 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Color and Texture Dual Pipeline Lightweight Style Transfer
Oct 02, 2023
Style transfer methods typically generate a single stylized output of color and texture coupling for reference styles, and color transfer schemes may introduce distortion or artifacts when processing reference images with duplicate textures. To solve the problem, we propose a Color and Texture Dual Pipeline Lightweight Style Transfer CTDP method, which employs a dual pipeline method to simultaneously output the results of color and texture transfer. Furthermore, we designed a masked total variation loss to suppress artifacts and small texture representations in color transfer results without affecting the semantic part of the content. More importantly, we are able to add texture structures with controllable intensity to color transfer results for the first time. Finally, we conducted feature visualization analysis on the texture generation mechanism of the framework and found that smoothing the input image can almost completely eliminate this texture structure. In comparative experiments, the color and texture transfer results generated by CTDP both achieve state-of-the-art performance. Additionally, the weight of the color transfer branch model size is as low as 20k, which is 100-1500 times smaller than that of other state-of-the-art models.
DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models
Oct 02, 2023Quantifying the impact of training data points is crucial for understanding the outputs of machine learning models and for improving the transparency of the AI pipeline. The influence function is a principled and popular data attribution method, but its computational cost often makes it challenging to use. This issue becomes more pronounced in the setting of large language models and text-to-image models. In this work, we propose DataInf, an efficient influence approximation method that is practical for large-scale generative AI models. Leveraging an easy-to-compute closed-form expression, DataInf