 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SDSTrack: Self-Distillation Symmetric Adapter Learning for Multi-Modal Visual Object Tracking
Mar 28, 2024
Multimodal Visual Object Tracking (VOT) has recently gained significant attention due to its robustness. Early research focused on fully fine-tuning RGB-based trackers, which was inefficient and lacked generalized representation due to the scarcity of multimodal data. Therefore, recent studies have utilized prompt tuning to transfer pre-trained RGB-based trackers to multimodal data. However, the modality gap limits pre-trained knowledge recall, and the dominance of the RGB modality persists, preventing the full utilization of information from other modalities. To address these issues, we propose a novel symmetric multimodal tracking framework called SDSTrack. We introduce lightweight adaptation for efficient fine-tuning, which directly transfers the feature extraction ability from RGB to other domains with a small number of trainable parameters and integrates multimodal features in a balanced, symmetric manner. Furthermore, we design a complementary masked patch distillation strategy to enhance the robustness of trackers in complex environments, such as extreme weather, poor imaging, and sensor failure. Extensive experiments demonstrate that SDSTrack outperforms state-of-the-art methods in various multimodal tracking scenarios, including RGB+Depth, RGB+Thermal, and RGB+Event tracking, and exhibits impressive results in extreme conditions. Our source code is available at https://github.com/hoqolo/SDSTrack.
DeNetDM: Debiasing by Network Depth Modulation
Mar 28, 2024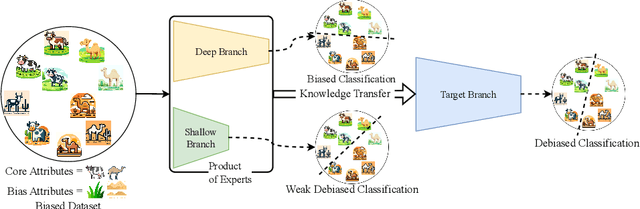
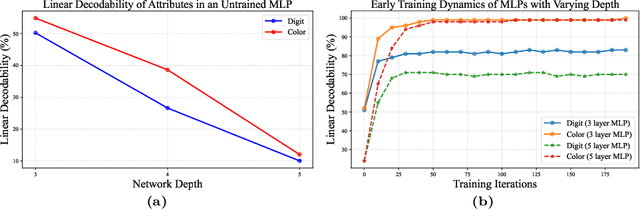
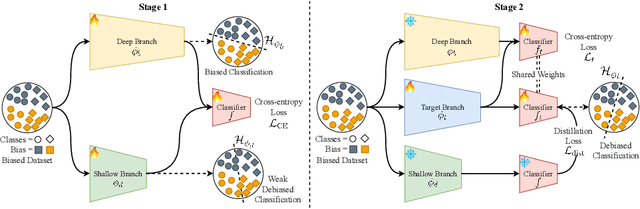
When neural networks are trained on biased datasets, they tend to inadvertently learn spurious correlations, leading to challenges in achieving strong generalization and robustness. Current approaches to address such biases typically involve utilizing bias annotations, reweighting based on pseudo-bias labels, or enhancing diversity within bias-conflicting data points through augmentation techniques. We introduce DeNetDM, a novel debiasing method based on the observation that shallow neural networks prioritize learning core attributes, while deeper ones emphasize biases when tasked with acquiring distinct information. Using a training paradigm derived from Product of Experts, we create both biased and debiased branches with deep and shallow architectures and then distill knowledge to produce the target debiased model. Extensive experiments and analyses demonstrate that our approach outperforms current debiasing techniques, achieving a notable improvement of around 5% in three datasets, encompassing both synthetic and real-world data. Remarkably, DeNetDM accomplishes this without requiring annotations pertaining to bias labels or bias types, while still delivering performance on par with supervised counterparts. Furthermore, our approach effectively harnesses the diversity of bias-conflicting points within the data, surpassing previous methods and obviating the need for explicit augmentation-based methods to enhance the diversity of such bias-conflicting points. The source code will be available upon acceptance.
