 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023
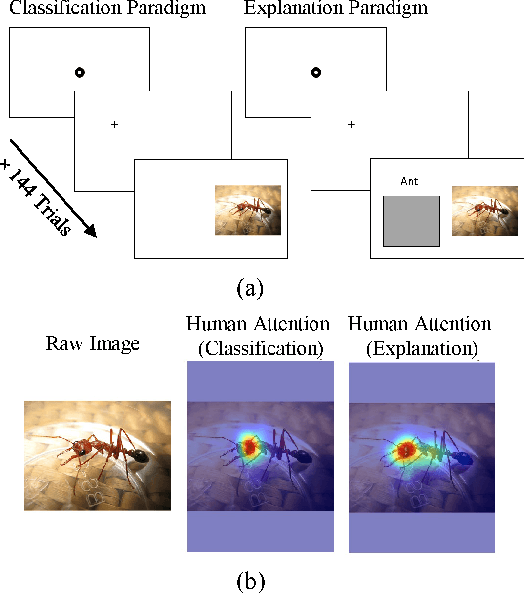
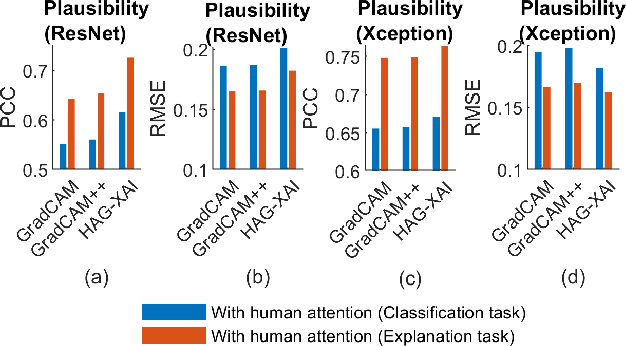
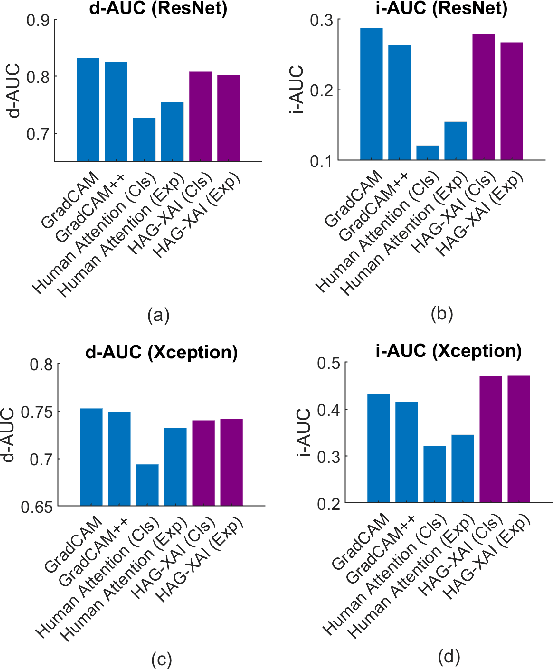
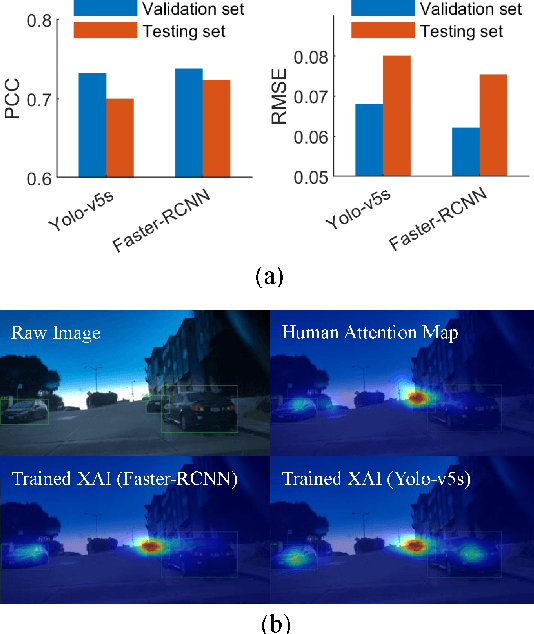
We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
HiPool: Modeling Long Documents Using Graph Neural Networks
May 05, 2023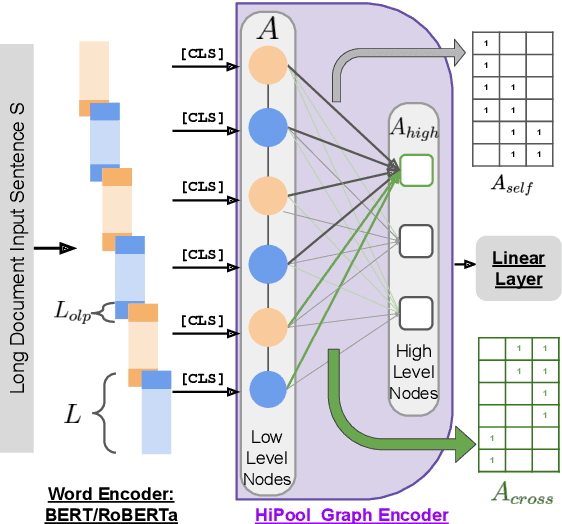
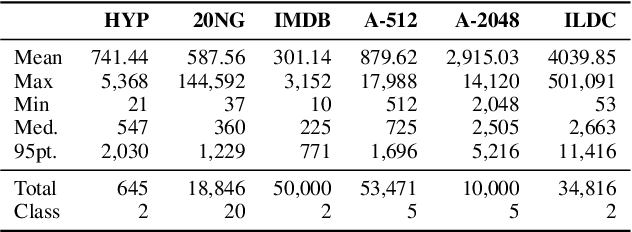
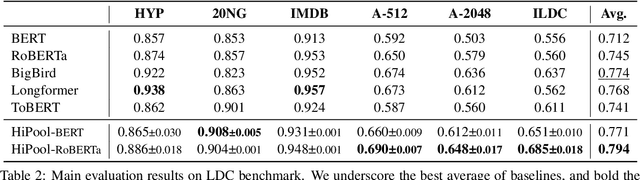
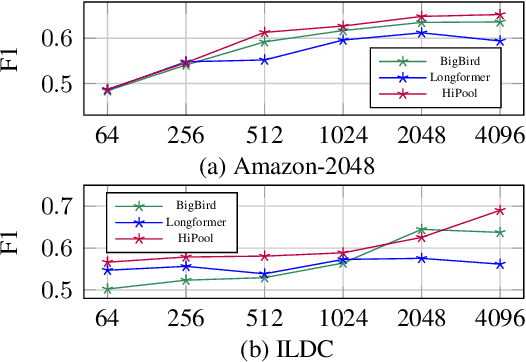
Encoding long sequences in Natural Language Processing (NLP) is a challenging problem. Though recent pretraining language models achieve satisfying performances in many NLP tasks, they are still restricted by a pre-defined maximum length, making them challenging to be extended to longer sequences. So some recent works utilize hierarchies to model long sequences. However, most of them apply sequential models for upper hierarchies, suffering from long dependency issues. In this paper, we alleviate these issues through a graph-based method. We first chunk the sequence with a fixed length to model the sentence-level information. We then leverage graphs to model intra- and cross-sentence correlations with a new attention mechanism. Additionally, due to limited standard benchmarks for long document classification (LDC), we propose a new challenging benchmark, totaling six datasets with up to 53k samples and 4034 average tokens' length. Evaluation shows our model surpasses competitive baselines by 2.6% in F1 score, and 4.8% on the longest sequence dataset. Our method is shown to outperform hierarchical sequential models with better performance and scalability, especially for longer sequences.
