 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SpanRE: Entities and Overlapping Relations Extraction Based on Spans and Entity Attention
Apr 06, 2023
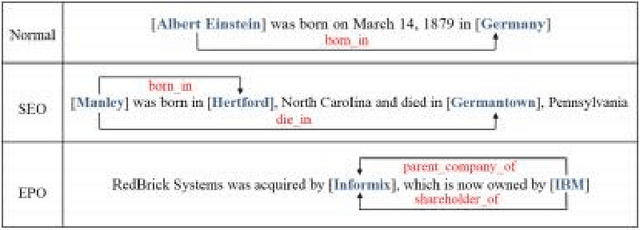
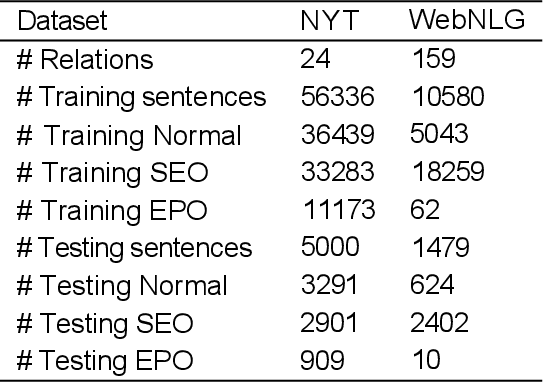
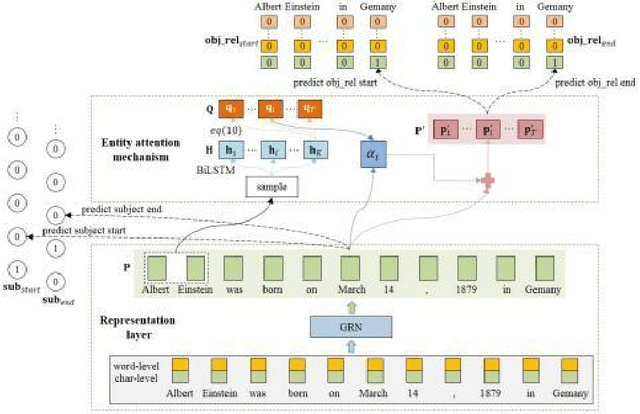
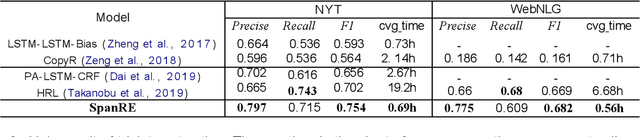
Extracting entities and relations is an essential task of information extraction. Triplets extracted from a sentence might overlap with each other. Previous methods either did not address the overlapping issues or solved overlapping issues partially. To tackle triplet overlapping problems completely, firstly we extract candidate subjects with a standard span mechanism. Then we present a labeled span mechanism to extract the objects and relations simultaneously, we use the labeled span mechanism to generate labeled spans whose start and end positions indicate the objects, and whose labels correspond to relations of subject and objects. Besides, we design an entity attention mechanism to enhance the information fusion between subject and sentence during extracting objects and relations. We test our method on two public datasets, our method achieves the best performances on these two datasets.
