 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Advancing Personalized Federated Learning: Group Privacy, Fairness, and Beyond
Sep 01, 2023
Federated learning (FL) is a framework for training machine learning models in a distributed and collaborative manner. During training, a set of participating clients process their data stored locally, sharing only the model updates obtained by minimizing a cost function over their local inputs. FL was proposed as a stepping-stone towards privacy-preserving machine learning, but it has been shown vulnerable to issues such as leakage of private information, lack of personalization of the model, and the possibility of having a trained model that is fairer to some groups than to others. In this paper, we address the triadic interaction among personalization, privacy guarantees, and fairness attained by models trained within the FL framework. Differential privacy and its variants have been studied and applied as cutting-edge standards for providing formal privacy guarantees. However, clients in FL often hold very diverse datasets representing heterogeneous communities, making it important to protect their sensitive information while still ensuring that the trained model upholds the aspect of fairness for the users. To attain this objective, a method is put forth that introduces group privacy assurances through the utilization of $d$-privacy (aka metric privacy). $d$-privacy represents a localized form of differential privacy that relies on a metric-oriented obfuscation approach to maintain the original data's topological distribution. This method, besides enabling personalized model training in a federated approach and providing formal privacy guarantees, possesses significantly better group fairness measured under a variety of standard metrics than a global model trained within a classical FL template. Theoretical justifications for the applicability are provided, as well as experimental validation on real-world datasets to illustrate the working of the proposed method.
Duplicate Question Retrieval and Confirmation Time Prediction in Software Communities
Sep 10, 2023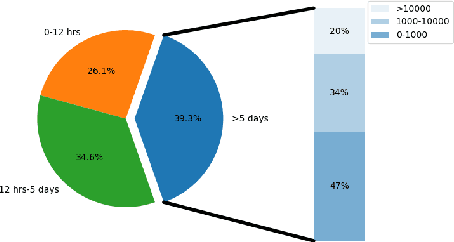
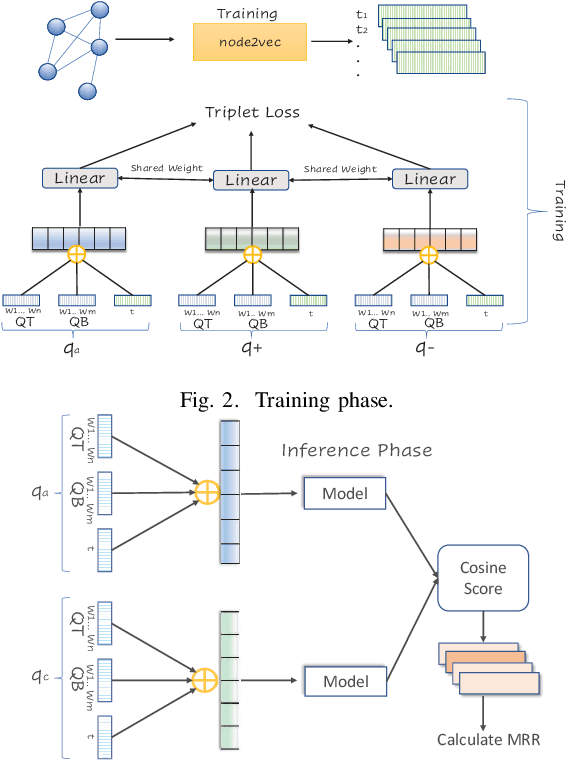


Community Question Answering (CQA) in different domains is growing at a large scale because of the availability of several platforms and huge shareable information among users. With the rapid growth of such online platforms, a massive amount of archived data makes it difficult for moderators to retrieve possible duplicates for a new question and identify and confirm existing question pairs as duplicates at the right time. This problem is even more critical in CQAs corresponding to large software systems like askubuntu where moderators need to be experts to comprehend something as a duplicate. Note that the prime challenge in such CQA platforms is that the moderators are themselves experts and are therefore usually extremely busy with their time being extraordinarily expensive. To facilitate the task of the moderators, in this work, we have tackled two significant issues for the askubuntu CQA platform: (1) retrieval of duplicate questions given a new question and (2) duplicate question confirmation time prediction. In the first task, we focus on retrieving duplicate questions from a question pool for a particular newly posted question. In the second task, we solve a regression problem to rank a pair of questions that could potentially take a long time to get confirmed as duplicates. For duplicate question retrieval, we propose a Siamese neural network based approach by exploiting both text and network-based features, which outperforms several state-of-the-art baseline techniques. Our method outperforms DupPredictor and DUPE by 5% and 7% respectively. For duplicate confirmation time prediction, we have used both the standard machine learning models and neural network along with the text and graph-based features. We obtain Spearman's rank correlation of 0.20 and 0.213 (statistically significant) for text and graph based features respectively.
