 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recognizing People by Body Shape Using Deep Networks of Images and Words
May 30, 2023


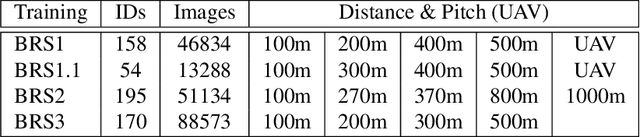

Common and important applications of person identification occur at distances and viewpoints in which the face is not visible or is not sufficiently resolved to be useful. We examine body shape as a biometric across distance and viewpoint variation. We propose an approach that combines standard object classification networks with representations based on linguistic (word-based) descriptions of bodies. Algorithms with and without linguistic training were compared on their ability to identify people from body shape in images captured across a large range of distances/views (close-range, 100m, 200m, 270m, 300m, 370m, 400m, 490m, 500m, 600m, and at elevated pitch in images taken by an unmanned aerial vehicle [UAV]). Accuracy, as measured by identity-match ranking and false accept errors in an open-set test, was surprisingly good. For identity-ranking, linguistic models were more accurate for close-range images, whereas non-linguistic models fared better at intermediary distances. Fusion of the linguistic and non-linguistic embeddings improved performance at all, but the farthest distance. Although the non-linguistic model yielded fewer false accepts at all distances, fusion of the linguistic and non-linguistic models decreased false accepts for all, but the UAV images. We conclude that linguistic and non-linguistic representations of body shape can offer complementary identity information for bodies that can improve identification in applications of interest.
STT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023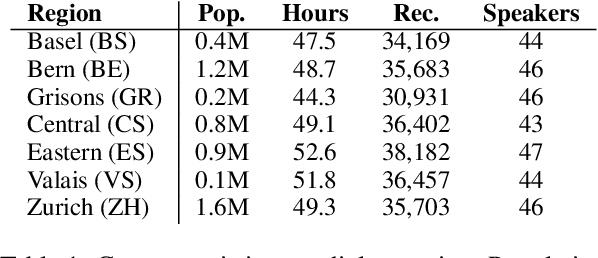
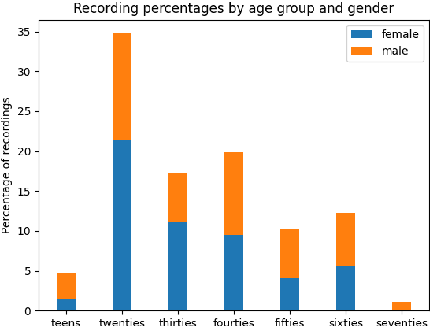
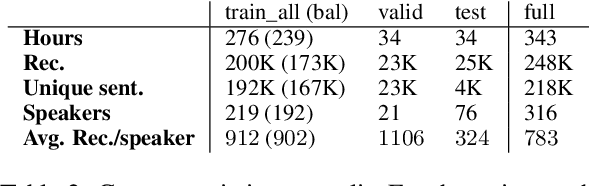