outperforms existing influence computation algorithms in terms of computational and memory efficiency. Our theoretical analysis shows that DataInf is particularly well-suited for parameter-efficient fine-tuning techniques such as LoRA. Through systematic empirical evaluations, we show that DataInf accurately approximates influence scores and is orders of magnitude faster than existing methods. In applications to RoBERTa-large, Llama-2-13B-chat, and stable-diffusion-v1.5 models, DataInf effectively identifies the most influential fine-tuning examples better than other approximate influence scores. Moreover, it can help to identify which data points are mislabeled.
Learning Tri-modal Embeddings for Zero-Shot Soundscape Mapping
Sep 19, 2023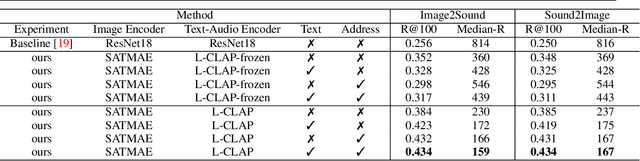
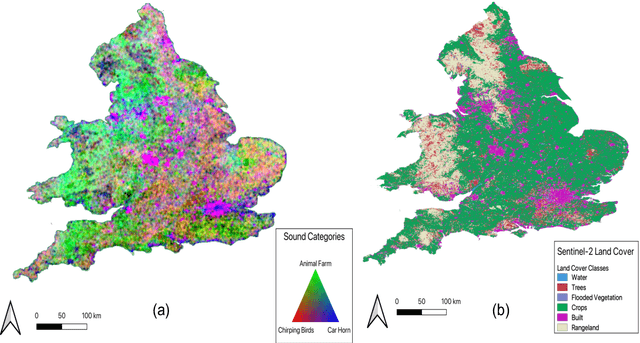
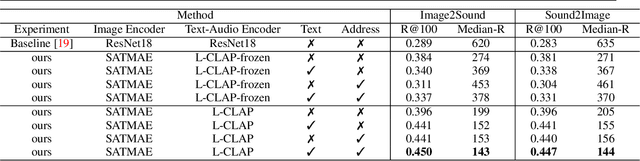

We focus on the task of soundscape mapping, which involves predicting the most probable sounds that could be perceived at a particular geographic location. We utilise recent state-of-the-art models to encode geotagged audio, a textual description of the audio, and an overhead image of its capture location using contrastive pre-training. The end result is a shared embedding space for the three modalities, which enables the construction of soundscape maps for any geographic region from textual or audio queries. Using the SoundingEarth dataset, we find that our approach significantly outperforms the existing SOTA, with an improvement of image-to-audio Recall@100 from 0.256 to 0.450. Our code is available at https://github.com/mvrl/geoclap.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023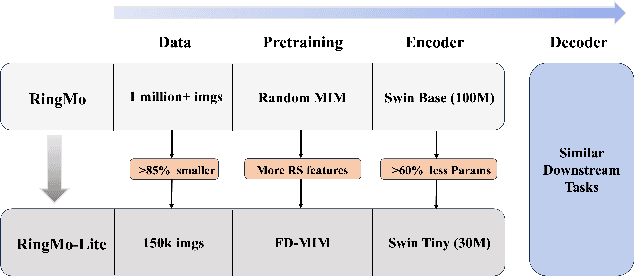
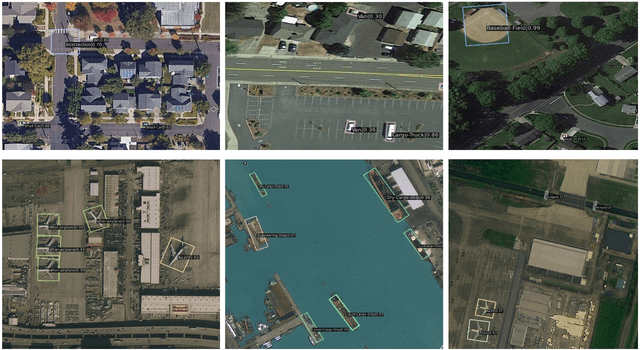
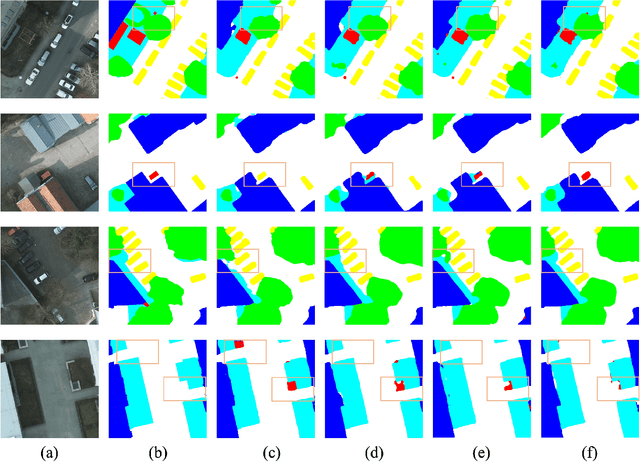
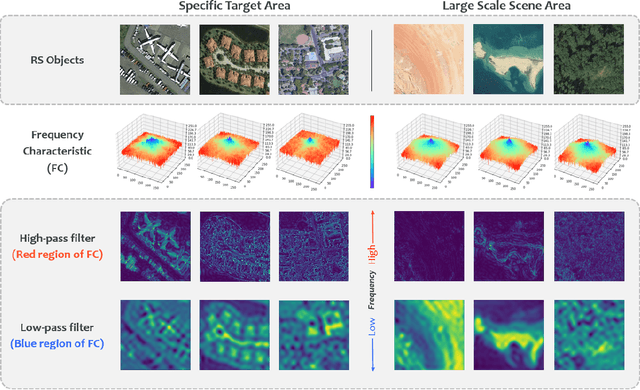
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.
Impact of architecture on robustness and interpretability of multispectral deep neural networks
Sep 21, 2023Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.