Measuring Spurious Correlation in Classification: 'Clever Hans' in Translationese
Aug 25, 2023Recent work has shown evidence of 'Clever Hans' behavior in high-performance neural translationese classifiers, where BERT-based classifiers capitalize on spurious correlations, in particular topic information, between data and target classification labels, rather than genuine translationese signals. Translationese signals are subtle (especially for professional translation) and compete with many other signals in the data such as genre, style, author, and, in particular, topic. This raises the general question of how much of the performance of a classifier is really due to spurious correlations in the data versus the signals actually targeted for by the classifier, especially for subtle target signals and in challenging (low resource) data settings. We focus on topic-based spurious correlation and approach the question from two directions: (i) where we have no knowledge about spurious topic information and its distribution in the data, (ii) where we have some indication about the nature of spurious topic correlations. For (i) we develop a measure from first principles capturing alignment of unsupervised topics with target classification labels as an indication of spurious topic information in the data. We show that our measure is the same as purity in clustering and propose a 'topic floor' (as in a 'noise floor') for classification. For (ii) we investigate masking of known spurious topic carriers in classification. Both (i) and (ii) contribute to quantifying and (ii) to mitigating spurious correlations.
Learning Whole-body Manipulation for Quadrupedal Robot
Sep 06, 2023
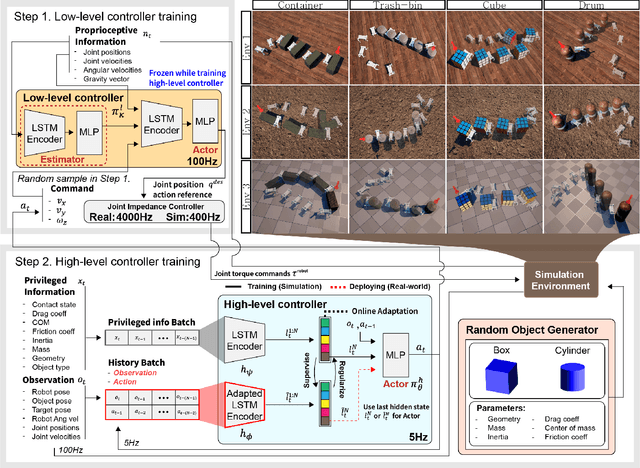
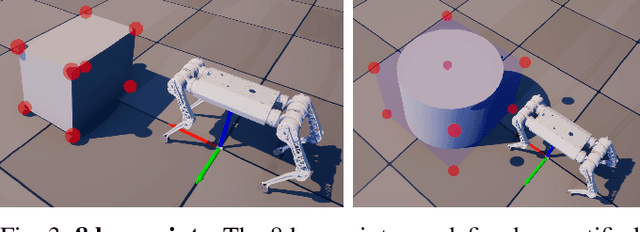

We propose a learning-based system for enabling quadrupedal robots to manipulate large, heavy objects using their whole body. Our system is based on a hierarchical control strategy that uses the deep latent variable embedding which captures manipulation-relevant information from interactions, proprioception, and action history, allowing the robot to implicitly understand object properties. We evaluate our framework in both simulation and real-world scenarios. In the simulation, it achieves a success rate of 93.6 % in accurately re-positioning and re-orienting various objects within a tolerance of 0.03 m and 5 {\deg}. Real-world experiments demonstrate the successful manipulation of objects such as a 19.2 kg water-filled drum and a 15.3 kg plastic box filled with heavy objects while the robot weighs 27 kg. Unlike previous works that focus on manipulating small and light objects using prehensile manipulation, our framework illustrates the possibility of using quadrupeds for manipulating large and heavy objects that are ungraspable with the robot's entire body. Our method does not require explicit object modeling and offers significant computational efficiency compared to optimization-based methods. The video can be found at https://youtu.be/fO_PVr27QxU.
