 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DMS: Differentiable Mean Shift for Dataset Agnostic Task Specific Clustering Using Side Information
May 29, 2023

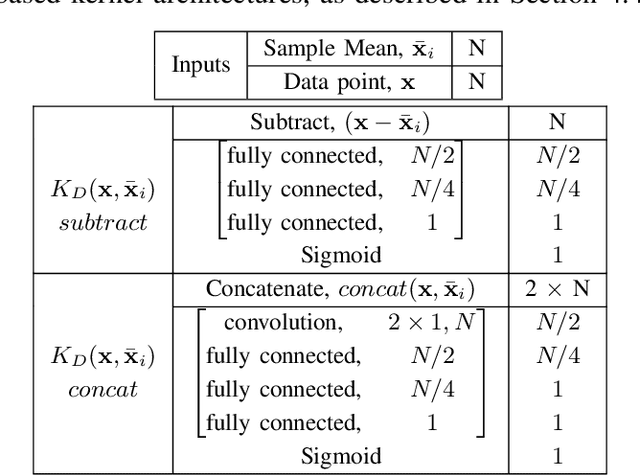
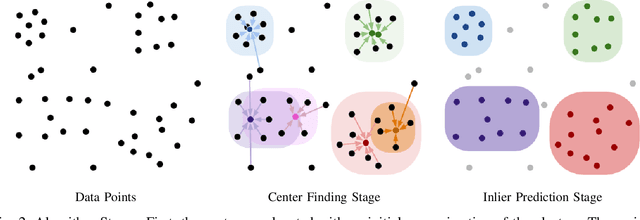
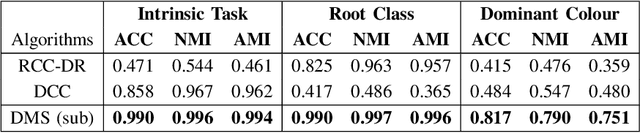
We present a novel approach, in which we learn to cluster data directly from side information, in the form of a small set of pairwise examples. Unlike previous methods, with or without side information, we do not need to know the number of clusters, their centers or any kind of distance metric for similarity. Our method is able to divide the same data points in various ways dependant on the needs of a specific task, defined by the side information. Contrastingly, other work generally finds only the intrinsic, most obvious, clusters. Inspired by the mean shift algorithm, we implement our new clustering approach using a custom iterative neural network to create Differentiable Mean Shift (DMS), a state of the art, dataset agnostic, clustering method. We found that it was possible to train a strong cluster definition without enforcing a constraint that each cluster must be presented during training. DMS outperforms current methods in both the intrinsic and non-intrinsic dataset tasks.
PURL: Safe and Effective Sanitization of Link Decoration
Aug 07, 2023While privacy-focused browsers have taken steps to block third-party cookies and browser fingerprinting, novel tracking methods that bypass existing defenses continue to emerge. Since trackers need to exfiltrate information from the client- to server-side through link decoration regardless of the tracking technique they employ, a promising orthogonal approach is to detect and sanitize tracking information in decorated links. We present PURL, a machine-learning approach that leverages a cross-layer graph representation of webpage execution to safely and effectively sanitize link decoration. Our evaluation shows that PURL significantly outperforms existing countermeasures in terms of accuracy and reducing website breakage while being robust to common evasion techniques. We use PURL to perform a measurement study on top-million websites. We find that link decorations are widely abused by well-known advertisers and trackers to exfiltrate user information collected from browser storage, email addresses, and scripts involved in fingerprinting.
