 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Higher or Lower: Challenges in Object based SLAM
Oct 20, 2023

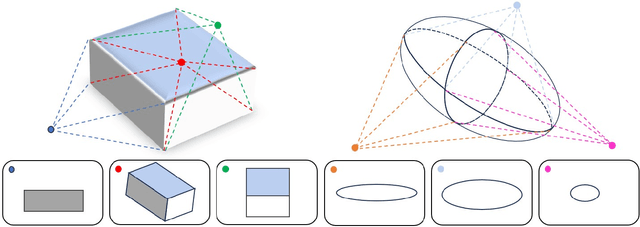
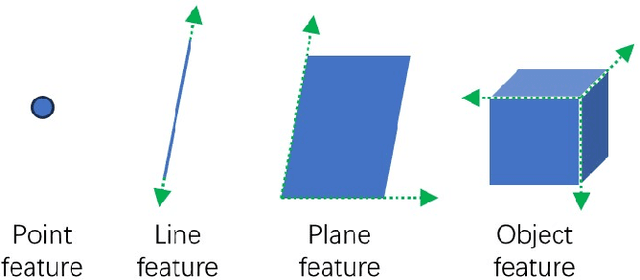

Simultaneous localization and mapping, as a fundamental task in computer vision, has gained higher demands for performance in recent years due to the rapid development of autonomous driving and unmanned aerial vehicles. Traditional SLAM algorithms highly rely on basic geometry features such as points and lines, which are susceptible to environment. Conversely, higher-level object features offer richer information that is crucial for enhancing the overall performance of the framework. However, the effective utilization of object features necessitates careful consideration of various challenges, including complexity and process velocity. Given the advantages and disadvantages of both high-level object feature and low-level geometry features, it becomes essential to make informed choices within the SLAM framework. Taking these factors into account, this paper provides a thorough comparison between geometry features and object features, analyzes the current mainstream application methods of object features in SLAM frameworks, and presents a comprehensive overview of the main challenges involved in object-based SLAM.
Graph AI in Medicine
Oct 20, 2023
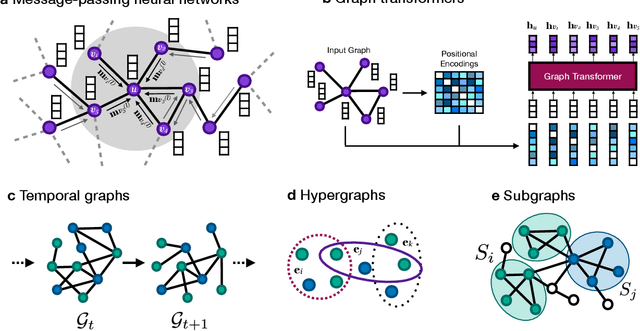
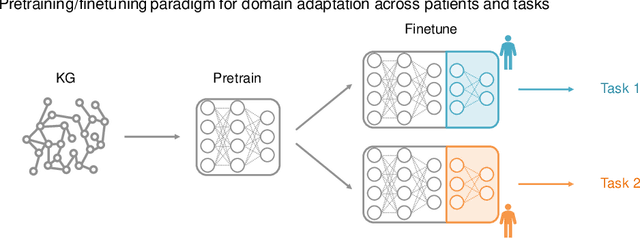
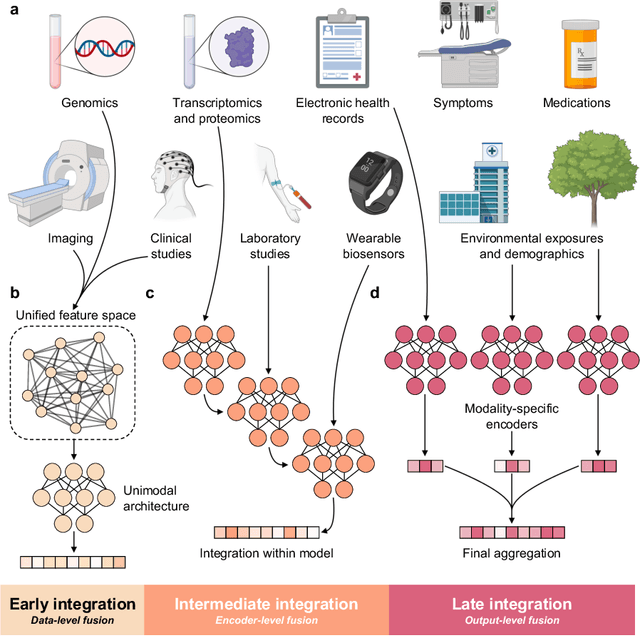
