 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Monotonicity of Information Aging
Mar 06, 2024
In this paper, we analyze the monotonicity of information aging in a remote estimation system, where historical observations of a Gaussian autoregressive AR(p) process are used to predict its future values. We consider two widely used loss functions in estimation: (i) logarithmic loss function for maximum likelihood estimation and (ii) quadratic loss function for MMSE estimation. The estimation error of the AR(p) process is written as a generalized conditional entropy which has closed-form expressions. By using a new information-theoretic tool called $\epsilon$-Markov chain, we can evaluate the divergence of the AR(p) process from being a Markov chain. When the divergence $\epsilon$ is large, the estimation error of the AR(p) process can be far from a non-decreasing function of the Age of Information (AoI). Conversely, for small divergence $\epsilon$, the inference error is close to a non-decreasing AoI function. Each observation is a short sequence taken from the AR(p) process. As the observation sequence length increases, the parameter $\epsilon$ progressively reduces to zero, and hence the estimation error becomes a non-decreasing AoI function. These results underscore a connection between the monotonicity of information aging and the divergence of from being a Markov chain.
FastPerson: Enhancing Video Learning through Effective Video Summarization that Preserves Linguistic and Visual Contexts
Mar 26, 2024Quickly understanding lengthy lecture videos is essential for learners with limited time and interest in various topics to improve their learning efficiency. To this end, video summarization has been actively researched to enable users to view only important scenes from a video. However, these studies focus on either the visual or audio information of a video and extract important segments in the video. Therefore, there is a risk of missing important information when both the teacher's speech and visual information on the blackboard or slides are important, such as in a lecture video. To tackle this issue, we propose FastPerson, a video summarization approach that considers both the visual and auditory information in lecture videos. FastPerson creates summary videos by utilizing audio transcriptions along with on-screen images and text, minimizing the risk of overlooking crucial information for learners. Further, it provides a feature that allows learners to switch between the summary and original videos for each chapter of the video, enabling them to adjust the pace of learning based on their interests and level of understanding. We conducted an evaluation with 40 participants to assess the effectiveness of our method and confirmed that it reduced viewing time by 53\% at the same level of comprehension as that when using traditional video playback methods.
Efficient Multi-branch Segmentation Network for Situation Awareness in Autonomous Navigation
Mar 30, 2024Real-time and high-precision situational awareness technology is critical for autonomous navigation of unmanned surface vehicles (USVs). In particular, robust and fast obstacle semantic segmentation methods are essential. However, distinguishing between the sea and the sky is challenging due to the differences between port and maritime environments. In this study, we built a dataset that captured perspectives from USVs and unmanned aerial vehicles in a maritime port environment and analysed the data features. Statistical analysis revealed a high correlation between the distribution of the sea and sky and row positional information. Based on this finding, a three-branch semantic segmentation network with a row position encoding module (RPEM) was proposed to improve the prediction accuracy between the sea and the sky. The proposed RPEM highlights the effect of row coordinates on feature extraction. Compared to the baseline, the three-branch network with RPEM significantly improved the ability to distinguish between the sea and the sky without significantly reducing the computational speed.
Weak-to-Strong 3D Object Detection with X-Ray Distillation
Mar 31, 2024This paper addresses the critical challenges of sparsity and occlusion in LiDAR-based 3D object detection. Current methods often rely on supplementary modules or specific architectural designs, potentially limiting their applicability to new and evolving architectures. To our knowledge, we are the first to propose a versatile technique that seamlessly integrates into any existing framework for 3D Object Detection, marking the first instance of Weak-to-Strong generalization in 3D computer vision. We introduce a novel framework, X-Ray Distillation with Object-Complete Frames, suitable for both supervised and semi-supervised settings, that leverages the temporal aspect of point cloud sequences. This method extracts crucial information from both previous and subsequent LiDAR frames, creating Object-Complete frames that represent objects from multiple viewpoints, thus addressing occlusion and sparsity. Given the limitation of not being able to generate Object-Complete frames during online inference, we utilize Knowledge Distillation within a Teacher-Student framework. This technique encourages the strong Student model to emulate the behavior of the weaker Teacher, which processes simple and informative Object-Complete frames, effectively offering a comprehensive view of objects as if seen through X-ray vision. Our proposed methods surpass state-of-the-art in semi-supervised learning by 1-1.5 mAP and enhance the performance of five established supervised models by 1-2 mAP on standard autonomous driving datasets, even with default hyperparameters. Code for Object-Complete frames is available here: https://github.com/sakharok13/X-Ray-Teacher-Patching-Tools.