Graph Neural Bandits
Aug 21, 2023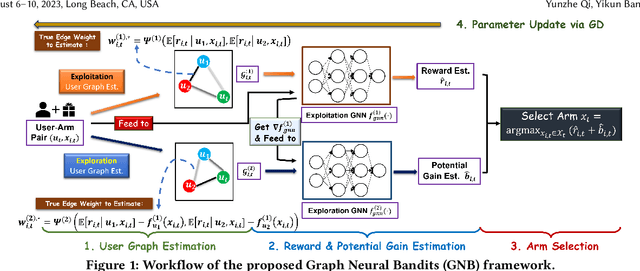
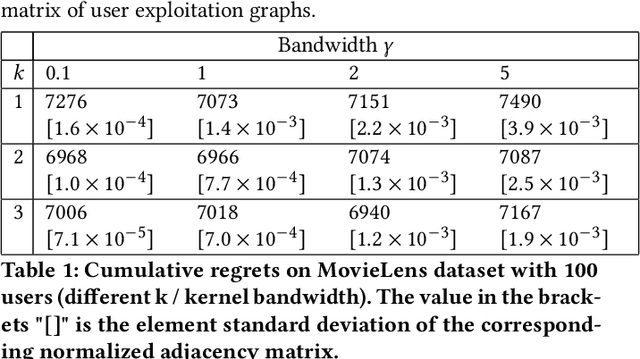
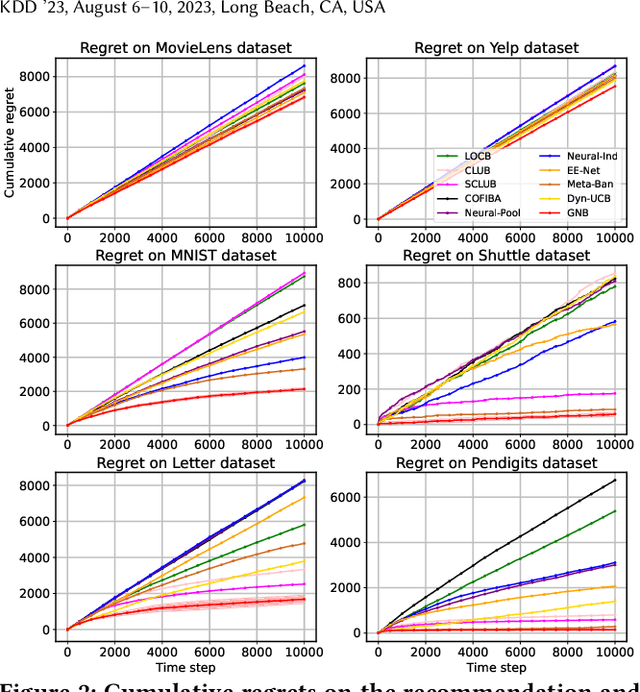
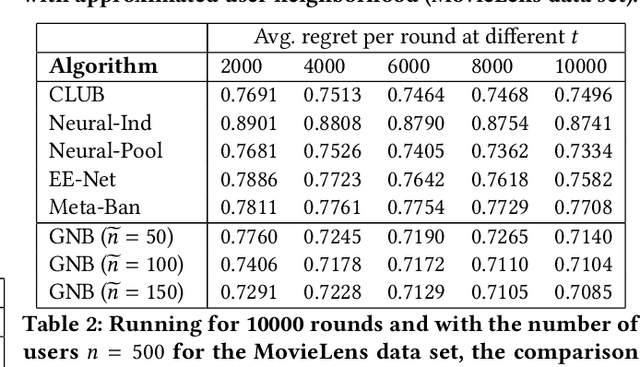
Contextual bandits algorithms aim to choose the optimal arm with the highest reward out of a set of candidates based on the contextual information. Various bandit algorithms have been applied to real-world applications due to their ability of tackling the exploitation-exploration dilemma. Motivated by online recommendation scenarios, in this paper, we propose a framework named Graph Neural Bandits (GNB) to leverage the collaborative nature among users empowered by graph neural networks (GNNs). Instead of estimating rigid user clusters as in existing works, we model the "fine-grained" collaborative effects through estimated user graphs in terms of exploitation and exploration respectively. Then, to refine the recommendation strategy, we utilize separate GNN-based models on estimated user graphs for exploitation and adaptive exploration. Theoretical analysis and experimental results on multiple real data sets in comparison with state-of-the-art baselines are provided to demonstrate the effectiveness of our proposed framework.
Patch Is Not All You Need
Aug 21, 2023Vision Transformers have achieved great success in computer visions, delivering exceptional performance across various tasks. However, their inherent reliance on sequential input enforces the manual partitioning of images into patch sequences, which disrupts the image's inherent structural and semantic continuity. To handle this, we propose a novel Pattern Transformer (Patternformer) to adaptively convert images to pattern sequences for Transformer input. Specifically, we employ the Convolutional Neural Network to extract various patterns from the input image, with each channel representing a unique pattern that is fed into the succeeding Transformer as a visual token. By enabling the network to optimize these patterns, each pattern concentrates on its local region of interest, thereby preserving its intrinsic structural and semantic information. Only employing the vanilla ResNet and Transformer, we have accomplished state-of-the-art performance on CIFAR-10 and CIFAR-100, and have achieved competitive results on ImageNet.
