 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TD-Net: A Tri-domain network for sparse-view CT reconstruction
Nov 26, 2023
Sparse-view CT reconstruction, aimed at reducing X-ray radiation risks, frequently suffers from image quality degradation, manifested as noise and artifacts. Existing post-processing and dual-domain techniques, although effective in radiation reduction, often lead to over-smoothed results, compromising diagnostic clarity. Addressing this, we introduce TD-Net, a pioneering tri-domain approach that unifies sinogram, image, and frequency domain optimizations. By incorporating Frequency Supervision Module(FSM), TD-Net adeptly preserves intricate details, overcoming the prevalent over-smoothing issue. Extensive evaluations demonstrate TD-Net's superior performance in reconstructing high-quality CT images from sparse views, efficiently balancing radiation safety and image fidelity. The enhanced capabilities of TD-Net in varied noise scenarios highlight its potential as a breakthrough in medical imaging.
Slice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction
Dec 03, 2023We introduce multi-slice reasoning, a new notion for single-view 3D reconstruction which challenges the current and prevailing belief that multi-view synthesis is the most natural conduit between single-view and 3D. Our key observation is that object slicing is more advantageous than altering views to reveal occluded structures. Specifically, slicing is more occlusion-revealing since it can peel through any occluders without obstruction. In the limit, i.e., with infinitely many slices, it is guaranteed to unveil all hidden object parts. We realize our idea by developing Slice3D, a novel method for single-view 3D reconstruction which first predicts multi-slice images from a single RGB image and then integrates the slices into a 3D model using a coordinate-based transformer network for signed distance prediction. The slice images can be regressed or generated, both through a U-Net based network. For the former, we inject a learnable slice indicator code to designate each decoded image into a spatial slice location, while the slice generator is a denoising diffusion model operating on the entirety of slice images stacked on the input channels. We conduct extensive evaluation against state-of-the-art alternatives to demonstrate superiority of our method, especially in recovering complex and severely occluded shape structures, amid ambiguities. All Slice3D results were produced by networks trained on a single Nvidia A40 GPU, with an inference time less than 20 seconds.
Method for robotic motion compensation during PET imaging of mobile subjects
Nov 29, 2023Studies of the human brain during natural activities, such as locomotion, would benefit from the ability to image deep brain structures during these activities. While Positron Emission Tomography (PET) can image these structures, the bulk and weight of current scanners are not compatible with the desire for a wearable device. This has motivated the design of a robotic system to support a PET imaging system around the subject's head and to move the system to accommodate natural motion. We report here the design and experimental evaluation of a prototype robotic system that senses motion of a subject's head, using parallel string encoders connected between the robot-supported imaging ring and a helmet worn by the subject. This measurement is used to robotically move the imaging ring (coarse motion correction) and to compensate for residual motion during image reconstruction (fine motion correction). Minimization of latency and measurement error are the key design goals, respectively, for coarse and fine motion correction. The system is evaluated using recorded human head motions during locomotion, with a mock imaging system consisting of lasers and cameras, and is shown to provide an overall system latency of about 80 ms, which is sufficient for coarse motion correction and collision avoidance, as well as a measurement accuracy of about 0.5 mm for fine motion correction.