In clinical artificial intelligence (AI), graph representation learning, mainly through graph neural networks (GNNs), stands out for its capability to capture intricate relationships within structured clinical datasets. With diverse data -- from patient records to imaging -- GNNs process data holistically by viewing modalities as nodes interconnected by their relationships. Graph AI facilitates model transfer across clinical tasks, enabling models to generalize across patient populations without additional parameters or minimal re-training. However, the importance of human-centered design and model interpretability in clinical decision-making cannot be overstated. Since graph AI models capture information through localized neural transformations defined on graph relationships, they offer both an opportunity and a challenge in elucidating model rationale. Knowledge graphs can enhance interpretability by aligning model-driven insights with medical knowledge. Emerging graph models integrate diverse data modalities through pre-training, facilitate interactive feedback loops, and foster human-AI collaboration, paving the way to clinically meaningful predictions.
A Simple Baseline for Knowledge-Based Visual Question Answering
Oct 20, 2023This paper is on the problem of Knowledge-Based Visual Question Answering (KB-VQA). Recent works have emphasized the significance of incorporating both explicit (through external databases) and implicit (through LLMs) knowledge to answer questions requiring external knowledge effectively. A common limitation of such approaches is that they consist of relatively complicated pipelines and often heavily rely on accessing GPT-3 API. Our main contribution in this paper is to propose a much simpler and readily reproducible pipeline which, in a nutshell, is based on efficient in-context learning by prompting LLaMA (1 and 2) using question-informative