Co-Designing Statistical MIMO Radar and In-band Full-Duplex Multi-User MIMO Communications -- Part II: Joint Precoder, Radar Code, and Receive Filters Design
Mar 28, 2024We address the challenge of spectral sharing between a statistical multiple-input multiple-output (MIMO) radar and an in-band full-duplex (IBFD) multi-user MIMO (MU-MIMO) communications system operating simultaneously in the same frequency band. Existing research on joint MIMO-radar-MIMO-communications (MRMC) systems has limitations, such as focusing on colocated MIMO radars, half-duplex MIMO communications, single-user scenarios, neglecting practical constraints, or employing separate transmit/receive units for MRMC coexistence. This paper, along with companion papers (Part I and III), proposes a comprehensive MRMC framework that addresses all these challenges. In the previous companion paper (Part I), we presented signal processing techniques for a distributed IBFD MRMC system. In this paper, we introduce joint design of statistical MIMO radar codes, uplink/downlink precoders, and corresponding receive filters using a novel metric called compounded-and-weighted sum mutual information. To solve the resulting highly non-convex problem, we employ a combination of block coordinate descent (BCD) and alternating projection methods. Numerical experiments show convergence of our algorithm, mitigation of uplink interference, and stable data rates under varying noise levels, channel estimate imperfections, and self-interference. The subsequent companion paper (Part III) extends the discussion to multiple targets and evaluates the tracking performance of our MRMC system.
IME: Integrating Multi-curvature Shared and Specific Embedding for Temporal Knowledge Graph Completion
Mar 28, 2024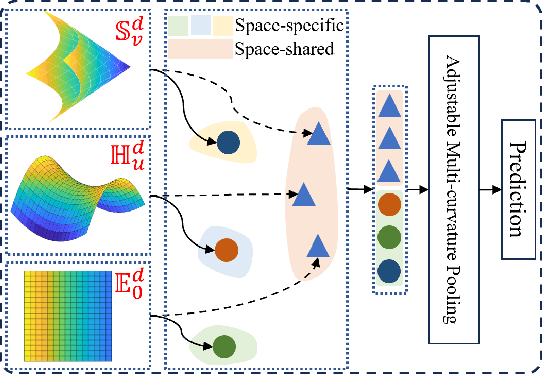
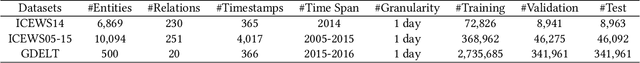
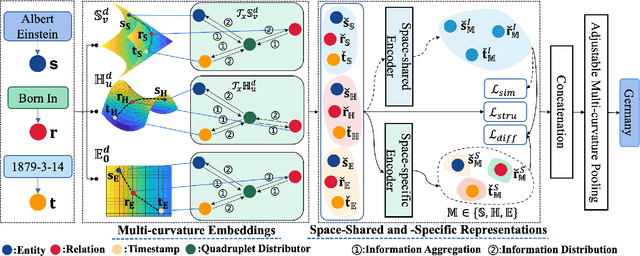
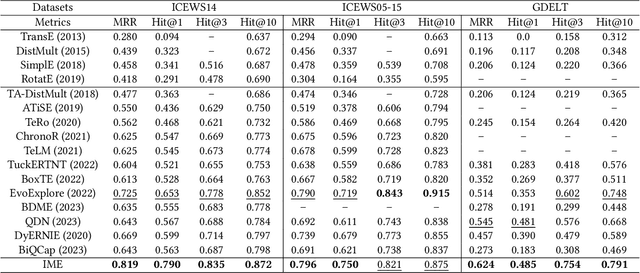
Temporal Knowledge Graphs (TKGs) incorporate a temporal dimension, allowing for a precise capture of the evolution of knowledge and reflecting the dynamic nature of the real world. Typically, TKGs contain complex geometric structures, with various geometric structures interwoven. However, existing Temporal Knowledge Graph Completion (TKGC) methods either model TKGs in a single space or neglect the heterogeneity of different curvature spaces, thus constraining their capacity to capture these intricate geometric structures. In this paper, we propose a novel Integrating Multi-curvature shared and specific Embedding (IME) model for TKGC tasks. Concretely, IME models TKGs into multi-curvature spaces, including hyperspherical, hyperbolic, and Euclidean spaces. Subsequently, IME incorporates two key properties, namely space-shared property and space-specific property. The space-shared property facilitates the learning of commonalities across different curvature spaces and alleviates the spatial gap caused by the heterogeneous nature of multi-curvature spaces, while the space-specific property captures characteristic features. Meanwhile, IME proposes an Adjustable Multi-curvature Pooling (AMP) approach to effectively retain important information. Furthermore, IME innovatively designs similarity, difference, and structure loss functions to attain the stated objective. Experimental results clearly demonstrate the superior performance of IME over existing state-of-the-art TKGC models.