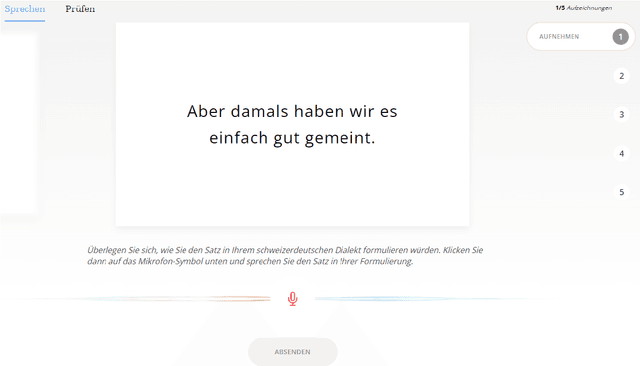
We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
Low Precision Quantization-aware Training in Spiking Neural Networks with Differentiable Quantization Function
May 30, 2023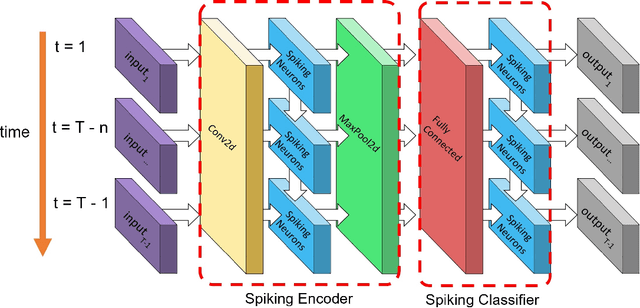
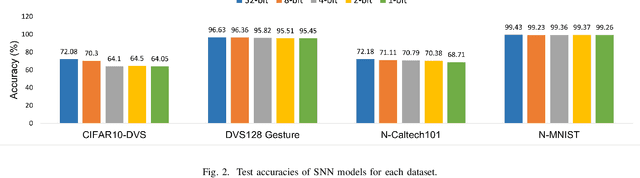
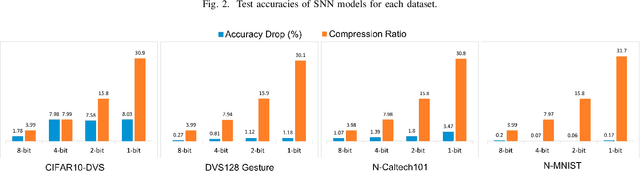
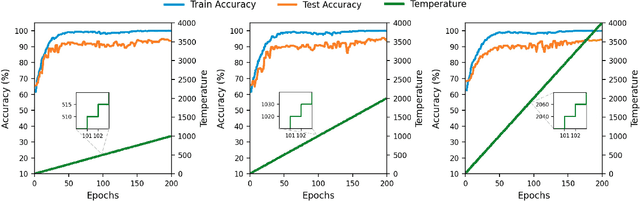
Deep neural networks have been proven to be highly effective tools in various domains, yet their computational and memory costs restrict them from being widely deployed on portable devices. The recent rapid increase of edge computing devices has led to an active search for techniques to address the above-mentioned limitations of machine learning frameworks. The quantization of artificial neural networks (ANNs), which converts the full-precision synaptic weights into low-bit versions, emerged as one of the solutions. At the same time, spiking neural networks (SNNs) have become an attractive alternative to conventional ANNs due to their temporal information processing capability, energy efficiency, and high biological plausibility. Despite being driven by the same motivation, the simultaneous utilization of both concepts has yet to be thoroughly studied. Therefore, this work aims to bridge the gap between recent progress in quantized neural networks and SNNs. It presents an extensive study on the performance of the quantization function, represented as a linear combination of sigmoid functions, exploited in low-bit weight quantization in SNNs. The presented quantization function demonstrates the state-of-the-art performance on four popular benchmarks, CIFAR10-DVS, DVS128 Gesture, N-Caltech101, and N-MNIST, for binary networks (64.05\%, 95.45\%, 68.71\%, and 99.43\% respectively) with small accuracy drops and up to 31$\times$ memory savings, which outperforms existing methods.