captions as contextual information. Contrary to recent approaches, our method is training-free, does not require access to external databases or APIs, and yet achieves state-of-the-art accuracy on the OK-VQA and A-OK-VQA datasets. Finally, we perform several ablation studies to understand important aspects of our method. Our code is publicly available at https://github.com/alexandrosXe/ASimple-Baseline-For-Knowledge-Based-VQA
Positive-Unlabeled Node Classification with Structure-aware Graph Learning
Oct 20, 2023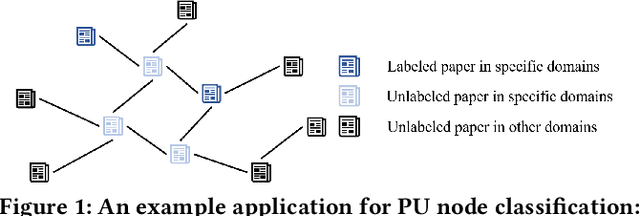
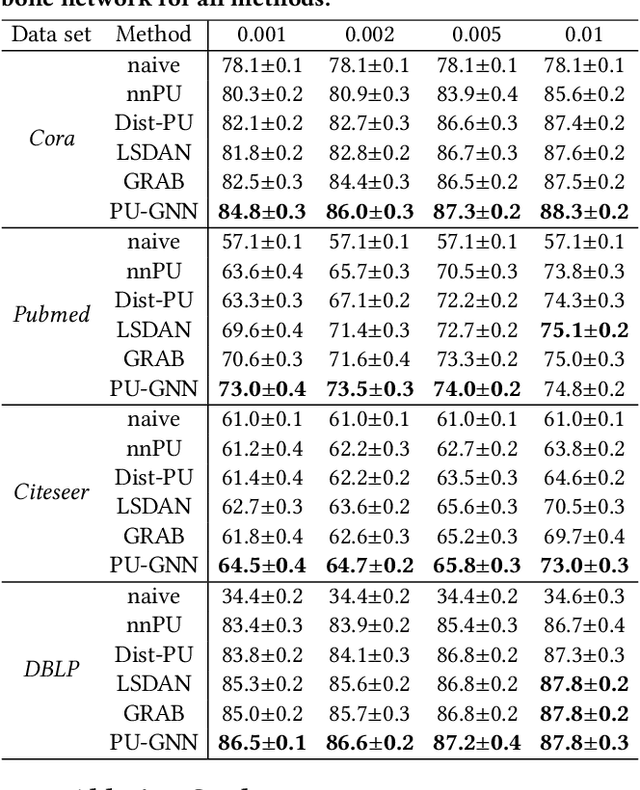
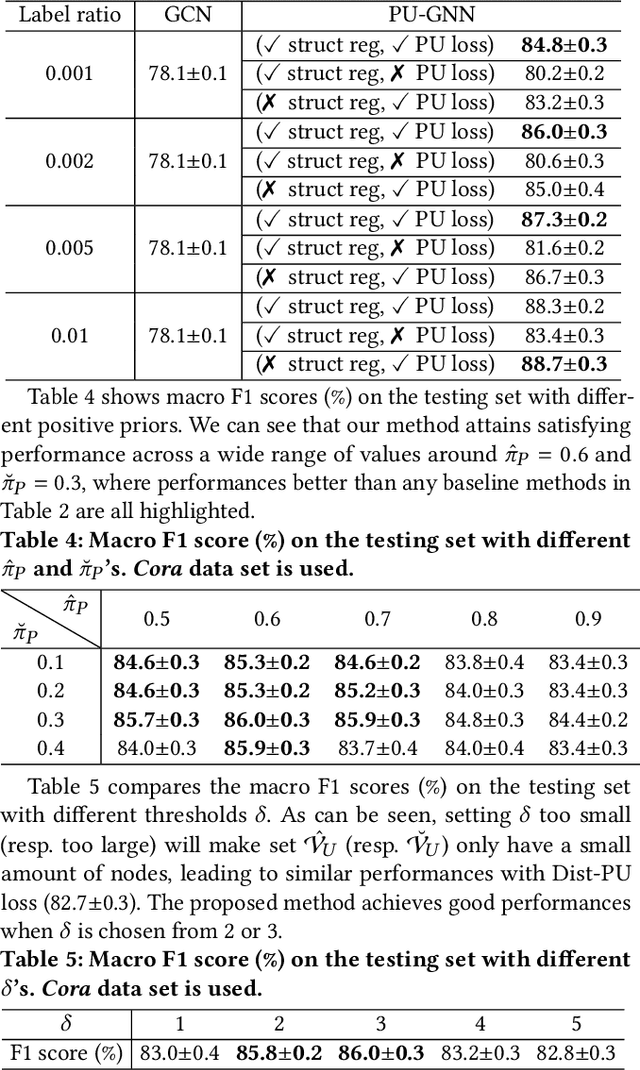
Node classification on graphs is an important research problem with many applications. Real-world graph data sets may not be balanced and accurate as assumed by most existing works. A challenging setting is positive-unlabeled (PU) node classification, where labeled nodes are restricted to positive nodes. It has diverse applications, e.g., pandemic prediction or network anomaly detection. Existing works on PU node classification overlook information in the graph structure, which can be critical. In this paper, we propose to better utilize graph structure for PU node classification. We first propose a distance-aware PU loss that uses homophily in graphs to introduce more accurate supervision. We also propose a regularizer to align the model with graph structure. Theoretical analysis shows that minimizing the proposed loss also leads to minimizing the expected loss with both positive and negative labels. Extensive empirical evaluation on diverse graph data sets demonstrates its superior performance over existing state-of-the-art methods.