MAC: Maximizing Algebraic Connectivity for Graph Sparsification
Mar 28, 2024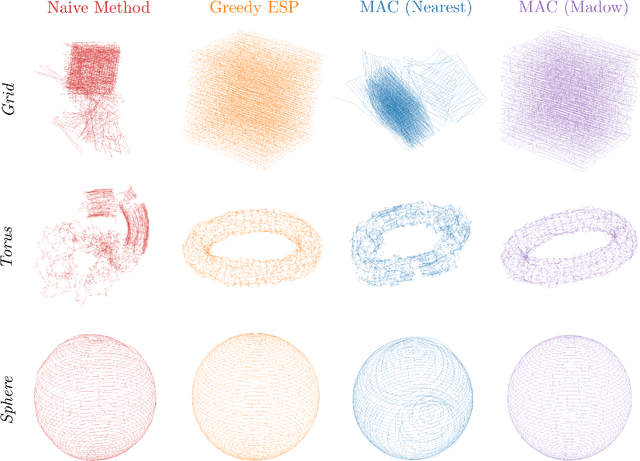
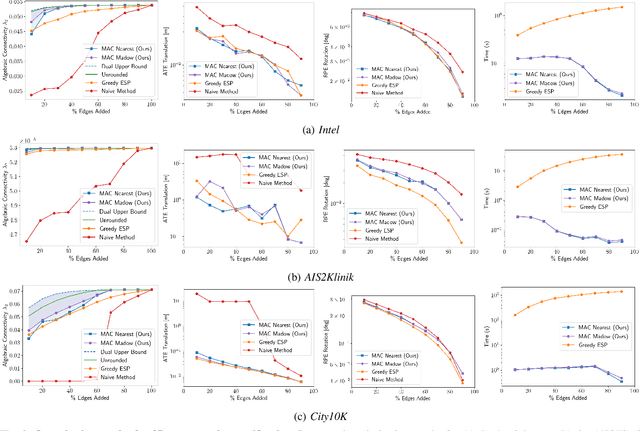
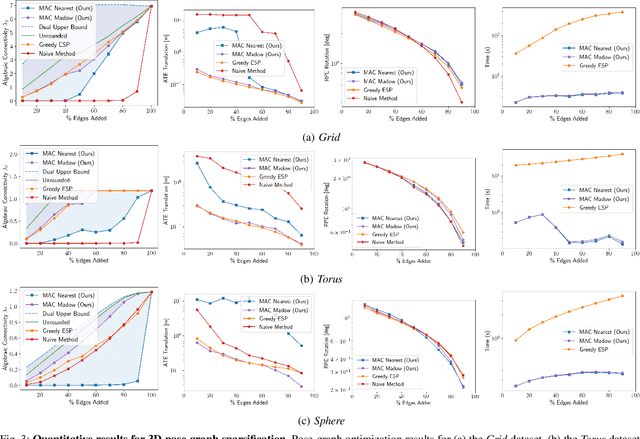
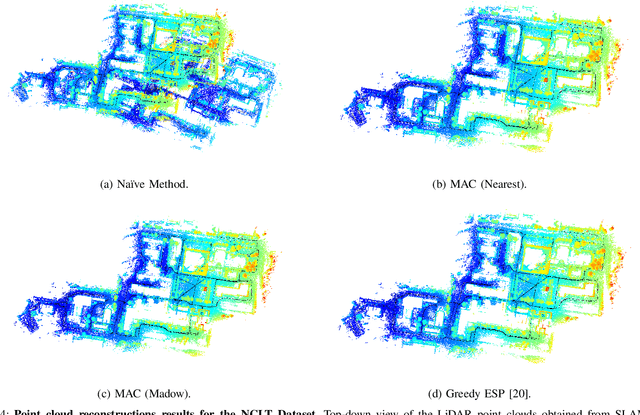
Simultaneous localization and mapping (SLAM) is a critical capability in autonomous navigation, but memory and computational limits make long-term application of common SLAM techniques impractical; a robot must be able to determine what information should be retained and what can safely be forgotten. In graph-based SLAM, the number of edges (measurements) in a pose graph determines both the memory requirements of storing a robot's observations and the computational expense of algorithms deployed for performing state estimation using those observations, both of which can grow unbounded during long-term navigation. Motivated by these challenges, we propose a new general purpose approach to sparsify graphs in a manner that maximizes algebraic connectivity, a key spectral property of graphs which has been shown to control the estimation error of pose graph SLAM solutions. Our algorithm, MAC (for maximizing algebraic connectivity), is simple and computationally inexpensive, and admits formal post hoc performance guarantees on the quality of the solution that it provides. In application to the problem of pose-graph SLAM, we show on several benchmark datasets that our approach quickly produces high-quality sparsification results which retain the connectivity of the graph and, in turn, the quality of corresponding SLAM solutions.
