 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CT Multi-Task Learning with a Large Image-Text (LIT) Model
Apr 03, 2023
Large language models (LLM) not only empower multiple language tasks but also serve as a general interface across different spaces. Up to now, it has not been demonstrated yet how to effectively translate the successes of LLMs in the computer vision field to the medical imaging field which involves high-dimensional and multi-modal medical images. In this paper, we report a feasibility study of building a multi-task CT large image-text (LIT) model for lung cancer diagnosis by combining an LLM and a large image model (LIM). Specifically, the LLM and LIM are used as encoders to perceive multi-modal information under task-specific text prompts, which synergizes multi-source information and task-specific and patient-specific priors for optimized diagnostic performance. The key components of our LIT model and associated techniques are evaluated with an emphasis on 3D lung CT analysis. Our initial results show that the LIT model performs multiple medical tasks well, including lung segmentation, lung nodule detection, and lung cancer classification. Active efforts are in progress to develop large image-language models for superior medical imaging in diverse applications and optimal patient outcomes.
TiDy-PSFs: Computational Imaging with Time-Averaged Dynamic Point-Spread-Functions
Mar 30, 2023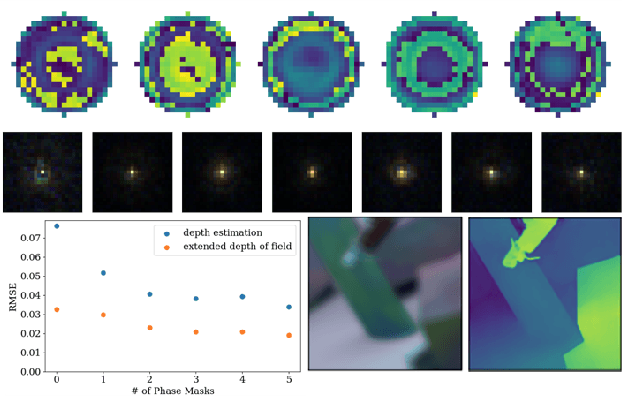
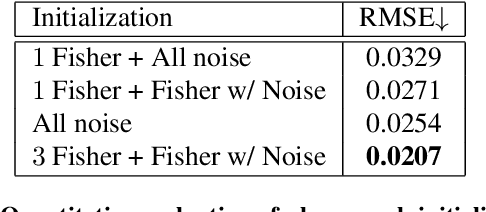

Point-spread-function (PSF) engineering is a powerful computational imaging techniques wherein a custom phase mask is integrated into an optical system to encode additional information into captured images. Used in combination with deep learning, such systems now offer state-of-the-art performance at monocular depth estimation, extended depth-of-field imaging, lensless imaging, and other tasks. Inspired by recent advances in spatial light modulator (SLM) technology, this paper answers a natural question: Can one encode additional information and achieve superior performance by changing a phase mask dynamically over time? We first prove that the set of PSFs described by static phase masks is non-convex and that, as a result, time-averaged PSFs generated by dynamic phase masks are fundamentally more expressive. We then demonstrate, in simulation, that time-averaged dynamic (TiDy) phase masks can offer substantially improved monocular depth estimation and extended depth-of-field imaging performance.