MoqaGPT : Zero-Shot Multi-modal Open-domain Question Answering with Large Language Model
Oct 20, 2023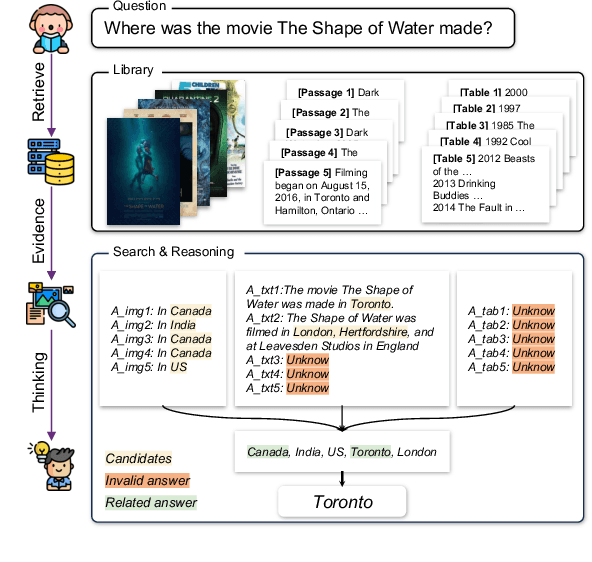

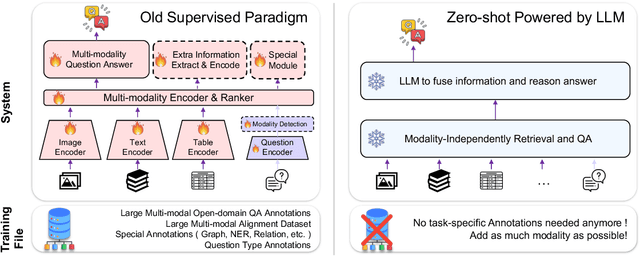
Multi-modal open-domain question answering typically requires evidence retrieval from databases across diverse modalities, such as images, tables, passages, etc. Even Large Language Models (LLMs) like GPT-4 fall short in this task. To enable LLMs to tackle the task in a zero-shot manner, we introduce MoqaGPT, a straightforward and flexible framework. Using a divide-and-conquer strategy that bypasses intricate multi-modality ranking, our framework can accommodate new modalities and seamlessly transition to new models for the task. Built upon LLMs, MoqaGPT retrieves and extracts answers from each modality separately, then fuses this multi-modal information using LLMs to produce a final answer. Our methodology boosts performance on the MMCoQA dataset, improving F1 by +37.91 points and EM by +34.07 points over the supervised baseline. On the MultiModalQA dataset, MoqaGPT surpasses the zero-shot baseline, improving F1 by 9.5 points and EM by 10.1 points, and significantly closes the gap with supervised methods. Our codebase is available at https://github.com/lezhang7/MOQAGPT.
Deep-Learning-based Change Detection with Spaceborne Hyperspectral PRISMA data
Oct 20, 2023Change detection (CD) methods have been applied to optical data for decades, while the use of hyperspectral data with a fine spectral resolution has been rarely explored. CD is applied in several sectors, such as environmental monitoring and disaster management. Thanks to the PRecursore IperSpettrale della Missione operativA (PRISMA), hyperspectral-from-space CD is now possible. In this work, we apply standard and deep-learning (DL) CD methods to different targets, from natural to urban areas. We propose a pipeline starting from coregistration, followed by CD with a full-spectrum algorithm and by a DL network developed for optical data. We find that changes in vegetation and built environments are well captured. The spectral information is valuable to identify subtle changes and the DL methods are less affected by noise compared to the statistical method, but atmospheric effects and the lack of reliable ground truth represent a major challenge to hyperspectral CD.
Electrical Fault Localisation Over a Distributed Parameter Transmission Line
Oct 20, 2023Motivated by the need to localise faults along electrical power lines, this paper adopts a frequency-domain approach to parameter estimation for an infinite-dimensional linear dynamical system with one spatial variable. Since the time of the fault is unknown, and voltages and currents are measured at only one end of the line, distance information must be extracted from the post-fault transients. To properly account for high-frequency transient behaviour, the line dynamics is modelled directly by the Telegrapher's equation, rather than the more commonly used lumped-parameter approximations. First, the governing equations are non-dimensionalised to avoid ill-conditioning. A closed-form expression for the transfer function is then derived. Finally, nonlinear least-squares optimisation is employed to search for the fault location. Requirements on fault bandwidth, sensor bandwidth and simulation time-step are also presented. The result is a novel end-to-end algorithm for data generation and fault localisation, the effectiveness of which is demonstrated via simulation.