Self-supervised Scene Text Segmentation with Object-centric Layered Representations Augmented by Text Regions
Aug 25, 2023Text segmentation tasks have a very wide range of application values, such as image editing, style transfer, watermark removal, etc.However, existing public datasets are of poor quality of pixel-level labels that have been shown to be notoriously costly to acquire, both in terms of money and time. At the same time, when pretraining is performed on synthetic datasets, the data distribution of the synthetic datasets is far from the data distribution in the real scene. These all pose a huge challenge to the current pixel-level text segmentation algorithms.To alleviate the above problems, we propose a self-supervised scene text segmentation algorithm with layered decoupling of representations derived from the object-centric manner to segment images into texts and background. In our method, we propose two novel designs which include Region Query Module and Representation Consistency Constraints adapting to the unique properties of text as complements to Auto Encoder, which improves the network's sensitivity to texts.For this unique design, we treat the polygon-level masks predicted by the text localization model as extra input information, and neither utilize any pixel-level mask annotations for training stage nor pretrain on synthetic datasets.Extensive experiments show the effectiveness of the method proposed. On several public scene text datasets, our method outperforms the state-of-the-art unsupervised segmentation algorithms.
A Generic Machine Learning Framework for Fully-Unsupervised Anomaly Detection with Contaminated Data
Aug 25, 2023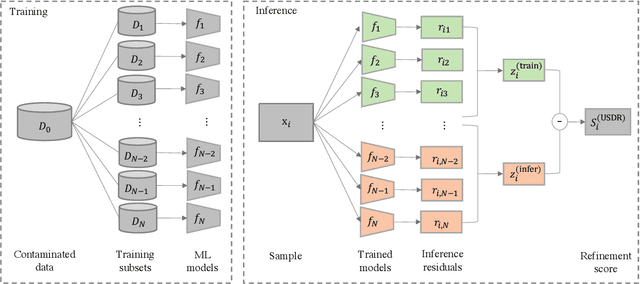
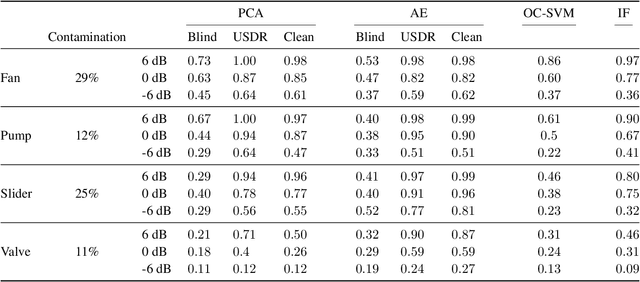
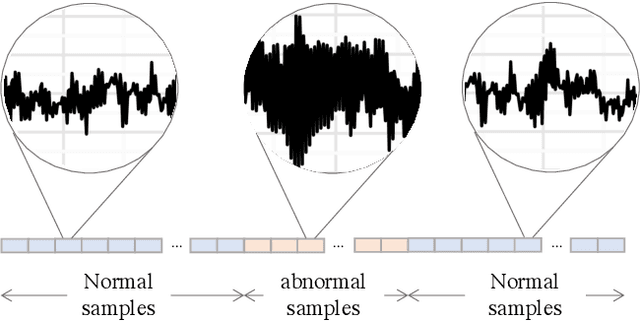
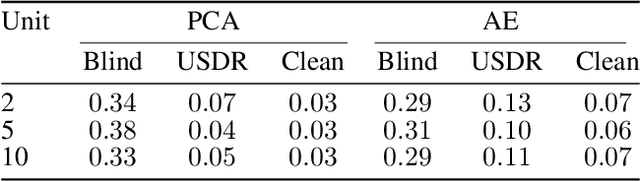
Anomaly detection (AD) tasks have been solved using machine learning algorithms in various domains and applications. The great majority of these algorithms use normal data to train a residual-based model, and assign anomaly scores to unseen samples based on their dissimilarity with the learned normal regime. The underlying assumption of these approaches is that anomaly-free data is available for training. This is, however, often not the case in real-world operational settings, where the training data may be contaminated with a certain fraction of abnormal samples. Training with contaminated data, in turn, inevitably leads to a deteriorated AD performance of the residual-based algorithms. In this paper we introduce a framework for a fully unsupervised refinement of contaminated training data for AD tasks. The framework is generic and can be applied to any residual-based machine learning model. We demonstrate the application of the framework to two public datasets of multivariate time series machine data from different application fields. We show its clear superiority over the naive approach of training with contaminated data without refinement. Moreover, we compare it to the ideal, unrealistic reference in which anomaly-free data would be available for training. Since the approach exploits information from the anomalies, and not only from the normal regime, it is comparable and often outperforms the ideal baseline as well.