An Attention Free Conditional Autoencoder For Anomaly Detection in Cryptocurrencies
Apr 20, 2023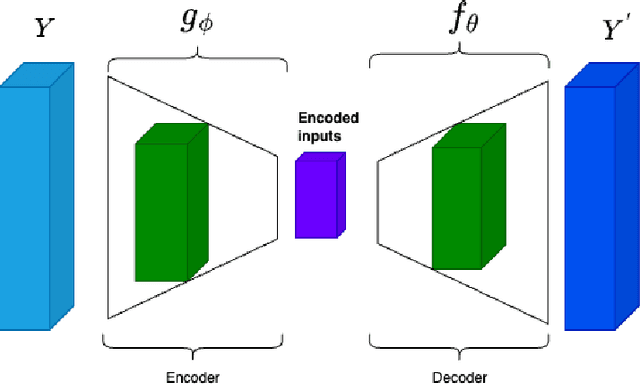
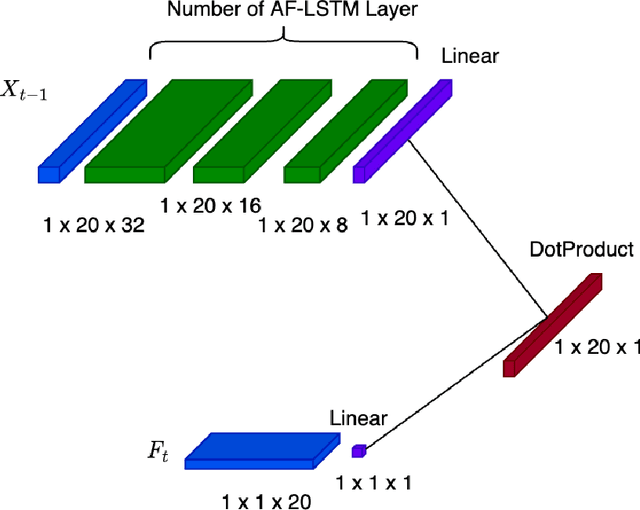
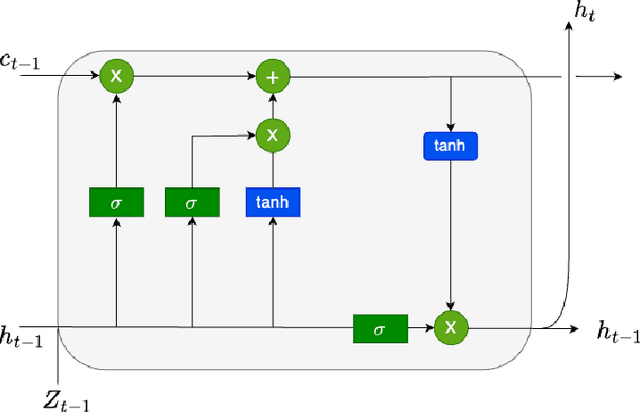
It is difficult to identify anomalies in time series, especially when there is a lot of noise. Denoising techniques can remove the noise but this technique can cause a significant loss of information. To detect anomalies in the time series we have proposed an attention free conditional autoencoder (AF-CA). We started from the autoencoder conditional model on which we added an Attention-Free LSTM layer \cite{inzirillo2022attention} in order to make the anomaly detection capacity more reliable and to increase the power of anomaly detection. We compared the results of our Attention Free Conditional Autoencoder with those of an LSTM Autoencoder and clearly improved the explanatory power of the model and therefore the detection of anomaly in noisy time series.
Counterfactual Explanation with Missing Values
Apr 28, 2023
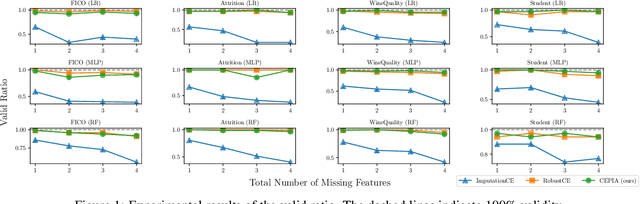

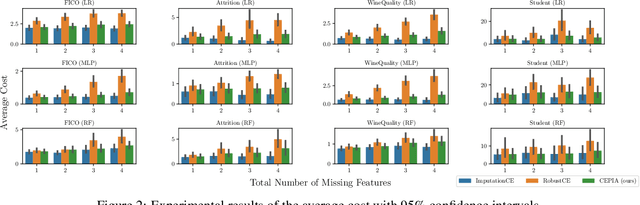
Counterfactual Explanation (CE) is a post-hoc explanation method that provides a perturbation for altering the prediction result of a classifier. Users can interpret the perturbation as an "action" to obtain their desired decision results. Existing CE methods require complete information on the features of an input instance. However, we often encounter missing values in a given instance, and the previous methods do not work in such a practical situation. In this paper, we first empirically and theoretically show the risk that missing value imputation methods affect the validity of an action, as well as the features that the action suggests changing. Then, we propose a new framework of CE, named Counterfactual Explanation by Pairs of Imputation and Action (CEPIA), that enables users to obtain valid actions even with missing values and clarifies how actions are affected by imputation of the missing values. Specifically, our CEPIA provides a representative set of pairs of an imputation candidate for a given incomplete instance and its optimal action. We formulate the problem of finding such a set as a submodular maximization problem, which can be solved by a simple greedy algorithm with an approximation guarantee. Experimental results demonstrated the efficacy of our CEPIA in comparison with the baselines in the presence of missing values.
