 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clinical information extraction for Low-resource languages with Few-shot learning using Pre-trained language models and Prompting
Mar 20, 2024
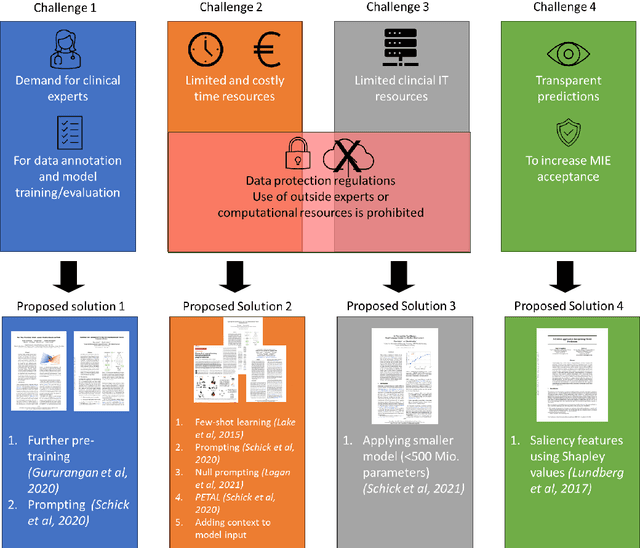
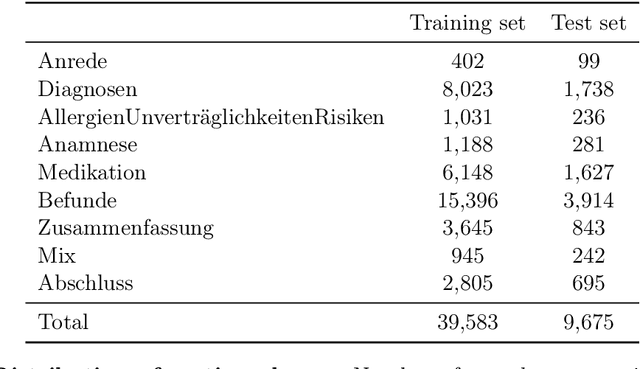
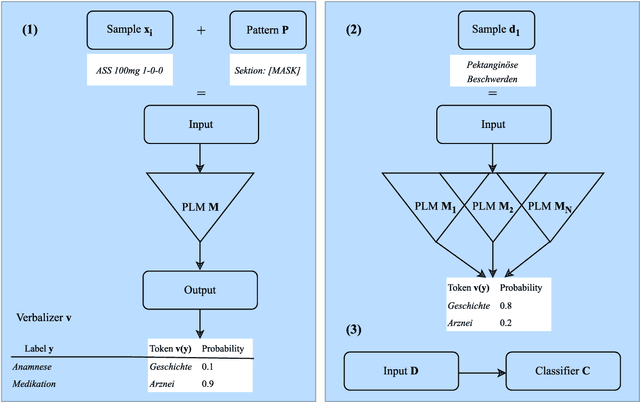

Automatic extraction of medical information from clinical documents poses several challenges: high costs of required clinical expertise, limited interpretability of model predictions, restricted computational resources and privacy regulations. Recent advances in domain-adaptation and prompting methods showed promising results with minimal training data using lightweight masked language models, which are suited for well-established interpretability methods. We are first to present a systematic evaluation of these methods in a low-resource setting, by performing multi-class section classification on German doctor's letters. We conduct extensive class-wise evaluations supported by Shapley values, to validate the quality of our small training data set and to ensure the interpretability of model predictions. We demonstrate that a lightweight, domain-adapted pretrained model, prompted with just 20 shots, outperforms a traditional classification model by 30.5% accuracy. Our results serve as a process-oriented guideline for clinical information extraction projects working with low-resource.