SARF: Aliasing Relation Assisted Self-Supervised Learning for Few-shot Relation Reasoning
Apr 20, 2023
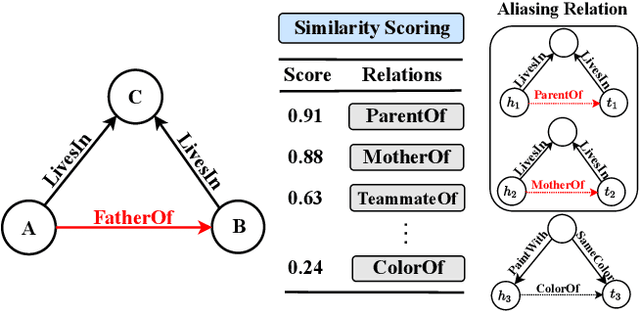
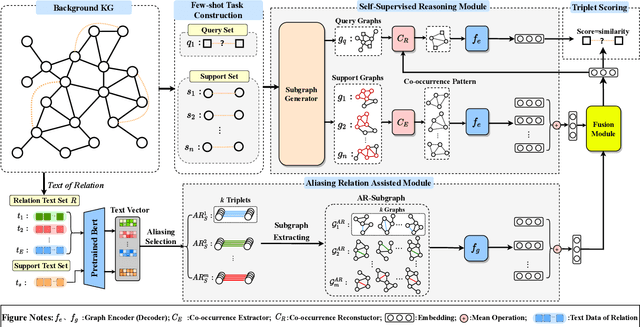
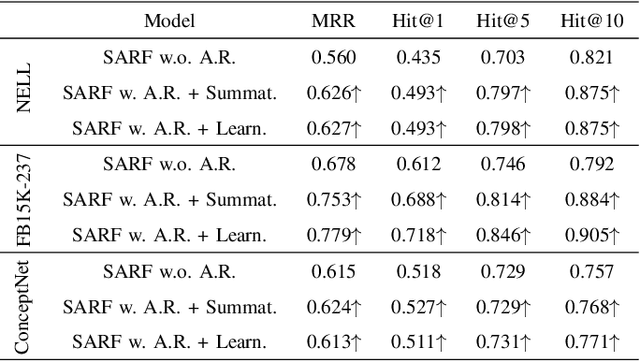
Few-shot relation reasoning on knowledge graphs (FS-KGR) aims to infer long-tail data-poor relations, which has drawn increasing attention these years due to its practicalities. The pre-training of previous methods needs to manually construct the meta-relation set, leading to numerous labor costs. Self-supervised learning (SSL) is treated as a solution to tackle the issue, but still at an early stage for FS-KGR task. Moreover, most of the existing methods ignore leveraging the beneficial information from aliasing relations (AR), i.e., data-rich relations with similar contextual semantics to the target data-poor relation. Therefore, we proposed a novel Self-Supervised Learning model by leveraging Aliasing Relations to assist FS-KGR, termed SARF. Concretely, four main components are designed in our model, i.e., SSL reasoning module, AR-assisted mechanism, fusion module, and scoring function. We first generate the representation of the co-occurrence patterns in a generative manner. Meanwhile, the representations of aliasing relations are learned to enhance reasoning in the AR-assist mechanism. Besides, multiple strategies, i.e., simple summation and learnable fusion, are offered for representation fusion. Finally, the generated representation is used for scoring. Extensive experiments on three few-shot benchmarks demonstrate that SARF achieves state-of-the-art performance compared with other methods in most cases.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023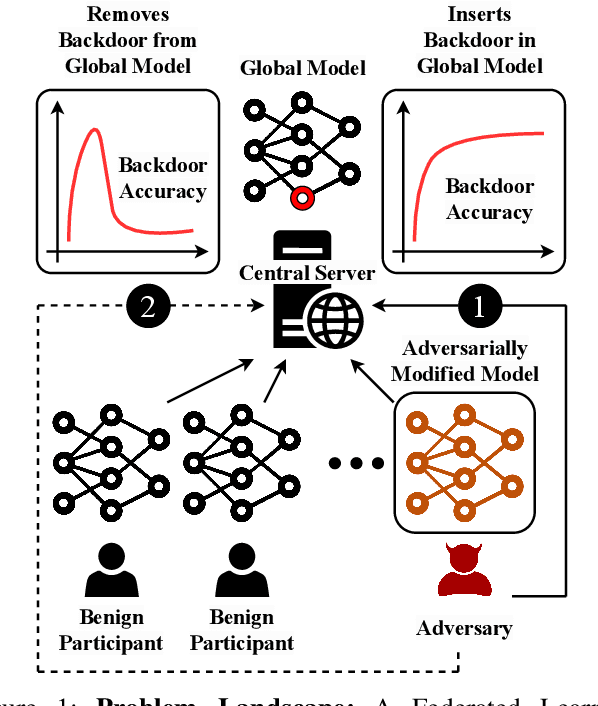
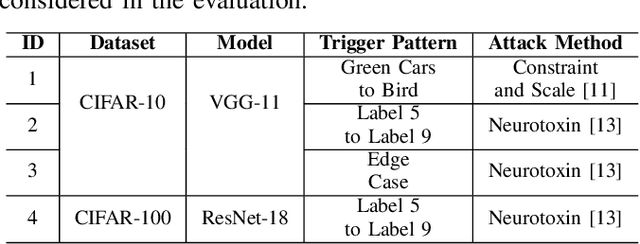
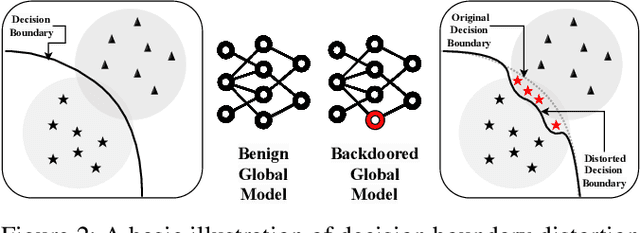
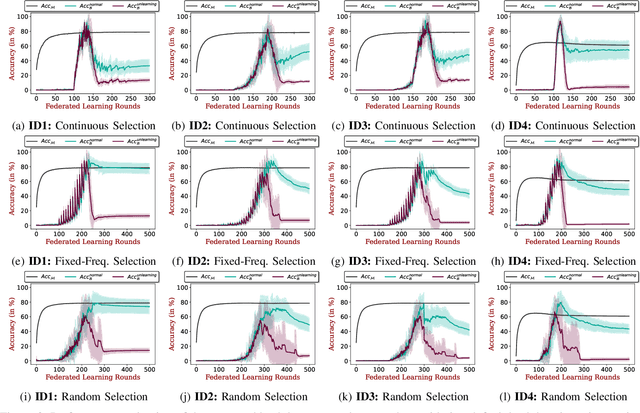
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.