Neural Influence Estimator: Towards Real-time Solutions to Influence Blocking Maximization
Aug 27, 2023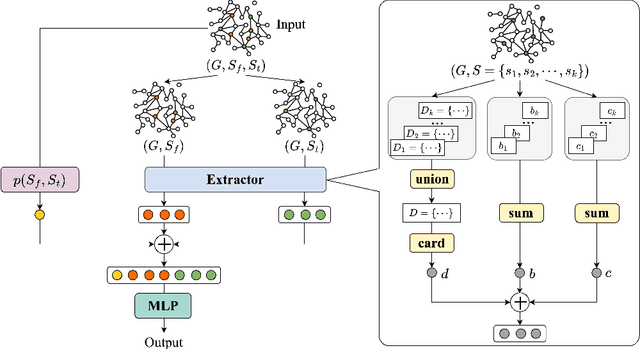
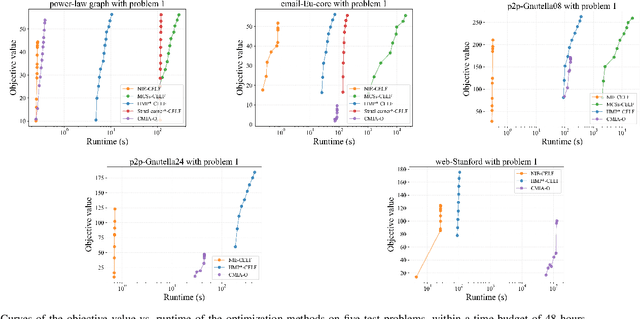
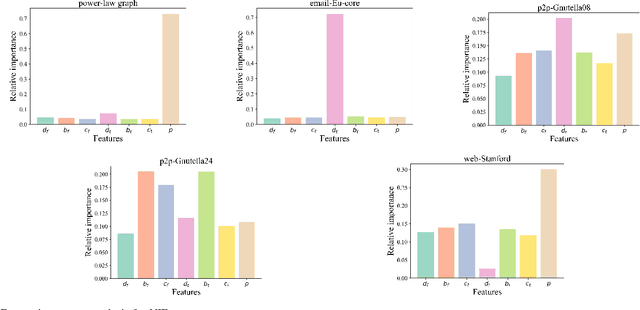
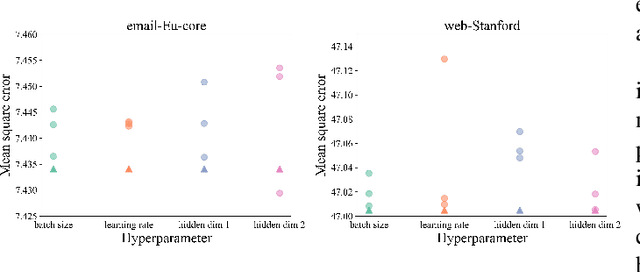
Real-time solutions to the influence blocking maximization (IBM) problems are crucial for promptly containing the spread of misinformation. However, achieving this goal is non-trivial, mainly because assessing the blocked influence of an IBM problem solution typically requires plenty of expensive Monte Carlo simulations (MCSs). Although several approaches have been proposed to enhance efficiency, they still fail to achieve real-time solutions to IBM problems of practical scales. This work presents a novel approach that enables solving IBM problems with hundreds of thousands of nodes and edges in seconds. The key idea is to construct a fast-to-evaluate surrogate model, called neural influence estimator (NIE), as a substitute for the time-intensive MCSs. To this end, a learning problem is formulated to build the NIE that takes the false-and-true information instance as input, extracts features describing the topology and inter-relationship between two seed sets, and predicts the blocked influence. A well-trained NIE can generalize across different IBM problems defined on a social network, and can be readily combined with existing IBM optimization algorithms such as the greedy algorithm. The experiments on 25 IBM problems with up to millions of edges show that the NIE-based optimization method can be up to four orders of magnitude faster than MCSs-based optimization method to achieve the same solution quality. Moreover, given a real-time constraint of one minute, the NIE-based method can solve IBM problems with up to hundreds of thousands of nodes, which is at least one order of magnitude larger than what can be solved by existing methods.