Autonomous GIS: the next-generation AI-powered GIS
May 10, 2023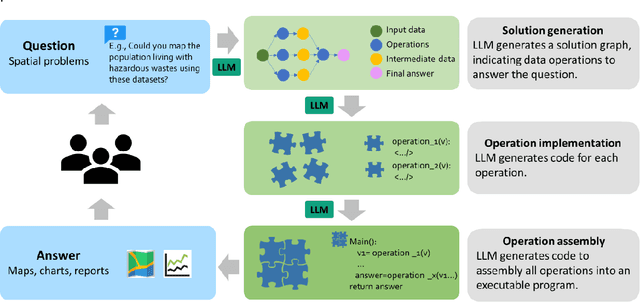
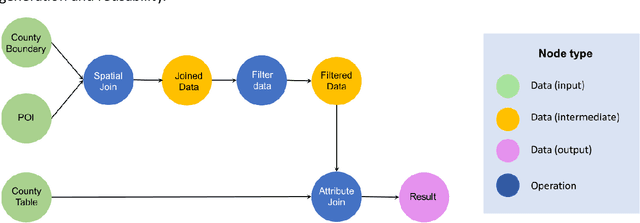


Large Language Models (LLMs), such as ChatGPT, demonstrate a strong understanding of human natural language and have been explored and applied in various fields, including reasoning, creative writing, code generation, translation, and information retrieval. By adopting LLM as the reasoning core, we propose Autonomous GIS, an AI-powered geographic information system (GIS) that leverages the LLM's general abilities in natural language understanding, reasoning and coding for addressing spatial problems with automatic spatial data collection, analysis and visualization. We envision that autonomous GIS will need to achieve five autonomous goals including self-generating, self-organizing, self-verifying, self-executing, and self-growing. We introduce the design principles of autonomous GIS to achieve these five autonomous goals from the aspects of information sufficiency, LLM ability, and agent architecture. We developed a prototype system called LLM-Geo using GPT-4 API in a Python environment, demonstrating what an autonomous GIS looks like and how it delivers expected results without human intervention using two case studies. For both case studies, LLM-Geo successfully returned accurate results, including aggregated numbers, graphs, and maps, significantly reducing manual operation time. Although still lacking several important modules such as logging and code testing, LLM-Geo demonstrates a potential path towards next-generation AI-powered GIS. We advocate for the GIScience community to dedicate more effort to the research and development of autonomous GIS, making spatial analysis easier, faster, and more accessible to a broader audience.
Finding Meaningful Distributions of ML Black-boxes under Forensic Investigation
May 10, 2023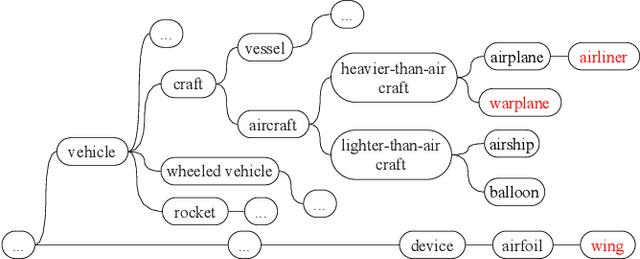
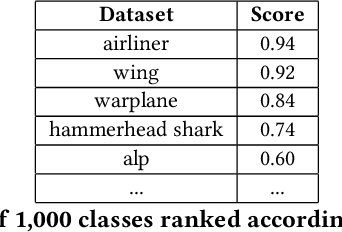
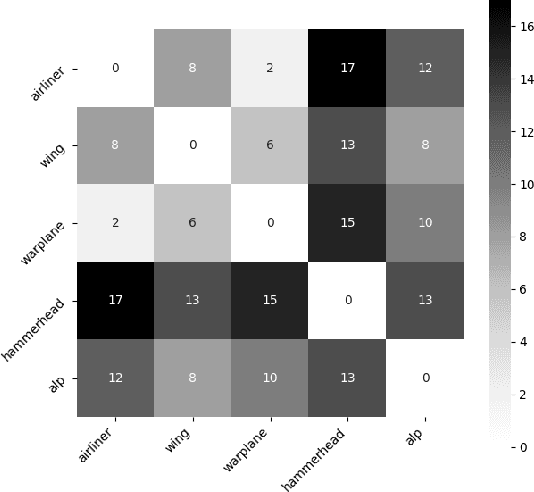
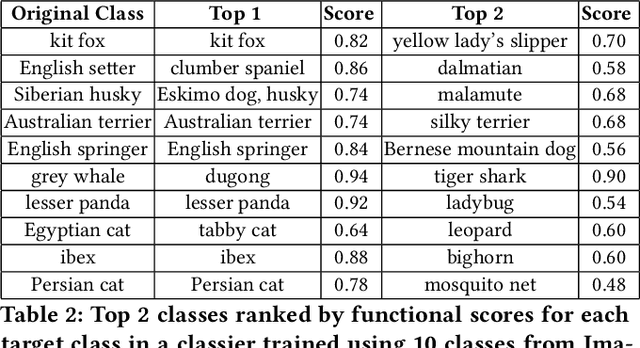
