 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Free Optimization-Empowered Wireless Channel Reconfiguration for 6G
Jul 03, 2025Reconfigurable antennas, including reconfigurable intelligent surface (RIS), movable antenna (MA), fluid antenna (FA), and other advanced antenna techniques, have been studied extensively in the context of reshaping wireless propagation environments for 6G and beyond wireless communications. Nevertheless, how to reconfigure/optimize the real-time controllable coefficients to achieve a favorable end-to-end wireless channel remains a substantial challenge, as it usually requires accurate modeling of the complex interaction between the reconfigurable devices and the electromagnetic waves, as well as knowledge of implicit channel propagation parameters. In this paper, we introduce a derivative-free optimization (a.k.a., zeroth-order (ZO) optimization) technique to directly optimize reconfigurable coefficients to shape the wireless end-to-end channel, without the need of channel modeling and estimation of the implicit environmental propagation parameters. We present the fundamental principles of ZO optimization and discuss its potential advantages in wireless channel reconfiguration. Two case studies for RIS and movable antenna-enabled single-input single-output (SISO) systems are provided to show the superiority of ZO-based methods as compared to state-of-the-art techniques. Finally, we outline promising future research directions and offer concluding insights on derivative-free optimization for reconfigurable antenna technologies.
A Derivative-Free Position Optimization Approach for Movable Antenna Multi-User Communication Systems
May 25, 2025



Movable antennas (MAs) have emerged as a disruptive technology in wireless communications for enhancing spatial degrees of freedom through continuous antenna repositioning within predefined regions, thereby creating favorable channel propagation conditions. In this paper, we study the problem of position optimization for MA-enabled multi-user MISO systems, where a base station (BS), equipped with multiple MAs, communicates with multiple users each equipped with a single fixed-position antenna (FPA). To circumvent the difficulty of acquiring the channel state information (CSI) from the transmitter to the receiver over the entire movable region, we propose a derivative-free approach for MA position optimization. The basic idea is to treat position optimization as a closed-box optimization problem and calculate the gradient of the unknown objective function using zeroth-order (ZO) gradient approximation techniques. Specifically, the proposed method does not need to explicitly estimate the global CSI. Instead, it adaptively refines its next movement based on previous measurements such that it eventually converges to an optimum or stationary solution. Simulation results show that the proposed derivative-free approach is able to achieve higher sample and computational efficiencies than the CSI estimation-based position optimization approach, particularly for challenging scenarios where the number of multi-path components (MPCs) is large or the number of pilot signals is limited.
CARE: Compatibility-Aware Incentive Mechanisms for Federated Learning with Budgeted Requesters
Apr 22, 2025Federated learning (FL) is a promising approach that allows requesters (\eg, servers) to obtain local training models from workers (e.g., clients). Since workers are typically unwilling to provide training services/models freely and voluntarily, many incentive mechanisms in FL are designed to incentivize participation by offering monetary rewards from requesters. However, existing studies neglect two crucial aspects of real-world FL scenarios. First, workers can possess inherent incompatibility characteristics (e.g., communication channels and data sources), which can lead to degradation of FL efficiency (e.g., low communication efficiency and poor model generalization). Second, the requesters are budgeted, which limits the amount of workers they can hire for their tasks. In this paper, we investigate the scenario in FL where multiple budgeted requesters seek training services from incompatible workers with private training costs. We consider two settings: the cooperative budget setting where requesters cooperate to pool their budgets to improve their overall utility and the non-cooperative budget setting where each requester optimizes their utility within their own budgets. To address efficiency degradation caused by worker incompatibility, we develop novel compatibility-aware incentive mechanisms, CARE-CO and CARE-NO, for both settings to elicit true private costs and determine workers to hire for requesters and their rewards while satisfying requester budget constraints. Our mechanisms guarantee individual rationality, truthfulness, budget feasibility, and approximation performance. We conduct extensive experiments using real-world datasets to show that the proposed mechanisms significantly outperform existing baselines.