Information Screening whilst Exploiting! Multimodal Relation Extraction with Feature Denoising and Multimodal Topic Modeling
May 25, 2023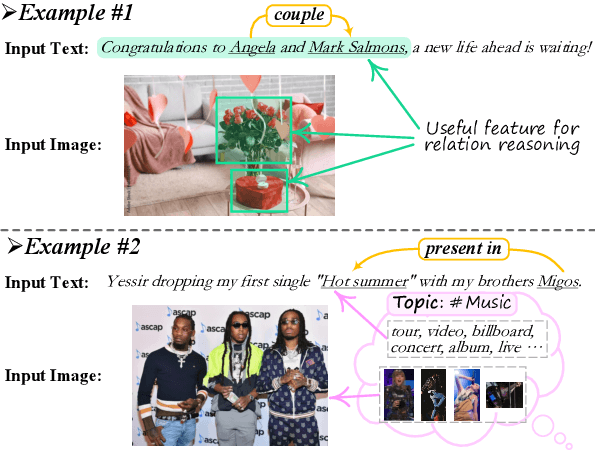
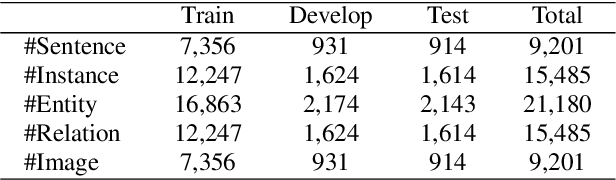
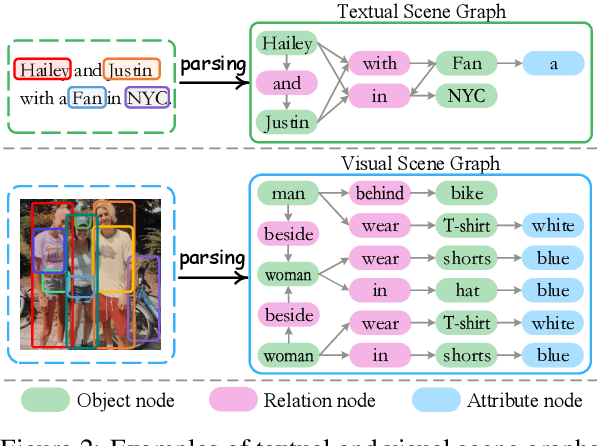
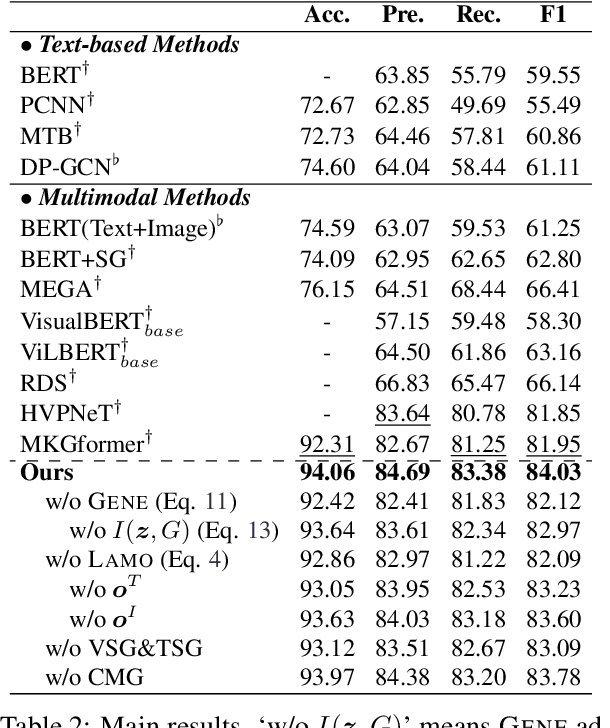
Existing research on multimodal relation extraction (MRE) faces two co-existing challenges, internal-information over-utilization and external-information under-exploitation. To combat that, we propose a novel framework that simultaneously implements the idea of internal-information screening and external-information exploiting. First, we represent the fine-grained semantic structures of the input image and text with the visual and textual scene graphs, which are further fused into a unified cross-modal graph (CMG). Based on CMG, we perform structure refinement with the guidance of the graph information bottleneck principle, actively denoising the less-informative features. Next, we perform topic modeling over the input image and text, incorporating latent multimodal topic features to enrich the contexts. On the benchmark MRE dataset, our system outperforms the current best model significantly. With further in-depth analyses, we reveal the great potential of our method for the MRE task. Our codes are open at https://github.com/ChocoWu/MRE-ISE.