Augmenting Low-Resource Text Classification with Graph-Grounded Pre-training and Prompting
May 05, 2023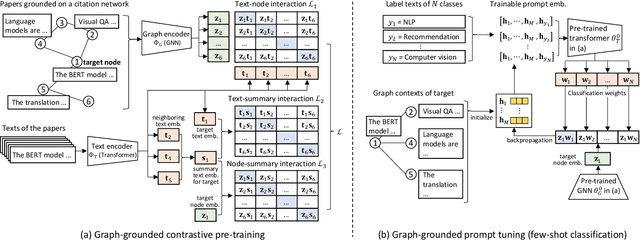
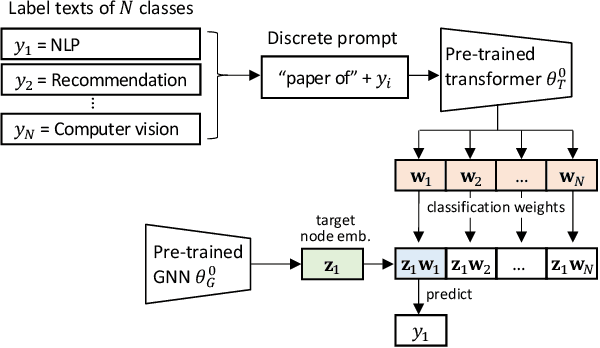
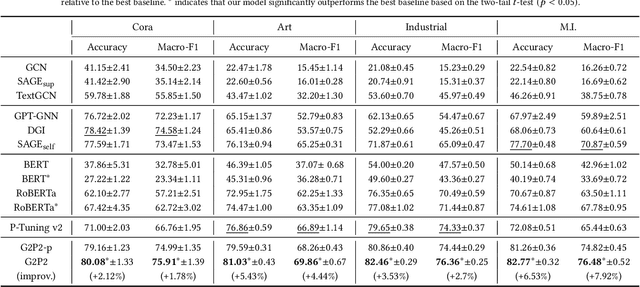
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with few or no labeled samples, poses a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore prompting for the jointly pre-trained model to achieve low-resource classification. Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks.
The geometry of financial institutions -- Wasserstein clustering of financial data
May 05, 2023The increasing availability of granular and big data on various objects of interest has made it necessary to develop methods for condensing this information into a representative and intelligible map. Financial regulation is a field that exemplifies this need, as regulators require diverse and often highly granular data from financial institutions to monitor and assess their activities. However, processing and analyzing such data can be a daunting task, especially given the challenges of dealing with missing values and identifying clusters based on specific features. To address these challenges, we propose a variant of Lloyd's algorithm that applies to probability distributions and uses generalized Wasserstein barycenters to construct a metric space which represents given data on various objects in condensed form. By applying our method to the financial regulation context, we demonstrate its usefulness in dealing with the specific challenges faced by regulators in this domain. We believe that our approach can also be applied more generally to other fields where large and complex data sets need to be represented in concise form.
Large Language Models in Sport Science & Medicine: Opportunities, Risks and Considerations
May 05, 2023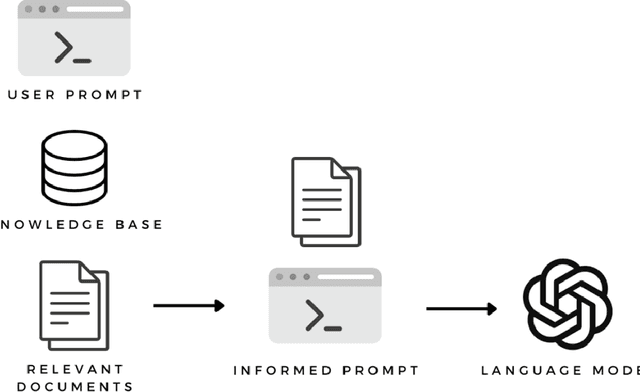
This paper explores the potential opportunities, risks, and challenges associated with the use of large language models (LLMs) in sports science and medicine. LLMs are large neural networks with transformer style architectures trained on vast amounts of textual data, and typically refined with human feedback. LLMs can perform a large range of natural language processing tasks. In sports science and medicine, LLMs have the potential to support and augment the knowledge of sports medicine practitioners, make recommendations for personalised training programs, and potentially distribute high-quality information to practitioners in developing countries. However, there are also potential risks associated with the use and development of LLMs, including biases in the dataset used to create the model, the risk of exposing confidential data, the risk of generating harmful output, and the need to align these models with human preferences through feedback. Further research is needed to fully understand the potential applications of LLMs in sports science and medicine and to ensure that their use is ethical and beneficial to athletes, clients, patients, practitioners, and the general public.