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Mar 31, 2024Businesses and software platforms are increasingly turning to Large Language Models (LLMs) such as GPT-3.5, GPT-4, GLM-3, and LLaMa-2 for chat assistance with file access or as reasoning agents for customer service. However, current LLM-based customer service models have limited integration with customer profiles and lack the operational capabilities necessary for effective service. Moreover, existing API integrations emphasize diversity over the precision and error avoidance essential in real-world customer service scenarios. To address these issues, we propose an LLM agent named CHOPS (CHat with custOmer Profile in existing System), designed to: (1) efficiently utilize existing databases or systems for accessing user information or interacting with these systems following existing guidelines; (2) provide accurate and reasonable responses or carry out required operations in the system while avoiding harmful operations; and (3) leverage a combination of small and large LLMs to achieve satisfying performance at a reasonable inference cost. We introduce a practical dataset, the CPHOS-dataset, which includes a database, guiding files, and QA pairs collected from CPHOS, an online platform that facilitates the organization of simulated Physics Olympiads for high school teachers and students. We have conducted extensive experiments to validate the performance of our proposed CHOPS architecture using the CPHOS-dataset, with the aim of demonstrating how LLMs can enhance or serve as alternatives to human customer service. Our code and dataset will be open-sourced soon.
Decentralizing Coherent Joint Transmission Precoding via Fast ADMM with Deterministic Equivalents
Mar 28, 2024Inter-cell interference (ICI) suppression is critical for multi-cell multi-user networks. In this paper, we investigate advanced precoding techniques for coordinated multi-point (CoMP) with downlink coherent joint transmission, an effective approach for ICI suppression. Different from the centralized precoding schemes that require frequent information exchange among the cooperating base stations, we propose a decentralized scheme to minimize the total power consumption. In particular, based on the covariance matrices of global channel state information, we estimate the ICI bounds via the deterministic equivalents and decouple the original design problem into sub-problems, each of which can be solved in a decentralized manner. To solve the sub-problems at each base station, we develop a low-complexity solver based on the alternating direction method of multipliers (ADMM) in conjunction with the convex-concave procedure (CCCP). Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, which achieves performance similar to the optimal centralized precoding scheme. Besides, our proposed ADMM solver can substantially reduce the computational complexity, while maintaining outstanding performance.
Predicting Species Occurrence Patterns from Partial Observations
Mar 28, 2024To address the interlinked biodiversity and climate crises, we need an understanding of where species occur and how these patterns are changing. However, observational data on most species remains very limited, and the amount of data available varies greatly between taxonomic groups. We introduce the problem of predicting species occurrence patterns given (a) satellite imagery, and (b) known information on the occurrence of other species. To evaluate algorithms on this task, we introduce SatButterfly, a dataset of satellite images, environmental data and observational data for butterflies, which is designed to pair with the existing SatBird dataset of bird observational data. To address this task, we propose a general model, R-Tran, for predicting species occurrence patterns that enables the use of partial observational data wherever found. We find that R-Tran outperforms other methods in predicting species encounter rates with partial information both within a taxon (birds) and across taxa (birds and butterflies). Our approach opens new perspectives to leveraging insights from species with abundant data to other species with scarce data, by modelling the ecosystems in which they co-occur.
All-in-One: Heterogeneous Interaction Modeling for Cold-Start Rating Prediction
Mar 28, 2024Cold-start rating prediction is a fundamental problem in recommender systems that has been extensively studied. Many methods have been proposed that exploit explicit relations among existing data, such as collaborative filtering, social recommendations and heterogeneous information network, to alleviate the data insufficiency issue for cold-start users and items. However, the explicit relations constructed based on data between different roles may be unreliable and irrelevant, which limits the performance ceiling of the specific recommendation task. Motivated by this, in this paper, we propose a flexible framework dubbed heterogeneous interaction rating network (HIRE). HIRE dose not solely rely on the pre-defined interaction pattern or the manually constructed heterogeneous information network. Instead, we devise a Heterogeneous Interaction Module (HIM) to jointly model the heterogeneous interactions and directly infer the important interactions via the observed data. In the experiments, we evaluate our model under three cold-start settings on three real-world datasets. The experimental results show that HIRE outperforms other baselines by a large margin. Furthermore, we visualize the inferred interactions of HIRE to confirm the contribution of our model.