InstructME: An Instruction Guided Music Edit And Remix Framework with Latent Diffusion Models
Sep 06, 2023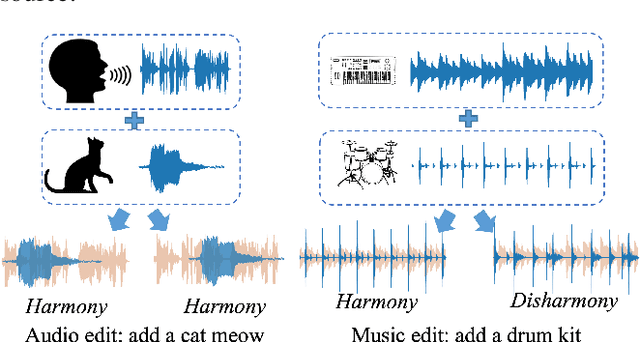
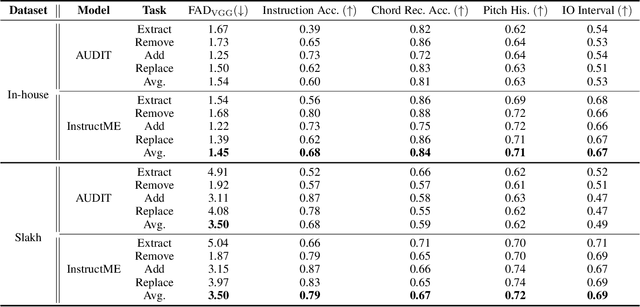
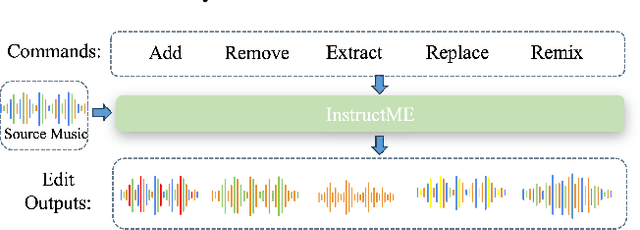
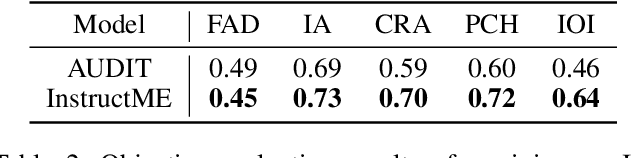
Music editing primarily entails the modification of instrument tracks or remixing in the whole, which offers a novel reinterpretation of the original piece through a series of operations. These music processing methods hold immense potential across various applications but demand substantial expertise. Prior methodologies, although effective for image and audio modifications, falter when directly applied to music. This is attributed to music's distinctive data nature, where such methods can inadvertently compromise the intrinsic harmony and coherence of music. In this paper, we develop InstructME, an Instruction guided Music Editing and remixing framework based on latent diffusion models. Our framework fortifies the U-Net with multi-scale aggregation in order to maintain consistency before and after editing. In addition, we introduce chord progression matrix as condition information and incorporate it in the semantic space to improve melodic harmony while editing. For accommodating extended musical pieces, InstructME employs a chunk transformer, enabling it to discern long-term temporal dependencies within music sequences. We tested InstructME in instrument-editing, remixing, and multi-round editing. Both subjective and objective evaluations indicate that our proposed method significantly surpasses preceding systems in music quality, text relevance and harmony. Demo samples are available at https://musicedit.github.io/
