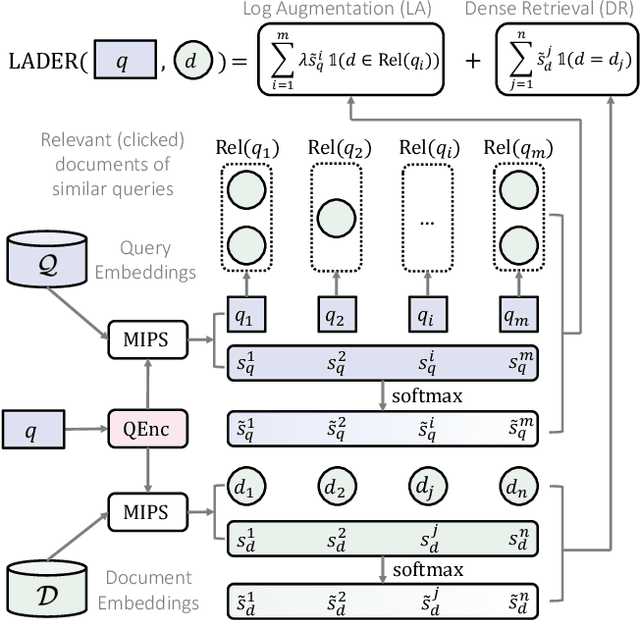
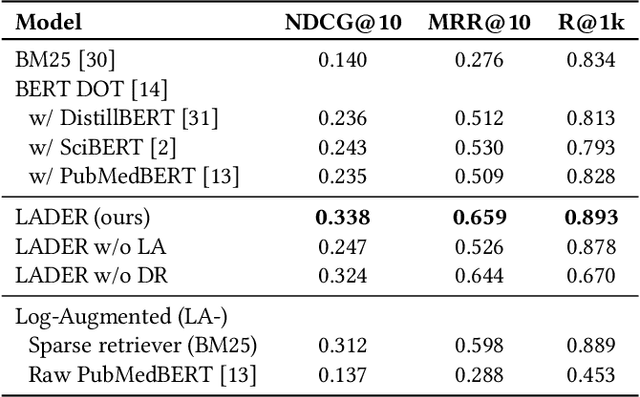
Queries with similar information needs tend to have similar document clicks, especially in biomedical literature search engines where queries are generally short and top documents account for most of the total clicks. Motivated by this, we present a novel architecture for biomedical literature search, namely Log-Augmented DEnse Retrieval (LADER), which is a simple plug-in module that augments a dense retriever with the click logs retrieved from similar training queries. Specifically, LADER finds both similar documents and queries to the given query by a dense retriever. Then, LADER scores relevant (clicked) documents of similar queries weighted by their similarity to the input query. The final document scores by LADER are the average of (1) the document similarity scores from the dense retriever and (2) the aggregated document scores from the click logs of similar queries. Despite its simplicity, LADER achieves new state-of-the-art (SOTA) performance on TripClick, a recently released benchmark for biomedical literature retrieval. On the frequent (HEAD) queries, LADER largely outperforms the best retrieval model by 39% relative NDCG@10 (0.338 v.s. 0.243). LADER also achieves better performance on the less frequent (TORSO) queries with 11% relative NDCG@10 improvement over the previous SOTA (0.303 v.s. 0.272). On the rare (TAIL) queries where similar queries are scarce, LADER still compares favorably to the previous SOTA method (NDCG@10: 0.310 v.s. 0.295). On all queries, LADER can improve the performance of a dense retriever by 24%-37% relative NDCG@10 while not requiring additional training, and further performance improvement is expected from more logs. Our regression analysis has shown that queries that are more frequent, have higher entropy of query similarity and lower entropy of document similarity, tend to benefit more from log augmentation.