CSI-Free Position Optimization for Movable Antenna Communication Systems: A Black-Box Optimization Approach
Aug 09, 2024


Movable antenna (MA) is a new technology which leverages local movement of antennas to improve channel qualities and enhance the communication performance. Nevertheless, to fully realize the potential of MA systems, complete channel state information (CSI) between the transmitter-MA and the receiver-MA is required, which involves estimating a large number of channel parameters and incurs an excessive amount of training overhead. To address this challenge, in this paper, we propose a CSI-free MA position optimization method. The basic idea is to treat position optimization as a black-box optimization problem and calculate the gradient of the unknown objective function using zeroth-order (ZO) gradient approximation techniques. Simulation results show that the proposed ZO-based method, through adaptively adjusting the position of the MA, can achieve a favorable signal-to-noise-ratio (SNR) using a smaller number of position measurements than the CSI-based approach. Such a merit makes the proposed algorithm more adaptable to fast-changing propagation channels.
Translating Expert Intuition into Quantifiable Features: Encode Investigator Domain Knowledge via LLM for Enhanced Predictive Analytics
May 11, 2024
In the realm of predictive analytics, the nuanced domain knowledge of investigators often remains underutilized, confined largely to subjective interpretations and ad hoc decision-making. This paper explores the potential of Large Language Models (LLMs) to bridge this gap by systematically converting investigator-derived insights into quantifiable, actionable features that enhance model performance. We present a framework that leverages LLMs' natural language understanding capabilities to encode these red flags into a structured feature set that can be readily integrated into existing predictive models. Through a series of case studies, we demonstrate how this approach not only preserves the critical human expertise within the investigative process but also scales the impact of this knowledge across various prediction tasks. The results indicate significant improvements in risk assessment and decision-making accuracy, highlighting the value of blending human experiential knowledge with advanced machine learning techniques. This study paves the way for more sophisticated, knowledge-driven analytics in fields where expert insight is paramount.
A Customer Level Fraudulent Activity Detection Benchmark for Enhancing Machine Learning Model Research and Evaluation
Apr 23, 2024In the field of fraud detection, the availability of comprehensive and privacy-compliant datasets is crucial for advancing machine learning research and developing effective anti-fraud systems. Traditional datasets often focus on transaction-level information, which, while useful, overlooks the broader context of customer behavior patterns that are essential for detecting sophisticated fraud schemes. The scarcity of such data, primarily due to privacy concerns, significantly hampers the development and testing of predictive models that can operate effectively at the customer level. Addressing this gap, our study introduces a benchmark that contains structured datasets specifically designed for customer-level fraud detection. The benchmark not only adheres to strict privacy guidelines to ensure user confidentiality but also provides a rich source of information by encapsulating customer-centric features. We have developed the benchmark that allows for the comprehensive evaluation of various machine learning models, facilitating a deeper understanding of their strengths and weaknesses in predicting fraudulent activities. Through this work, we seek to bridge the existing gap in data availability, offering researchers and practitioners a valuable resource that empowers the development of next-generation fraud detection techniques.
Similar Data Points Identification with LLM: A Human-in-the-loop Strategy Using Summarization and Hidden State Insights
Apr 03, 2024This study introduces a simple yet effective method for identifying similar data points across non-free text domains, such as tabular and image data, using Large Language Models (LLMs). Our two-step approach involves data point summarization and hidden state extraction. Initially, data is condensed via summarization using an LLM, reducing complexity and highlighting essential information in sentences. Subsequently, the summarization sentences are fed through another LLM to extract hidden states, serving as compact, feature-rich representations. This approach leverages the advanced comprehension and generative capabilities of LLMs, offering a scalable and efficient strategy for similarity identification across diverse datasets. We demonstrate the effectiveness of our method in identifying similar data points on multiple datasets. Additionally, our approach enables non-technical domain experts, such as fraud investigators or marketing operators, to quickly identify similar data points tailored to specific scenarios, demonstrating its utility in practical applications. In general, our results open new avenues for leveraging LLMs in data analysis across various domains.