Jedi: Entropy-based Localization and Removal of Adversarial Patches
Apr 20, 2023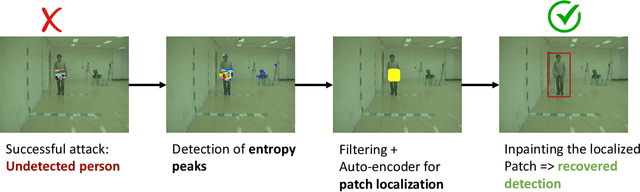
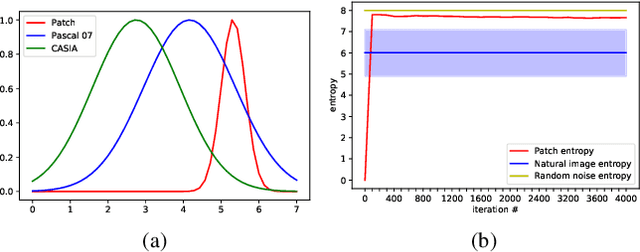
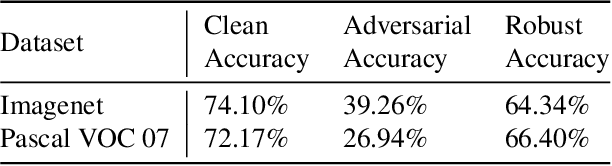
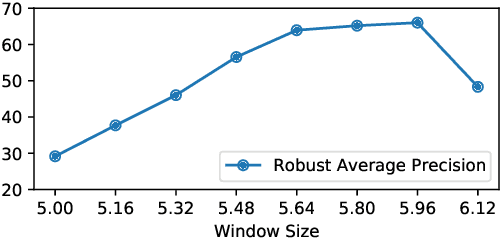
Real-world adversarial physical patches were shown to be successful in compromising state-of-the-art models in a variety of computer vision applications. Existing defenses that are based on either input gradient or features analysis have been compromised by recent GAN-based attacks that generate naturalistic patches. In this paper, we propose Jedi, a new defense against adversarial patches that is resilient to realistic patch attacks. Jedi tackles the patch localization problem from an information theory perspective; leverages two new ideas: (1) it improves the identification of potential patch regions using entropy analysis: we show that the entropy of adversarial patches is high, even in naturalistic patches; and (2) it improves the localization of adversarial patches, using an autoencoder that is able to complete patch regions from high entropy kernels. Jedi achieves high-precision adversarial patch localization, which we show is critical to successfully repair the images. Since Jedi relies on an input entropy analysis, it is model-agnostic, and can be applied on pre-trained off-the-shelf models without changes to the training or inference of the protected models. Jedi detects on average 90% of adversarial patches across different benchmarks and recovers up to 94% of successful patch attacks (Compared to 75% and 65% for LGS and Jujutsu, respectively).