Guided Prompting in SAM for Weakly Supervised Cell Segmentation in Histopathological Images
Nov 29, 2023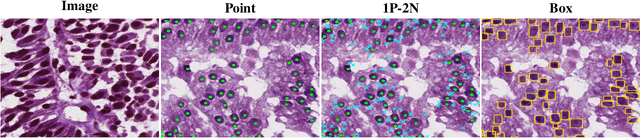
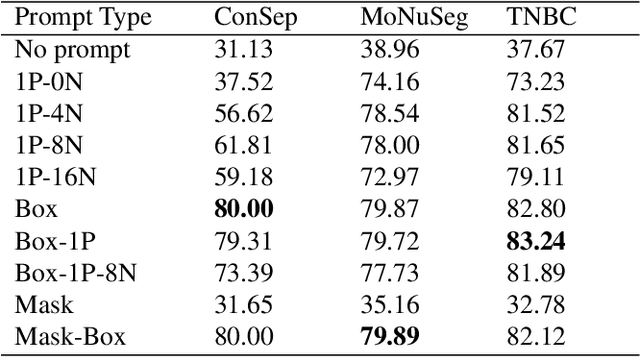
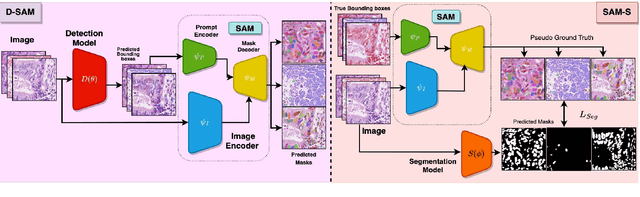
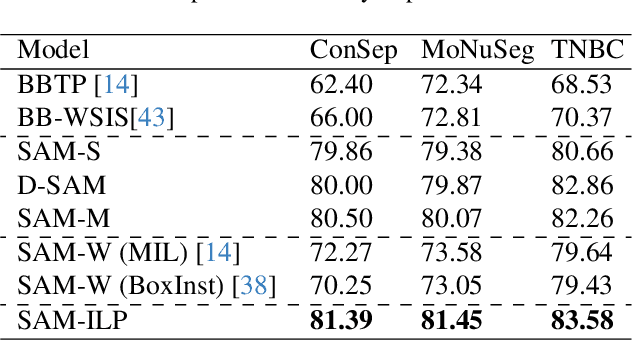
Cell segmentation in histopathological images plays a crucial role in understanding, diagnosing, and treating many diseases. However, data annotation for this is expensive since there can be a large number of cells per image, and expert pathologists are needed for labelling images. Instead, our paper focuses on using weak supervision -- annotation from related tasks -- to induce a segmenter. Recent foundation models, such as Segment Anything (SAM), can use prompts to leverage additional supervision during inference. SAM has performed remarkably well in natural image segmentation tasks; however, its applicability to cell segmentation has not been explored. In response, we investigate guiding the prompting procedure in SAM for weakly supervised cell segmentation when only bounding box supervision is available. We develop two workflows: (1) an object detector's output as a test-time prompt to SAM (D-SAM), and (2) SAM as pseudo mask generator over training data to train a standalone segmentation model (SAM-S). On finding that both workflows have some complementary strengths, we develop an integer programming-based approach to reconcile the two sets of segmentation masks, achieving yet higher performance. We experiment on three publicly available cell segmentation datasets namely, ConSep, MoNuSeg, and TNBC, and find that all SAM-based solutions hugely outperform existing weakly supervised image segmentation models, obtaining 9-15 pt Dice gains.
Time-efficient combined morphologic and quantitative joint MRI based on clinical image contrasts -- An exploratory in-situ study of standardized cartilage defects
Nov 14, 2023OBJECTIVES: Quantitative MRI techniques such as T2 and T1$\rho$ mapping are beneficial in evaluating cartilage and meniscus. We aimed to evaluate the MIXTURE (Multi-Interleaved X-prepared Turbo-Spin Echo with IntUitive RElaxometry) sequences that provide morphologic images with clinical turbo spin-echo (TSE) contrasts and additional parameter maps versus reference TSE sequences in an in-situ model of human cartilage defects. MATERIALS AND METHODS: Prospectively, standardized cartilage defects of 8mm, 5mm, and 3mm diameter were created in the lateral femora of 10 human cadaveric knee specimens (81$\pm$10 years, nine male/one female). Using a clinical 3T MRI scanner and knee coil, MIXTURE sequences combining (i) proton-density weighted fat-saturated (PD-w FS) images and T2 maps and (ii) T1-weighted images and T1$\rho$ maps were acquired before and after defect creation, alongside the corresponding 2D TSE and 3D TSE reference sequences. Defect delineability, bone texture, and cartilage relaxation times were quantified. Inter-sequence comparisons were made using appropriate parametric and non-parametric tests. RESULTS: Overall, defect delineability and texture features were not significantly different between the MIXTURE and reference sequences. After defect creation, relaxation times increased significantly in the central femur (for T2) and all regions combined (for T1$\rho$). CONCLUSION: MIXTURE sequences permit time-efficient simultaneous morphologic and quantitative joint assessment based on clinical image contrasts. While providing T2 or T1$\rho$ maps in clinically feasible scan time, morphologic image features, i.e., cartilage defect delineability and bone texture, were comparable between MIXTURE and corresponding reference sequences.