Discrete Message via Online Clustering Labels in Decentralized POMDP
Aug 14, 2023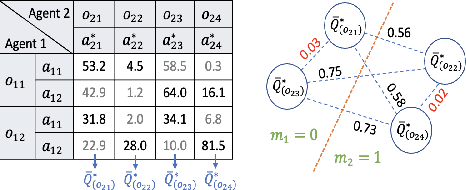
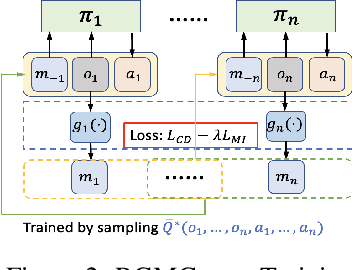
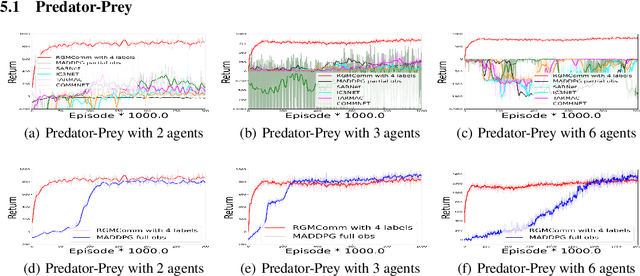
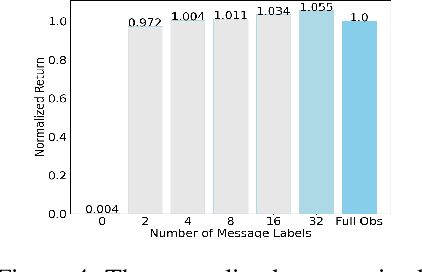
Communication is crucial for solving cooperative Multi-Agent Reinforcement Learning tasks in Partially-Observable Markov Decision Processes. Existing works often rely on black-box methods to encode local information/features into messages shared with other agents. However, such black-box approaches are unable to provide any quantitative guarantees on the expected return and often lead to the generation of continuous messages with high communication overhead and poor interpretability. In this paper, we establish an upper bound on the return gap between an ideal policy with full observability and an optimal partially-observable policy with discrete communication. This result enables us to recast multi-agent communication into a novel online clustering problem over the local observations at each agent, with messages as cluster labels and the upper bound on the return gap as clustering loss. By minimizing the upper bound, we propose a surprisingly simple design of message generation functions in multi-agent communication and integrate it with reinforcement learning using a Regularized Information Maximization loss function. Evaluations show that the proposed discrete communication significantly outperforms state-of-the-art multi-agent communication baselines and can achieve nearly-optimal returns with few-bit messages that are naturally interpretable.