Hide and Seek (HaS): A Lightweight Framework for Prompt Privacy Protection
Sep 06, 2023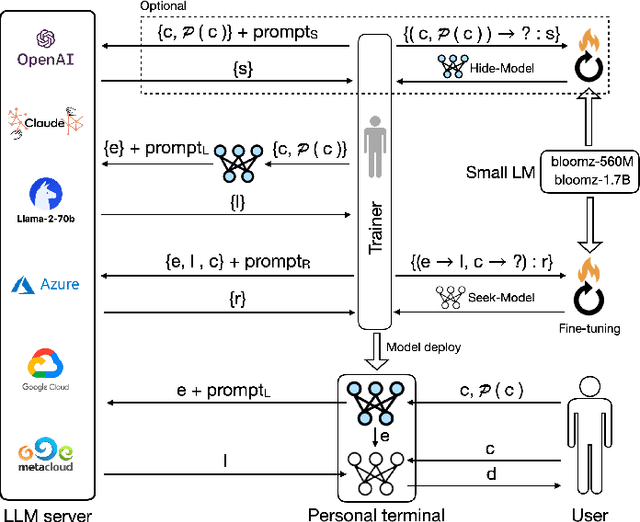

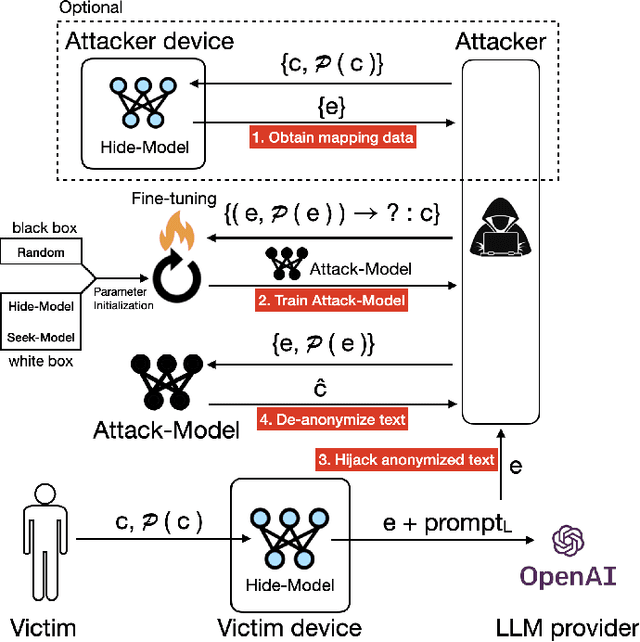

Numerous companies have started offering services based on large language models (LLM), such as ChatGPT, which inevitably raises privacy concerns as users' prompts are exposed to the model provider. Previous research on secure reasoning using multi-party computation (MPC) has proven to be impractical for LLM applications due to its time-consuming and communication-intensive nature. While lightweight anonymization techniques can protect private information in prompts through substitution or masking, they fail to recover sensitive data replaced in the LLM-generated results. In this paper, we expand the application scenarios of anonymization techniques by training a small local model to de-anonymize the LLM's returned results with minimal computational overhead. We introduce the HaS framework, where "H(ide)" and "S(eek)" represent its two core processes: hiding private entities for anonymization and seeking private entities for de-anonymization, respectively. To quantitatively assess HaS's privacy protection performance, we propose both black-box and white-box adversarial models. Furthermore, we conduct experiments to evaluate HaS's usability in translation and classification tasks. The experimental findings demonstrate that the HaS framework achieves an optimal balance between privacy protection and utility.