Computationally Efficient Unsupervised Deep Learning for Robust Joint AP Clustering and Beamforming Design in Cell-Free Systems
Apr 03, 2024In this paper, we consider robust joint access point (AP) clustering and beamforming design with imperfect channel state information (CSI) in cell-free systems. Specifically, we jointly optimize AP clustering and beamforming with imperfect CSI to simultaneously maximize the worst-case sum rate and minimize the number of AP clustering under power constraint and the sparsity constraint of AP clustering. By transformations, the semi-infinite constraints caused by the imperfect CSI are converted into more tractable forms for facilitating a computationally efficient unsupervised deep learning algorithm. In addition, to further reduce the computational complexity, a computationally effective unsupervised deep learning algorithm is proposed to implement robust joint AP clustering and beamforming design with imperfect CSI in cell-free systems. Numerical results demonstrate that the proposed unsupervised deep learning algorithm achieves a higher worst-case sum rate under a smaller number of AP clustering with computational efficiency.
Collapse of Self-trained Language Models
Apr 02, 2024In various fields of knowledge creation, including science, new ideas often build on pre-existing information. In this work, we explore this concept within the context of language models. Specifically, we explore the potential of self-training models on their own outputs, akin to how humans learn and build on their previous thoughts and actions. While this approach is intuitively appealing, our research reveals its practical limitations. We find that extended self-training of the GPT-2 model leads to a significant degradation in performance, resulting in repetitive and collapsed token output.
MonoCD: Monocular 3D Object Detection with Complementary Depths
Apr 04, 2024Monocular 3D object detection has attracted widespread attention due to its potential to accurately obtain object 3D localization from a single image at a low cost. Depth estimation is an essential but challenging subtask of monocular 3D object detection due to the ill-posedness of 2D to 3D mapping. Many methods explore multiple local depth clues such as object heights and keypoints and then formulate the object depth estimation as an ensemble of multiple depth predictions to mitigate the insufficiency of single-depth information. However, the errors of existing multiple depths tend to have the same sign, which hinders them from neutralizing each other and limits the overall accuracy of combined depth. To alleviate this problem, we propose to increase the complementarity of depths with two novel designs. First, we add a new depth prediction branch named complementary depth that utilizes global and efficient depth clues from the entire image rather than the local clues to reduce the correlation of depth predictions. Second, we propose to fully exploit the geometric relations between multiple depth clues to achieve complementarity in form. Benefiting from these designs, our method achieves higher complementarity. Experiments on the KITTI benchmark demonstrate that our method achieves state-of-the-art performance without introducing extra data. In addition, complementary depth can also be a lightweight and plug-and-play module to boost multiple existing monocular 3d object detectors. Code is available at https://github.com/elvintanhust/MonoCD.
Roadside Monocular 3D Detection via 2D Detection Prompting
Apr 04, 2024The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
MPOFI: Multichannel Partially Observed Functional Modeling for Defect Classification with Imbalanced Dataset via Deep Metric Learning
Apr 04, 2024In modern manufacturing, most of the product lines are conforming. Few products are nonconforming but with different defect types. The identification of defect types can help further root cause diagnosis of production lines. With the sensing development, continuous signals of process variables can be collected in high resolution, which can be regarded as multichannel functional data. They have abundant information to characterize the process and help identify the defect types. Motivated by a real example from the pipe tightening process, we target at detect classification when each sample is a multichannel functional data. However, the available samples for each defect type are limited and imbalanced. Moreover, the functions are partially observed since the pre-tightening process before the pipe tightening process is unobserved. To classify the defect samples based on imbalanced, multichannel, and partially observed functional data is very important but challenging. Thus, we propose an innovative framework known as "Multichannel Partially Observed Functional Modeling for Defect Classification with an Imbalanced Dataset" (MPOFI). The framework leverages the power of deep metric learning in conjunction with a neural network specially crafted for processing functional data. This paper introduces a neural network explicitly tailored for handling multichannel and partially observed functional data, complemented by developing a corresponding loss function for training on imbalanced datasets. The results from a real-world case study demonstrate the superior accuracy of our framework when compared to existing benchmarks.