Given a poorly documented neural network model, we take the perspective of a forensic investigator who wants to find out the model's data domain (e.g. whether on face images or traffic signs). Although existing methods such as membership inference and model inversion can be used to uncover some information about an unknown model, they still require knowledge of the data domain to start with. In this paper, we propose solving this problem by leveraging on comprehensive corpus such as ImageNet to select a meaningful distribution that is close to the original training distribution and leads to high performance in follow-up investigations. The corpus comprises two components, a large dataset of samples and meta information such as hierarchical structure and textual information on the samples. Our goal is to select a set of samples from the corpus for the given model. The core of our method is an objective function that considers two criteria on the selected samples: the model functional properties (derived from the dataset), and semantics (derived from the metadata). We also give an algorithm to efficiently search the large space of all possible subsets w.r.t. the objective function. Experimentation results show that the proposed method is effective. For example, cloning a given model (originally trained with CIFAR-10) by using Caltech 101 can achieve 45.5% accuracy. By using datasets selected by our method, the accuracy is improved to 72.0%.
Towards Bias Correction of FedAvg over Nonuniform and Time-Varying Communications
Jun 01, 2023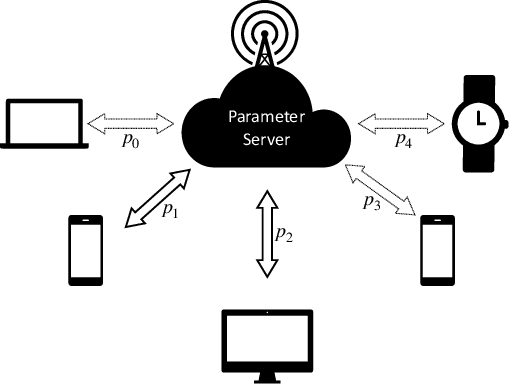
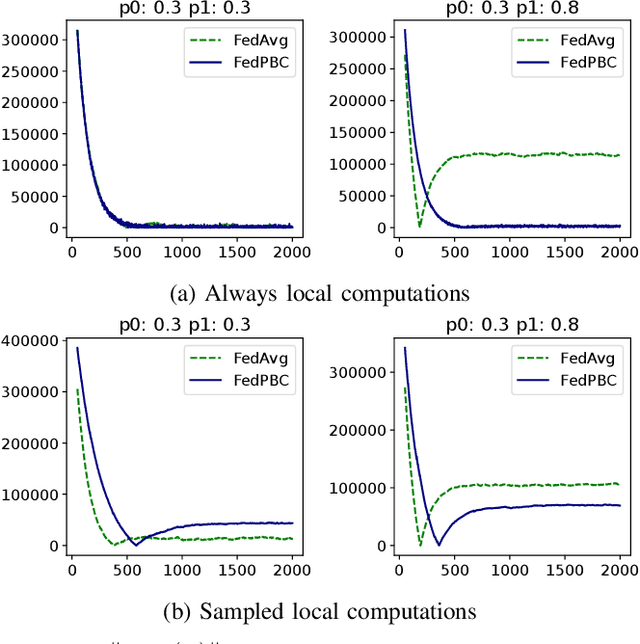
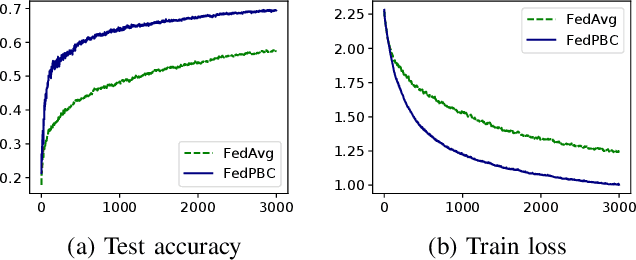
Federated learning (FL) is a decentralized learning framework wherein a parameter server (PS) and a collection of clients collaboratively train a model via minimizing a global objective. Communication bandwidth is a scarce resource; in each round, the PS aggregates the updates from a subset of clients only. In this paper, we focus on non-convex minimization that is vulnerable to non-uniform and time-varying communication failures between the PS and the clients. Specifically, in each round $t$, the link between the PS and client $i$ is active with probability $p_i^t$, which is $\textit{unknown}$ to both the PS and the clients. This arises when the channel conditions are heterogeneous across clients and are changing over time. We show that when the $p_i^t$'s are not uniform, $\textit{Federated Average}$ (FedAvg) -- the most widely adopted FL algorithm -- fails to minimize the global objective. Observing