Observer study-based evaluation of TGAN architecture used to generate oncological PET images
Nov 28, 2023The application of computer-vision algorithms in medical imaging has increased rapidly in recent years. However, algorithm training is challenging due to limited sample sizes, lack of labeled samples, as well as privacy concerns regarding data sharing. To address these issues, we previously developed (Bergen et al. 2022) a synthetic PET dataset for Head and Neck (H and N) cancer using the temporal generative adversarial network (TGAN) architecture and evaluated its performance segmenting lesions and identifying radiomics features in synthesized images. In this work, a two-alternative forced-choice (2AFC) observer study was performed to quantitatively evaluate the ability of human observers to distinguish between real and synthesized oncological PET images. In the study eight trained readers, including two board-certified nuclear medicine physicians, read 170 real/synthetic image pairs presented as 2D-transaxial using a dedicated web app. For each image pair, the observer was asked to identify the real image and input their confidence level with a 5-point Likert scale. P-values were computed using the binomial test and Wilcoxon signed-rank test. A heat map was used to compare the response accuracy distribution for the signed-rank test. Response accuracy for all observers ranged from 36.2% [27.9-44.4] to 63.1% [54.8-71.3]. Six out of eight observers did not identify the real image with statistical significance, indicating that the synthetic dataset was reasonably representative of oncological PET images. Overall, this study adds validity to the realism of our simulated H&N cancer dataset, which may be implemented in the future to train AI algorithms while favoring patient confidentiality and privacy protection.
Learning Cortical Anomaly through Masked Encoding for Unsupervised Heterogeneity Mapping
Dec 05, 2023The detection of heterogeneous mental disorders based on brain readouts remains challenging due to the complexity of symptoms and the absence of reliable biomarkers. This paper introduces CAM (Cortical Anomaly Detection through Masked Image Modeling), a novel self-supervised framework designed for the unsupervised detection of complex brain disorders using cortical surface features. We employ this framework for the detection of individuals on the psychotic spectrum and demonstrate its capabilities compared to state-ofthe-art methods, achieving an AUC of 0.696 for Schizoaffective and 0.769 for Schizophreniform, without the need for any labels. Furthermore, the analysis of atypical cortical regions includes Pars Triangularis and several frontal areas, often implicated in schizophrenia, provide further confidence in our approach. Altogether, we demonstrate a scalable approach for anomaly detection of complex brain disorders based on cortical abnormalities.
Explainable Severity ranking via pairwise n-hidden comparison: a case study of glaucoma
Dec 05, 2023Primary open-angle glaucoma (POAG) is a chronic and progressive optic nerve condition that results in an acquired loss of optic nerve fibers and potential blindness. The gradual onset of glaucoma results in patients progressively losing their vision without being consciously aware of the changes. To diagnose POAG and determine its severity, patients must undergo a comprehensive dilated eye examination. In this work, we build a framework to rank, compare, and interpret the severity of glaucoma using fundus images. We introduce a siamese-based severity ranking using pairwise n-hidden comparisons. We additionally have a novel approach to explaining why a specific image is deemed more severe than others. Our findings indicate that the proposed severity ranking model surpasses traditional ones in terms of diagnostic accuracy and delivers improved saliency explanations.
DI-Net : Decomposed Implicit Garment Transfer Network for Digital Clothed 3D Human
Nov 28, 20233D virtual try-on enjoys many potential applications and hence has attracted wide attention. However, it remains a challenging task that has not been adequately solved. Existing 2D virtual try-on methods cannot be directly extended to 3D since they lack the ability to perceive the depth of each pixel. Besides, 3D virtual try-on approaches are mostly built on the fixed topological structure and with heavy computation. To deal with these problems, we propose a Decomposed Implicit garment transfer network (DI-Net), which can effortlessly reconstruct a 3D human mesh with the newly try-on result and preserve the texture from an arbitrary perspective. Specifically, DI-Net consists of two modules: 1) A complementary warping module that warps the reference image to have the same pose as the source image through dense correspondence learning and sparse flow learning; 2) A geometry-aware decomposed transfer module that decomposes the garment transfer into image layout based transfer and texture based transfer, achieving surface and texture reconstruction by constructing pixel-aligned implicit functions. Experimental results show the effectiveness and superiority of our method in the 3D virtual try-on task, which can yield more high-quality results over other existing methods.
$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Nov 25, 2023Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.