A School Student Essay Corpus for Analyzing Interactions of Argumentative Structure and Quality
Apr 03, 2024Learning argumentative writing is challenging. Besides writing fundamentals such as syntax and grammar, learners must select and arrange argument components meaningfully to create high-quality essays. To support argumentative writing computationally, one step is to mine the argumentative structure. When combined with automatic essay scoring, interactions of the argumentative structure and quality scores can be exploited for comprehensive writing support. Although studies have shown the usefulness of using information about the argumentative structure for essay scoring, no argument mining corpus with ground-truth essay quality annotations has been published yet. Moreover, none of the existing corpora contain essays written by school students specifically. To fill this research gap, we present a German corpus of 1,320 essays from school students of two age groups. Each essay has been manually annotated for argumentative structure and quality on multiple levels of granularity. We propose baseline approaches to argument mining and essay scoring, and we analyze interactions between both tasks, thereby laying the ground for quality-oriented argumentative writing support.
Similar Data Points Identification with LLM: A Human-in-the-loop Strategy Using Summarization and Hidden State Insights
Apr 03, 2024This study introduces a simple yet effective method for identifying similar data points across non-free text domains, such as tabular and image data, using Large Language Models (LLMs). Our two-step approach involves data point summarization and hidden state extraction. Initially, data is condensed via summarization using an LLM, reducing complexity and highlighting essential information in sentences. Subsequently, the summarization sentences are fed through another LLM to extract hidden states, serving as compact, feature-rich representations. This approach leverages the advanced comprehension and generative capabilities of LLMs, offering a scalable and efficient strategy for similarity identification across diverse datasets. We demonstrate the effectiveness of our method in identifying similar data points on multiple datasets. Additionally, our approach enables non-technical domain experts, such as fraud investigators or marketing operators, to quickly identify similar data points tailored to specific scenarios, demonstrating its utility in practical applications. In general, our results open new avenues for leveraging LLMs in data analysis across various domains.
BCAmirs at SemEval-2024 Task 4: Beyond Words: A Multimodal and Multilingual Exploration of Persuasion in Memes
Apr 03, 2024Memes, combining text and images, frequently use metaphors to convey persuasive messages, shaping public opinion. Motivated by this, our team engaged in SemEval-2024 Task 4, a hierarchical multi-label classification task designed to identify rhetorical and psychological persuasion techniques embedded within memes. To tackle this problem, we introduced a caption generation step to assess the modality gap and the impact of additional semantic information from images, which improved our result. Our best model utilizes GPT-4 generated captions alongside meme text to fine-tune RoBERTa as the text encoder and CLIP as the image encoder. It outperforms the baseline by a large margin in all 12 subtasks. In particular, it ranked in top-3 across all languages in Subtask 2a, and top-4 in Subtask 2b, demonstrating quantitatively strong performance. The improvement achieved by the introduced intermediate step is likely attributable to the metaphorical essence of images that challenges visual encoders. This highlights the potential for improving abstract visual semantics encoding.
Toward Safe Evolution of Artificial Intelligence (AI) based Conversational Agents to Support Adolescent Mental and Sexual Health Knowledge Discovery
Apr 03, 2024Following the recent release of various Artificial Intelligence (AI) based Conversation Agents (CAs), adolescents are increasingly using CAs for interactive knowledge discovery on sensitive topics, including mental and sexual health topics. Exploring such sensitive topics through online search has been an essential part of adolescent development, and CAs can support their knowledge discovery on such topics through human-like dialogues. Yet, unintended risks have been documented with adolescents' interactions with AI-based CAs, such as being exposed to inappropriate content, false information, and/or being given advice that is detrimental to their mental and physical well-being (e.g., to self-harm). In this position paper, we discuss the current landscape and opportunities for CAs to support adolescents' mental and sexual health knowledge discovery. We also discuss some of the challenges related to ensuring the safety of adolescents when interacting with CAs regarding sexual and mental health topics. We call for a discourse on how to set guardrails for the safe evolution of AI-based CAs for adolescents.