AmGCL: Feature Imputation of Attribute Missing Graph via Self-supervised Contrastive Learning
May 05, 2023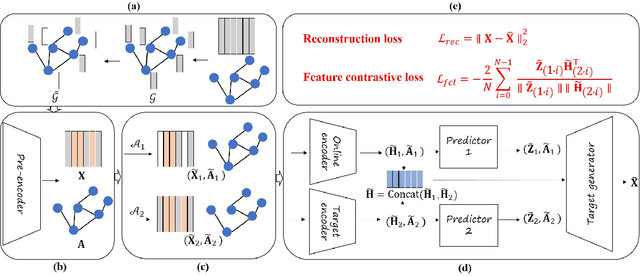
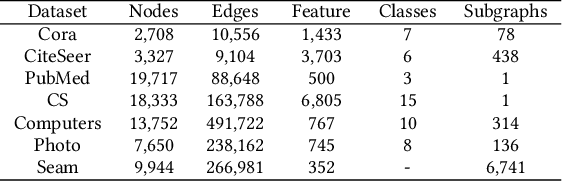
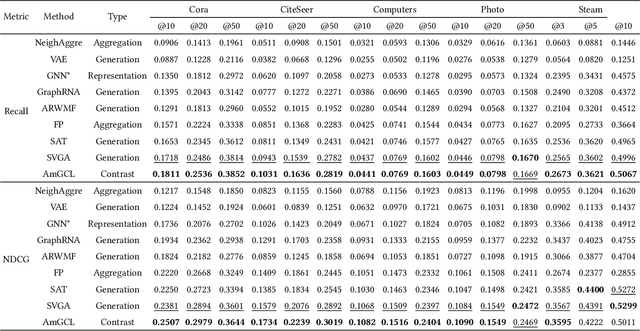
Attribute graphs are ubiquitous in multimedia applications, and graph representation learning (GRL) has been successful in analyzing attribute graph data. However, incomplete graph data and missing node attributes can have a negative impact on media knowledge discovery. Existing methods for handling attribute missing graph have limited assumptions or fail to capture complex attribute-graph dependencies. To address these challenges, we propose Attribute missing Graph Contrastive Learning (AmGCL), a framework for handling missing node attributes in attribute graph data. AmGCL leverages Dirichlet energy minimization-based feature precoding to encode in missing attributes and a self-supervised Graph Augmentation Contrastive Learning Structure (GACLS) to learn latent variables from the encoded-in data. Specifically, AmGCL utilizies feature reconstruction based on structure-attribute energy minimization while maximizes the lower bound of evidence for latent representation mutual information. Our experimental results on multiple real-world datasets demonstrate that AmGCL outperforms state-of-the-art methods in both feature imputation and node classification tasks, indicating the effectiveness of our proposed method in real-world attribute graph analysis tasks.
Voxel-wise classification for porosity investigation of additive manufactured parts with 3D unsupervised and (deeply) supervised neural networks
May 13, 2023


Additive Manufacturing (AM) has emerged as a manufacturing process that allows the direct production of samples from digital models. To ensure that quality standards are met in all manufactured samples of a batch, X-ray computed tomography (X-CT) is often used combined with automated anomaly detection. For the latter, deep learning (DL) anomaly detection techniques are increasingly, as they can be trained to be robust to the material being analysed and resilient towards poor image quality. Unfortunately, most recent and popular DL models have been developed for 2D image processing, thereby disregarding valuable volumetric information. This study revisits recent supervised (UNet, UNet++, UNet 3+, MSS-UNet) and unsupervised (VAE, ceVAE, gmVAE, vqVAE) DL models for porosity analysis of AM samples from X-CT images and extends them to accept 3D input data with a 3D-patch pipeline for lower computational requirements, improved efficiency and generalisability. The supervised models were trained using the Focal Tversky loss to address class imbalance that arises from the low porosity in the training datasets. The output of the unsupervised models is post-processed to reduce misclassifications caused by their inability to adequately represent the object surface. The findings were cross-validated in a 5-fold fashion and include: a performance benchmark of the DL models, an evaluation of the post-processing algorithm, an evaluation of the effect of training supervised models with the output of unsupervised models. In a final performance benchmark on a test set with poor image quality, the best performing supervised model was MSS-UNet with an average precision of 0.808 $\pm$ 0.013, while the best unsupervised model was the post-processed ceVAE with 0.935 $\pm$ 0.001. The VAE/ceVAE models demonstrated superior capabilities, particularly when leveraging post-processing techniques.