Improve Video Representation with Temporal Adversarial Augmentation
Apr 28, 2023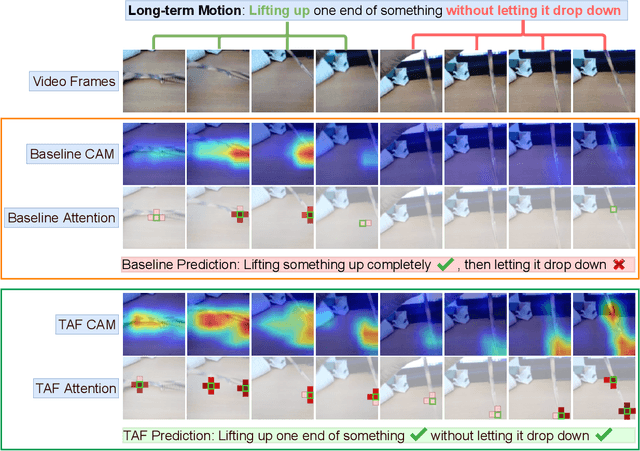
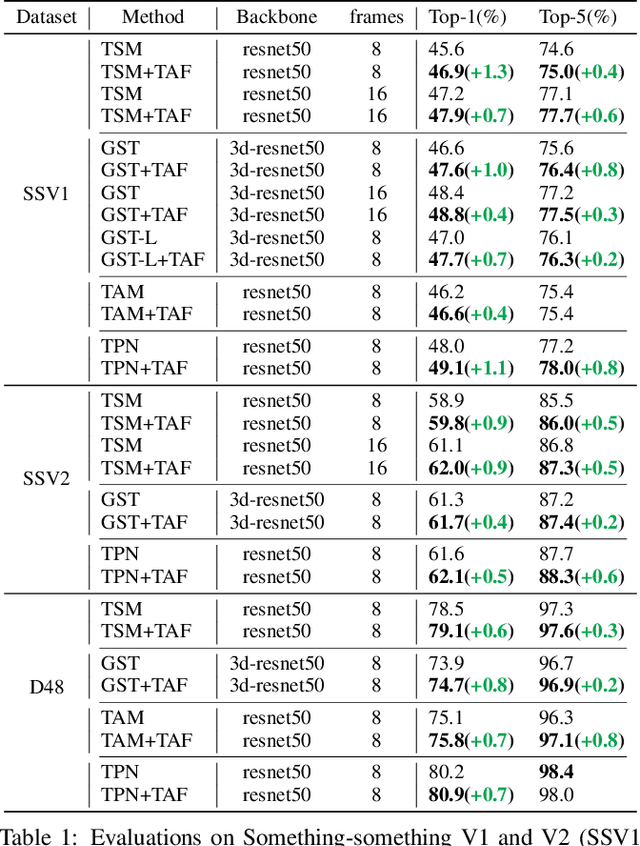
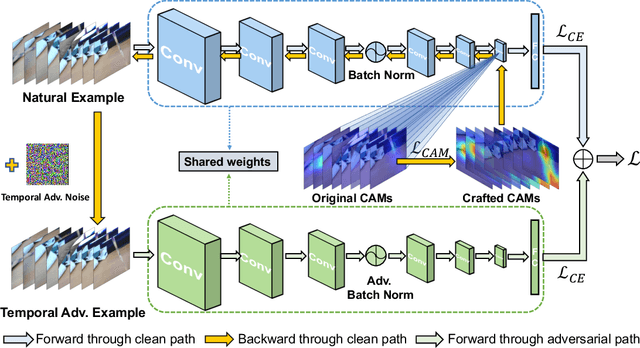

Recent works reveal that adversarial augmentation benefits the generalization of neural networks (NNs) if used in an appropriate manner. In this paper, we introduce Temporal Adversarial Augmentation (TA), a novel video augmentation technique that utilizes temporal attention. Unlike conventional adversarial augmentation, TA is specifically designed to shift the attention distributions of neural networks with respect to video clips by maximizing a temporal-related loss function. We demonstrate that TA will obtain diverse temporal views, which significantly affect the focus of neural networks. Training with these examples remedies the flaw of unbalanced temporal information perception and enhances the ability to defend against temporal shifts, ultimately leading to better generalization. To leverage TA, we propose Temporal Video Adversarial Fine-tuning (TAF) framework for improving video representations. TAF is a model-agnostic, generic, and interpretability-friendly training strategy. We evaluate TAF with four powerful models (TSM, GST, TAM, and TPN) over three challenging temporal-related benchmarks (Something-something V1&V2 and diving48). Experimental results demonstrate that TAF effectively improves the test accuracy of these models with notable margins without introducing additional parameters or computational costs. As a byproduct, TAF also improves the robustness under out-of-distribution (OOD) settings. Code is available at https://github.com/jinhaoduan/TAF.