this, we propose $\textit{Federated Postponed Broadcast}$ (FedPBC) which is a simple variant of FedAvg. It differs from FedAvg in that the PS postpones broadcasting the global model till the end of each round. We show that FedPBC converges to a stationary point of the original objective. The introduced staleness is mild and there is no noticeable slowdown. Both theoretical analysis and numerical results are provided. On the technical front, postponing the global model broadcasts enables implicit gossiping among the clients with active links at round $t$. Despite $p_i^t$'s are time-varying, we are able to bound the perturbation of the global model dynamics via the techniques of controlling the gossip-type information mixing errors.
Contrastive Learning MRI Reconstruction
Jun 01, 2023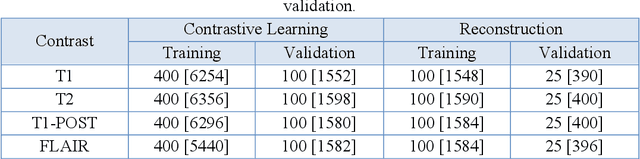
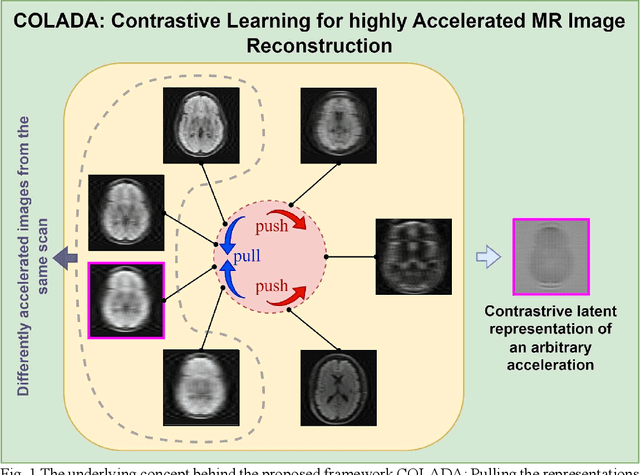
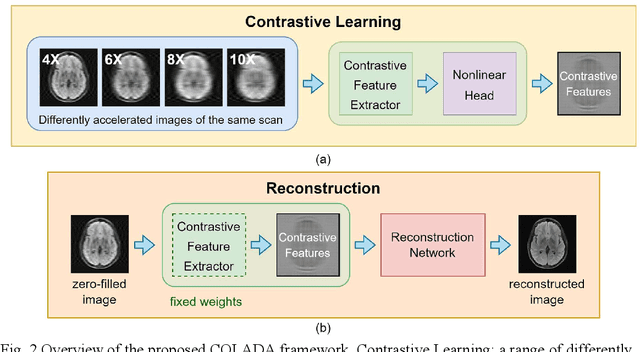
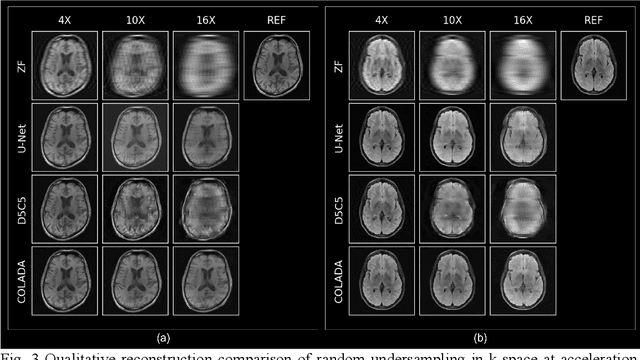
Purpose: We propose a novel contrastive learning latent space representation for MRI datasets with partially acquired scans. We show that this latent space can be utilized for accelerated MR image reconstruction. Theory and Methods: Our novel framework, referred to as COLADA (stands for Contrastive Learning for highly accelerated MR image reconstruction), maximizes the mutual information between differently accelerated images of an MRI scan by using self-supervised contrastive learning. In other words, it attempts to "pull" the latent representations of the same scan together and "push" the latent representations of other scans away. The generated MRI latent space is subsequently utilized for MR image reconstruction and the performance was assessed in comparison to several baseline deep learning reconstruction methods. Furthermore, the quality of the proposed latent space representation was analyzed using Alignment and Uniformity. Results: COLADA comprehensively outperformed other reconstruction methods with robustness to variations in undersampling patterns, pathological abnormalities, and noise in k-space during inference. COLADA proved the high quality of reconstruction on unseen data with minimal fine-tuning. The analysis of representation quality suggests that the contrastive features produced by COLADA are optimally distributed in