Modeling the Dashboard Provenance
Aug 13, 2023
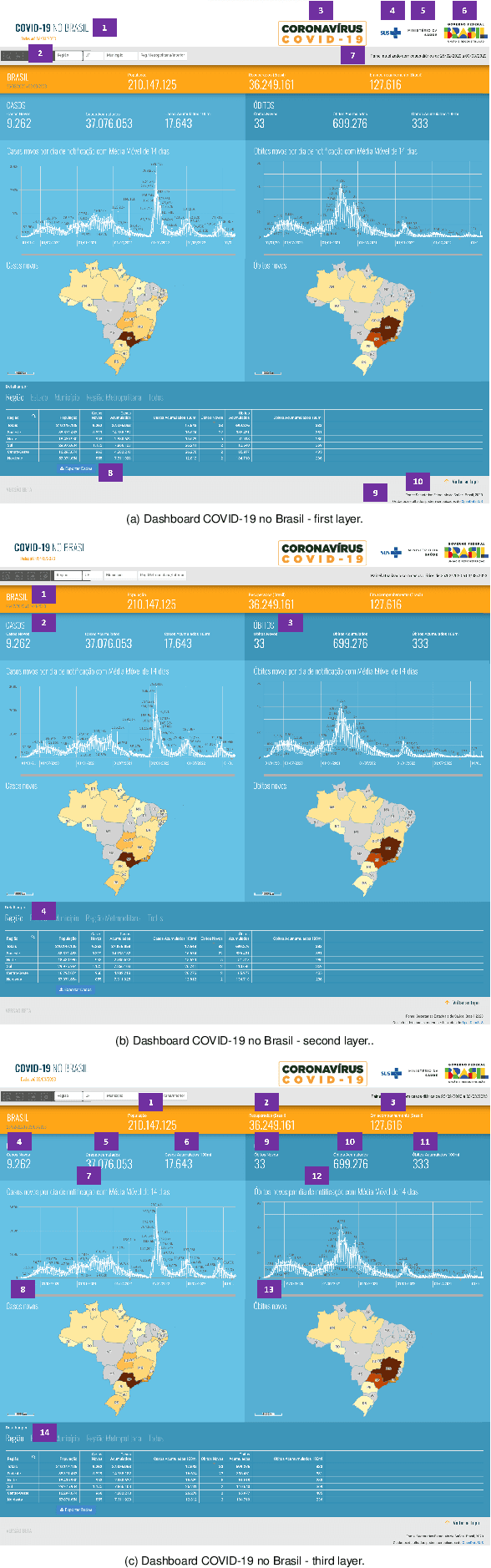
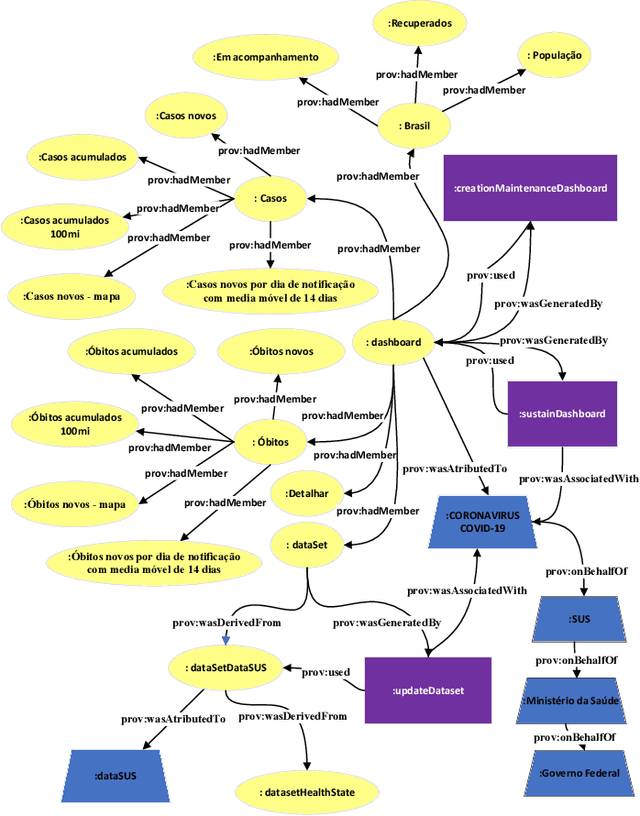
Organizations of all kinds, whether public or private, profit-driven or non-profit, and across various industries and sectors, rely on dashboards for effective data visualization. However, the reliability and efficacy of these dashboards rely on the quality of the visual and data they present. Studies show that less than a quarter of dashboards provide information about their sources, which is just one of the expected metadata when provenance is seriously considered. Provenance is a record that describes people, organizations, entities, and activities that had a role in the production, influence, or delivery of a piece of data or an object. This paper aims to provide a provenance representation model, that entitles standardization, modeling, generation, capture, and visualization, specifically designed for dashboards and its visual and data components. The proposed model will offer a comprehensive set of essential provenance metadata that enables users to evaluate the quality, consistency, and reliability of the information presented on dashboards. This will allow a clear and precise understanding of the context in which a specific dashboard was developed, ultimately leading to better decision-making.