Hedonic Prices and Quality Adjusted Price Indices Powered by AI
Apr 28, 2023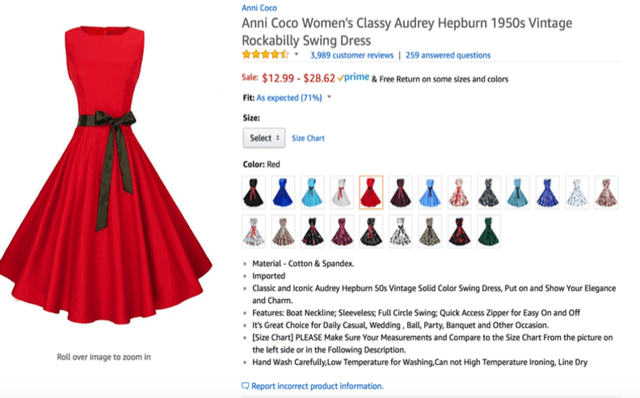
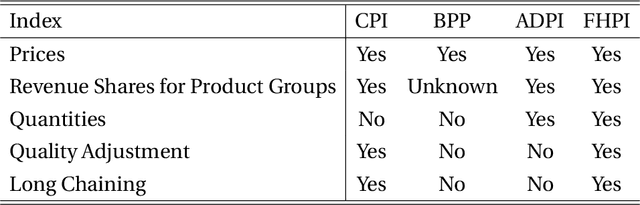
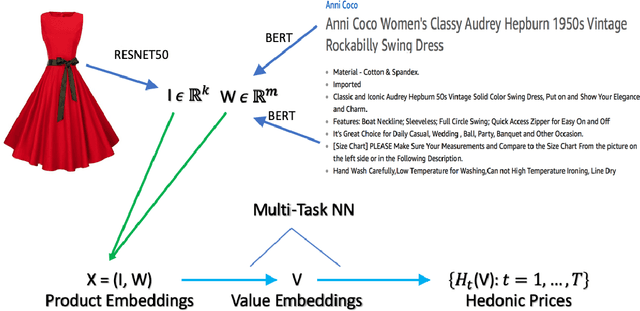

Accurate, real-time measurements of price index changes using electronic records are essential for tracking inflation and productivity in today's economic environment. We develop empirical hedonic models that can process large amounts of unstructured product data (text, images, prices, quantities) and output accurate hedonic price estimates and derived indices. To accomplish this, we generate abstract product attributes, or ``features,'' from text descriptions and images using deep neural networks, and then use these attributes to estimate the hedonic price function. Specifically, we convert textual information about the product to numeric features using large language models based on transformers, trained or fine-tuned using product descriptions, and convert the product image to numeric features using a residual network model. To produce the estimated hedonic price function, we again use a multi-task neural network trained to predict a product's price in all time periods simultaneously. To demonstrate the performance of this approach, we apply the models to Amazon's data for first-party apparel sales and estimate hedonic prices. The resulting models have high predictive accuracy, with $R^2$ ranging from $80\%$ to $90\%$. Finally, we construct the AI-based hedonic Fisher price index, chained at the year-over-year frequency. We contrast the index with the CPI and other electronic indices.