SAID-NeRF: Segmentation-AIDed NeRF for Depth Completion of Transparent Objects
Mar 28, 2024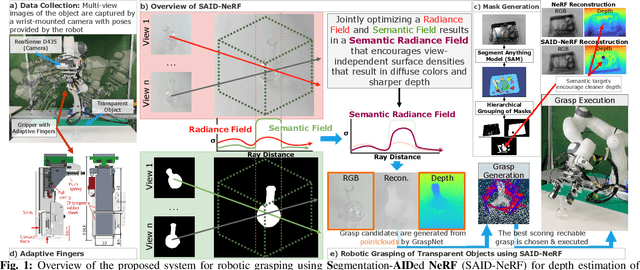
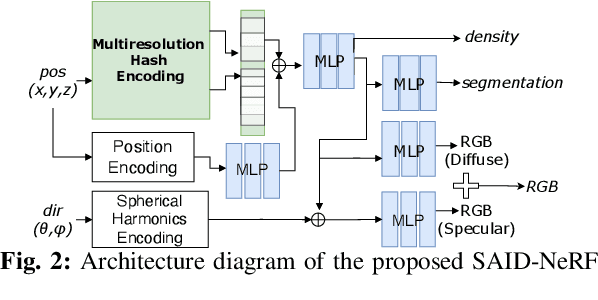


Acquiring accurate depth information of transparent objects using off-the-shelf RGB-D cameras is a well-known challenge in Computer Vision and Robotics. Depth estimation/completion methods are typically employed and trained on datasets with quality depth labels acquired from either simulation, additional sensors or specialized data collection setups and known 3d models. However, acquiring reliable depth information for datasets at scale is not straightforward, limiting training scalability and generalization. Neural Radiance Fields (NeRFs) are learning-free approaches and have demonstrated wide success in novel view synthesis and shape recovery. However, heuristics and controlled environments (lights, backgrounds, etc) are often required to accurately capture specular surfaces. In this paper, we propose using Visual Foundation Models (VFMs) for segmentation in a zero-shot, label-free way to guide the NeRF reconstruction process for these objects via the simultaneous reconstruction of semantic fields and extensions to increase robustness. Our proposed method Segmentation-AIDed NeRF (SAID-NeRF) shows significant performance on depth completion datasets for transparent objects and robotic grasping.
Retrieval-Enhanced Knowledge Editing for Multi-Hop Question Answering in Language Models
Mar 28, 2024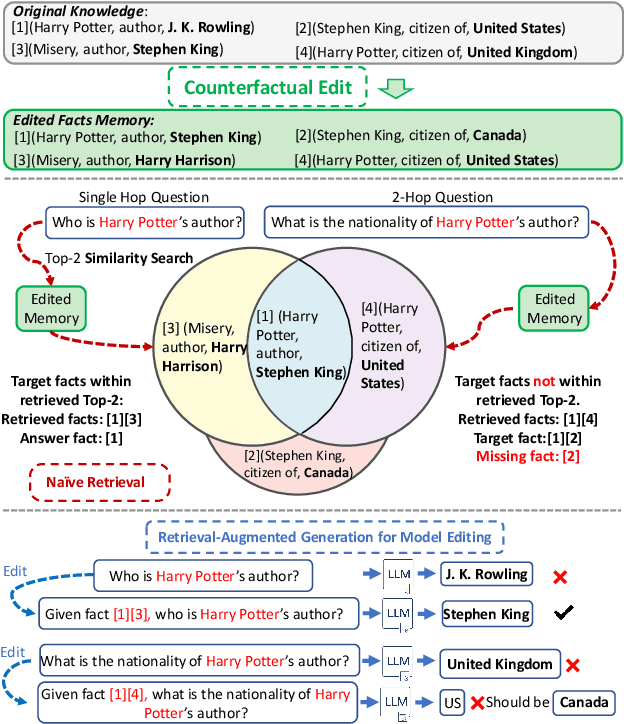

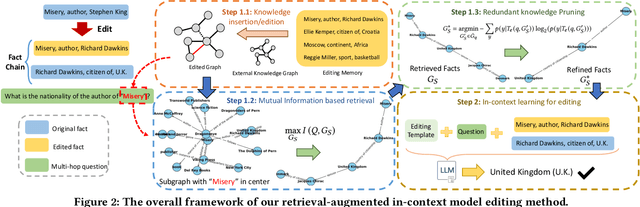
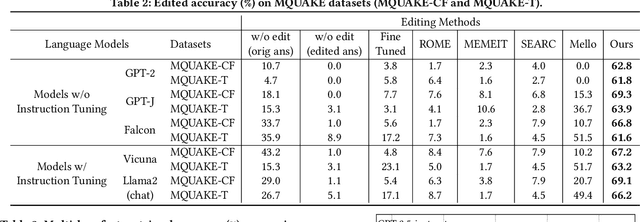
Large Language Models (LLMs) have shown proficiency in question-answering tasks but often struggle to integrate real-time knowledge updates, leading to potentially outdated or inaccurate responses. This problem becomes even more challenging when dealing with multi-hop questions since they require LLMs to update and integrate multiple knowledge pieces relevant to the questions. To tackle the problem, we propose the Retrieval-Augmented model Editing (RAE) framework tailored for multi-hop question answering. RAE first retrieves edited facts and then refines the language model through in-context learning. Specifically, our retrieval approach, based on mutual information maximization, leverages the reasoning abilities of LLMs to identify chain facts that na\"ive similarity-based searches might miss. Additionally, our framework incorporates a pruning strategy to eliminate redundant information from the retrieved facts, which enhances the editing accuracy and mitigates the hallucination problem. Our framework is supported by theoretical justification for its fact retrieval efficacy. Finally, comprehensive evaluation across various LLMs validates RAE's ability in providing accurate answers with updated knowledge.