latent space. Conclusion: To the best of our knowledge, this is the first attempt to utilize contrastive learning on differently accelerated images for MR image reconstruction. The proposed latent space representation has practical usage due to a large number of existing partially sampled datasets. This implies the possibility of exploring self-supervised contrastive learning further to enhance the latent space of MRI for image reconstruction.
Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment
Jun 01, 2023
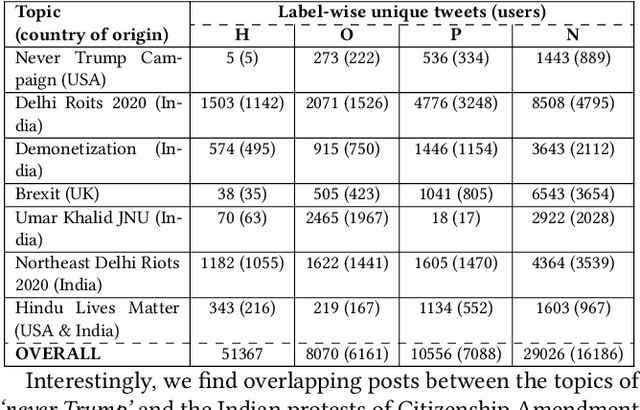
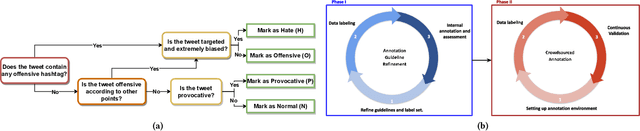
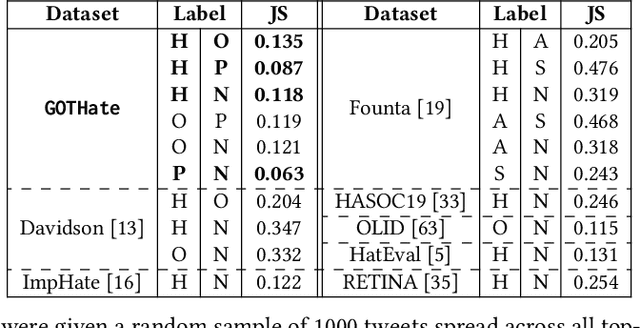
Social media is awash with hateful content, much of which is often veiled with linguistic and topical diversity. The benchmark datasets used for hate speech detection do not account for such divagation as they are predominantly compiled using hate lexicons. However, capturing hate signals becomes challenging in neutrally-seeded malicious content. Thus, designing models and datasets that mimic the real-world variability of hate warrants further investigation. To this end, we present GOTHate, a large-scale code-mixed crowdsourced dataset of around 51k posts for hate speech detection from Twitter. GOTHate is neutrally seeded, encompassing different languages and topics. We conduct detailed comparisons of GOTHate with the existing hate speech datasets, highlighting its novelty. We benchmark it with 10 recent baselines. Our extensive empirical and benchmarking experiments suggest that GOTHate is hard to classify in a text-only setup. Thus, we investigate how adding endogenous signals enhances the hate speech detection task. We augment GOTHate with the user's timeline information and ego network, bringing the overall data source closer to the real-world setup for understanding hateful content. Our proposed solution HEN-mBERT is a modular, multilingual, mixture-of-experts model that enriches the linguistic subspace with latent endogenous signals from history, topology, and exemplars. HEN-mBERT transcends the best baseline by 2.5% and 5% in overall macro-F1 and hate class F1, respectively. Inspired by our experiments, in partnership with Wipro AI, we are developing a semi-automated pipeline to detect hateful content as a part of their mission to tackle online harm.