Joint Transceiver Optimization for MmWave/THz MU-MIMO ISAC Systems
Jan 31, 2024In this paper, we consider the problem of joint transceiver design for millimeter wave (mmWave)/Terahertz (THz) multi-user MIMO integrated sensing and communication (ISAC) systems. Such a problem is formulated into a nonconvex optimization problem, with the objective of maximizing a weighted sum of communication users' rates and the passive radar's signal-to-clutter-and-noise-ratio (SCNR). By exploring a low-dimensional subspace property of the optimal precoder, a low-complexity block-coordinate-descent (BCD)-based algorithm is proposed. Our analysis reveals that the hybrid analog/digital beamforming structure can attain the same performance as that of a fully digital precoder, provided that the number of radio frequency (RF) chains is no less than the number of resolvable signal paths. Also, through expressing the precoder as a sum of a communication-precoder and a sensing-precoder, we develop an analytical solution to the joint transceiver design problem by generalizing the idea of block-diagonalization (BD) to the ISAC system. Simulation results show that with a proper tradeoff parameter, the proposed methods can achieve a decent compromise between communication and sensing, where the performance of each communication/sensing task experiences only a mild performance loss as compared with the performance attained by optimizing exclusively for a single task.
Pre-training transformer-based framework on large-scale pediatric claims data for downstream population-specific tasks
Jun 24, 2021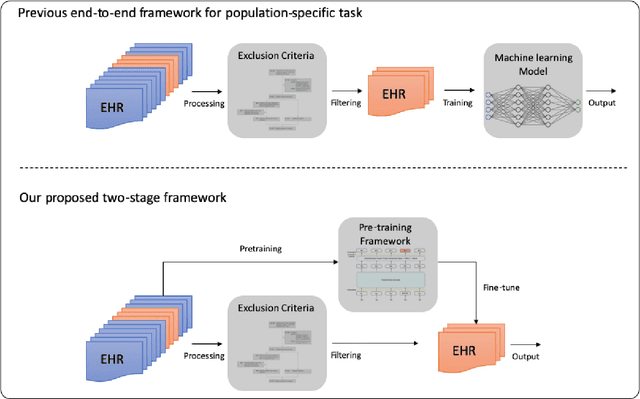
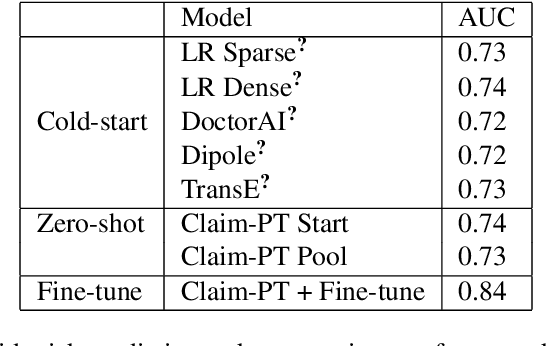
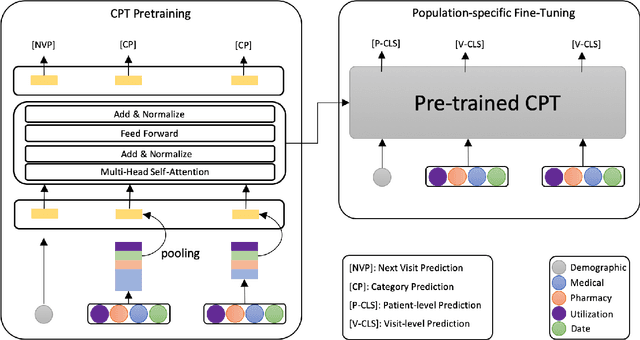
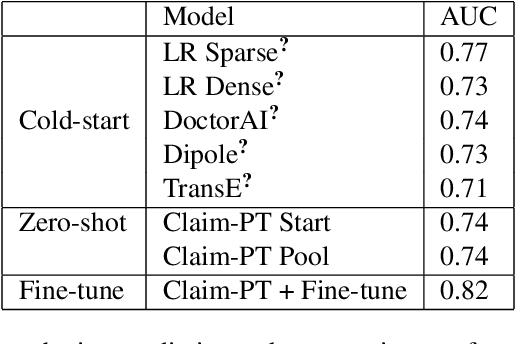
The adoption of electronic health records (EHR) has become universal during the past decade, which has afforded in-depth data-based research. By learning from the large amount of healthcare data, various data-driven models have been built to predict future events for different medical tasks, such as auto diagnosis and heart-attack prediction. Although EHR is abundant, the population that satisfies specific criteria for learning population-specific tasks is scarce, making it challenging to train data-hungry deep learning models. This study presents the Claim Pre-Training (Claim-PT) framework, a generic pre-training model that first trains on the entire pediatric claims dataset, followed by a discriminative fine-tuning on each population-specific task. The semantic meaning of medical events can be captured in the pre-training stage, and the effective knowledge transfer is completed through the task-aware fine-tuning