A manifold learning-based CSI feedback framework for FDD massive MIMO
Apr 28, 2023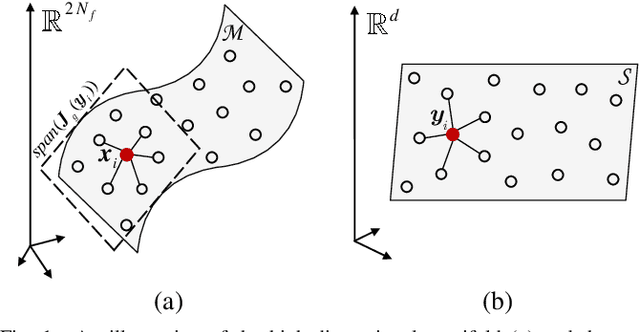
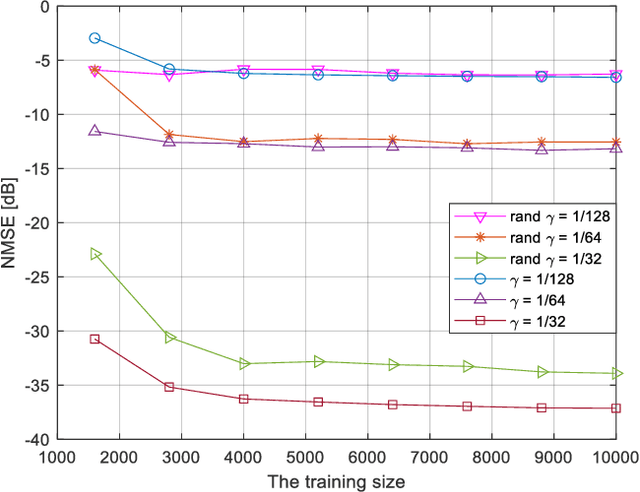
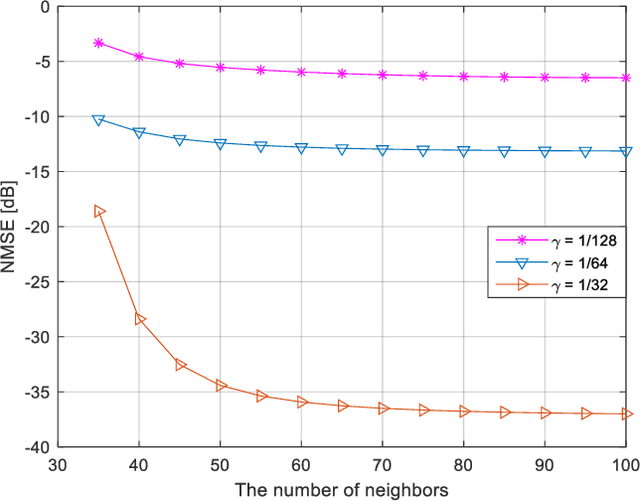
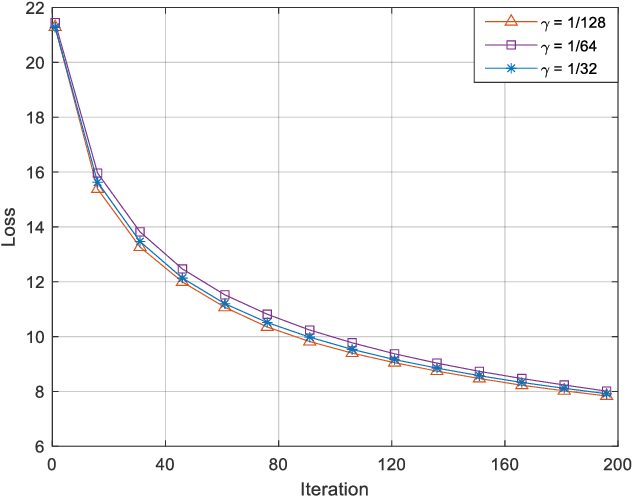
Massive multi-input multi-output (MIMO) in Frequency Division Duplex (FDD) mode suffers from heavy feedback overhead for Channel State Information (CSI). In this paper, a novel manifold learning-based CSI feedback framework (MLCF) is proposed to reduce the feedback and improve the spectral efficiency of FDD massive MIMO. Manifold learning (ML) is an effective method for dimensionality reduction. However, most ML algorithms focus only on data compression, and lack the corresponding recovery methods. Moreover, the computational complexity is high when dealing with incremental data. To solve these problems, we propose a landmark selection algorithm to characterize the topological skeleton of the manifold where the CSI sample resides. Based on the learned skeleton, the local patch of the incremental CSI on the manifold can be easily determined by its nearest landmarks. This motivates us to propose a low-complexity compression and reconstruction scheme by keeping the local geometric relationships with landmarks unchanged. We theoretically prove the convergence of the proposed algorithm. Meanwhile, the upper bound on the error of approximating the CSI samples using landmarks is derived. Simulation results under an industrial channel model of 3GPP demonstrate that the proposed MLCF method outperforms existing algorithms based on compressed sensing and deep learning.