Strengths and Weaknesses of 3D Pose Estimation and Inertial Motion Capture System for Movement Therapy
Jun 01, 2023
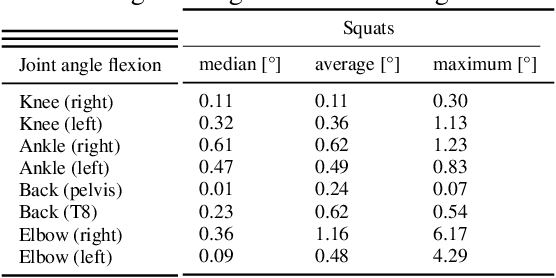
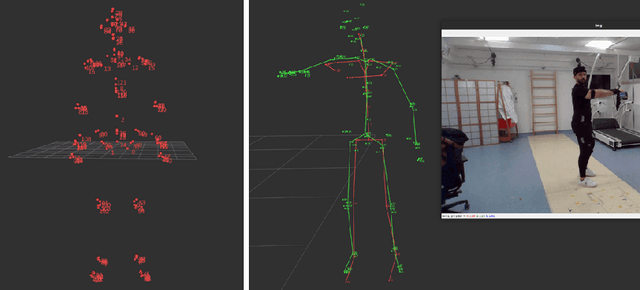
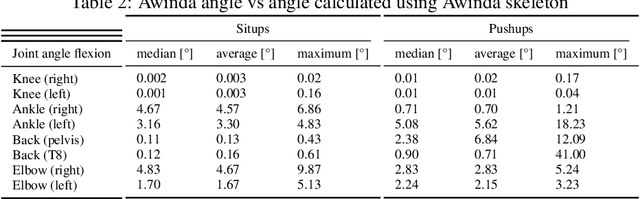
3D pose estimation offers the opportunity for fast, non-invasive, and accurate motion analysis. This is of special interest also for clinical use. Currently, motion capture systems are used, as they offer robust and precise data acquisition, which is essential in the case of clinical applications. In this study, we investigate the accuracy of the state-of-the-art 3D position estimation approach MeTrabs, compared to the established inertial sensor system MTw Awinda for specific motion exercises. The study uses and provides an evaluation dataset of parallel recordings from 10 subjects during various movement therapy exercises. The information from the Awinda system and the frames for monocular pose estimation are synchronized. For the comparison, clinically relevant parameters for joint angles of ankle, knee, back, and elbow flexion-extension were estimated and evaluated using mean, median, and maximum deviation between the calculated joint angles for the different exercises, camera positions, and clothing items. The results of the analysis indicate that the mean and median deviations can be kept below 5{\deg} for some of the studied angles. These joints could be considered for medical applications even considering the maximum deviations of 15{\deg}. However, caution should be applied to certain particularly problematic joints. In particular, elbow flexions, which showed high maximum deviations of up to 50{\deg} in our analysis. Furthermore, the type of exercise plays a crucial role in the reliable and safe application of the 3D position estimation method. For example, all joint angles showed a significant deterioration in performance during exercises near the ground.