The Future of ChatGPT-enabled Labor Market: A Preliminary Study
Apr 20, 2023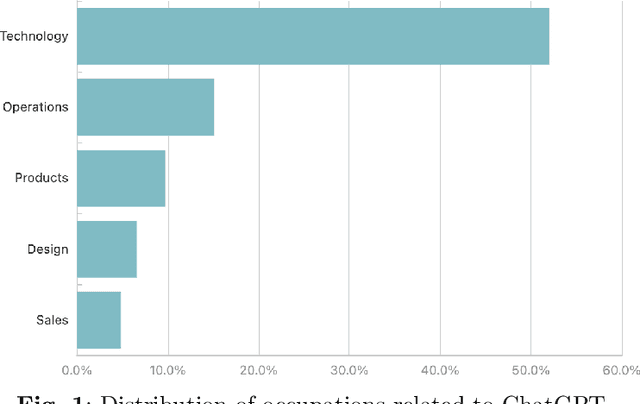

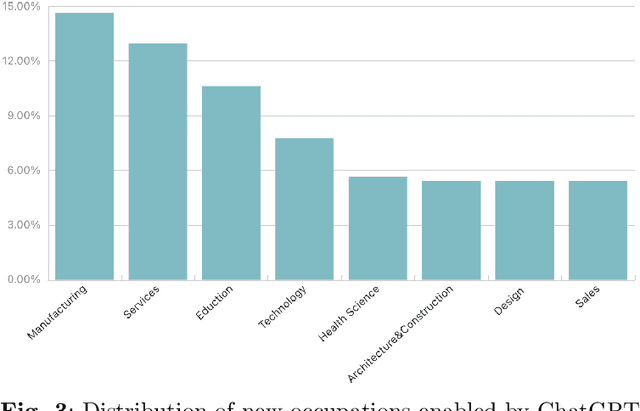
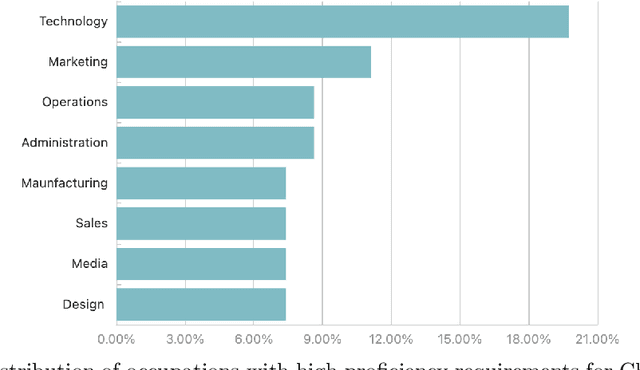
As a phenomenal large language model, ChatGPT has achieved unparalleled success in various real-world tasks and increasingly plays an important role in our daily lives and work. However, extensive concerns are also raised about the potential ethical issues, especially about whether ChatGPT-like artificial general intelligence (AGI) will replace human jobs. To this end, in this paper, we introduce a preliminary data-driven study on the future of ChatGPT-enabled labor market from the view of Human-AI Symbiosis instead of Human-AI Confrontation. To be specific, we first conduct an in-depth analysis of large-scale job posting data in BOSS Zhipin, the largest online recruitment platform in China. The results indicate that about 28% of occupations in the current labor market require ChatGPT-related skills. Furthermore, based on a large-scale occupation-centered knowledge graph, we develop a semantic information enhanced collaborative filtering algorithm to predict the future occupation-skill relations in the labor market. As a result, we find that additional 45% occupations in the future will require ChatGPT-related skills. In particular, industries related to technology, products, and operations are expected to have higher proficiency requirements for ChatGPT-related skills, while the manufacturing, services, education, and health science related industries will have lower requirements for ChatGPT-related skills.
LA3: Efficient Label-Aware AutoAugment
Apr 20, 2023Automated augmentation is an emerging and effective technique to search for data augmentation policies to improve generalizability of deep neural network training. Most existing work focuses on constructing a unified policy applicable to all data samples in a given dataset, without considering sample or class variations. In this paper, we propose a novel two-stage data augmentation algorithm, named Label-Aware AutoAugment (LA3), which takes advantage of the label information, and learns augmentation policies separately for samples of different labels. LA3 consists of two learning stages, where in the first stage, individual augmentation methods are evaluated and ranked for each label via Bayesian Optimization aided by a neural predictor, which allows us to identify effective augmentation techniques for each label under a low search cost. And in the second stage, a composite augmentation policy is constructed out of a selection of effective as well as complementary augmentations, which produces significant performance boost and can be easily deployed in typical model training. Extensive experiments demonstrate that LA3 achieves excellent performance matching or surpassing existing methods on CIFAR-10 and CIFAR-100, and achieves a new state-of-the-art ImageNet accuracy of 79.97% on ResNet-50 among auto-augmentation methods, while maintaining a low computational cost.