A feature selection method based on Shapley values robust to concept shift in regression
Apr 28, 2023
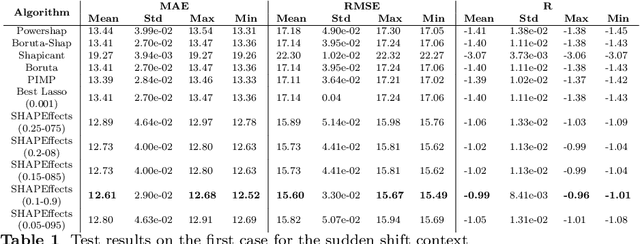
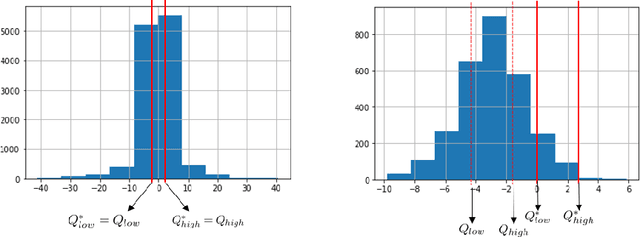
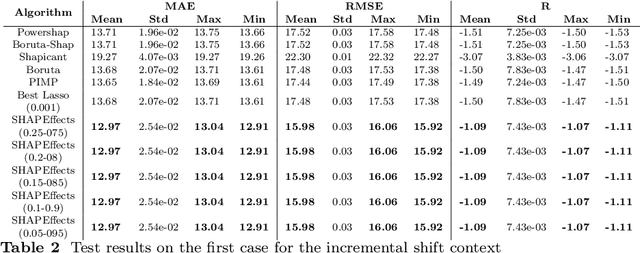
Feature selection is one of the most relevant processes in any methodology for creating a statistical learning model. Generally, existing algorithms establish some criterion to select the most influential variables, discarding those that do not contribute any relevant information to the model. This methodology makes sense in a classical static situation where the joint distribution of the data does not vary over time. However, when dealing with real data, it is common to encounter the problem of the dataset shift and, specifically, changes in the relationships between variables (concept shift). In this case, the influence of a variable cannot be the only indicator of its quality as a regressor of the model, since the relationship learned in the traning phase may not correspond to the current situation. Thus, we propose a new feature selection methodology for regression problems that takes this fact into account, using Shapley values to study the effect that each variable has on the predictions. Five examples are analysed: four correspond to typical situations where the method matches the state of the art and one example related to electricity price forecasting where a concept shift phenomenon has occurred in the Iberian market. In this case the proposed algorithm improves the results significantly.