Deep Operator Learning-based Surrogate Models with Uncertainty Quantification for Optimizing Internal Cooling Channel Rib Profiles
Jun 01, 2023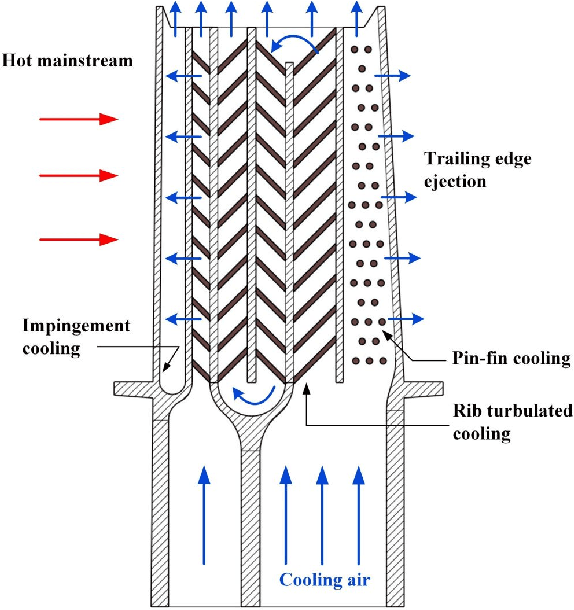
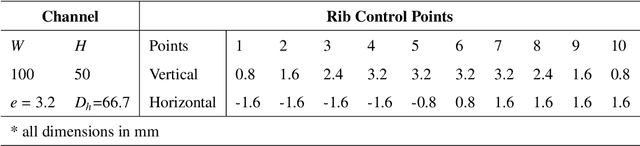
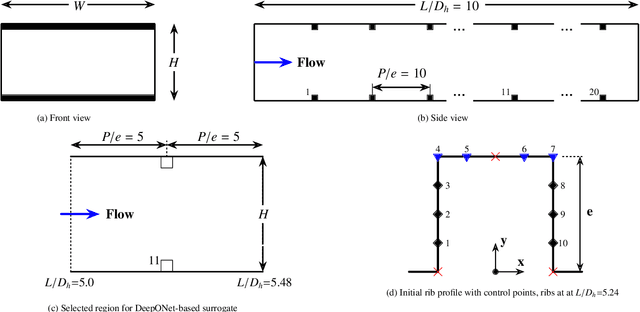

This paper designs surrogate models with uncertainty quantification capabilities to improve the thermal performance of rib-turbulated internal cooling channels effectively. To construct the surrogate, we use the deep operator network (DeepONet) framework, a novel class of neural networks designed to approximate mappings between infinite-dimensional spaces using relatively small datasets. The proposed DeepONet takes an arbitrary continuous rib geometry with control points as input and outputs continuous detailed information about the distribution of pressure and heat transfer around the profiled ribs. The datasets needed to train and test the proposed DeepONet framework were obtained by simulating a 2D rib-roughened internal cooling channel. To accomplish this, we continuously modified the input rib geometry by adjusting the control points according to a simple random distribution with constraints, rather than following a predefined path or sampling method. The studied channel has a hydraulic diameter, Dh, of 66.7 mm, and a length-to-hydraulic diameter ratio, L/Dh, of 10. The ratio of rib center height to hydraulic diameter (e/Dh), which was not changed during the rib profile update, was maintained at a constant value of 0.048. The ribs were placed in the channel with a pitch-to-height ratio (P/e) of 10. In addition, we provide the proposed surrogates with effective uncertainty quantification capabilities. This is achieved by converting the DeepONet framework into a Bayesian DeepONet (B-DeepONet). B-DeepONet samples from the posterior distribution of DeepONet parameters using the novel framework of stochastic gradient replica-exchange MCMC.