Conditional Density Estimations from Privacy-Protected Data
Oct 20, 2023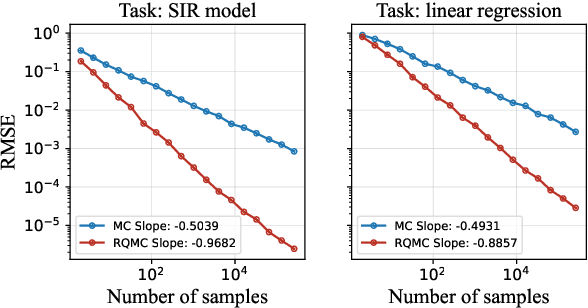
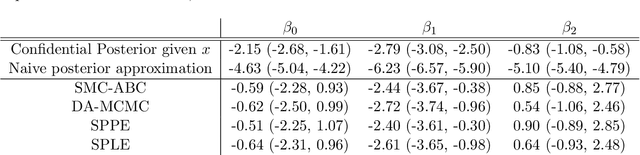
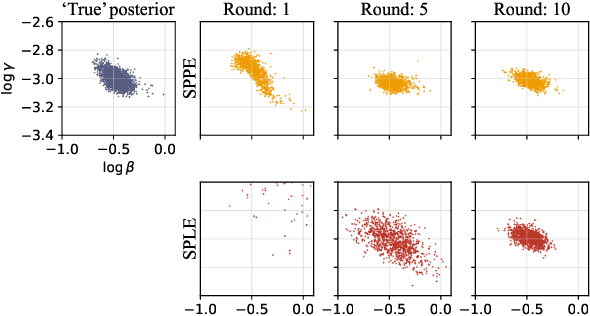
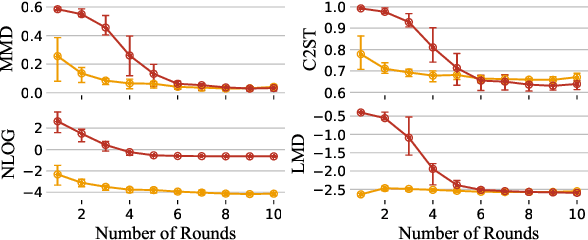
Many modern statistical analysis and machine learning applications require training models on sensitive user data. Differential privacy provides a formal guarantee that individual-level information about users does not leak. In this framework, randomized algorithms inject calibrated noise into the confidential data, resulting in privacy-protected datasets or queries. However, restricting access to only the privatized data during statistical analysis makes it computationally challenging to perform valid inferences on parameters underlying the confidential data. In this work, we propose simulation-based inference methods from privacy-protected datasets. Specifically, we use neural conditional density estimators as a flexible family of distributions to approximate the posterior distribution of model parameters given the observed private query results. We illustrate our methods on discrete time-series data under an infectious disease model and on ordinary linear regression models. Illustrating the privacy-utility trade-off, our experiments and analysis demonstrate the necessity and feasibility of designing valid statistical inference procedures to correct for biases introduced by the privacy-protection mechanisms.
Graph Convolutional Network with Connectivity Uncertainty for EEG-based Emotion Recognition
Oct 22, 2023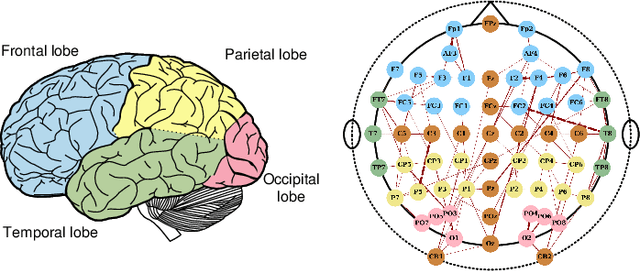
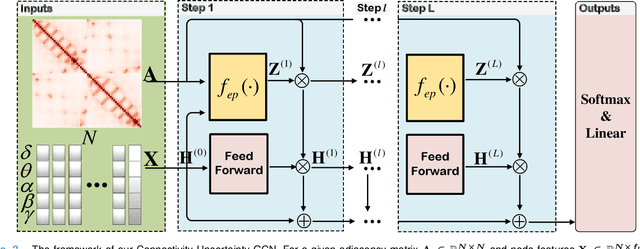
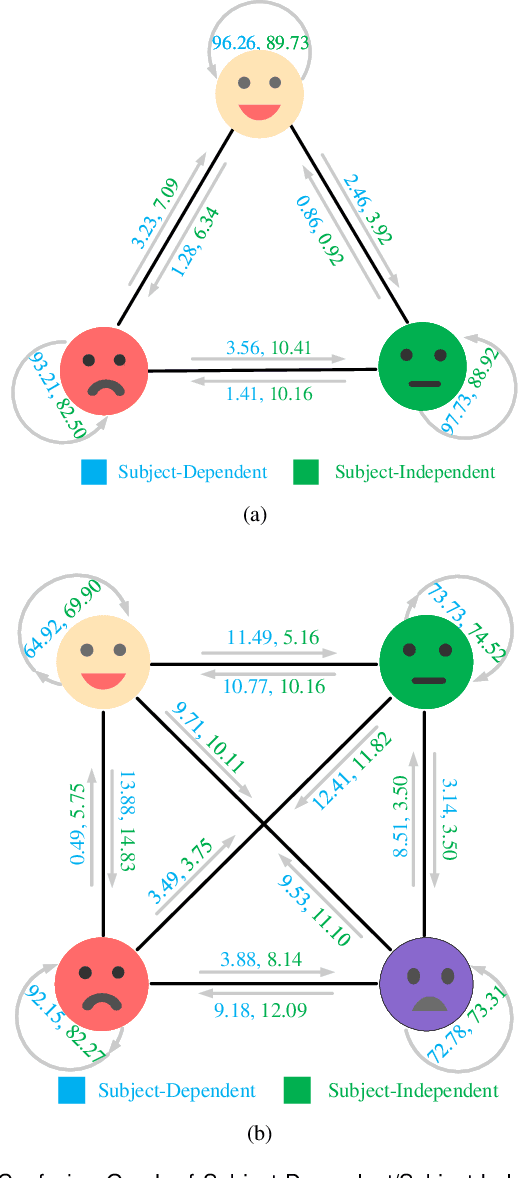
Automatic emotion recognition based on multichannel Electroencephalography (EEG) holds great potential in advancing human-computer interaction. However, several significant challenges persist in existing research on algorithmic emotion recognition. These challenges include the need for a robust model to effectively learn discriminative node attributes over long paths, the exploration of ambiguous topological information in EEG channels and effective frequency bands, and the mapping between intrinsic data qualities and provided labels. To address these challenges, this study introduces the distribution-based uncertainty method to represent spatial dependencies and temporal-spectral relativeness