Image Coding for Machines with Edge Information Learning Using Segment Anything
Mar 07, 2024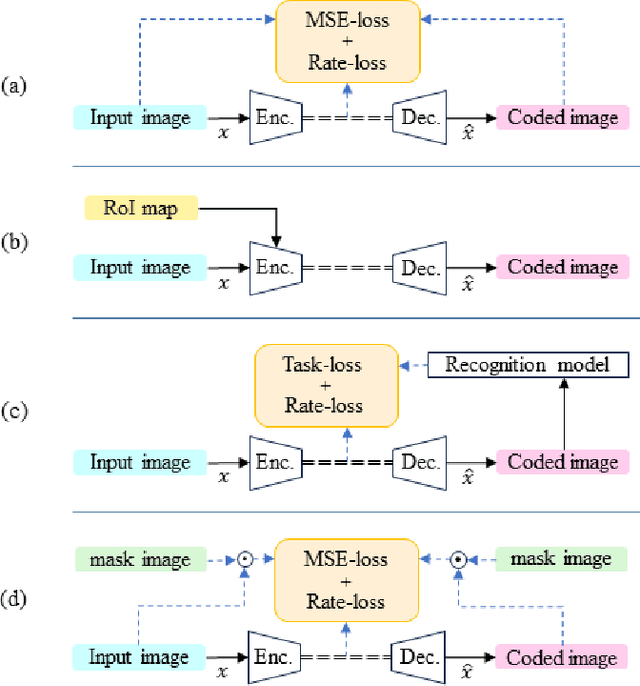

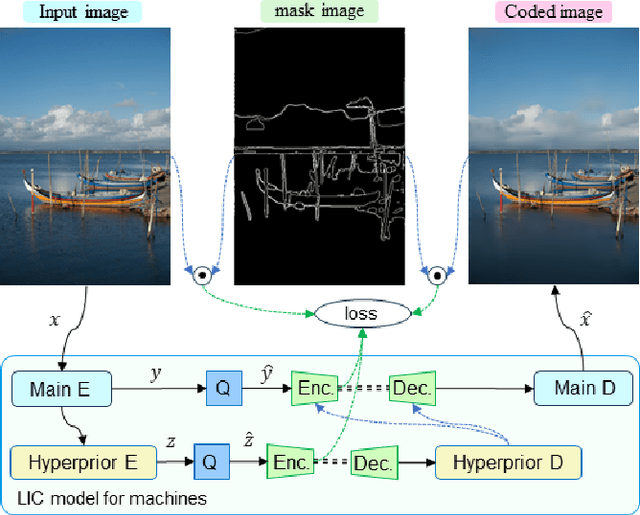
Image Coding for Machines (ICM) is an image compression technique for image recognition. This technique is essential due to the growing demand for image recognition AI. In this paper, we propose a method for ICM that focuses on encoding and decoding only the edge information of object parts in an image, which we call SA-ICM. This is an Learned Image Compression (LIC) model trained using edge information created by Segment Anything. Our method can be used for image recognition models with various tasks. SA-ICM is also robust to changes in input data, making it effective for a variety of use cases. Additionally, our method provides benefits from a privacy point of view, as it removes human facial information on the encoder's side, thus protecting one's privacy. Furthermore, this LIC model training method can be used to train Neural Representations for Videos (NeRV), which is a video compression model. By training NeRV using edge information created by Segment Anything, it is possible to create a NeRV that is effective for image recognition (SA-NeRV). Experimental results confirm the advantages of SA-ICM, presenting the best performance in image compression for image recognition. We also show that SA-NeRV is superior to ordinary NeRV in video compression for machines.