The Emerged Artificial Intelligence Protocol for Hierarchical Information Network
Feb 19, 2023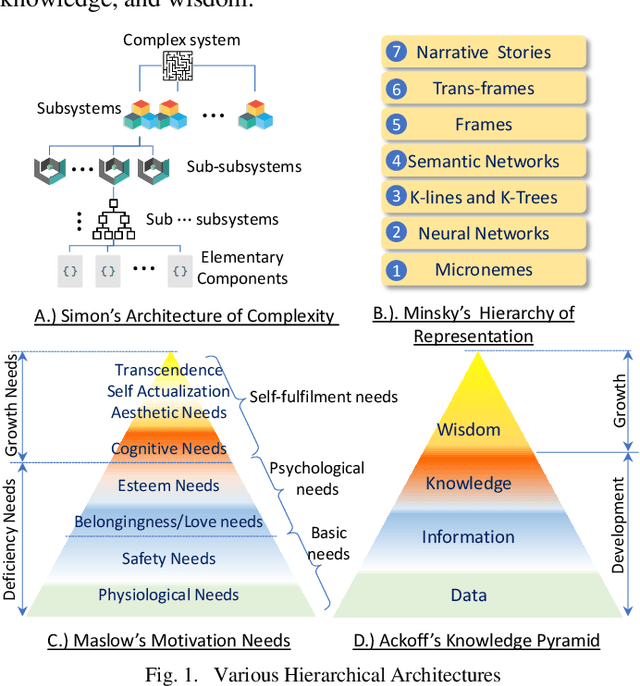
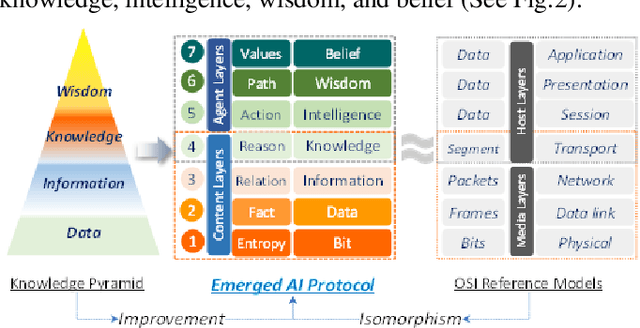


The recent development of artificial intelligence enables a machine to achieve a human level of intelligence. Problem-solving and decision-making are two mental abilities to measure human intelligence. Many scholars have proposed different models. However, there is a gap in establishing an AI-oriented hierarchical model with a multilevel abstraction. This study proposes a novel model known as the emerged AI protocol that consists of seven distinct layers capable of providing an optimal and explainable solution for a given problem.
* 6 pages, 4 figures, 1 table
Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery
May 10, 2023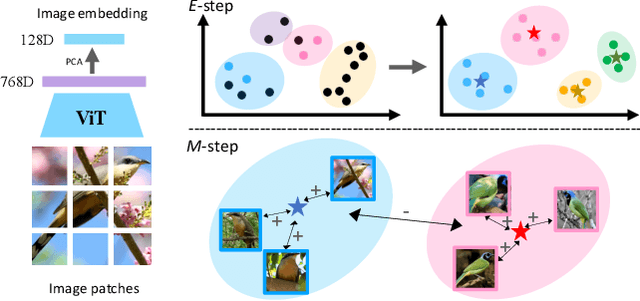
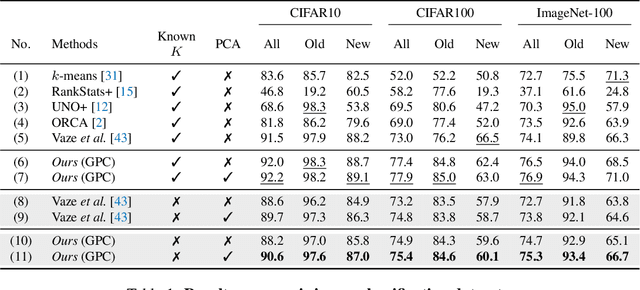

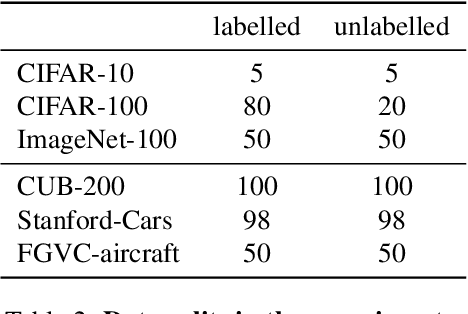
In this paper, we address the problem of generalized category discovery (GCD), \ie, given a set of images where part of them are labelled and the rest are not, the task is to automatically cluster the images in the unlabelled data, leveraging the information from the labelled data, while the unlabelled data contain images from the labelled classes and also new ones. GCD is similar to semi-supervised learning (SSL) but is more realistic and challenging, as SSL assumes all the unlabelled images are from the same classes as the labelled ones. We also do not assume the class number in the unlabelled data is known a-priori, making the GCD problem even harder. To tackle the problem of GCD without knowing the class number, we propose an EM-like framework that alternates between representation learning and class number estimation. We propose a semi-supervised variant of the Gaussian Mixture Model (GMM) with a stochastic splitting and merging mechanism to dynamically determine the prototypes by examining