stage. The fine-tuning process requires minimal parameter modification without changing the model architecture, which mitigates the data scarcity issue and helps train the deep learning model adequately on small patient cohorts. We conducted experiments on a real-world claims dataset with more than one million patient records. Experimental results on two downstream tasks demonstrated the effectiveness of our method: our general task-agnostic pre-training framework outperformed tailored task-specific models, achieving more than 10\% higher in model performance as compared to baselines. In addition, our framework showed a great generalizability potential to transfer learned knowledge from one institution to another, paving the way for future healthcare model pre-training across institutions.
Human-in-the-loop model explanation via verbatim boundary identification in generated neighborhoods
Jun 24, 2021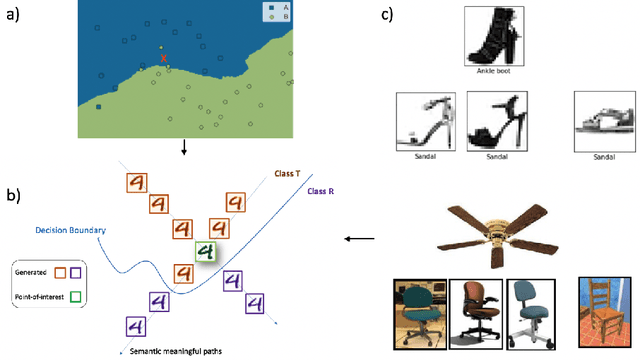

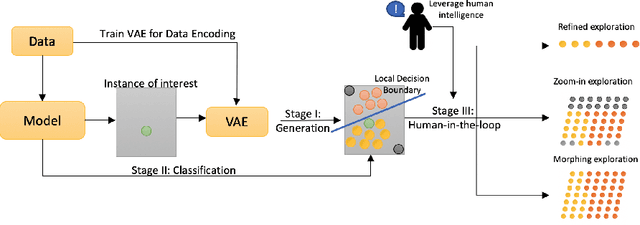

The black-box nature of machine learning models limits their use in case-critical applications, raising faithful and ethical concerns that lead to trust crises. One possible way to mitigate this issue is to understand how a (mispredicted) decision is carved out from the decision boundary. This paper presents a human-in-the-loop approach to explain machine learning models using verbatim neighborhood manifestation. Contrary to most of the current eXplainable Artificial Intelligence (XAI) systems, which provide hit-or-miss approximate explanations, our approach generates the local decision boundary of the given instance and enables human intelligence to conclude the model behavior. Our method can be divided into three stages: 1) a neighborhood generation stage, which generates instances based on the given sample; 2) a classification stage, which yields classifications on the generated instances to carve out the local decision boundary and delineate the model behavior; and 3) a human-in-the-loop stage, which involves human to refine and explore the neighborhood of interest. In the generation stage, a generative model is used to generate the plausible synthetic neighbors around the given instance. After the classification stage, the classified neighbor instances provide a multifaceted understanding of the model behavior. Three intervention points are provided in the human-in-the-loop stage, enabling humans to leverage their own intelligence to interpret the model behavior. Several experiments on two datasets are conducted, and the experimental results demonstrate the potential of our proposed approach for boosting human understanding of the complex machine learning model.