Partially Blinded Unlearning: Class Unlearning for Deep Networks a Bayesian Perspective
Mar 24, 2024In order to adhere to regulatory standards governing individual data privacy and safety, machine learning models must systematically eliminate information derived from specific subsets of a user's training data that can no longer be utilized. The emerging discipline of Machine Unlearning has arisen as a pivotal area of research, facilitating the process of selectively discarding information designated to specific sets or classes of data from a pre-trained model, thereby eliminating the necessity for extensive retraining from scratch. The principal aim of this study is to formulate a methodology tailored for the purposeful elimination of information linked to a specific class of data from a pre-trained classification network. This intentional removal is crafted to degrade the model's performance specifically concerning the unlearned data class while concurrently minimizing any detrimental impacts on the model's performance in other classes. To achieve this goal, we frame the class unlearning problem from a Bayesian perspective, which yields a loss function that minimizes the log-likelihood associated with the unlearned data with a stability regularization in parameter space. This stability regularization incorporates Mohalanobis distance with respect to the Fisher Information matrix and $l_2$ distance from the pre-trained model parameters. Our novel approach, termed \textbf{Partially-Blinded Unlearning (PBU)}, surpasses existing state-of-the-art class unlearning methods, demonstrating superior effectiveness. Notably, PBU achieves this efficacy without requiring awareness of the entire training dataset but only to the unlearned data points, marking a distinctive feature of its performance.
EXPLORA: A teacher-apprentice methodology for eliciting natural child-computer interactions
Mar 25, 2024Investigating child-computer interactions within their contexts is vital for designing technology that caters to children's needs. However, determining what aspects of context are relevant for designing child-centric technology remains a challenge. We introduce EXPLORA, a multimodal, multistage online methodology comprising three pivotal stages: (1) building a teacher-apprentice relationship,(2) learning from child-teachers, and (3) assessing and reinforcing researcher-apprentice learning. Central to EXPLORA is the collection of attitudinal data through pre-observation interviews, offering researchers a deeper understanding of children's characteristics and contexts. This informs subsequent online observations, allowing researchers to focus on frequent interactions. Furthermore, researchers can validate preliminary assumptions with children. A means-ends analysis framework aids in the systematic analysis of data, shedding light on context, agency and homework-information searching processes children employ in their activities. To illustrate EXPLORA's capabilities, we present nine single case studies investigating Brazilian child-caregiver dyads' (children ages 9-11) use of technology in homework information-searching.
If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions
Mar 25, 2024Recent works often assume that Vision-Language Model (VLM) representations are based on visual attributes like shape. However, it is unclear to what extent VLMs prioritize this information to represent concepts. We propose Extract and Explore (EX2), a novel approach to characterize important textual features for VLMs. EX2 uses reinforcement learning to align a large language model with VLM preferences and generates descriptions that incorporate the important features for the VLM. Then, we inspect the descriptions to identify the features that contribute to VLM representations. We find that spurious descriptions have a major role in VLM representations despite providing no helpful information, e.g., Click to enlarge photo of CONCEPT. More importantly, among informative descriptions, VLMs rely significantly on non-visual attributes like habitat to represent visual concepts. Also, our analysis reveals that different VLMs prioritize different attributes in their representations. Overall, we show that VLMs do not simply match images to scene descriptions and that non-visual or even spurious descriptions significantly influence their representations.
Belief Samples Are All You Need For Social Learning
Mar 25, 2024In this paper, we consider the problem of social learning, where a group of agents embedded in a social network are interested in learning an underlying state of the world. Agents have incomplete, noisy, and heterogeneous sources of information, providing them with recurring private observations of the underlying state of the world. Agents can share their learning experience with their peers by taking actions observable to them, with values from a finite feasible set of states. Actions can be interpreted as samples from the beliefs which agents may form and update on what the true state of the world is. Sharing samples, in place of full beliefs, is motivated by the limited communication, cognitive, and information-processing resources available to agents especially in large populations. Previous work (Salhab et al.) poses the question as to whether learning with probability one is still achievable if agents are only allowed to communicate samples from their beliefs. We provide a definite positive answer to this question, assuming a strongly connected network and a ``collective distinguishability'' assumption, which are both required for learning even in full-belief-sharing settings. In our proposed belief update mechanism, each agent's belief is a normalized weighted geometric interpolation between a fully Bayesian private belief -- aggregating information from the private source -- and an ensemble of empirical distributions of the samples shared by her neighbors over time. By carefully constructing asymptotic almost-sure lower/upper bounds on the frequency of shared samples matching the true state/or not, we rigorously prove the convergence of all the beliefs to the true state, with probability one.