Food Image Classification and Segmentation with Attention-based Multiple Instance Learning
Aug 22, 2023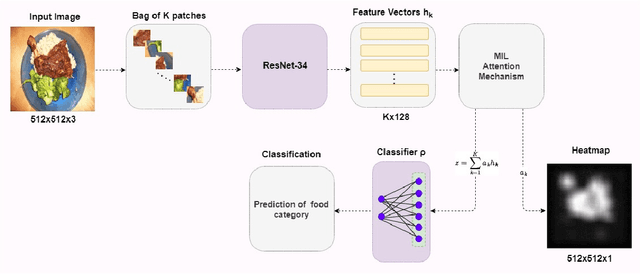
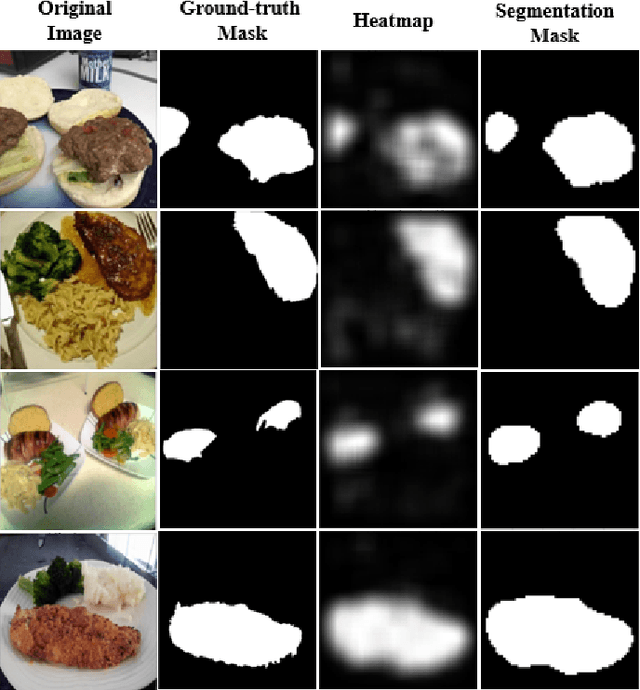
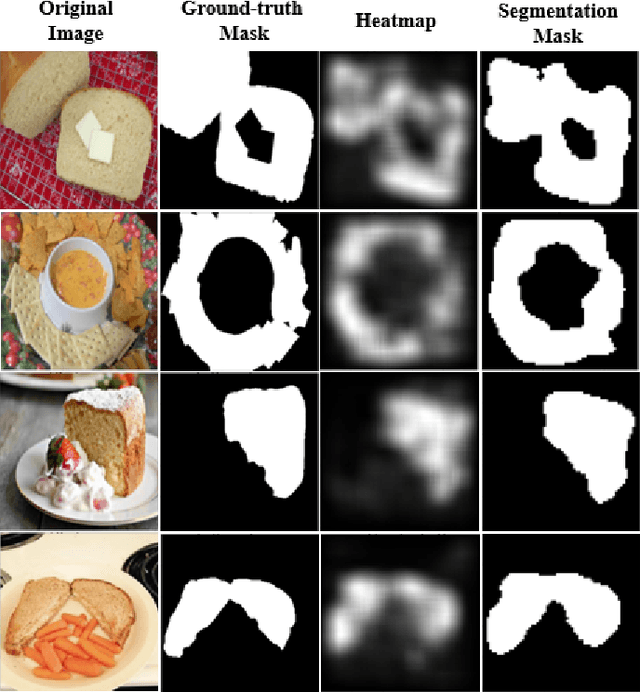
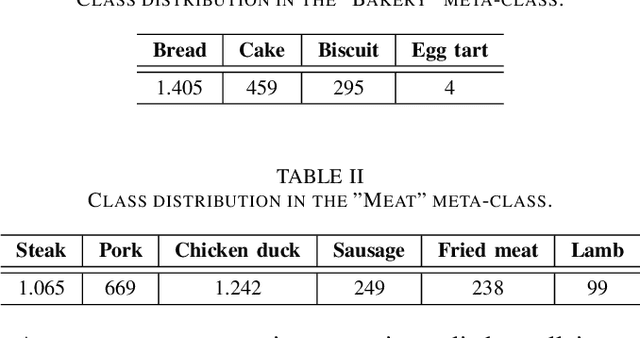
The demand for accurate food quantification has increased in the recent years, driven by the needs of applications in dietary monitoring. At the same time, computer vision approaches have exhibited great potential in automating tasks within the food domain. Traditionally, the development of machine learning models for these problems relies on training data sets with pixel-level class annotations. However, this approach introduces challenges arising from data collection and ground truth generation that quickly become costly and error-prone since they must be performed in multiple settings and for thousands of classes. To overcome these challenges, the paper presents a weakly supervised methodology for training food image classification and semantic segmentation models without relying on pixel-level annotations. The proposed methodology is based on a multiple instance learning approach in combination with an attention-based mechanism. At test time, the models are used for classification and, concurrently, the attention mechanism generates semantic heat maps which are used for food class segmentation. In the paper, we conduct experiments on two meta-classes within the FoodSeg103 data set to verify the feasibility of the proposed approach and we explore the functioning properties of the attention mechanism.