Multi-label Node Classification On Graph-Structured Data
Apr 20, 2023



Graph Neural Networks (GNNs) have shown state-of-the-art improvements in node classification tasks on graphs. While these improvements have been largely demonstrated in a multi-class classification scenario, a more general and realistic scenario in which each node could have multiple labels has so far received little attention. The first challenge in conducting focused studies on multi-label node classification is the limited number of publicly available multi-label graph datasets. Therefore, as our first contribution, we collect and release three real-world biological datasets and develop a multi-label graph generator to generate datasets with tunable properties. While high label similarity (high homophily) is usually attributed to the success of GNNs, we argue that a multi-label scenario does not follow the usual semantics of homophily and heterophily so far defined for a multi-class scenario. As our second contribution, besides defining homophily for the multi-label scenario, we develop a new approach that dynamically fuses the feature and label correlation information to learn label-informed representations. Finally, we perform a large-scale comparative study with $10$ methods and $9$ datasets which also showcase the effectiveness of our approach. We release our benchmark at \url{https://anonymous.4open.science/r/LFLF-5D8C/}.
Two-Memory Reinforcement Learning
Apr 20, 2023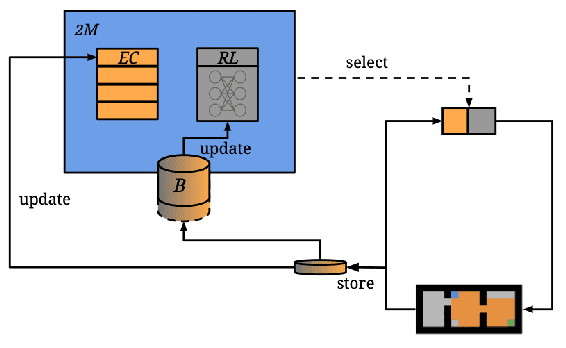
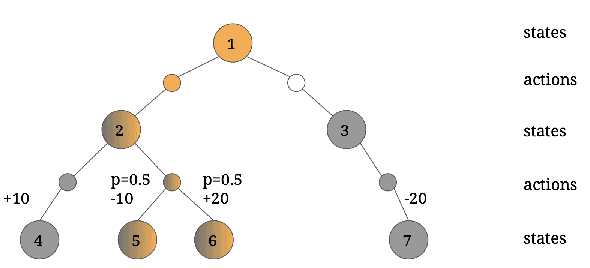

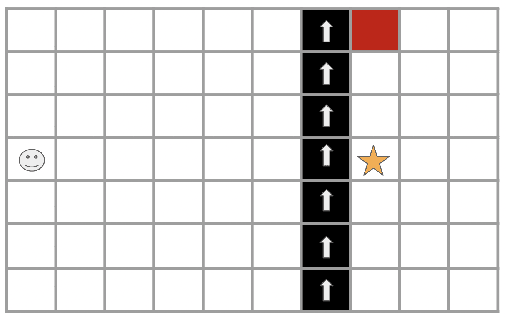
While deep reinforcement learning has shown important empirical success, it tends to learn relatively slow due to slow propagation of rewards information and slow update of parametric neural networks. Non-parametric episodic memory, on the other hand, provides a faster learning alternative that does not require representation learning and uses maximum episodic return as state-action values for action selection. Episodic memory and reinforcement learning both have their own strengths and weaknesses. Notably, humans can leverage multiple memory systems concurrently during learning and benefit from all of them. In this work, we propose a method called Two-Memory reinforcement learning agent (2M) that combines episodic memory and reinforcement learning to distill both of their strengths. The 2M agent exploits the speed of the episodic memory part and the optimality and the generalization capacity of the reinforcement learning part to complement each other. Our experiments demonstrate that the 2M agent is more data efficient and outperforms both pure episodic memory and pure reinforcement learning, as well as a state-of-the-art memory-augmented RL agent. Moreover, the proposed approach provides a general framework that can be used to combine any episodic memory agent with other off-policy reinforcement learning algorithms.
Feature point detection in HDR images based on coefficient of variation
Apr 20, 2023



Feature point (FP) detection is a fundamental step of many computer vision tasks. However, FP detectors are usually designed for low dynamic range (LDR) images. In scenes with extreme light conditions, LDR images present saturated pixels, which degrade FP detection. On the other hand, high dynamic range (HDR) images usually present no saturated pixels but FP detection algorithms do not take advantage of all the information present in such images. FP detection frequently relies on differential methods, which work well in LDR images. However, in HDR images, the differential operation response in bright areas overshadows the response in dark areas. As an alternative to standard FP detection methods, this study proposes an FP detector based on a coefficient of variation (CV) designed for HDR images. The CV operation adapts its response based on the standard deviation of pixels inside a window, working well in both dark and bright areas of HDR images. The proposed and standard detectors are evaluated by measuring their repeatability rate (RR) and uniformity. Our proposed detector shows better performance when compared to other standard state-of-the-art detectors. In uniformity metric, our proposed detector surpasses all the other algorithms. In other hand, when using the repeatability rate metric, the proposed detector is worse than Harris for HDR and SURF detectors.