the cluster compactness and separability. With these prototypes, we leverage prototypical contrastive learning for representation learning on the partially labelled data subject to the constraints imposed by the labelled data. Our framework alternates between these two steps until convergence. The cluster assignment for an unlabelled instance can then be retrieved by identifying its nearest prototype. We comprehensively evaluate our framework on both generic image classification datasets and challenging fine-grained object recognition datasets, achieving state-of-the-art performance.
Dexterous In-Hand Manipulation of Slender Cylindrical Objects through Deep Reinforcement Learning with Tactile Sensing
Apr 11, 2023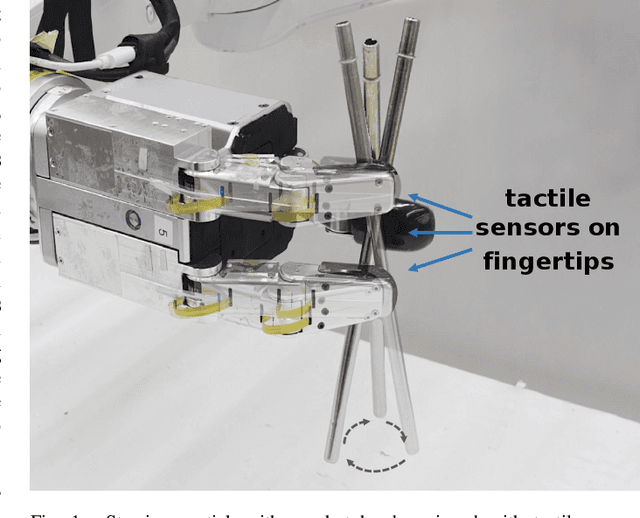
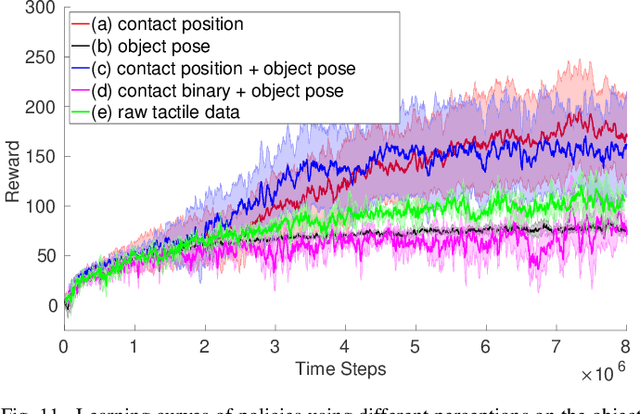

Continuous in-hand manipulation is an important physical interaction skill, where tactile sensing provides indispensable contact information to enable dexterous manipulation of small objects. This work proposed a framework for end-to-end policy learning with tactile feedback and sim-to-real transfer, which achieved fine in-hand manipulation that controls the pose of a thin cylindrical object, such as a long stick, to track various continuous trajectories through multiple contacts of three fingertips of a dexterous robot hand with tactile sensor arrays. We estimated the central contact position between the stick and each fingertip from the high-dimensional tactile information and showed that the learned policies achieved effective manipulation performance with the processed tactile feedback. The policies were trained with deep reinforcement learning in simulation and successfully transferred to real-world experiments, using coordinated model calibration and domain randomization. We evaluated the effectiveness of tactile information via comparative studies and validated the sim-to-real performance through real-world experiments.