Musical Voice Separation as Link Prediction: Modeling a Musical Perception Task as a Multi-Trajectory Tracking Problem
Apr 28, 2023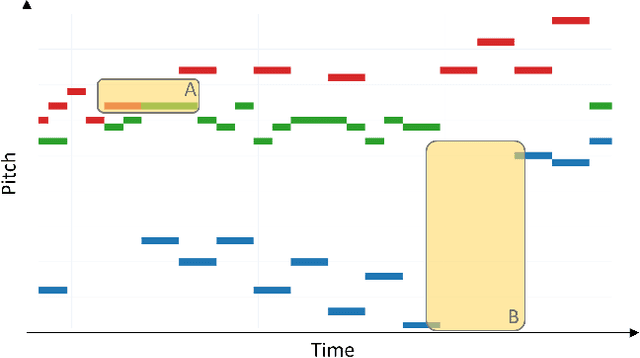
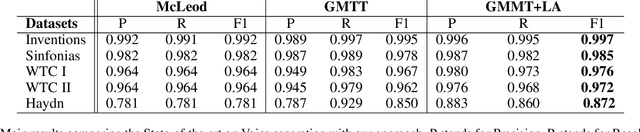

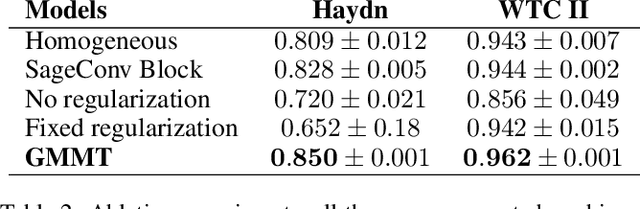
This paper targets the perceptual task of separating the different interacting voices, i.e., monophonic melodic streams, in a polyphonic musical piece. We target symbolic music, where notes are explicitly encoded, and model this task as a Multi-Trajectory Tracking (MTT) problem from discrete observations, i.e., notes in a pitch-time space. Our approach builds a graph from a musical piece, by creating one node for every note, and separates the melodic trajectories by predicting a link between two notes if they are consecutive in the same voice/stream. This kind of local, greedy prediction is made possible by node embeddings created by a heterogeneous graph neural network that can capture inter- and intra-trajectory information. Furthermore, we propose a new regularization loss that encourages the output to respect the MTT premise of at most one incoming and one outgoing link for every node, favouring monophonic (voice) trajectories; this loss function might also be useful in other general MTT scenarios. Our approach does not use domain-specific heuristics, is scalable to longer sequences and a higher number of voices, and can handle complex cases such as voice inversions and overlaps. We reach new state-of-the-art results for the voice separation task in classical music of different styles.
Measures of Information Reflect Memorization Patterns
Oct 19, 2022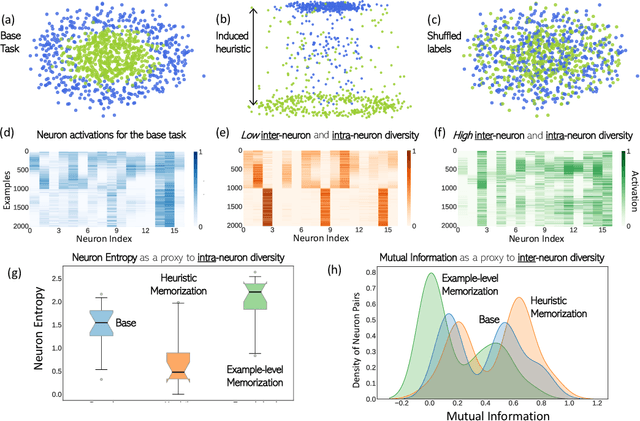
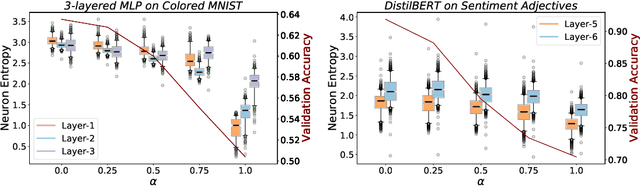
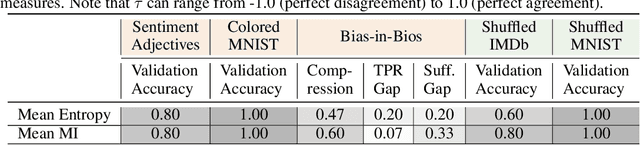
Neural networks are known to exploit spurious artifacts (or shortcuts) that co-occur with a target label, exhibiting heuristic memorization. On the other hand, networks have been shown to memorize training examples, resulting in example-level memorization. These kinds of memorization impede generalization of networks beyond their training distributions. Detecting such memorization could be challenging, often requiring researchers to curate tailored test sets. In this work, we hypothesize -- and subsequently show -- that the diversity in the activation patterns of different neurons is reflective of model generalization and memorization. We quantify the diversity in the neural activations through information-theoretic measures and find support for our hypothesis on experiments spanning several natural language and vision tasks. Importantly, we discover that information organization points to the two forms of memorization, even for neural activations computed on unlabeled in-distribution examples. Lastly, we demonstrate the utility of our findings for the problem of model selection. The associated code and other resources for this work are available at https://linktr.ee/InformationMeasures .