J-Guard: Journalism Guided Adversarially Robust Detection of AI-generated News
Sep 06, 2023
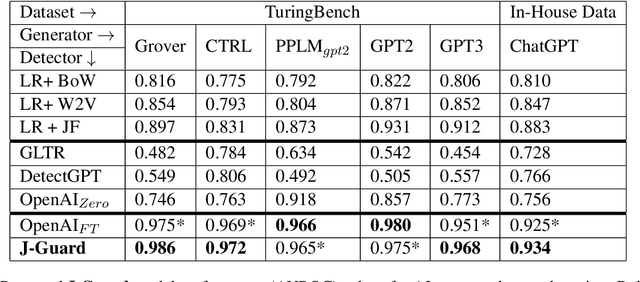
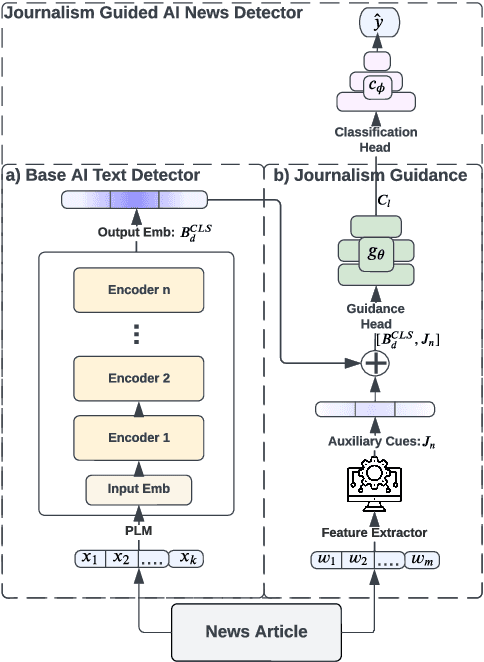
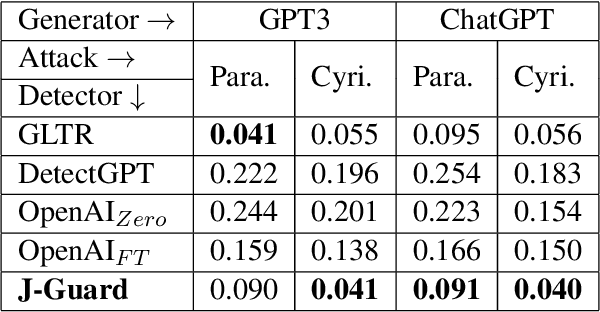
The rapid proliferation of AI-generated text online is profoundly reshaping the information landscape. Among various types of AI-generated text, AI-generated news presents a significant threat as it can be a prominent source of misinformation online. While several recent efforts have focused on detecting AI-generated text in general, these methods require enhanced reliability, given concerns about their vulnerability to simple adversarial attacks. Furthermore, due to the eccentricities of news writing, applying these detection methods for AI-generated news can produce false positives, potentially damaging the reputation of news organizations. To address these challenges, we leverage the expertise of an interdisciplinary team to develop a framework, J-Guard, capable of steering existing supervised AI text detectors for detecting AI-generated news while boosting adversarial robustness. By incorporating stylistic cues inspired by the unique journalistic attributes, J-Guard effectively distinguishes between real-world journalism and AI-generated news articles. Our experiments on news articles generated by a vast array of AI models, including ChatGPT (GPT3.5), demonstrate the effectiveness of J-Guard in enhancing detection capabilities while maintaining an average performance decrease of as low as 7% when faced with adversarial attacks.
A Multimodal Analysis of Influencer Content on Twitter
Sep 06, 2023
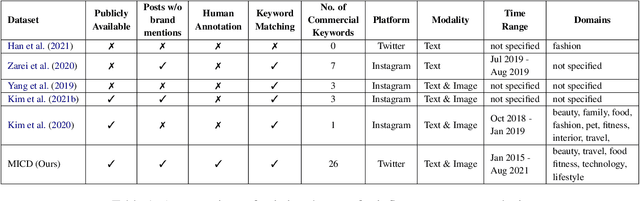
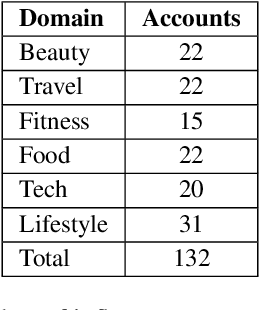

Influencer marketing involves a wide range of strategies in which brands collaborate with popular content creators (i.e., influencers) to leverage their reach, trust, and impact on their audience to promote and endorse products or services. Because followers of influencers are more likely to buy a product after receiving an authentic product endorsement rather than an explicit direct product promotion, the line between personal opinions and commercial content promotion is frequently blurred. This makes automatic detection of regulatory compliance breaches related to influencer advertising (e.g., misleading advertising or hidden sponsorships) particularly difficult. In this work, we (1) introduce a new Twitter (now X) dataset consisting of 15,998 influencer posts mapped into commercial and non-commercial categories for assisting in the automatic detection of commercial influencer content; (2) experiment with an extensive set of predictive models that combine text and visual information showing that our proposed cross-attention approach outperforms state-of-the-art multimodal models; and (3) conduct a thorough analysis of strengths and limitations of our models. We show that multimodal modeling is useful for identifying commercial posts, reducing the amount of false positives, and capturing relevant context that aids in the discovery of undisclosed commercial posts.