in EEG signals based on Graph Convolutional Network (GCN) architecture that adaptively assigns weights to functional aggregate node features, enabling effective long-path capturing while mitigating over-smoothing phenomena. Moreover, the graph mixup technique is employed to enhance latent connected edges and mitigate noisy label issues. Furthermore, we integrate the uncertainty learning method with deep GCN weights in a one-way learning fashion, termed Connectivity Uncertainty GCN (CU-GCN). We evaluate our approach on two widely used datasets, namely SEED and SEEDIV, for emotion recognition tasks. The experimental results demonstrate the superiority of our methodology over previous methods, yielding positive and significant improvements. Ablation studies confirm the substantial contributions of each component to the overall performance.
ConViViT -- A Deep Neural Network Combining Convolutions and Factorized Self-Attention for Human Activity Recognition
Oct 22, 2023The Transformer architecture has gained significant popularity in computer vision tasks due to its capacity to generalize and capture long-range dependencies. This characteristic makes it well-suited for generating spatiotemporal tokens from videos. On the other hand, convolutions serve as the fundamental backbone for processing images and videos, as they efficiently aggregate information within small local neighborhoods to create spatial tokens that describe the spatial dimension of a video. While both CNN-based architectures and pure transformer architectures are extensively studied and utilized by researchers, the effective combination of these two backbones has not received comparable attention in the field of activity recognition. In this research, we propose a novel approach that leverages the strengths of both CNNs and Transformers in an hybrid architecture for performing activity recognition using RGB videos. Specifically, we suggest employing a CNN network to enhance the video representation by generating a 128-channel video that effectively separates the human performing the activity from the background. Subsequently, the output of the CNN module is fed into a transformer to extract spatiotemporal tokens, which are then used for classification purposes. Our architecture has achieved new SOTA results with 90.05 \%, 99.6\%, and 95.09\% on HMDB51, UCF101, and ETRI-Activity3D respectively.