Network Visualization of ChatGPT Research: a study based on term and keyword co-occurrence network analysis
Apr 01, 2023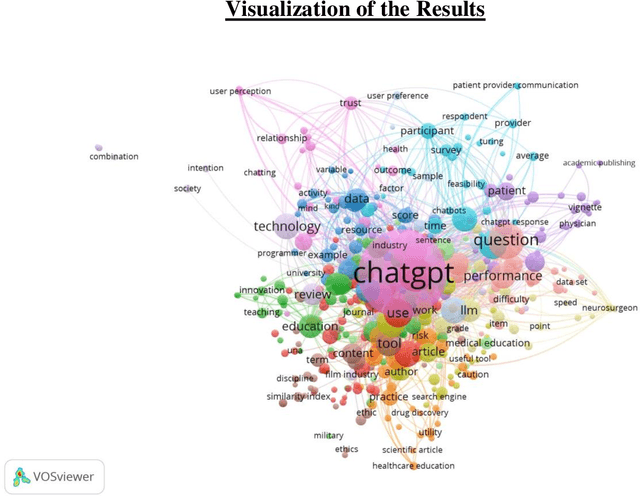
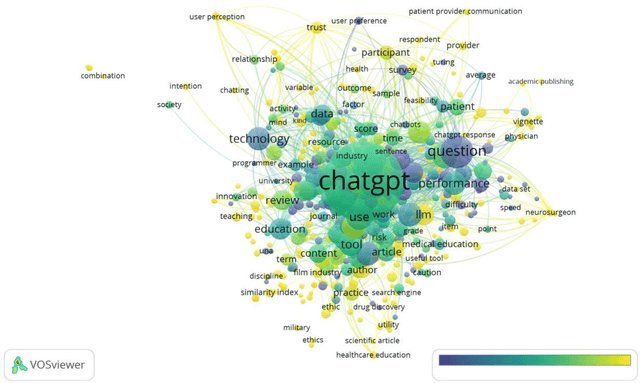
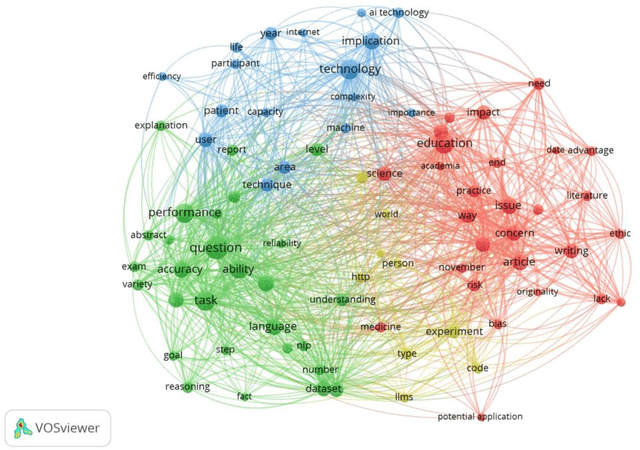
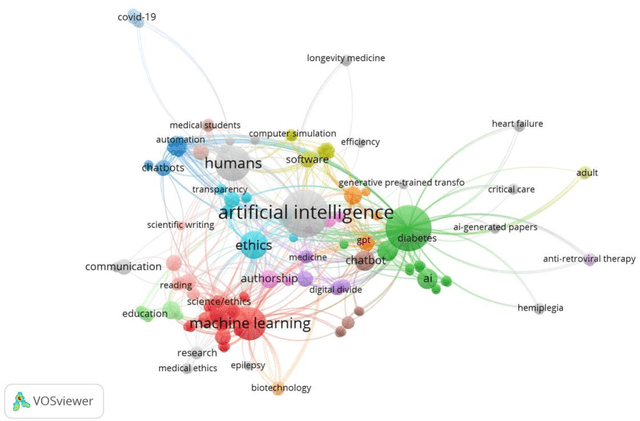
The main objective of this paper is to identify the major research areas of ChatGPT through term and keyword co-occurrence network mapping techniques. For conducting the present study, total of 577 publications were retrieved from the Lens database for the network visualization. The findings of the study showed that chatgpt occurrence in maximum number of times followed by its related terms such as artificial intelligence, large language model, gpt, study etc. This study will be helpful to library and information science as well as computer or information technology professionals.