Real-time auralization for performers on virtual stages
Sep 06, 2023This article presents an interactive system for stage acoustics experimentation including considerations for hearing one's own and others' instruments. The quality of real-time auralization systems for psychophysical experiments on music performance depends on the system's calibration and latency, among other factors (e.g. visuals, simulation methods, haptics, etc). The presented system focuses on the acoustic considerations for laboratory implementations. The calibration is implemented as a set of filters accounting for the microphone-instrument distances and the directivity factors, as well as the transducers' frequency responses. Moreover, sources of errors are characterized using both state-of-the-art information and derivations from the mathematical definition of the calibration filter. In order to compensate for hardware latency without cropping parts of the simulated impulse responses, the virtual direct sound of musicians hearing themselves is skipped from the simulation and addressed by letting the actual direct sound reach the listener through open headphones. The required latency compensation of the interactive part (i.e. hearing others) meets the minimum distance requirement between musicians, which is 2 m for the implemented system. Finally, a proof of concept is provided that includes objective and subjective experiments, which give support to the feasibility of the proposed setup.
An Offline Learning Approach to Propagator Models
Sep 06, 2023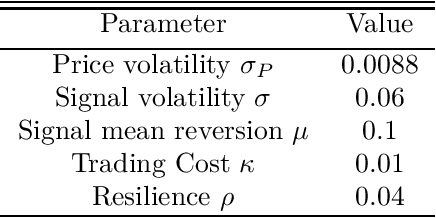

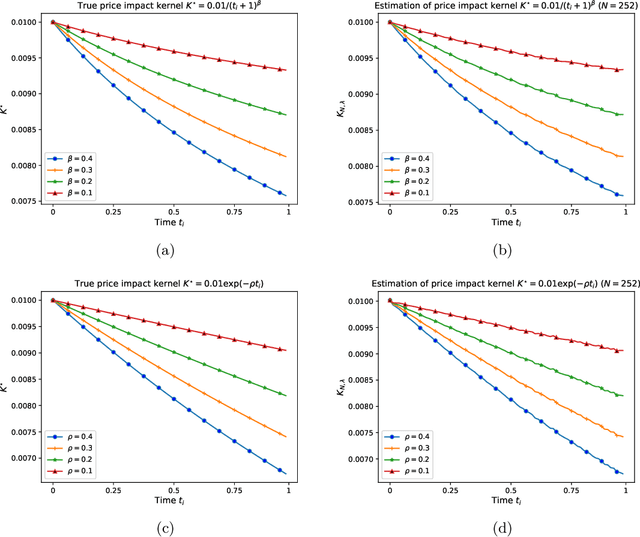
We consider an offline learning problem for an agent who first estimates an unknown price impact kernel from a static dataset, and then designs strategies to liquidate a risky asset while creating transient price impact. We propose a novel approach for a nonparametric estimation of the propagator from a dataset containing correlated price trajectories, trading signals and metaorders. We quantify the accuracy of the estimated propagator using a metric which depends explicitly on the dataset. We show that a trader who tries to minimise her execution costs by using a greedy strategy purely based on the estimated propagator will encounter suboptimality due to so-called spurious correlation between the trading strategy and the estimator and due to intrinsic uncertainty resulting from a biased cost functional. By adopting an offline reinforcement learning approach, we introduce a pessimistic loss functional taking the uncertainty of the estimated propagator into account, with an optimiser which eliminates the spurious correlation, and derive an asymptotically optimal bound on the execution costs even without precise information on the true propagator. Numerical experiments are included to demonstrate the effectiveness of the proposed propagator estimator and the pessimistic trading strategy.