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023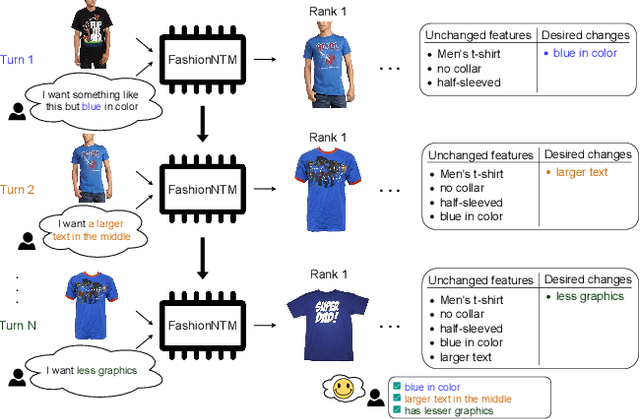
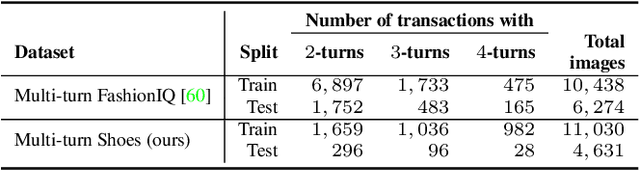
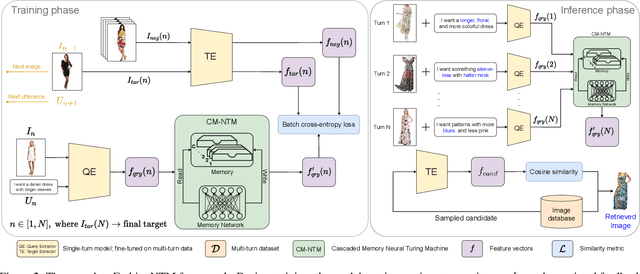
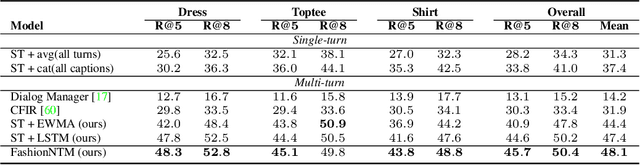
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
Improving Medical Image Classification in Noisy Labels Using Only Self-supervised Pretraining
Aug 08, 2023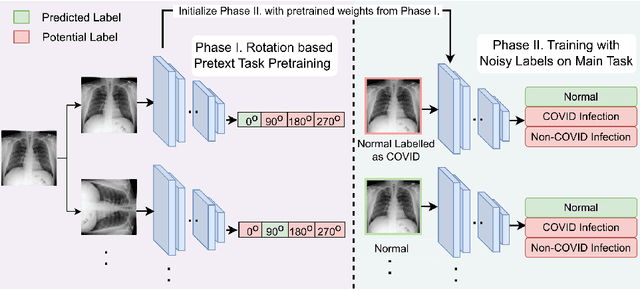
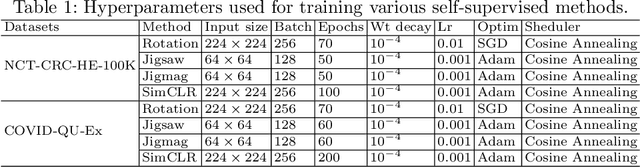
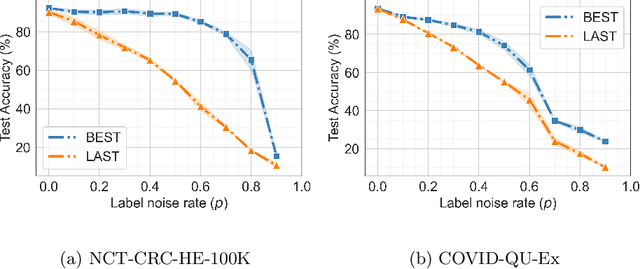
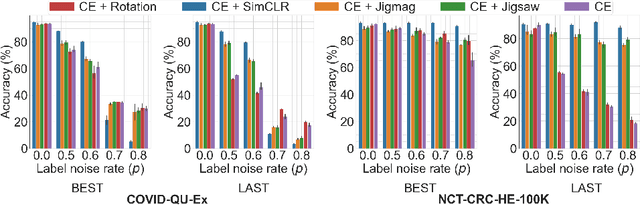
Noisy labels hurt deep learning-based supervised image classification performance as the models may overfit the noise and learn corrupted feature extractors. For natural image classification training with noisy labeled data, model initialization with contrastive self-supervised pretrained weights has shown to reduce feature corruption and improve classification performance. However, no works have explored: i) how other self-supervised approaches, such as pretext task-based pretraining, impact the learning with noisy label, and ii) any self-supervised pretraining methods alone for medical images in noisy label settings. Medical images often feature smaller datasets and subtle inter class variations, requiring human expertise to ensure correct classification. Thus, it is not clear if the methods improving learning with noisy labels in natural image datasets such as CIFAR would also help with medical images. In this work, we explore contrastive and pretext task-based self-supervised pretraining to initialize the weights of a deep learning classification model for two medical datasets with self-induced noisy labels -- NCT-CRC-HE-100K tissue histological images and COVID-QU-Ex chest X-ray images. Our results show that models initialized with pretrained weights obtained from self-supervised learning can effectively learn better features and improve robustness against noisy labels.
Brand Network Booster: A New System for Improving Brand Connectivity
Sep 28, 2023This paper presents a new decision support system offered for an in-depth analysis of semantic networks, which can provide insights for a better exploration of a brand's image and the improvement of its connectivity. In terms of network analysis, we show that this goal is achieved by solving an extended version of the Maximum Betweenness Improvement problem, which includes the possibility of considering adversarial nodes, constrained budgets, and weighted networks - where connectivity improvement can be obtained by adding links or increasing the weight of existing connections. We present this new system together with two case studies, also discussing its performance. Our tool and approach are useful both for network scholars and for supporting the strategic decision-making processes of marketing and communication managers.
PromptPaint: Steering Text-to-Image Generation Through Paint Medium-like Interactions
Aug 09, 2023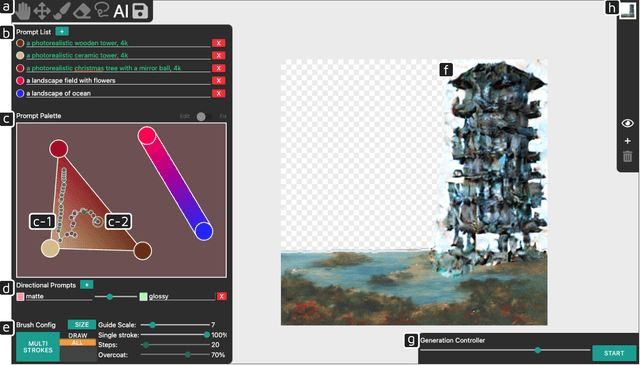

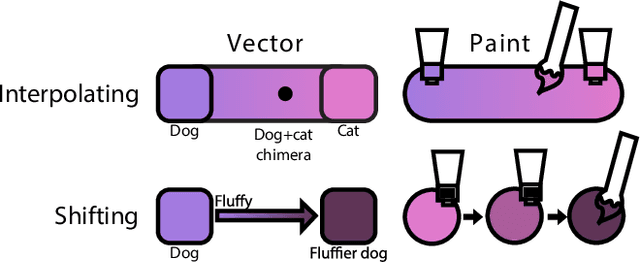

While diffusion-based text-to-image (T2I) models provide a simple and powerful way to generate images, guiding this generation remains a challenge. For concepts that are difficult to describe through language, users may struggle to create prompts. Moreover, many of these models are built as end-to-end systems, lacking support for iterative shaping of the image. In response, we introduce PromptPaint, which combines T2I generation with interactions that model how we use colored paints. PromptPaint allows users to go beyond language to mix prompts that express challenging concepts. Just as we iteratively tune colors through layered placements of paint on a physical canvas, PromptPaint similarly allows users to apply different prompts to different canvas areas and times of the generative process. Through a set of studies, we characterize different approaches for mixing prompts, design trade-offs, and socio-technical challenges for generative models. With PromptPaint we provide insight into future steerable generative tools.